本章内容
- 定义提示模板(prompt templates)
- 提供上下文
- 格式化响应输出
- 流式传输响应
- 访问响应元数据
在第 1 章中,你创建了一个非常简单的 Spring AI 应用:它在 POST 请求里接收一个问题,并通过注入的 ChatClient 直接提交给 LLM。它运行良好,但随着你的生成式 AI 需求变得更高级,你发给 LLM 的提示也会随之复杂化。此时,基于 String 的提示可能就不够用了。
另外,生成的响应也不仅仅是一个简单的字符串。结果中可能包含有用的元数据 ,例如用量数据 ,帮助你评估每次生成对计费的影响。响应还可以分片流式返回给客户端,而不是一次性返回完整结果。
本章将把你的提示与响应处理提升到新水平。先从如何定义提示模板开始。
3.1 使用提示模板(Working with prompt templates)
Spring AI 支持从模板创建提示 。模板由固定文本与一个或多个占位符组成。如图 3.1 所示,这些模板的占位符将由"模型数据"在每次调用时填充,以生成要发送给 LLM 的提示。模型数据被填入占位符,外层由提示文本包裹,引导 LLM 应当如何作答。
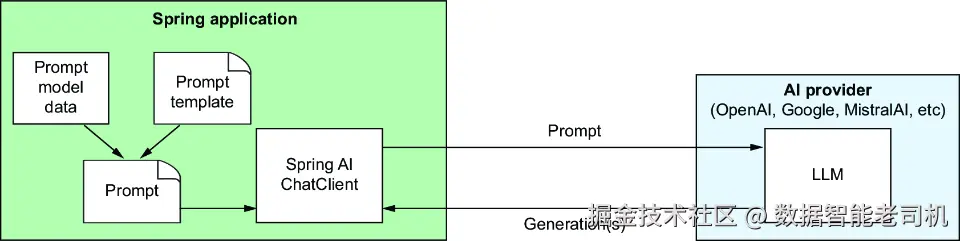
图 3.1 使用提示模板由模型数据生成提示
为了演示提示模板如何工作,我们从第 1 章的示例出发,把它扩展为能回答各类桌面游戏(如跳棋、Monopoly,或更现代的欧式桌游如 Catan、Wingspan)的问答。
首先,需要在 Question 记录类型中加入游戏标题:
less
package com.example.boardgamebuddy;
import jakarta.validation.constraints.NotBlank;
public record Question(
@NotBlank(message = "Game title is required") String gameTitle,
@NotBlank(message = "Question is required") String question) {
}这个新版 Question 增加了 gameTitle 属性,用于承载游戏名。这样即便问题本身未提到游戏名,也能提供足够上下文来回答关于某款游戏的提问。
你也会注意到两个属性都标注了 @NotBlank。虽然校验 不是 Spring AI 的特性,但它是 Spring 本身非常重要且有用的功能。用 @NotBlank 声明它们都是必填 的,且不能为 null 或去空白后变成空字符串。
要启用 @NotBlank 以及 Spring 的校验支持,需要在构建中加入如下 starter 依赖:
arduino
implementation 'org.springframework.boot:spring-boot-starter-validation'同时,需要在控制器的 ask() 方法里给 Question 参数添加 @Valid,以便 Spring 在处理该控制器的请求时执行校验:
less
@PostMapping(path="/ask", produces="application/json")
public Answer ask(@RequestBody @Valid Question question) {
return boardGameService.askQuestion(question);
}最后,为了把校验错误整齐地 以 JSON 形式返回,下面的控制器增强(advice)类利用了 Spring 对 Problem Details(RFC-7807) 的支持(datatracker.ietf.org/doc/html/rf...)。
清单 3.1 使用 Problem Details 优雅返回校验错误
kotlin
package com.example.boardgamebuddy;
import org.springframework.context.MessageSourceResolvable;
import org.springframework.http.HttpStatus;
import org.springframework.http.ProblemDetail;
import org.springframework.web.bind.MethodArgumentNotValidException;
import org.springframework.web.bind.annotation.ExceptionHandler;
import org.springframework.web.bind.annotation.RestControllerAdvice;
import java.util.List;
@RestControllerAdvice
public class ExceptionHandlerAdvice {
@ExceptionHandler(MethodArgumentNotValidException.class)
public ProblemDetail handleValidationExceptions(
MethodArgumentNotValidException ex) {
var problemDetail = ProblemDetail
.forStatusAndDetail(HttpStatus.BAD_REQUEST, "Validation failed");
var validationMessages = ex.getBindingResult().getAllErrors()
.stream()
.map(MessageSourceResolvable::getDefaultMessage)
.toList();
problemDetail.setProperty("validationErrors", validationMessages);
return problemDetail;
}
}简而言之,Problem Details 是一种对 HTTP API 错误进行标准化结构化 的规范。自 Spring 6.0 起,Spring 就提供了一等的 Problem Details 支持。当应用了 Problem Details 且校验失败(例如请求未提供游戏名)时,客户端会收到类似这样的标准响应:
json
{
"detail": "Validation failed",
"instance": "/ask",
"status": 400,
"title": "Bad Request",
"type": "about:blank",
"validationErrors": [
"Game title is required"
]
}现在把注意力转向响应 。与 Question 一样,你还希望在 Answer 记录类型中加入游戏标题,让 API 客户端知道这条答案对应的是哪款游戏:
arduino
package com.example.boardgamebuddy;
public record Answer(String gameTitle, String answer) {
}既然 Question 与 Answer 都包含了游戏名,你可以把 SpringAiBoardGameService 中的 askQuestion() 简化为字符串拼接生成提示:
typescript
@Override
public Answer askQuestion(Question question) {
String prompt =
"Answer this question about " + question.gameTitle() +
": " + question.question();
String answerText = chatClient.prompt()
.user(prompt)
.call()
.content();
return new Answer(question.gameTitle(), answerText);
}现在可以在请求中带上游戏名来提问了。比如用 HTTPie 向经典的 checkers(跳棋) 提问:
bash
$ http :8080/ask gameTitle="checkers" \
question="How many pieces are there?" -b
{
"answer": "In checkers, there are a total of 24 pieces-12 for each player.",
"gameTitle": "checkers"
}底层 LLM 能基于自身训练回答关于跳棋的问题。这种方式适用于知名游戏 (如跳棋、国际象棋);但对于较新/不那么出名 的游戏可能会吃力。下一章我们会看到如何让 LLM 回答超出其训练范围的问题。
虽然能用,但通过字符串拼接 来构建提示很笨拙。即便是 askQuestion() 中这样简单的提示,也会让代码读写不便。
3.1.1 定义提示模板(Defining a prompt template)
与其用字符串拼接,不如创建一个提示模板 ,把"原始、未渲染的提示"写成带占位符的模板。下面清单展示了修改后的 SpringAiBoardGameService,它使用了模板化提示。
清单 3.2 使用提示模板,避免笨拙的字符串拼接
java
package com.example.boardgamebuddy;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.stereotype.Service;
@Service
public class SpringAiBoardGameService implements BoardGameService {
private final ChatClient chatClient;
public SpringAiBoardGameService(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder.build();
}
private static final String questionPromptTemplate = """
Answer this question about {game}: {question}
""";
@Override
public Answer askQuestion(Question question) {
var answerText = chatClient.prompt()
.user(userSpec -> userSpec
.text(questionPromptTemplate)
.param("gameTitle", question.gameTitle())
.param("question", question.question()))
.call()
.content();
return new Answer(question.gameTitle(), answerText);
}
}如你所见,名为 questionPromptTemplate 的提示模板看起来与此前拼接出来的提示很像,但它不仅仅是文本。它是一个 StringTemplate (www.stringtemplate.org/),其中包含每个参数的占位符{game} 与 {question}。
由于存在占位符,这个模板不能 直接作为普通字符串提交;你还必须提供用于填充占位符的值。
因此,在 askQuestion() 中,user() 不是接收模板字符串本身,而是接收一个lambda 。更具体地说,这个 lambda 实现了 Consumer<UserSpec> 接口,让你能定制要发送给 LLM 的消息。
在本例中,通过在 userSpec 上调用 text() 指定用户消息的正文(也就是提示模板),再通过多次调用 param() 为每个参数设置值。在提示发送给 LLM 之前,占位符会被这些参数值填充,从而形成完整的提示消息。图 3.2 演示了这个过程。
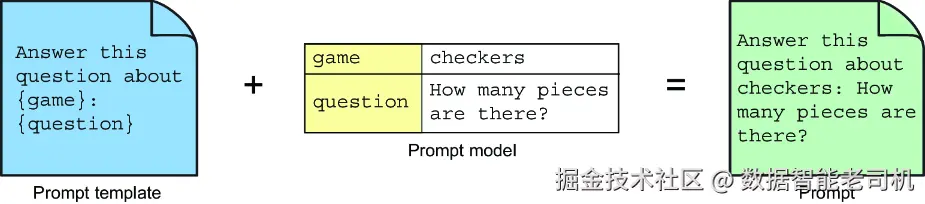
图 3.2 提示模板把模型数据渲染进提示,再提交给 LLM
askQuestion() 余下的代码与之前相同:call() 表示提示已准备就绪并发送;content() 返回答案文本。
重新启动应用,再次提交请求,它应当像之前一样工作(由于生成式 AI 的非确定性 ,回答的措辞可能略有变化)。你也可以试着询问其他桌游来看看回答情况。
现在,提示的核心集中在一个地方------那个静态字符串常量 ------可读且易维护,尽管在 askQuestion() 里多了几行代码。既然更易维护了,我们就做点提示工程(prompt engineering) ,把模板再优化一下。例如改为:
ini
private static final String questionPromptTemplate = """
You are a helpful assistant, answering questions about tabletop games.
If you don't know anything about the game or don't know the answer,
say "I don't know".
The game is {game}.
The question is: {question}.
""";这个新模板为 LLM 设置了更多角色与期望上下文 :告诉它自己是一个有用的助手、要回答桌面游戏 相关的问题;还要求它在不知道答案或不了解该游戏时明确承认不知道。
像这样的小小提示工程技巧,能帮助你从提示中获得更好的结果。更多提示工程建议可参考 Prompt Engineering Guide (www.promptingguide.ai/)。
3.1.2 将模板作为资源导入(Importing the template as a resource)
把提示模板的字符串提取成常量,有助于整理 askQuestion() 方法,让代码更易读、也更便于调整提示。但你还能再进一步:把模板抽到外部文件。这样既能让模板与 Java 源码分离,又仍可将模板纳入代码仓库管理。
为此,先在项目的 src/main/resources 目录下创建名为 promptTemplates 的新目录。在新目录里创建文件 questionPromptTemplate.st,内容如下:
vbnet
You are a helpful assistant, answering questions about tabletop games.
If you don't know anything about the game or don't know the answer,
say "I don't know".
Answer in complete sentences.
The game is {gameTitle}.
The question is: {question}.NOTE 目录名与模板文件名可以随意取;只要在把模板注入到 SpringAiBoardGameService 时正确引用即可。
(尽管你把代码提交到 GitHub 时它可能会提示别的),扩展名 .st 表示这是一个 StringTemplate 文件(并不是 Smalltalk 文件)。可以看到,这个 StringTemplate 文件的文本与之前定义的静态字符串常量相同。但现在模板在独立文件中,模板的细节可与"提交提示的代码"分开维护。
基于此,你需要修改 SpringAiBoardGameService 来引用该模板文件。删除静态字符串常量,改为如下字段:
kotlin
@Value("classpath:/promptTemplates/questionPromptTemplate.st")
Resource questionPromptTemplate;@Value 注解使用 classpath: 前缀来引用模板文件,本质上是把它注入到一个 Resource 属性中。注意,这个 Resource 属性的名字与原先的字符串常量相同。user 规格的 text() 方法是重载 的,既可接受 String,也可接受 Resource。因此把该 Resource 命名为 questionPromptTemplate 后,你无需修改 askQuestion() 方法里对模板的使用。
重启应用,继续就游戏提问;行为依旧与之前相同。尽管应用外在行为没变,但内部实现更整洁;对模板的任何调整,都可以与 SpringAiBoardGameService 代码解耦地完成。
如果你询问 checkers、chess 或其他知名游戏,很可能会得到正确答案。但假设你问的是模型未被训练过的游戏。例如试着询问纸牌游戏 Burger Battle (www.burgerbattlegame.com/)。理想情况下,如果它不知道答案,它会说 "I don't know":
bash
$ http :8080/ask gameTitle="Burger Battle" \
question="What is the Grave Digger card?" -b
{
"answer": "I don't know.",
"gameTitle": "Burger Battle"
}尽管模板明确要求"不会就说 I don't know",你仍有相当概率得到瞎编的答案:
bash
$ http :8080/ask gameTitle="Burger Battle" \
question="What is the Destroy card?" -b
{
"answer": "In Burger Battle, the Destroy card is a special card that allows
players to eliminate one ingredient card from an opponent's burger.",
"gameTitle": "Burger Battle"
}如果你玩过------或读过------Burger Battle 的规则,你会知道这答案是错误的 。这就是与 LLM 共事时一个不太妙、但有时颇具"喜剧效果"的特性:当它对某话题训练不足时,可能编造 一个完全不真实的答案------通常称为幻觉(hallucinations) 。
避免幻觉的几种方式包括:
- 训练你自己的模型
- 对现有模型进行微调(fine-tuning)
- 在提示中提供额外上下文
从根本上说,训练或微调(更不用说能基于私有数据定制模型)是避免幻觉的上策,但这很难,且需要数据科学 领域的技能而非软件开发技能。此外,训练/微调要想做得好,需要大量数据 ,也非常耗时------可能是数小时、数天,甚至数周。以我们构建的桌游示例为例,因应新品发布立即为其"加入一个游戏"的做法就不可行。
相较之下,在提示中添加一些上下文 几乎就像添加问题本身那样简单------在提交提示的即时 阶段完成。因此,它比训练/微调要简单得多。
下面看看如何在提示中连同问题一起提供额外上下文 。这将为下一章的 RAG(检索增强生成) 做铺垫------RAG 是一种更高级的方法,能在不超限的情况下为提示添加相关上下文。
3.2 用上下文"填充"提示(Stuffing the prompt with context)
回想你上学时,可能遇到过开卷考试 。这时,你不必把所有内容死记在脑子里:即便你没复习,也能翻书找到过关所需的答案。
在生成式 AI 中,常被称为 "stuffing the prompt(填充提示)" 的技巧,就像给 LLM 进行一次"开卷考试"。除了把问题提交给 LLM 生成外,你还提供一段额外文本供它参考。这样,LLM 即便未在该主题上预训练,也能回答相关问题。
为了让 Board Game Buddy 能准确回答 Burger Battle (LLM 未训练过的游戏)的问题,我们给它来一场"开卷":把游戏规则 作为上下文加入提示。最直接的方式是创建一个纯文本文件来存放该游戏规则。
Burger Battle 的规则(mng.bz/yNKo)相对较短,但仍然太长,不适合原文印在书里。至少,为了让 LLM 能回答 Destroy 卡或其他战斗卡相关问题,创建一个包含以下内容的文件:
python
* Burger Bomb: Blow up another player's Burger by sending their ingredients
to the Graveyard.
* Burger Force Field: Your Burger is now protected from all Battle Cards
* Burgerpocalypse: Obliterate all players' ingredients, including your own,
and toss them in the Graveyard.
* Destroy!: Destroy any Battle Card of yours or another player's and toss
it in the Graveyard.
* Gonna Eat That?: Steal another player's ingredient and add it to your
Burger.
* Grave Digger: Dig through the Graveyard for any needed ingredient and add
it to your Burger.
* I Got Nothin': Toss your hand in the Graveyard and draw 5 new cards
* More Meat!: Make another player's Burger a double-decker by adding an
extra Meat to their ingredients list.
* Pickle Plague: Rain vengeance down upon another player by adding Pickles
to their ingredients list.
* Picky Eater: Throw another player's Lettuce, Tomato, or Onion in the
Graveyard.
* The Old Switcheroo: Trade hands with another player.
* Yours Looks Good!: Trade your Burger and all of your ingredients with
another player, including added Battle Cards.把这个文件放到 src/main/resources 下新建的 gameRules 目录,命名为 burger_battle.txt。
接下来,需要修改模板,加入一个规则占位符:
vbnet
You are a helpful assistant, answering questions about tabletop games.
If available, use the rules in the RULES section below.
If you don't know anything about the game or don't know the answer,
say "I don't know".
Answer in complete sentences.
The game is {gameTitle}.
The question is: {question}.
RULES:
{rules}注意,除了新增 {rules} 占位符之外,文本中还加入了指令,告诉 LLM:如果有规则可用,请使用它们。
在把规则注入提示之前,需要先把规则读入一个字符串。为此,创建一个类似下方清单的服务类。
清单 3.3 GameRulesService 将游戏规则加载为字符串
java
package com.example.boardgamebuddy;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.core.io.DefaultResourceLoader;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.nio.charset.Charset;
@Service
public class GameRulesService {
private static final Logger LOG =
LoggerFactory.getLogger(GameRulesService.class);
public String getRulesFor(String gameName) {
try {
var filename = String.format(
"classpath:/gameRules/%s.txt",
gameName.toLowerCase().replace(" ", "_"));
return new DefaultResourceLoader()
.getResource(filename)
.getContentAsString(Charset.defaultCharset()); \
} catch (IOException e) {
LOG.info("No rules found for game: " + gameName);
return "";
}
}
}简而言之,getRulesFor() 会通过 Resource 把某个游戏的规则加载为字符串 。由于资源路径会随游戏名变化,无法像模板那样用 @Value 固定注入,因此 getRulesFor() 借助了一些 Spring 的工具类来构造 Resource。
在构造规则路径时,getRulesFor() 会把游戏标题转为小写 并把空格替换为下划线,避免因大小写或空格差异导致标题与文件名不一致。例如如果 Question 中传入的游戏名是 "Burger battle",它会被规范化为 burger_battle。
现在可以修改 SpringAiBoardGameService,把规则加入提示。首先把 GameRulesService 注入进来:
kotlin
@Service
public class SpringAiBoardGameService implements BoardGameService {
private final ChatClient chatClient;
private final GameRulesService gameRulesService;
public SpringAiBoardGameService(
ChatClient.Builder chatClientBuilder,
GameRulesService gameRulesService) {
this.chatClient = chatClientBuilder.build();
this.gameRulesService = gameRulesService;
}
// ...
}然后,修改 askQuestion(),调用 GameRulesService 读取规则,并通过再调用一次 param() 把规则作为参数加入用户消息规格:
less
@Override
public Answer askQuestion(Question question) {
var gameRules = gameRulesService.getRulesFor(question.gameTitle());
var answerText = chatClient.prompt()
.user(userSpec -> userSpec
.text(questionPromptTemplate)
.param("gameTitle", question.gameTitle())
.param("question", question.question())
.param("rules", gameRules))
.call()
.content();
return new Answer(question.gameTitle(), answerText);
}现在可以试一试了。重启应用,再次询问 Burger Battle 的 Destroy 卡:
bash
$ http :8080/ask gameTitle="Burger Battle" \
question="What is the Destroy card?" -b
{
"answer": "The Destroy card in Burger Battle allows you to destroy any
Battle Card, whether it belongs to you or another player, and then
place it in the Graveyard.",
"gameTitle": "Burger Battle"
}太棒了!这次答案正确 ,而且显然是从提示中给定的上下文抽取出来的。
为确保其他游戏也能正常回答,再试一次。这次问 chess:
bash
$ http :8080/ask gameTitle="chess" \
question="How are knights allowed to move?" -b
{
"answer": "In chess, knights move in an L-shape: two squares in one
direction, and then one square perpendicular to that. Knights are the
only pieces that can jump over other pieces on the board.",
"gameTitle": "chess"
}即使应用没有从资源中加载国际象棋的规则,模型也能回答,因为它已在训练中学过国际象棋规则。
需要理解的是:更多上下文 意味着提示中会有更多输入 token 。例如提问国际象棋时没有额外上下文,提示只有 75 个 token ;而 Burger Battle 的问题(即便只包含一小段规则)提示 token 数是 315 ------ 是无上下文时的 4 倍多。
至少,token 数会影响成本:提示(以及响应)中的 token 越多,付费就越多。很多 LLM(如 GPT-4o)在每 1,000 token 的价格上非常便宜,但随着使用时间增长,也会累积。
更进一步,如果提示里 token 太多,可能会超出上下文窗口 的限制。以 GPT-4o 为例,窗口为 128K token,远超我们这个简单示例的需求。大多数桌游的规则都能轻松落在 128K 内,但在其他领域,把大体量文档作为上下文就很可能超限。
在下一章里,你将学习如何使用 RAG(检索增强生成) ,在不超限的情况下,为提示提供相关的上下文 。在引入 RAG 之前,关于提示我们还有一些内容要探索,比如提示角色(prompt roles) 的用法。
3.3 为提示分配角色(Assigning prompt roles)
包括 OpenAI、MistralAI、Anthropic 在内的许多 LLM,都支持把一个提示切分为多条消息 ,每条消息都归属于某个角色,模型应按该角色来理解这段内容。常见的角色包括:
- User(用户) ------来自应用用户(或代表用户)的提问或陈述。
- System(系统) ------应用本身给 LLM 的指令。
- Assistant(助手) ------LLM 的响应内容。
- Tool(工具) ------调用外部工具以执行某些操作或获取额外上下文的指令。
现在我们先聚焦 user 与 system 消息。assistant 消息在与 LLM 的多轮对话 中才会用到,第 5 章会详细讨论。第 6 章则会看到 tool 消息如何通过对接 API 让 AI 交互更具动态性。
NOTE 并非所有 LLM API 都支持相同的消息角色选择。如果某个 API 不支持 System 角色,Spring AI 会把原本用于 System 角色的文本直接合并进 User 消息里。
到目前为止,我们一直通过 user() 方法来指定提示,也就是说,这些提示在语义上都属于用户消息。例如,在当前代码基础上询问"checkers(跳棋)有多少棋子",Spring AI 会向 OpenAI 发送如下 JSON(作为 POST 请求体):
swift
{
"messages": [
{
"content": "You are a helpful assistant, answering questions about
tabletop games.\nIf available, use the rules in the RULES section
below.\nIf you don't know anything about the game or don't know the
answer,\nsay "I don't know".\n\nThe game is checkers.\n\nThe
question is: How many pieces are there?.\n\nRULES:\n",
"role": "user"
}
],
"model": "gpt-4o",
"stream": false,
"temperature": 0.7
}可以看到这里只有一条消息,内容是整个提示,角色是 user 。这能工作,但还能更好。
检查 Spring AI 的请求与响应
如果你想查看使用 Spring AI 提交提示时的原始请求与响应 JSON ,可以在项目里加入 Logbook(github.com/zalando/log...)依赖:
arduino
implementation 'org.zalando:logbook-spring-boot-starter:3.9.0'该依赖会为 Spring 自动配置一些组件,用来拦截并记录通过这些组件发起的 HTTP 请求与返回的响应。
Spring AI 的 ChatClient 底层用的是 Spring 的 RestClient ,因此你需要声明一个 RestClientCustomizer bean,把 Logbook 的 LogbookClientHttpRequestInterceptor 加为请求拦截器:
typescript
@Bean
RestClientCustomizer logbookCustomizer(
LogbookClientHttpRequestInterceptor interceptor) {
return restClient -> restClient.requestInterceptor(interceptor);
}Logbook 以 TRACE 级别记录请求与响应细节,因此需要在 application.properties 中设置日志级别:
makefile
logging.level.org.zalando.logbook: TRACE默认情况下,Logbook 以 JSON 格式输出日志,可读性一般;可选地,你可以把 logbook.format.style 设为 http 来提升可读性:
ini
logbook.format.style=http配置完成后,Spring AI 与各 AI API 之间的请求与响应都会被记录,便于检查。需要注意:Spring AI 的 Gemini 模块使用 Google 自有的 HTTP 客户端库而非 RestClient,因此如果选择 Google Gemini 作为 LLM,Logbook 将无法拦截其请求。
如图 3.3 所示,我们可以把消息内容拆成两条:其中大部分文本实际是给 LLM 的指令 ,用于指导它如何回答用户问题,因此更合适做成 system 消息;真正来自用户的只有那个问题本身。
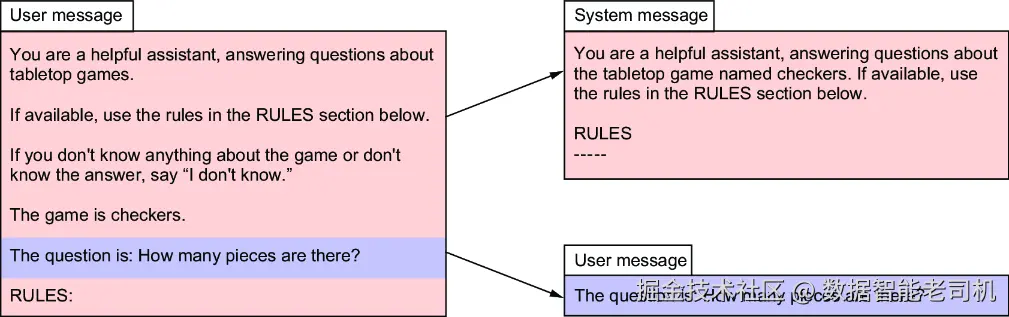
图 3.3 将原先的用户消息拆分为独立的 system 与 user 消息
要把这个变更应用到项目中,先在模板目录新增一个 systemPromptTemplate.st 文件,用它替代原先的 questionPromptTemplate.st(后者不再使用,可以删除)。新的 system 模板内容如下:
markdown
You are a helpful assistant, answering questions about the tabletop
game named {gameTitle}. If available, use the rules in the RULES
section below.
Answer in complete sentences.
RULES
-----
{rules}接下来需要调整 SpringAiBoardGameService,让它使用这个新模板 而非旧的 question 模板。用下面的字段替换掉类中现有的模板 Resource 属性:
kotlin
@Value("classpath:/promptTemplates/systemPromptTemplate.st")
Resource promptTemplate;最后,对 askQuestion() 方法做一些变更以使用新模板。新版本如下(清单 3.4 将提示拆分为独立的 user 与 system 消息):
less
@Override
public Answer askQuestion(Question question) {
var gameRules = gameRulesService.getRulesFor(question.gameTitle());
var answerText = chatClient.prompt()
.system(systemSpec -> systemSpec #1
.text(promptTemplate)
.param("gameTitle", question.gameTitle())
.param("rules", gameRules))
.user(question.question()) #2
.call()
.content();
return new Answer(question.gameTitle(), answerText);
}具体而言:模板通过 system 消息规格的 text() 提供(而不是先前的 user 规格),用于填充占位符的参数也同理。至于 user 消息,再次仅使用用户问题的文本本身。
user 与 system 消息的先后顺序并不重要;无论顺序如何,它们最终都会出现在发给 LLM 的请求中。
完成这些修改后,重启应用再试一次。表面上仍与之前一致,但底层发往 OpenAI 的请求现在包含两条明确分离的消息:一条是 system 指令 ,一条是 user 提问:
swift
{
"messages": [
{
"content": "How many pieces are there?",
"role": "user"
},
{
"content": "You are a helpful assistant, answering questions about the
tabletop\ngame named checkers. If available, use the rules in the
RULES section below.\n\nRULES\n-----\n",
"role": "system"
}
],
"model": "gpt-4o",
"stream": false,
"temperature": 0.7
}尽管我们目前的示例可能过于简单,不足以体现"角色"带来的明显差异,但总体而言,合理使用角色有助于 LLM 生成更优的响应。随着提示复杂度提高,这种积极作用会更加显著。
到现在为止,我们关注的是如何创建并发送 提示给 LLM 进行生成。接下来把注意力转到对话的另一端:学习如何告知 LLM 我们希望以何种形式接收生成的响应。
3.4 影响响应生成(Influencing response generation)
Spring AI 提供了几项很实用的功能,用来影响响应返回的方式,包括:
- 设置生成选项:在生成响应时,对"下一枚 token 的选择"施加一定控制。
- 输出转换(output conversion) :在提示中加入格式化指令,告诉 LLM 按特定格式返回,以便把文本响应转换成 Java 对象。
- 流式传输 :让结果一点点 返回,而不是等待一次性返回完整响应。
下面从把响应绑定为 Java 对象开始,逐一介绍这些功能。
3.4.1 指定聊天选项(Specifying chat options)
在使用生成式 AI 时,你可能会发现 LLM 的回答并不总如预期。模型巨大的训练规模,加上生成过程的非确定性,有时会产生不那么理想的结果。
Spring AI 提供了若干属性,让你"调参"以影响 LLM 处理提示的方式。你已在第 1 章见过一个:在 application.properties 中覆盖默认模型为 gpt-4.1-nano:
ini
spring.ai.openai.chat.options.model=gpt-4.1-nanoSpring AI 支持的各类 API 都有类似属性来指定模型。例如,使用 Ollama 时选择 Llama 3.2:
ini
spring.ai.ollama.chat.options.model=llama3.2这两行的关键区别(除模型名外)在于:一行对应 OpenAI 的 API,另一行对应 Ollama 的 API。以这种方式设置聊天选项时,请确保使用与你所用 API 匹配的属性前缀。
多数聊天选项都可以在 application.properties 里设置;也可以在创建 ChatClient 时通过 defaultOptions() 设为默认值。例如,创建 ChatClient 时指定 gpt-4.1-nano:
ini
ChatOptions chatOptions = ChatOptions.builder()
.model("gpt-4.1-nano")
.build();
ChatClient chatClient = chatClientBuilder
.defaultOptions(chatOptions)
.build();通过 defaultOptions() 设置的选项会覆盖 在 application.properties 里同名的配置;而这些默认选项又可以在创建提示 时通过 options() 继续覆盖,例如:
scss
String answerText = chatClient.prompt()
.user(question.question())
.options(chatOptions)
.call()
.content();选择模型只是众多聊天选项之一。不同生成式 API 支持的选项并不完全相同,但有若干核心选项是普遍存在的。先看一组会影响"如何逐 token 选取"的选项。
调整"多样性/随机性"(Adjusting variability)
响应生成是逐 token 进行的:先考虑原始提示,然后由 API 基于模型选择下一枚 token;接着再选下一枚,直到完整响应生成完毕。
选择"下一枚 token"的方法可理解为统计概率 + 随机选择 的组合。模型会给出若干候选 token,每个都有成为下一枚 token 的概率。以概率为权重做一次随机选择:概率高的更容易被选中,但所有候选都有被选中的可能。
例如提示为:"Finish this sentence: I have a large collection of." 为了便于理解,我们先用词 代替 token 来思考。假设候选词及其概率如下:
- "books" - 0.475
- "coins" - 0.236
- "records" - 0.129
- "arts" - 0.096
- "stamps" - 0.064
基于以上权重,books 被选中的概率约是 coins 的两倍、是 stamps 的七倍多。多次提交相同提示,大多数结果会以 books 完成句子,coins/records/arts/stamps 偶尔出现,且频率逐步降低。
通过 temperature、Top-p、Top-k 等选项,你可以影响选择的随机性以及不同 token 被选中的相对可能性:
- temperature(温度) :范围 0--2 ,对概率施加缩放。直觉上,温度越高 ,结果越随机 ;温度越低 ,结果越确定 (见图 3.4)。当温度趋近 2,各 token 概率趋于平均;当温度趋近 0,最高概率 token 的概率趋近 1,其他趋近 0;温度为 1 时概率不变。
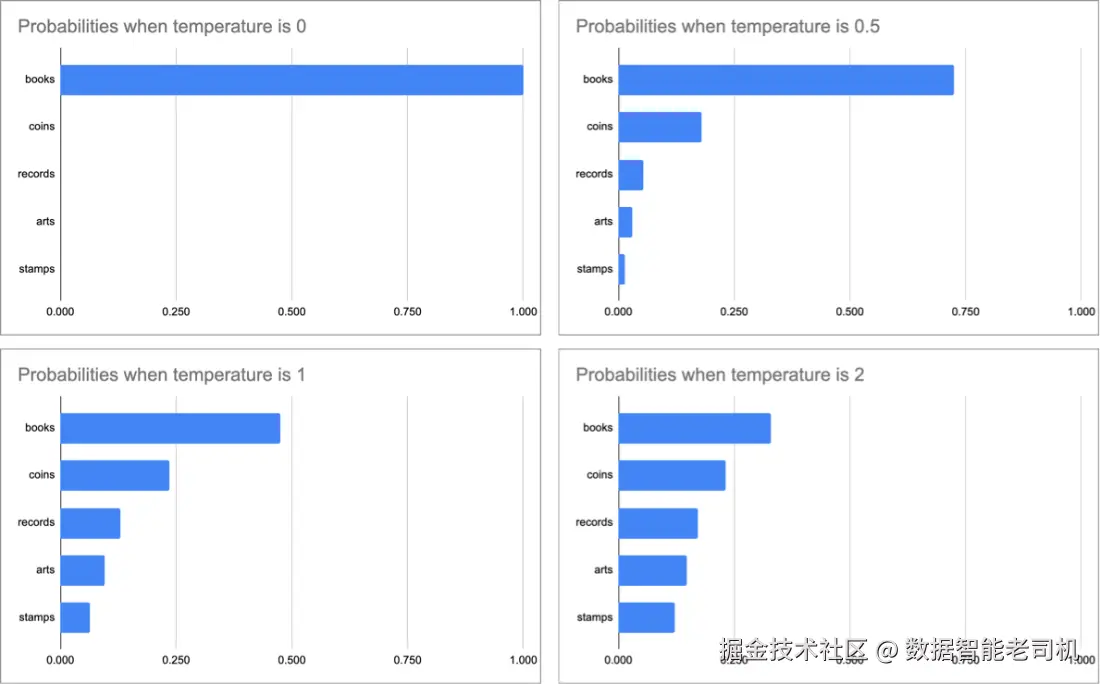
图 3.4 温度越高,概率越均匀,结果更随机;温度越低,概率差异被放大,结果更确定。
在 application.properties 中可按所用 API 设置温度。例如 OpenAI 设为 0.7:
ini
spring.ai.openai.chat.options.temperature=0.7或在代码里通过 ChatOptions 指定:
ini
ChatOptions chatOptions = ChatOptions.builder()
.temperature(0.7)
.build();- Top-P(核采样) :范围 0--1 ,保留累计概率 达到阈值的最小候选集合 ,其余全部剔除。
例如 Top-P=0.8,如图 3.5,books+coins+records的累计概率为 0.84,达到阈值,于是 arts/stamps 被剔除;随后对保留集合的概率归一化再做加权随机选择。
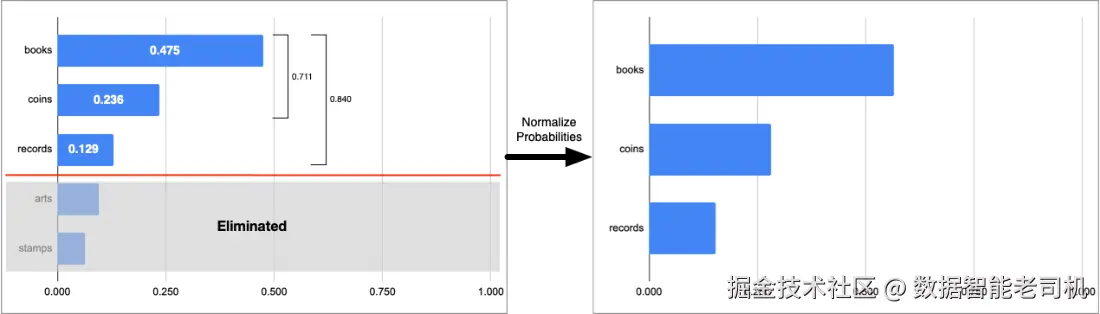
图 3.5 Top-P 根据高排名 token 的累计概率阈值,剔除其余候选。
在 OpenAI 下用属性设置:
ini
spring.ai.openai.chat.options.top-p=0.8或代码设置:
ini
ChatOptions chatOptions = ChatOptions.builder()
.topP(0.8)
.build();通常建议二选一 :使用 temperature 或 Top-P。两者同时使用是允许的,但不一定更好。
- Top-K :与 Top-P 类似,但用计数 而非累计概率,直接保留前 K 个 候选。OpenAI 不支持 Top-K ,因此无法在 OpenAI 上调整它;Ollama 支持,可在配置中设置:
ini
spring.ai.ollama.chat.options.top-k=4或在代码中:
ini
ChatOptions chatOptions = ChatOptions.builder()
.topK(4)
.build();若你在 ChatOptions 里设置了 Top-K 却把提示发给 OpenAI,将会收到"不支持 Top-K"的错误。
应用到前述"收藏"示例上,若 top-k=4,则 books/coins/records/arts 被保留,stamps 被剔除;随后同样进行概率归一化并随机选择。
像 temperature、Top-P、Top-K 这样的选项,可以在 LLM 生成响应时对其"选择过程"施加一定控制。接下来我们看看输出转换(output conversion) ,如何让生成结果直接落地为一个 Java 对象。
3.4.2 格式化响应输出(Formatting response output)
到目前为止,我们的应用会显式地从 LLM 返回的响应中提取文本内容 ,并据此创建一个 Answer 对象。就目前这个简单的 Answer 记录类型而言,这并不难。但可以想见,若响应更复杂,"先提取再实例化"的代码会变得臃肿。幸运的是,Spring AI 提供了**输出转换(output conversion)**辅助,用于把 LLM 的响应映射为 Java 对象。
为了演示输出转换如何工作,先看看如何让 ChatClient 直接返回 Answer 对象 ,而不是字符串。为此,需要把 askQuestion() 方法改为请求实体对象。
清单 3.5 将 LLM 结果直接获取为 Answer 对象
kotlin
package com.example.boardgamebuddy;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.core.io.Resource;
import org.springframework.stereotype.Service;
@Service
public class SpringAiBoardGameService implements BoardGameService {
private final ChatClient chatClient;
private final GameRulesService gameRulesService;
public SpringAiBoardGameService(
ChatClient.Builder chatClientBuilder,
GameRulesService gameRulesService) {
this.chatClient = chatClientBuilder.build();
this.gameRulesService = gameRulesService;
}
@Value("classpath:/promptTemplates/systemPromptTemplate.st")
Resource promptTemplate;
@Override
public Answer askQuestion(Question question) {
var gameRules = gameRulesService.getRulesFor(question.gameTitle());
return chatClient.prompt()
.system(systemSpec -> systemSpec
.text(promptTemplate)
.param("gameTitle", question.gameTitle())
.param("rules", gameRules))
.user(question.question())
.call()
.entity(Answer.class);
}
}askQuestion() 的工作方式几乎与之前完全相同,只是有一个不太显眼的变化:不再调用 content(),而是调用 entity(),并传入 Answer.class 指明期望的响应类型。
这个小改动带来两点变化:
- 格式化指令会被加入到提示中;
- 返回的响应会被解析为对象。
在提示发送给 LLM 之前,Spring AI 会装饰 提示,加入格式化指令 ,告诉模型响应应采用何种格式。该格式由 Answer 记录及其属性推导而来。如果你拦截请求并查看细节,会看到类似如下的格式化指令:
vbscript
Your response should be in JSON format.
Do not include any explanations, only provide a RFC8259 compliant JSON
response following this format without deviation.
Do not include markdown code blocks in your response.
Here is the JSON Schema instance your output must adhere to:
```{
"$schema" : "https://json-schema.org/draft/2020-12/schema",
"type" : "object",
"properties" : {
"answer" : {
"type" : "string"
},
"gameTitle" : {
"type" : "string"
}
}
}```这里的格式说明精确告知 LLM:应按 JSON 对象返回,并附上了 JSON Schema。
当响应返回时,这个 JSON 对象会被转换 成所需类型------此处为 Answer。
NOTE 即使 Spring AI 的输出转换负责生成了格式化指令,也不保证 一定有效。有些 LLM 并不遵循格式要求,仍会随意返回答案。OpenAI 的 GPT 模型通常执行得不错,但其他模型(如 Mistral 7B )可能不行。如果所用 LLM 不遵守格式,结果就无法可靠 地转换并绑定到对象;这种情况下,当 Spring AI 尝试把"非 JSON 响应"绑定到对象时,会抛出 JsonParseException。
就是这样!现在 Spring AI 的输出转换会负责创建 Answer 对象------它之所以能做到,是因为它首先生成了指令,告诉 LLM 按 JSON 对象格式返回结果。
将输出解析为列表(Parsing output to a list)
Spring AI 也能把响应解析为 List<String>。当你预期响应是一个"条目列表"时,这很适合,比如游乐园景点清单、联赛球队名单、或 Billboard Hot 100 的年度十大金曲。
为演示如何拿到列表响应,我们创建一个新的控制器(如下清单),按给定年份返回前 10 首歌曲:
清单 3.6 返回某年份热门歌曲 Top 10 的控制器
kotlin
package com.example.topsongs;
import java.util.List;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.core.ParameterizedTypeReference;
import org.springframework.core.io.Resource;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class TopSongsController {
@Value("classpath:/top-songs-prompt.st")
Resource topSongPromptTemplate; #1
private final ChatClient chatClient;
public TopSongsController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder.build();
}
@GetMapping(path = "/topSongs", produces = "application/json")
public List<String> topSongs(@RequestParam("year") String year) {
return chatClient.prompt()
.user(userSpec -> userSpec
.text(topSongPromptTemplate)
.param("year", year))
.call()
.entity(new ParameterizedTypeReference<List<String>>() {}); #2
}
}为简单起见,这里直接在控制器中使用 ChatClient,而不是像 SpringAiBoardGameService 那样抽到单独的服务类。
提示模板定义在 src/main/resources/top-songs-prompt.st,并作为 Resource 注入控制器。模板内容如下:
sql
What were the top 10 songs on the Billboard Hot 100 in {year}?
Each item should only include the song title.该控制器与之前在 SpringAiBoardGameService 中见到的代码很相似,但有一点不同:调用 entity() 时传入了 new ParameterizedTypeReference<List<String>>() {}。我们期望的结果是 List<String>,但不能直接把 List 或 List<String> 传给 entity()。ParameterizedTypeReference 是一种特殊的类型引用,能在 Java 的类型擦除 下,仍携带泛型实参 传给方法(如 entity())。
由于向 entity() 传入了 new ParameterizedTypeReference<List<String>>() {},提示会被赋予如下的格式化指令:
makefile
FORMAT: Your response should be a list of comma separated values
eg: `foo, bar, baz`运行应用后,可用 HTTPie 试试,例如:
bash
$ http :8080/topSongs?year=1981 -b
[
"Bette Davis Eyes",
"Endless Love",
"Lady",
"(Just Like) Starting Over",
"Jessie's Girl",
"Celebration",
"Kiss On My List",
"I Love A Rainy Night",
"9 To 5",
"Keep On Loving You"
]太好了!快速搜一下可确认这些确实是 1981 年的前十热单。当然,准确性 取决于你所选 LLM 的训练质量(上述列单由 OpenAI 的 gpt-4o 返回)。但更重要的是,得益于列表输出转换,响应被格式化为一个值列表。
虽然把响应格式化为 Java 对象或列表很有用,但有时候纯文本 就够了,只是你希望它在生成时逐步返回 。接下来看看如何使用另一种 Spring AI 聊天客户端,把结果流式返回给调用方。
3.4.3 流式返回响应(Streaming the response)
如果你用过 OpenAI 的 ChatGPT、微软 Copilot 等聊天客户端,你就体验过"聊天式界面"的 LLM 交互。你也会注意到:LLM 的回答像"在打字"一样,逐步流入对话窗口。
流式响应的关键好处是:提升聊天应用的用户体验 。简单回答可能很快返回,但复杂回答需要更长的生成时间。如果能在生成过程中逐步渲染 ,用户就能确信应用在工作而非"卡住"。
Spring AI 在使用 ChatClient 时支持这种流式风格 。下面的清单展示了:只需对 askQuestion() 做少量修改,就能以流的方式取回结果。
清单 3.7 流式返回的棋盘游戏服务
less
@Override
public Flux<String> askQuestion(Question question) { #1
var gameRules = gameRulesService.getRulesFor(question.gameTitle());
return chatClient.prompt()
.system(systemSpec -> systemSpec
.text(promptTemplate)
.param("gameTitle", question.gameTitle())
.param("rules", gameRules))
.user(question.question())
.stream() #2
.content();
}与先前版本相比,关键差异在于:该方法的返回类型是 Flux<String>,且不再调用 call(),而是调用 stream()。等等,Flux 是什么?
Flux 来自 Project Reactor (projectreactor.io/),是 Spring 响应式栈的基础库。更多内容可参考《Spring in Action》(www.manning.com/books/sprin...),从第 5 版起其中就有专章讲解 Reactor 以及 Flux / Mono。
此处只需理解:Flux 是一种响应式类型 ,会在数据可用时流式 地产生 0 到多条数据。对 LLM 的生成响应而言,Flux 通常会按词粒度(或短片段)不断推送内容。
你还需要修改 AskController,让它返回服务方法返回的 Flux。如下:
清单 3.8 流式的 AskController
kotlin
package com.example.boardgamebuddy;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
@RestController
public class AskController {
private final BoardGameService boardGameService;
public AskController(BoardGameService boardGameService) {
this.boardGameService = boardGameService;
}
@PostMapping(path="/ask", produces="application/json")
public Flux<String> ask(@RequestBody Question question) {
return boardGameService.askQuestion(question);
}
}ask() 方法还有一个小改动:@PostMapping 需声明返回流式响应 ,其 MIME 一般设为 text/event-stream。这一点很重要:如果仍是 application/json,结果会一次性返回,而不是流式返回。
你可以像之前一样用 HTTPie 试试。因为流式响应通常很快返回,除非答案较长,否则你可能不明显地感受到"流动"。比如询问 Burger Battle 的战斗卡列表:
kotlin
$ http :8080/ask gameTitle="Burger Battle" \
question="What battle cards are there?" -b
data:
data:Here
data: is
data: a
data: list
data: of
data: the
data: Battle
data: Cards
...为避免篇幅过长,这里只展示前几项。显然,响应是逐词 流回,而非一次性返回。尽管输出不容易看出,但每个词之间有小延迟,就像 LLM 正在"打字"。
text/event-stream 的一个副作用是:每个词前会带上 data: 前缀,因此调用方需要能够剥离该前缀以取出真正的词。
为了避免对每个词做特殊处理,可以把 @PostMapping 的 produces 改为 application/ndjson(换行分隔 JSON):
ini
@PostMapping(path = "/ask", produces = "application/ndjson")此时,LLM 仍会逐词 流回,但不再带 data: 前缀。
如果用 HTTPie 测试这个 MIME,更可能会以为"流式坏了"。因为 HTTPie 遇到 text/event-stream 时会默认 按流处理,但对 application/ndjson 并不会。要启用流式显示,需加 --stream:
ini
$ http :8080/ask gameTitle="Burger Battle" \
question="What battle cards are there?" -b --stream --pretty none #1输出(此处为节选)类似:
python
In Burger Battle there are several Battle Cards that players can use. Here
is a list of the standard Battle Cards:
1. **Burger Bomb**: Blow up another player's Burger by sending their
ingredients to the Graveyard.
2. **Burger Force Field**: Your Burger is now protected from all Battle
Cards.
3. **Burgerpocalypse**: Obliterate all players' ingredients, including your
own, and toss them in the Graveyard.
4. **Destroy!**: Destroy any Battle Card of yours or another player's and
toss it in the Graveyard.
5. **Gonna Eat That?**: Steal another player's ingredient and add it to your
Burger.
...再次强调:书页静态展示不明显,但实际使用 HTTPie 时,响应是带小延迟 地流回的。虽然底层仍是逐词 流式,HTTPie 会缓冲这些词,直到凑成一整行再打印。
你也许会问:能否把流式响应 与前面用到的输出转换 结合起来?理论上,流式客户端可以像处理纯文本一样流式返回JSON 文本 ;但流回的 JSON 会被拆成词或符号 ,在完整 响应结束前,你并没有一个完备的 JSON 文档可以解析。
因此,你必须先收集 完整的流式 JSON 字符串,再交给输出转换去处理------这等于违背 了使用流式的初衷。简言之,不要混用"流式 + 输出转换"。
在本章中,你已经看到如何使用 Spring AI 将提示提交给 LLM 进行生成;使用提示模板 实现"填空式"提示;用上下文填充 提示;利用提示角色 ;以及影响响应生成 的方式。收尾之前,我们再看看如何检查模型可能随响应一并返回的响应元数据。
3.5 使用响应元数据(Working with response metadata)
除了拿到生成结果外,ChatClient 还可以提供与 LLM 交互的一些有用元数据 。其中最有用的是用量(usage)统计 。每个提示和每段生成的响应最终都会被拆分成若干 token。这些 token(以及其他因素)会用于计算你向 AI 服务支付的费用。因此,了解每次请求消耗了多少 token,有助于你评估与 LLM 的交互成本。
如何使用 token 用量信息取决于你自己。最基本的做法是把这些信息简单地写入应用日志 。在第 9 章,你会看到如何借助 Spring AI 的可观测性功能,对外暴露 token 用量与其他指标。
清单 3.9 记录 token 用量到日志
kotlin
package com.example.boardgamebuddy;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.ResponseEntity;
import org.springframework.ai.chat.metadata.ChatResponseMetadata;
import org.springframework.ai.chat.metadata.Usage;
import org.springframework.ai.chat.model.ChatResponse;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.core.io.Resource;
import org.springframework.stereotype.Service;
@Service
public class SpringAiBoardGameService implements BoardGameService {
private static final Logger log =
LoggerFactory.getLogger(SpringAiBoardGameService.class);
private final ChatClient chatClient;
private final GameRulesService gameRulesService;
public SpringAiBoardGameService(
ChatClient.Builder chatClientBuilder,
GameRulesService gameRulesService) {
this.chatClient = chatClientBuilder.build();
this.gameRulesService = gameRulesService;
}
@Value("classpath:/promptTemplates/systemPromptTemplate.st")
Resource promptTemplate;
@Override
public Answer askQuestion(Question question) {
var gameRules = gameRulesService.getRulesFor(question.gameTitle());
var responseEntity = chatClient.prompt()
.system(systemSpec -> systemSpec
.text(promptTemplate)
.param("gameTitle", question.gameTitle())
.param("rules", gameRules))
.user(question.question())
.call()
.responseEntity(Answer.class);
var response = responseEntity.response();
var metadata = response.getMetadata();
logUsage(metadata.getUsage());
return responseEntity.entity();
}
private void logUsage(Usage usage) {
log.info("Token usage: prompt={}, generation={}, total={}",
usage.getPromptTokens(),
usage.getCompletionTokens(),
usage.getTotalTokens());
}
}askQuestion() 方法和之前相比略有不同。关键差异在于:它不再调用 content() 或 entity() 获取响应,而是调用 responseEntity()。该方法与 entity() 类似,会把响应绑定 为指定类型的对象(这里是 Answer);但不同的是,它返回的是一个 ResponseEntity<ChatResponse, Answer>,其中既包含 Answer,也携带一个 ChatResponse 对象。
ChatResponse 对象中可以找到元数据 。调用 getMetadata() 可获取用量信息,从而在 ask() 方法(此处为 askQuestion())中把它传给 logUsage() 进行日志记录。随后,askQuestion() 返回 ResponseEntity 中承载的 Answer。
完成这些修改后,像之前一样启动应用并向 /ask 发送请求。你应该会在日志里看到类似如下的记录:
ini
Token usage: prompt=1618, generation=35, total=1653为突出重点,这里只展示了日志消息本身。实际的 token 数会因提问与回答而变化。但可以看到,日志为你提供了有价值的洞察:使用了多少 token(进而可用于估算费用)。
需要注意:并非所有 AI 服务都会返回用量指标。例如,发送给本地 Ollama 的 LLM 提示不会提供用量数据。Mistral AI 也是一个似乎不返回用量数据的服务。但你通常可以从 OpenAI、Anthropic、Google(以及可能的其他服务)拿到用量数据。
总结
- 提示模板让你可以定义并外部化通用提示,在提交生成前用具体内容填充。
- 模板也支持向提示中提供额外上下文,以使生成更聚焦、更准确。
- 上下文可包含输出格式化指令,例如要求以 JSON 返回,以便绑定到 Java 对象。
- 输出转换 可以把 LLM 的生成结果解析为 Java 对象 或列表。
- 响应可以流式返回给客户端,模拟"思考与打字"的体验。
- 生成响应中可能包含有用的元数据 ,如 token 用量 等指标。