双向链表是一种基础且重要的数据结构,每个节点不仅包含数据,还包含指向前一个节点和后一个节点的指针。这种结构使得双向链表在插入和删除操作上,尤其是在已知节点位置时,比单向链表更具优势。
本文将聚焦于删除操作,带你从基本概念出发,逐步深入到边界处理和应用实践。
第一部分:基础篇 ------ 删除节点的核心逻辑
在双向链表中删除一个节点,核心在于"重新布线",将被删除节点前后两个节点连接起来,然后安全地释放该节点。
假设我们有一个简单的节点定义:
cpp
struct ListNode {
int val;
ListNode* prev; // 指向前一个节点
ListNode* next; // 指向后一个节点
ListNode(int x) : val(x), prev(nullptr), next(nullptr) {}
};现在,假设我们要在链表中删除一个已知的节点 delNode。下图清晰地展示了这一过程:
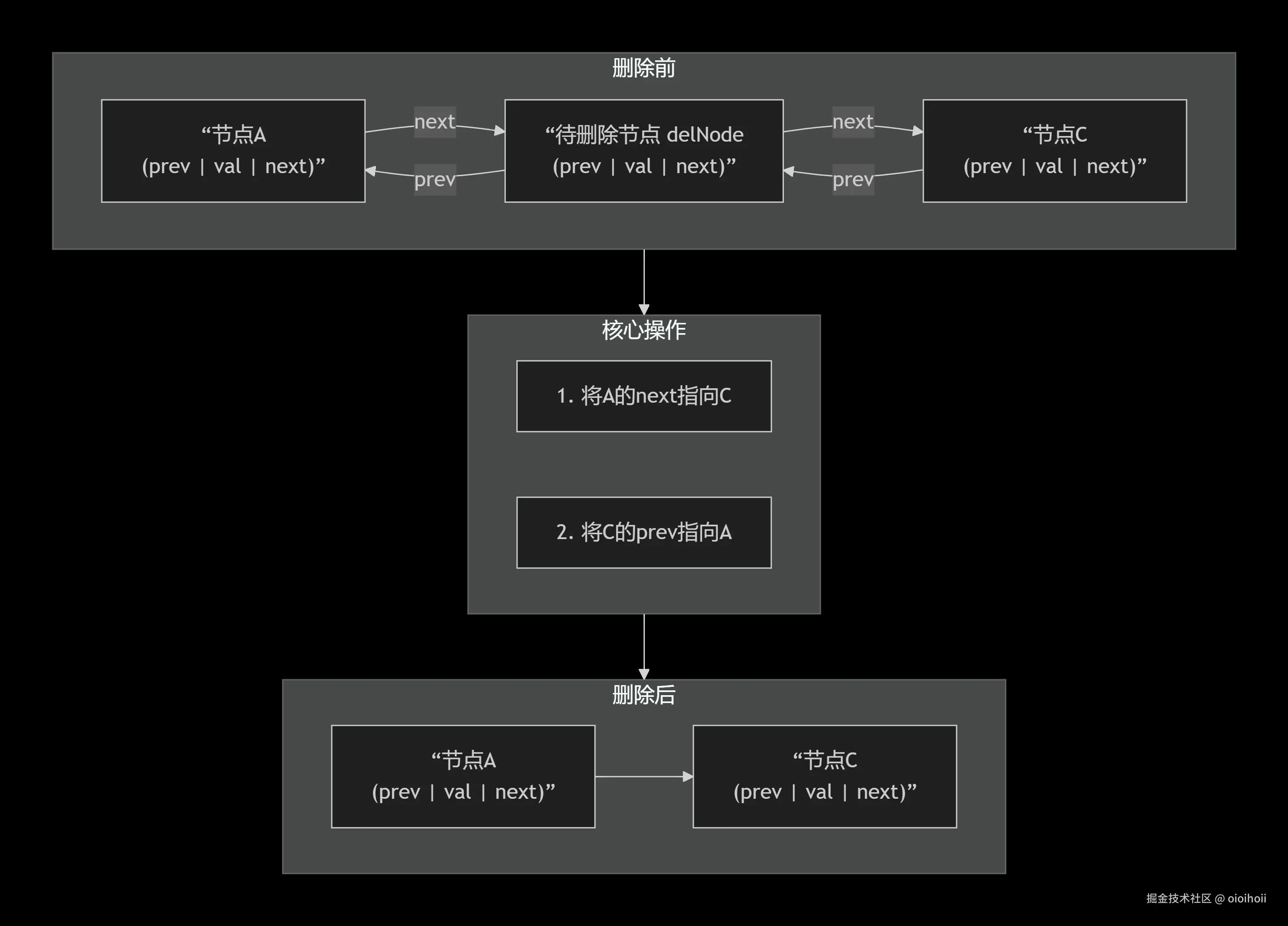
根据图示,我们可以将其转化为代码:
cpp
// 前提:delNode 不是空指针,且存在于链表中
void deleteNode(ListNode* delNode) {
// 1. 处理前驱节点的next指针
if (delNode->prev != nullptr) {
delNode->prev->next = delNode->next;
}
// 2. 处理后继节点的prev指针
if (delNode->next != nullptr) {
delNode->next->prev = delNode->prev;
}
// 3. 安全删除节点
delete delNode;
}关键点:
- 我们必须检查
delNode->prev和delNode->next是否为空,因为要删除的节点可能是头节点或尾节点。 - 操作顺序很重要,但在此例中,只要在解除链接前获取了必要的信息,顺序可以调整。
第二部分:进阶篇 ------ 处理边界情况与设计封装
基础的删除逻辑很简单,但一个健壮的链表实现需要 meticulously (一丝不苟地) 处理各种边界情况。
情况一:删除头节点
如果 delNode 是链表的头节点,在删除后,链表的头指针需要被更新。
cpp
void deleteNode(ListNode** head_ref, ListNode* delNode) {
// 检查空指针
if (*head_ref == nullptr || delNode == nullptr) return;
// 如果删除的是头节点,则需要更新头指针
if (*head_ref == delNode) {
*head_ref = delNode->next; // 新的头节点是原头的下一个
}
// ... (接下来的连接操作与基础篇相同)
if (delNode->next != nullptr) {
delNode->next->prev = delNode->prev;
}
if (delNode->prev != nullptr) {
delNode->prev->next = delNode->next;
}
delete delNode;
}情况二:删除尾节点
如果 delNode 是尾节点,我们只需要更新它前一个节点的 next 指针为 nullptr。基础代码中的 if (delNode->next != nullptr) 已经完美处理了这种情况,防止了访问空指针的 prev。
情况三:删除唯一节点
如果链表只有一个节点,那么删除它后,头指针需要被置为 nullptr。上面的代码同样可以处理:它首先将 *head_ref 设置为 delNode->next(也就是 nullptr),然后进行连接操作(因为 prev 和 next 都是 nullptr,所以 if 内的语句不会执行)。
第三部分:实践篇 ------ 完整的链表类与复杂删除
让我们在一个简单的双向链表类中实现删除功能,并探讨更复杂的场景。
cpp
class DoublyLinkedList {
private:
ListNode* head;
public:
DoublyLinkedList() : head(nullptr) {}
// 删除指定值的第一个节点
void deleteByValue(int value) {
ListNode* current = head;
while (current != nullptr) {
if (current->val == value) {
// 找到节点,调用删除逻辑
if (current == head) {
head = head->next;
}
if (current->next != nullptr) {
current->next->prev = current->prev;
}
if (current->prev != nullptr) {
current->prev->next = current->next;
}
delete current;
return; // 只删除第一个找到的
}
current = current->next;
}
}
// 删除指定位置的节点 (索引从0开始)
void deleteByPosition(int position) {
if (head == nullptr || position < 0) return;
ListNode* current = head;
for (int i = 0; current != nullptr && i < position; i++) {
current = current->next;
}
// 如果current为空,说明位置超出链表长度
if (current == nullptr) return;
// 复用删除节点的核心逻辑
if (current == head) {
head = head->next;
}
if (current->next != nullptr) {
current->next->prev = current->prev;
}
if (current->prev != nullptr) {
current->prev->next = current->next;
}
delete current;
}
// 清空整个链表
void clear() {
while (head != nullptr) {
ListNode* temp = head;
head = head->next;
delete temp;
}
}
// ... 其他成员函数,如push_front, push_back, print等
};复杂删除场景:
-
清空链表: 如
clear()函数所示,它反复删除头节点,直到链表为空。这是一种高效且安全的方法。 -
在析构函数中调用: 一个良好的 C++ 链表类必须在析构函数中清理所有节点,防止内存泄漏。
cpp~DoublyLinkedList() { clear(); }
第四部分:深入理解 ------ 与单向链表删除的对比
这是理解双向链表优势的关键。
| 特性 | 单向链表 | 双向链表 |
|---|---|---|
| 删除给定节点 | O(n)。需要从头遍历以找到该节点的前驱节点。 | O(1) 。因为通过 prev 指针可以直接找到前驱节点。 |
| 删除头节点 | O(1) | O(1) |
| 删除尾节点 | O(n)。需要找到倒数第二个节点。 | O(1)。通过尾节点的 prev 直接找到前驱。 |
结论: 当操作涉及到反向遍历或已知节点位置而非仅值时的删除,双向链表的效率远高于单向链表。
总结
从最基础的"重新布线"逻辑,到处理头节点、尾节点等边界情况,再到封装成完整的类并与单向链表进行对比,我们对C++双向链表的删除操作进行了一次由浅入深的探索。
记住成为一名优秀C++程序员的关键:
- 始终注意内存管理 :
new和delete要成对出现。 - 严谨处理边界:头节点、尾节点、空链表是bug的高发区。
- 理解底层原理:明白指针是如何被操作的,才能写出正确、高效的代码。