本文是对《搞定系统设计:面试敲开大厂的门》第一章的学习和思考,同时也是对那道经典面试题"从输入URL到看到页面经历了哪些步骤"的回答。
设计一个支持数百万用户的系统具有挑战性,是一个需要持续完善和不断改进的过程。在这一章中,我们构建一个支持单个用户的系统,并逐渐扩展以服务数百万用户。
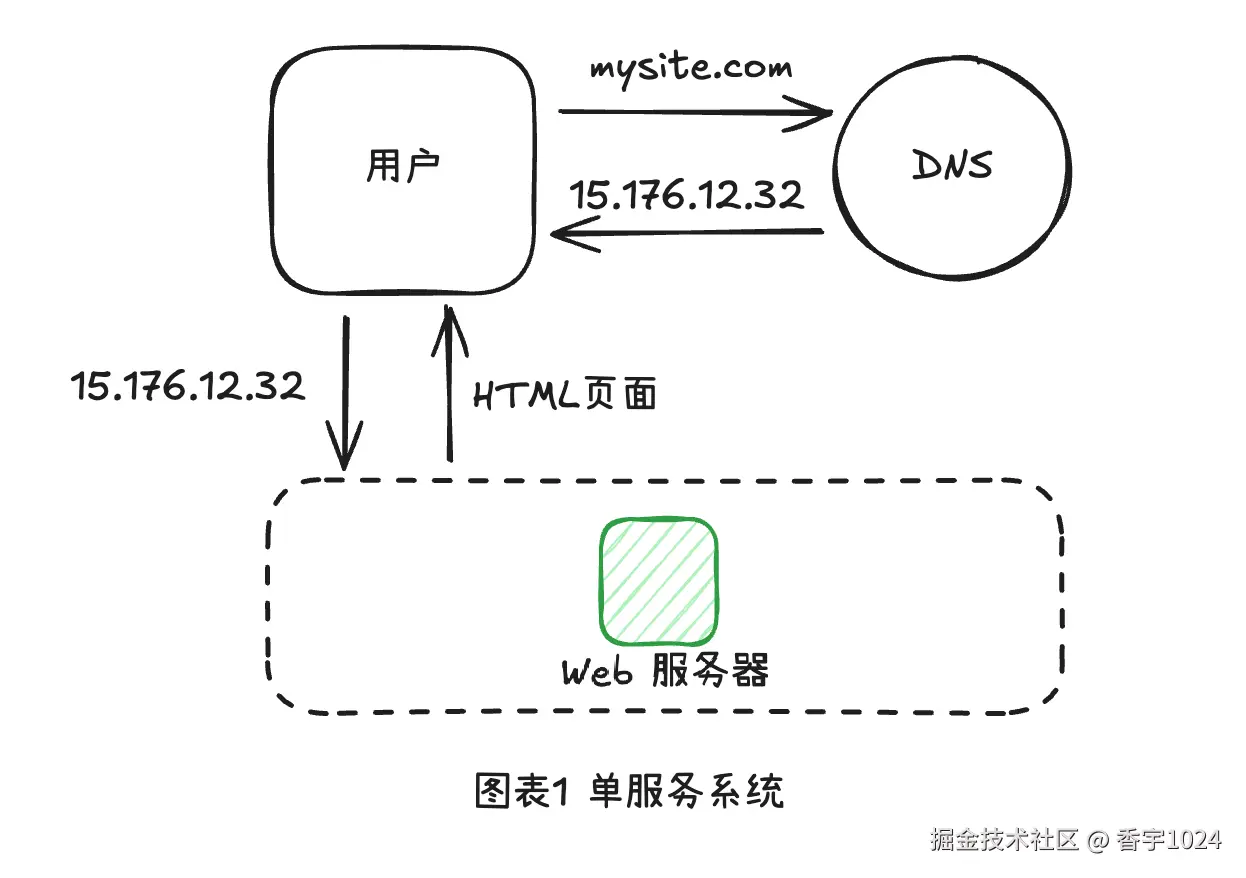
一、单服务系统
最基础的服务只需要一个Web服务器、域名和公网ip。浏览器根据域名,去DNS服务找到对应的公网ip,访问Web服务器,获取HTML页面。
二、数据库服务器
随着用户的增长,单个Web服务器已经不够了,我们需要一个数据库服务器。
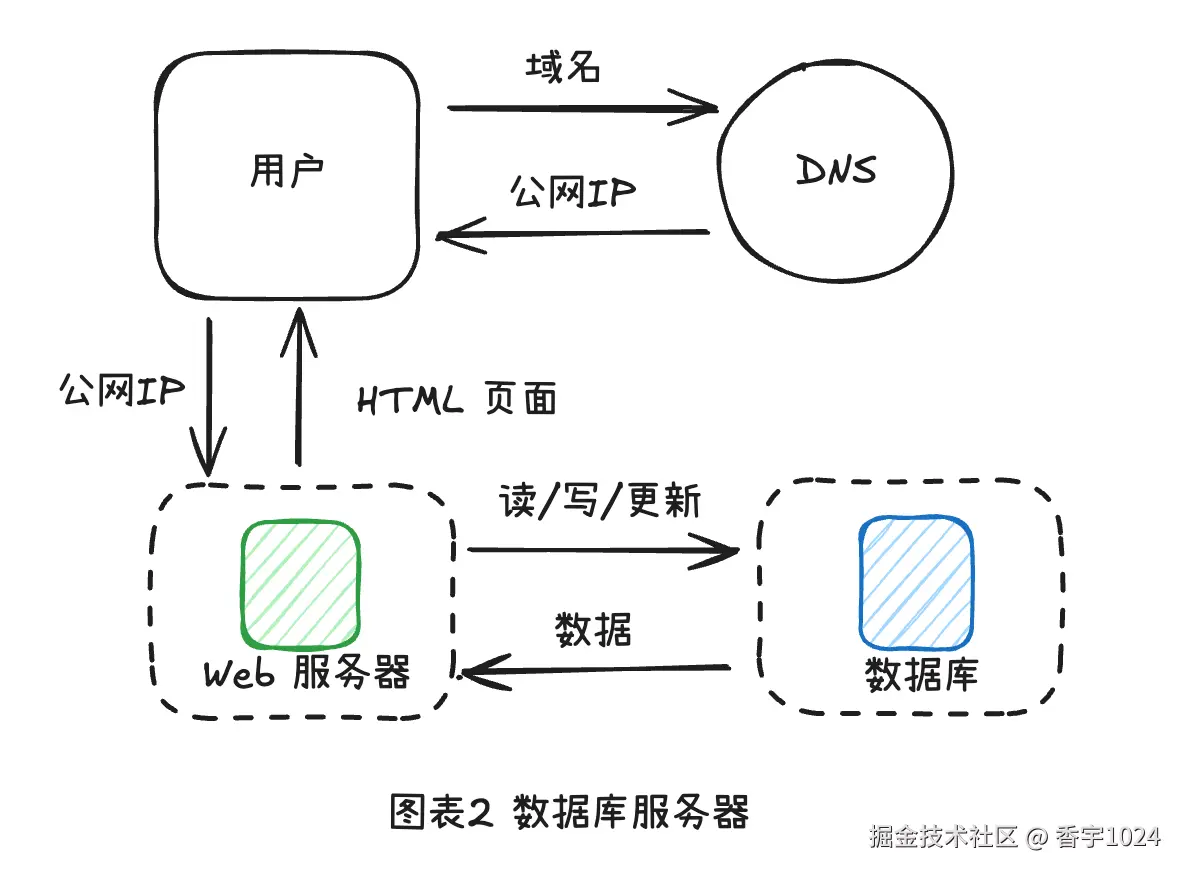
使用什么数据库? 你可以在传统关系型数据库和非关系型数据库之间进行选择。
关系型数据库也称为关系数据库管理系统(RDBMS)或SQL数据库。其中最流行的包括MySQL、Oracle数据库、PostgreSQL等。关系型数据库使用表格和行来表示和存储数据。你可以使用SQL在不同的数据库表之间执行连接操作。非关系型数据库也称为NoSQL数据库,分为四类:键值存储(用于存储缓存)、列存储(半结构存储,用于存储用户日志、用户画像)和文档存储(半结构存储,用于存博客、电商订单等,相比列存储最大的优势在于可以基于内容查询,而列存储只能基于key来查询)、图形存储(用于适合存储朋友关系)。
三、负载均衡器
数据库服务器有了,我们的系统涌入了更多用户,把Web服务器挤爆了,这个时候就轮到负载均衡上场了。
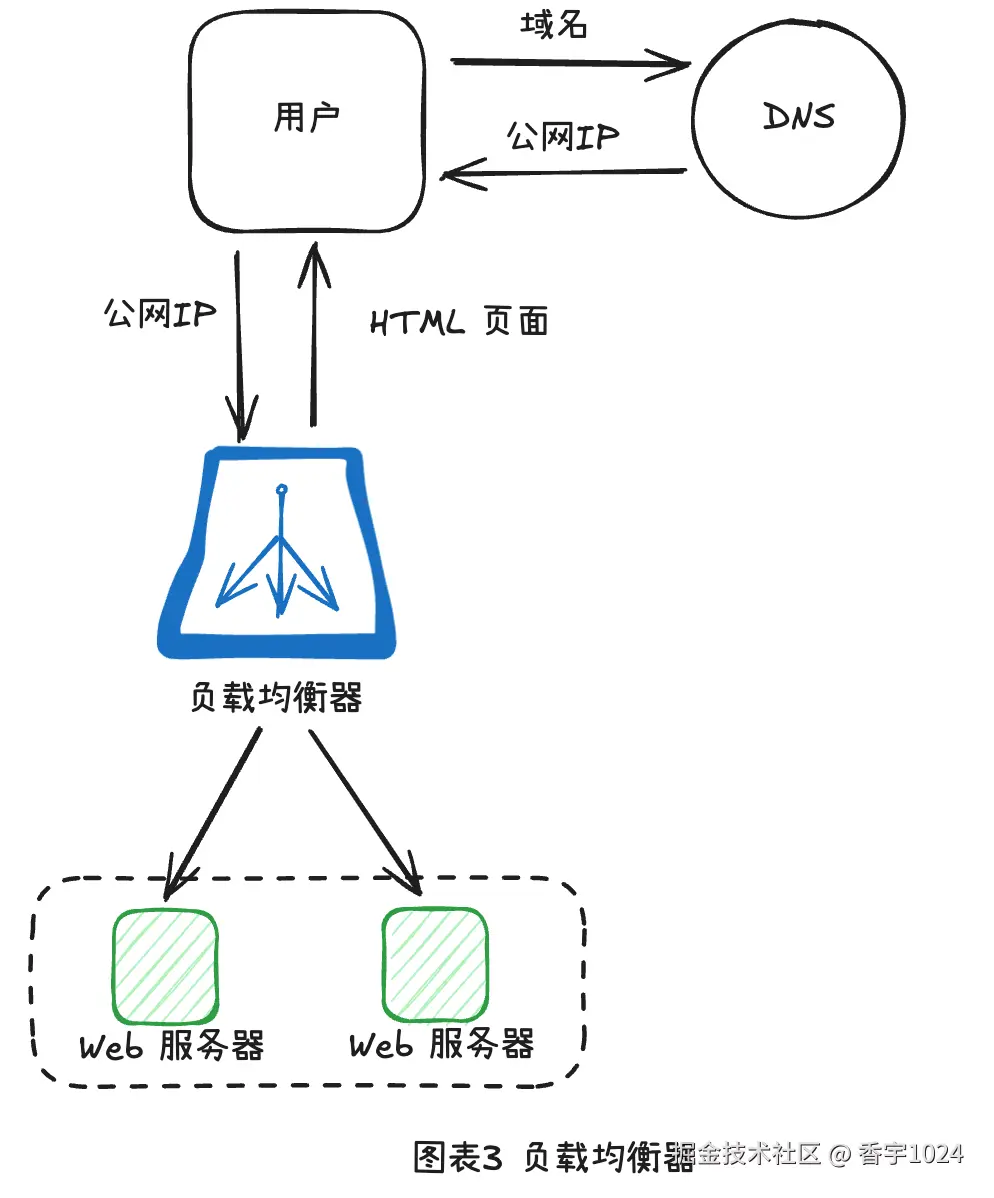
负载均衡可以把网络流量根据策略打到不同的Web服务器上,从而避免其单点故障问题。负载均衡器本身可能成为单点故障,因此实际系统通常部署多台负载均衡器并配合主备或双主切换,实现高可用。
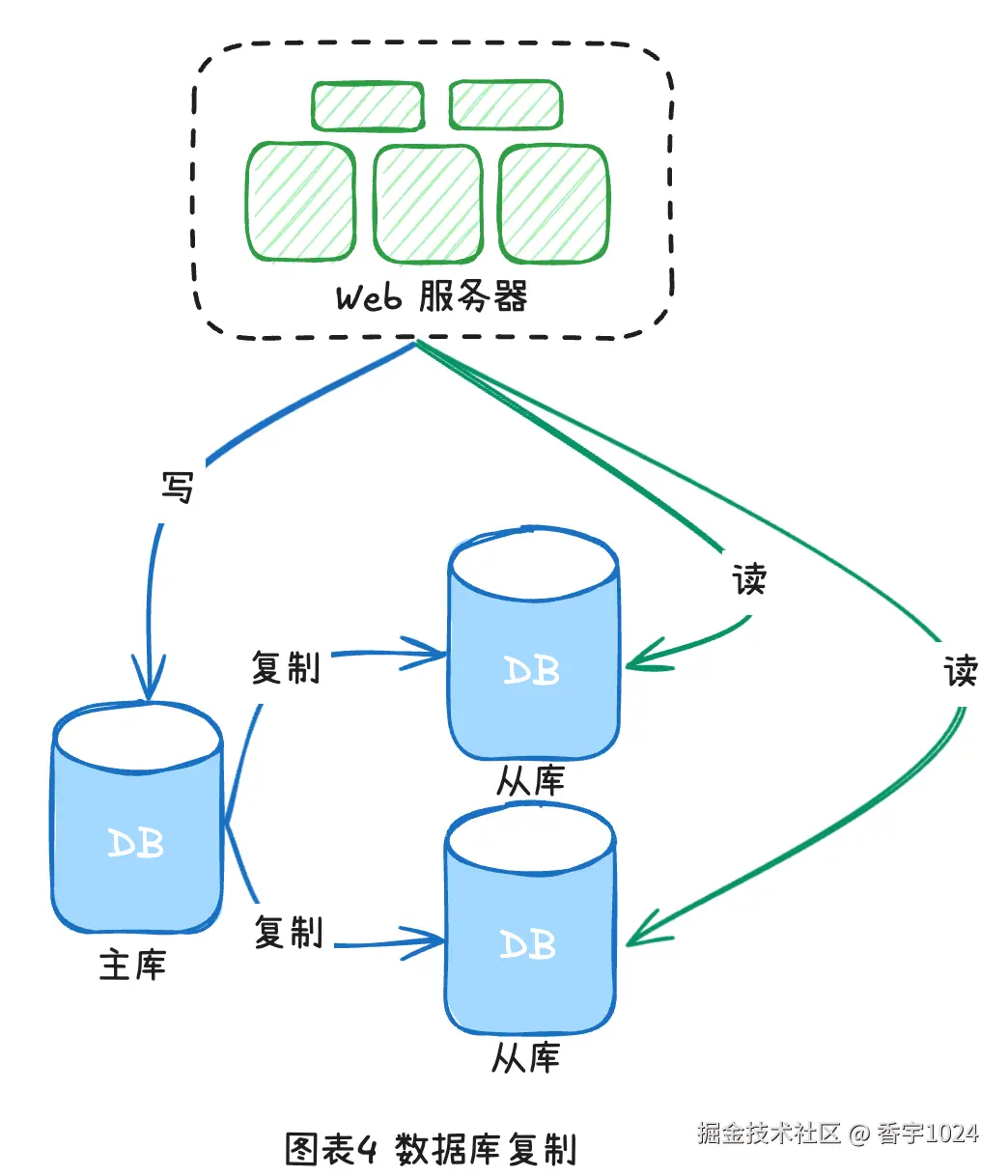
四、数据库复制
一个数据库服务器还不够的情况下,还可以继续扩展------垂直扩展和水平扩展。垂直扩展通过增强单机性能提升系统能力,简单但受硬件上限和单点故障限制;相比之下,水平扩展更适合大规模与高可用场景。
在实际应用中,读请求通常远多于写请求,因此系统往往配置多个从库以分担读负载。数据库复制通过将主库数据同步到从库,实现水平扩展并提升系统可用性。
现在我们已经基本搞懂网络层和数据层了,接下来让我们提升一下响应速度。
五、缓存层
缓存层是一个临时的数据存储层,比数据库更快。拥有独立的缓存层的好处包括更好的系统性能、减轻数据库负载的能力以及能够独立扩展缓存层。
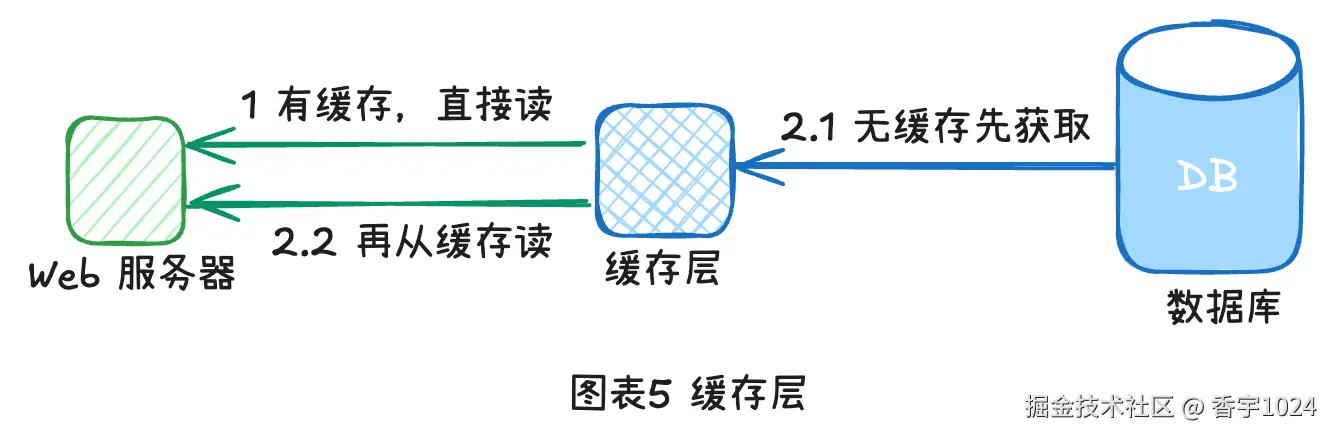
使用缓存的几个注意事项:
- 何时使用缓存?
缓存的核心作用是提升读性能、减轻后端负载、降低延迟。适合使用缓存的典型场景:
- 读多写少:如商品详情、配置项、用户资料等;
- 生成成本高:复杂计算、聚合查询、外部接口结果;
- 能容忍短暂不一致:如统计类、排行榜、推荐列表。
不建议使用缓存的情况:
-
数据频繁变动或需要强一致性(如交易余额、库存扣减);
-
缓存命中率低或数据体量过大导致内存浪费。
- 使用缓存常见问题
缓存虽然能提速,但引入了一致性与可靠性风险。
(1)一致性问题
现象: 缓存与数据库更新不同步,出现"脏读"或"旧数据"。 原因: 数据写入数据库后,缓存未及时更新或删除。 典型场景: 用户更新资料后,页面仍显示旧信息。 常见策略:
- 异步通知机制:通过消息队列或订阅系统触发缓存更新。
- 版本控制或时间戳校验:校验缓存数据是否过期。
(2)出错与过载风险
缓存系统一旦异常或过期,可能引发访问风暴,冲击数据库。
| 缓存穿透 | 查询不存在的 key,每次都打到数据库。 | 使用 布隆过滤器 或缓存空值。 |
|---|---|---|
| 缓存击穿 | 热点 key 过期瞬间被并发访问。 | 给热点 key 加锁或使用 逻辑过期机制。 |
| 缓存雪崩 | 大量 key 同时过期,导致数据库压力激增。 | 设置 随机过期时间、分批刷新、限流与预热。 |
| 系统异常 | 缓存宕机或访问超时。 | 启用 降级机制(返回旧数据或默认值)。 |
- 清除缓存
(1)时间(过期策略) 缓存应具备生命周期(TTL),防止长期脏数据。
- 固定 TTL:统一设置过期时间,简单易控;
- 滑动 TTL:访问时刷新过期时间,保证热点数据常驻;
- 主动刷新:后台任务或订阅机制定期更新缓存;
- 随机过期时间:避免大量 key 同时过期造成雪崩。
(2)驱逐(Eviction)策略 当缓存空间不足时,系统会根据策略淘汰数据:
- LRU(Least Recently Used) :淘汰最久未使用的;
- LFU(Least Frequently Used) :淘汰访问最少的;
- FIFO(First In First Out) :按写入顺序淘汰;
- 自定义优先级:关键数据可标记为不过期或延迟淘汰。
驱逐策略应根据业务访问模式选择:
-
热点集中 → LRU 更合适;
-
数据访问分布均匀 → LFU 效果更优。
缓存层这一招,确实让我们的系统"飞"了一大截------热门数据不用次次查数据库,响应速度嗖嗖的。可问题也随之冒出来:离我们机房近的用户体验丝滑,远在海外或偏远地区的用户,却依旧卡得想摔电脑。明明服务器已经优化到牙缝里去了,为什么他们访问还是慢?其实瓶颈不在服务器性能,而在------"距离"。这时候,我们就得请出加速全球访问的神器:CDN(内容分发网络) 。
六、CDN
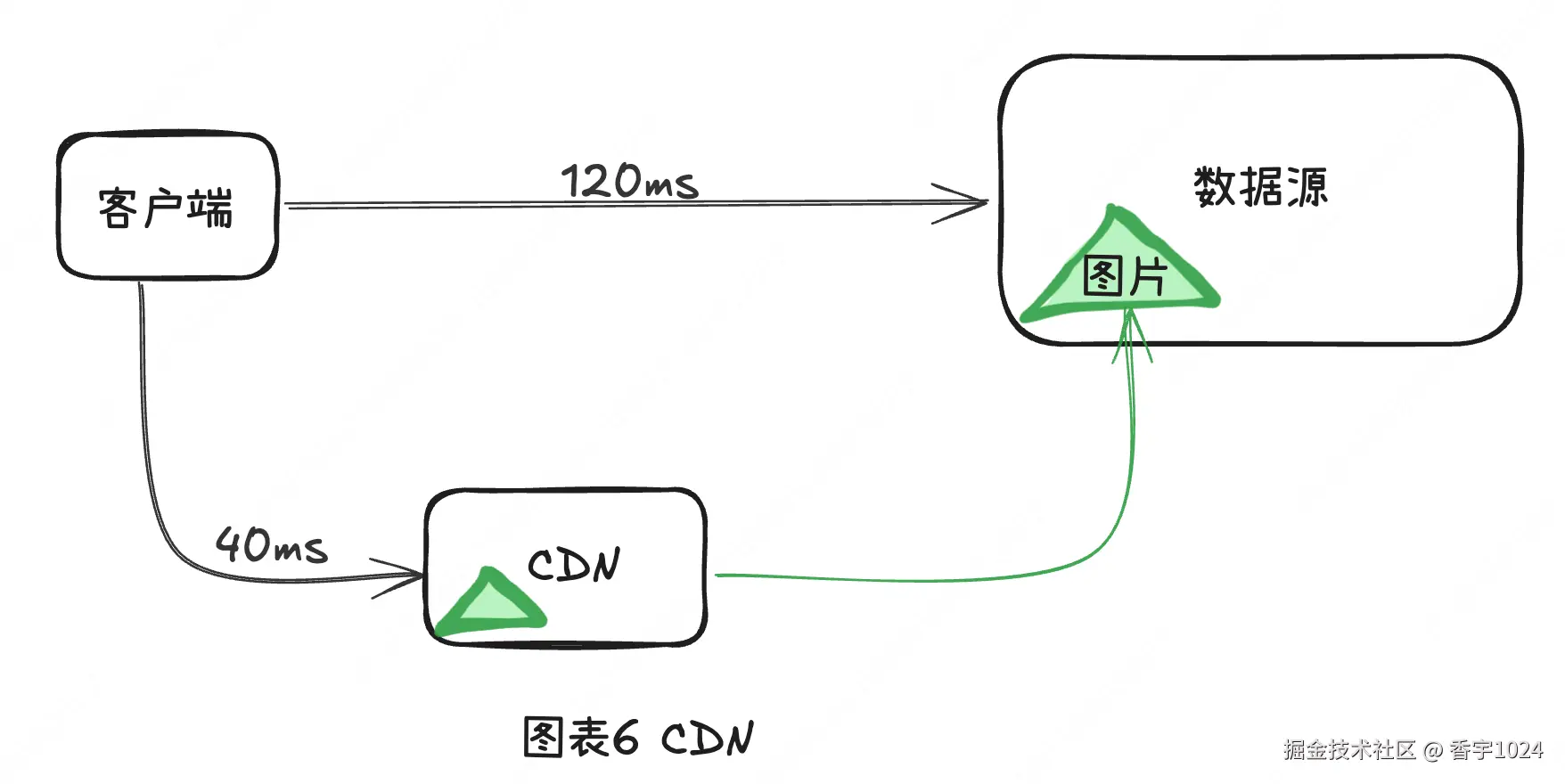
说到 CDN,最先想到的就是静态内容缓存。它的作用很简单------把图片、视频、脚本、样式表等不常变化的资源缓存在离用户更近的节点上,让用户能更快加载网页、减轻源站压力、提升访问体验。做静态缓存是需要注意设置好故障回退策略、自动和手动过期策略当然还有开销。
在现代 Web 架构中,动态内容缓存 已成为提升性能与可扩展性的重要手段。它不同于静态内容缓存仅针对图片、脚本、样式表等固定资源,而是面向那些会根据请求参数、用户特征或业务逻辑而变化的内容,例如个性化页面、搜索结果、推荐信息等。
动态内容缓存的核心思想,是让 CDN 或边缘节点在一定程度上缓存由服务端实时生成的 HTML 页面或 API 响应,从而减少源站计算压力、缩短用户响应时间。以 Amazon CloudFront 为例,它支持通过灵活的 缓存键(Cache Key) 配置,将不同请求的特征纳入缓存维度,实现更智能的缓存策略。
CloudFront 的缓存键默认包含"域名 + URL 路径",但开发者可以根据业务需要进一步指定:
- 查询字符串(Query String) :根据请求参数缓存不同页面版本,如
?lang=en与?lang=zh-CN。 - Cookie:针对不同用户状态或偏好缓存对应页面,例如登录与未登录状态。
- 请求头(Header) :根据设备类型或语言首选项(如
User-Agent或Accept-Language)缓存不同响应。 - 请求路径(Path Pattern) :为不同业务路径设置差异化缓存策略。
这种机制使 CDN 能够在边缘层实现对部分动态页面的缓存与复用,从而显著提升访问速度并减轻源站负载。
七、无状态网络
是时候横向扩展网络层了。在前文的设计中,用户登录信息是存储在Web服务器(网络层)中的,这叫做有状态网络,由于要网络层服务器要"记住"用户状态,所以难以扩展。无状态网络层是指服务器在处理请求时,不保存客户端的任何上下文状态。每个请求都是独立、完整、自足的,服务端只依赖请求中携带的信息就能处理完逻辑并返回响应。简单就是: "服务器忘记上一次你是谁,只看这一次你说了什么。"
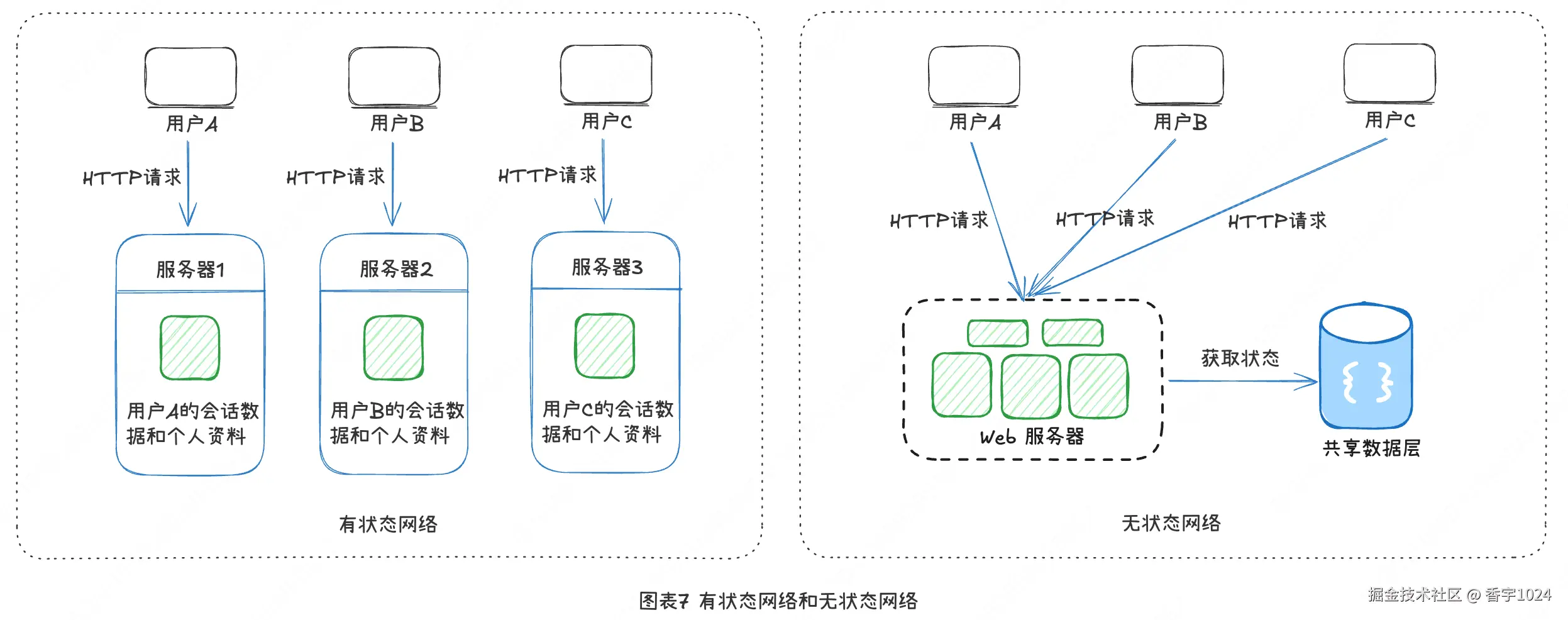
将用户状态从网络层移到专门的持久化存储(一般用NoSQL,比较快),网络层就可以实现自动扩展(基于网络流量自动地增加或者减少Web服务器)了。
八、数据中心
网站继续发展,而且吸引了非常多的国际用户,要提高可用性以及在更广的地理区域提供更好的用户体验,让网站支持多数据中心就非常关键。
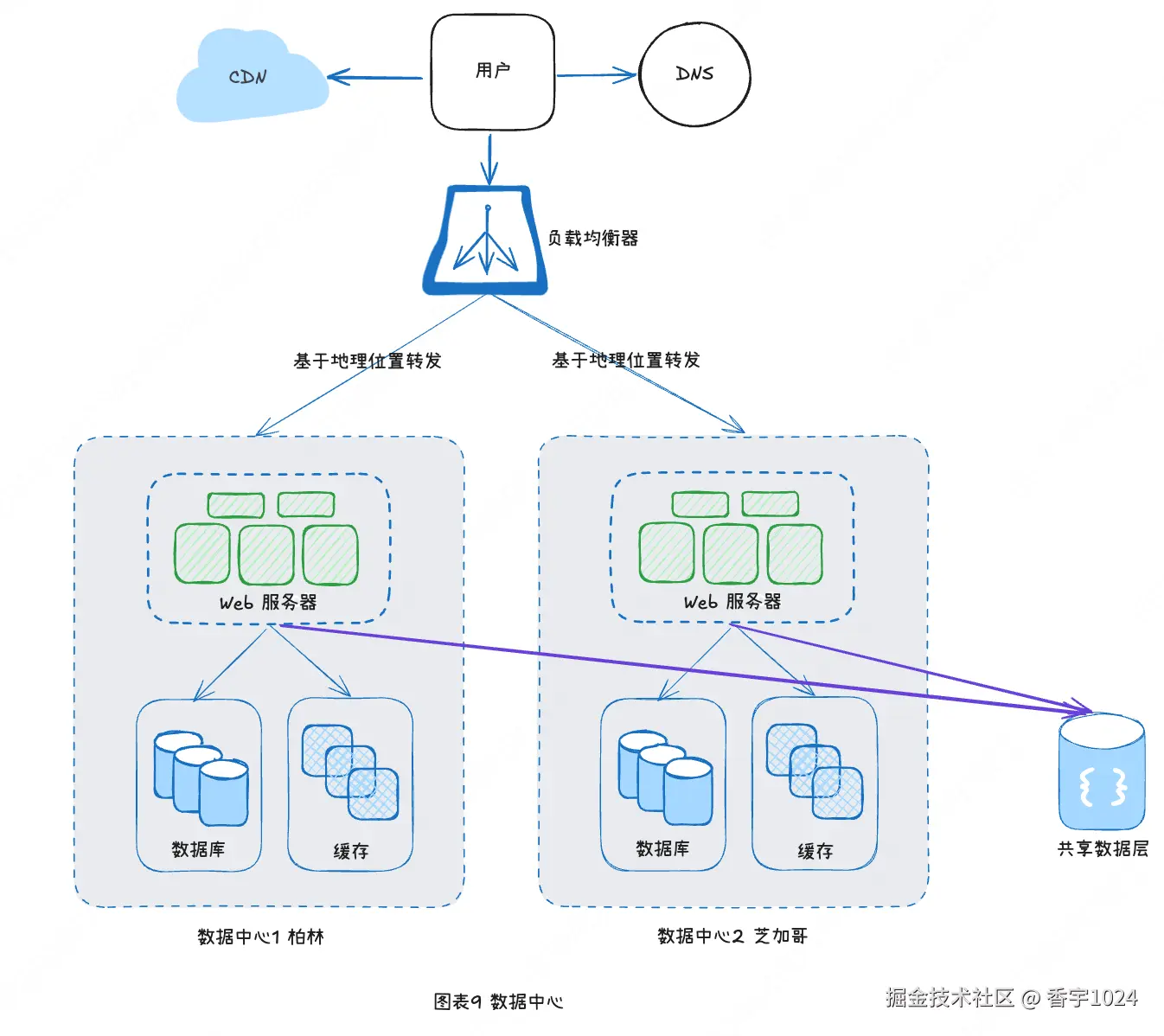
要设置多数据中心,必须先解决如下技术难题:
•流量重定向。要有能把流量引导到正确数据中心的有效工具。
•数据同步。不同地区的用户可以使用不同的本地数据库或者缓存。在故障转移的场景中,流量可能被转到一个数据不可用的数据中心。常用的一个策略是在多个数据中心复制数据。
•测试和部署:设置多数据中心后,在不同的地点测试你的网站/应用是很重要的。而自动部署工具则对于确保所有数据中心的服务一致性至关重要。
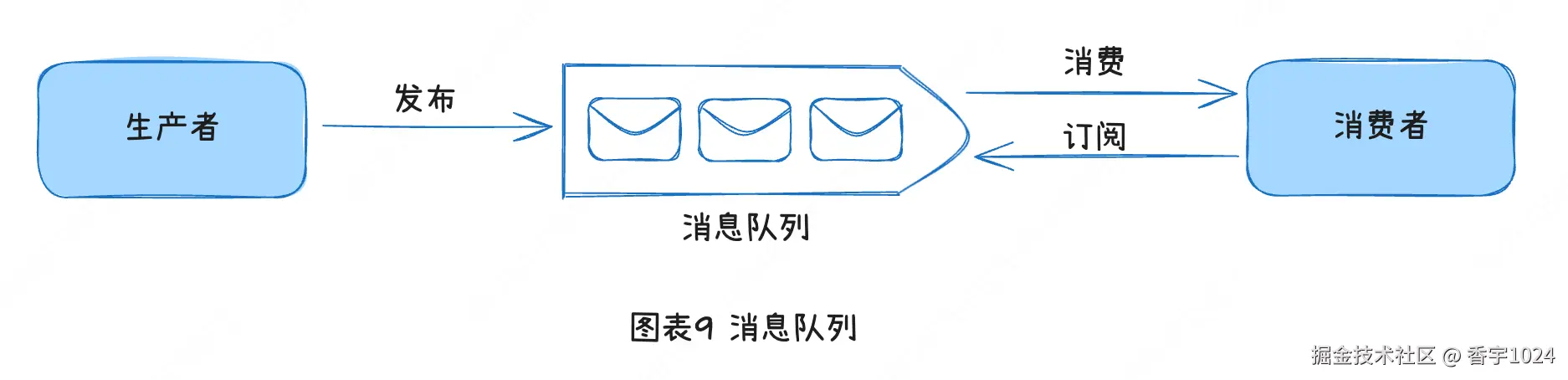
九、消息队列
为了进一步扩展我们的系统,我们需要解耦系统中不同的组件,这样它们就可以单独扩展了。在现实世界中,很多分布式系统用消息队列来解决这个问题。解耦使消息队列成为构建可扩展和可靠应用的首选架构。有了消息队列,当消费者无法处理消息时,生产者依然可以将消息发布到队列中;就算生产者不可用,消费者也可以从队列中读取消息。
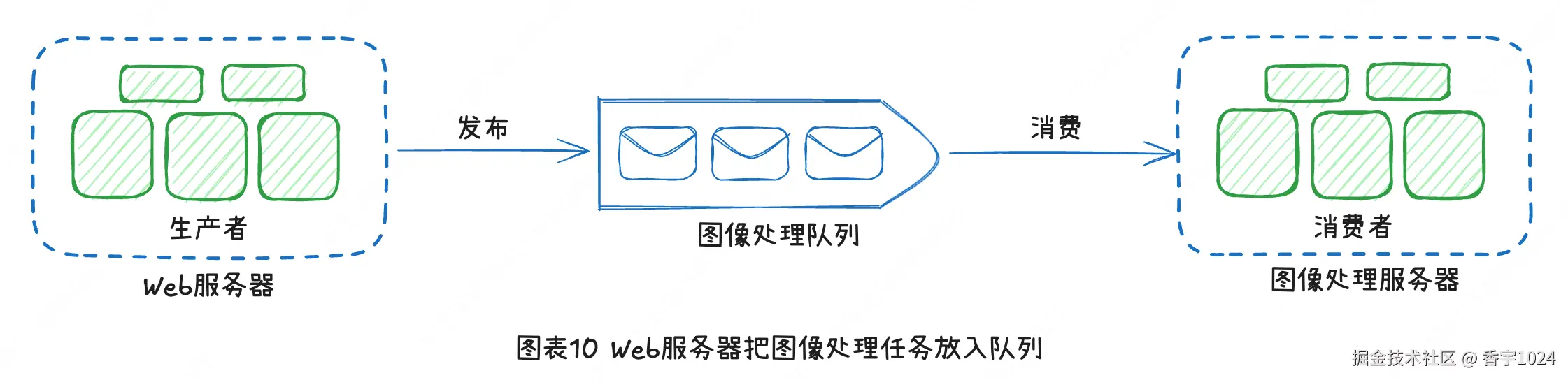
考虑以下用例:你的应用支持修改图像,包括裁剪、锐化、模糊化等,这些任务都需要时间来完成。Web服务器把图像处理的任务发布到消息队列。图像处理进程或服务(Worker)从消息队列中领取这个任务,并异步执行。生产者和消费者都可以独立地扩展。队列的规模变大以后,可以加入更多的Worker,以减少处理时间。如果队列在大部分时间中都是空的,就可以减少Worker的数量。
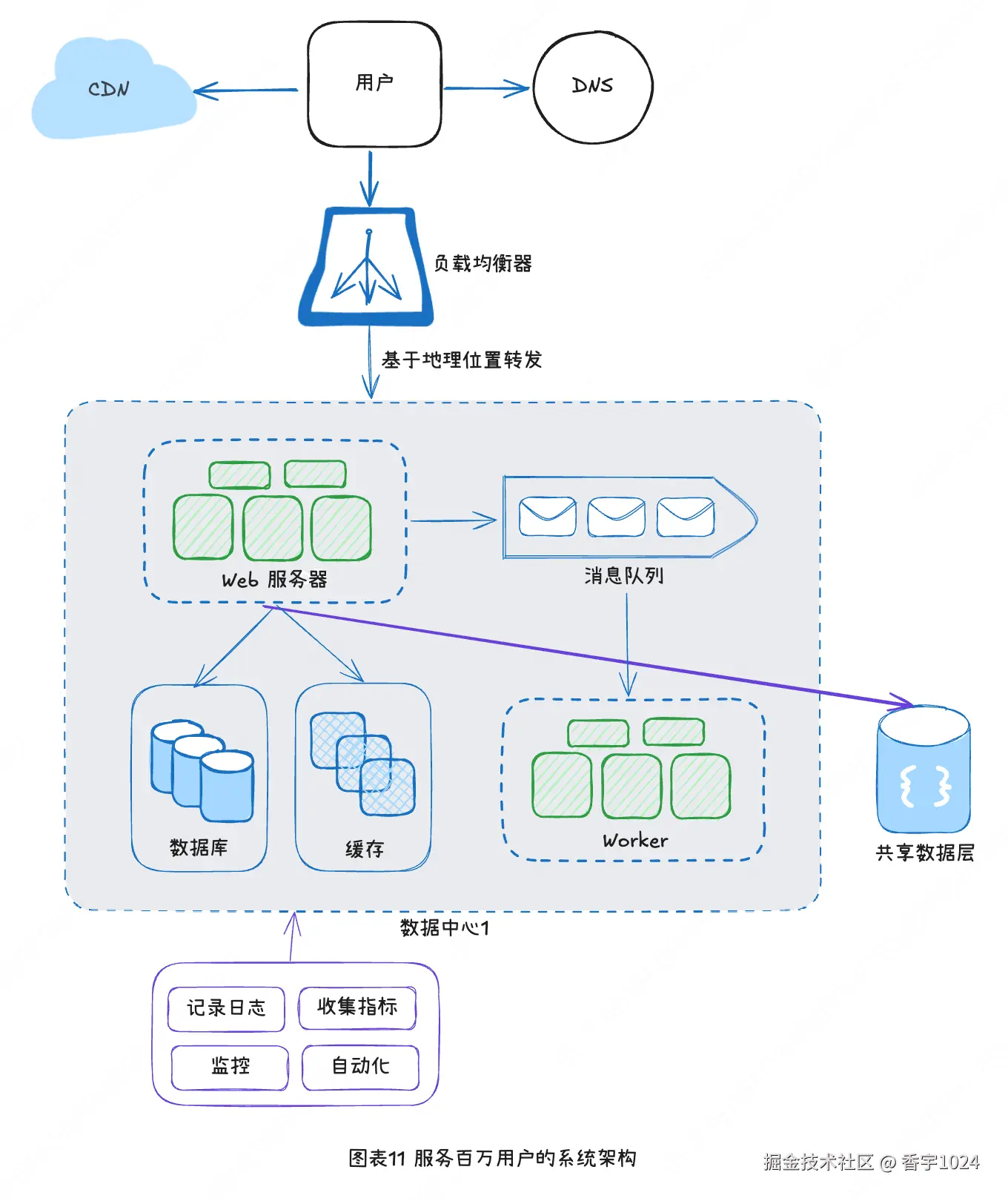
十、日志、收集指标与自动化
对于一个只有几台服务器的小网站,记录日志、收集指标和自动化只是锦上添花的实践而非必需的工作。但是当网站发展成为大企业提供服务的平台时,这些工作就是必需的了。
记录日志:监控错误日志非常重要,因为它可以帮助识别系统的错误和问题。你可以监控每个服务器的错误日志,也可以用工具把各个服务器的日志汇总到一个中心化的服务中,方便搜索和查看。
收集指标:收集不同类型的指标数据,有助于获得商业洞察力和了解系统的健康状态。以下几个指标很有用:
•主机级别指标:CPU、内存、磁盘I/O等。
•聚合级别指标:比如整个数据库层的性能,整个缓存层的性能等。
•关键业务指标:每日活跃用户数、留存率、收益等。
自动化:当系统变得庞大且复杂时,就需要创建或者使用自动化工具来提高生产力。持续集成是一个很好的做法。在这种做法中,每次代码检入(check in)都需要通过自动化工具的审核,使团队能及时发现问题。同时,将构建、测试和部署等流程自动化,可以显著提高开发人员的生产力。
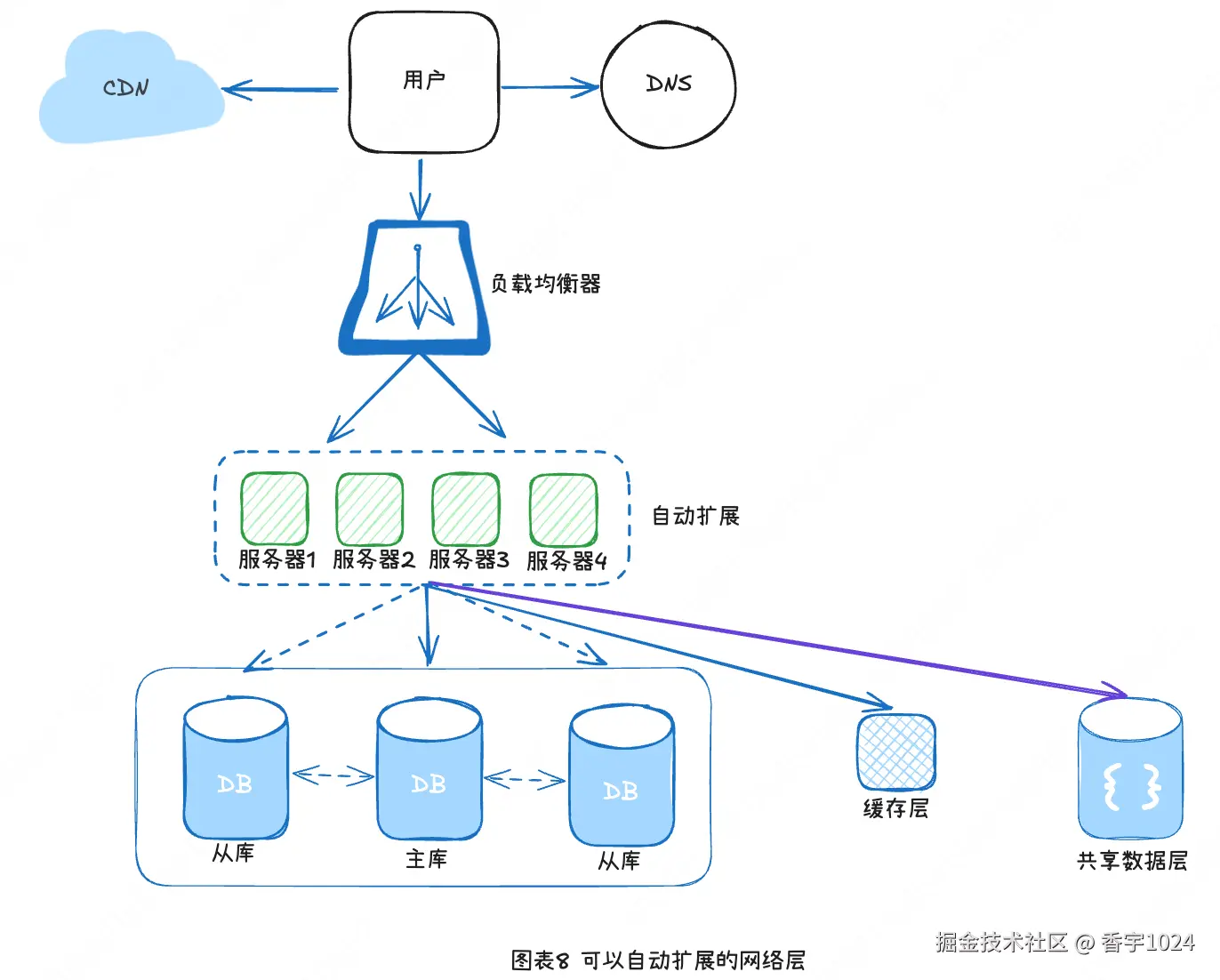
奉上一张完整的系统架构图:
十一、当用户超过100万
当网站或应用的用户数量超过100万时,就需要进行更多的调整和采用新的策略来扩展网站。比如,你可能需要优化系统,并把它解耦成更小的服务。