作者:代丽 货拉拉/技术中心/质量保障部/履约组
当一个数据平台的工具量突破3000+、日均调用超50万次,是该庆祝规模化的胜利,还是警惕效率的陷阱?
货拉拉数据工厂就曾站在这样的十字路口------依托高效的"协议编程"架构,我们实现了工具的爆发式增长,却也迎来了用户最真实的抱怨:"工具太多选不出""串流程要记半天""新手上手太费劲"。
于是,一场从"平台化"到"AI智能化"的跃迁就此启动。今天,我们就聊聊这场转型背后的痛点、方案与收获。
一、3k+工具的甜蜜烦恼:高效架构下的使用困局
在聊转型前,必须先说说支撑我们走到今天的核心底气------"协议编程"架构,简单来说就是:
工具开发者只需写Java工具类(遵循统一规范),平台通过自研解析引擎自动提取功能描述、输入输出参数等元信息,前端再自动生成可视化界面。
这个模式的威力有多强?开发者不用管前端交互、权限控制这些"杂事",专注业务逻辑就行,工具开发成本直接降低60%以上。
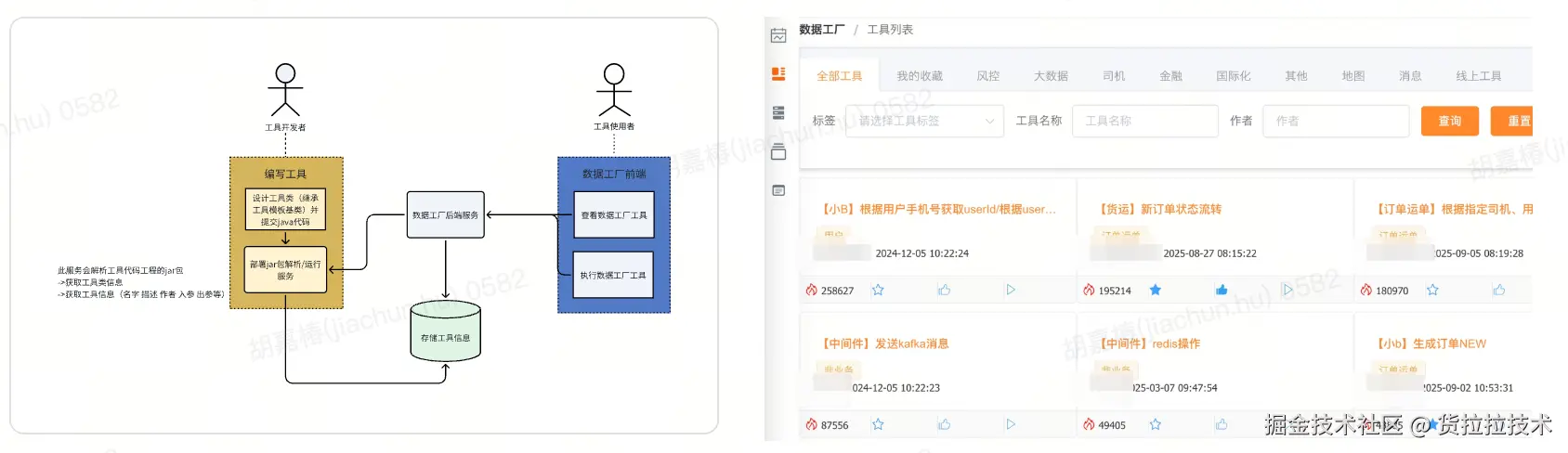
靠着这套打法,数据工厂迅速成为内部造数的核心基础设施:工具总量突破3k+,日均调用超50万次。但规模上去了,新问题也找上门了,集中在两个核心痛点:
1. 工具太多,选得发愁
为了鼓励提效,我们采用"全局核心工具+业务线自定义工具"的运营策略,这就导致很多功能相似的工具并存。比如"账号信息查询"这个简单场景,平台上就有3个主流版本:
- 账号中台:通用版(支持全账户类型)
- 司机业务线:专属版(仅支持司机账户)
- 用户业务线:专属版(仅支持用户账户)
实际使用中,70%的用户会优先选本业务线工具,导致通用工具复用率不足30%;更糟的是,新用户得花3分钟对比测试才能找到合适的工具,提升了使用门槛。
2. 步骤太繁,操作耗时
我们的工具大多是"原子化"的,一个工具只干一件事。但真实业务场景往往需要多工具串联,比如"下单并给指定司机流转至完单"这个高频操作,用户得手动走三步:
- 用"获取司机信息"工具查车型
- 用"下单"工具完成创建
- 用"订单流转"工具更新状态
整个流程平均要5分钟,中间还要手动记结果、切工具,不仅麻烦,还容易出错。
二、升级目标:让造数像"说话"一样简单
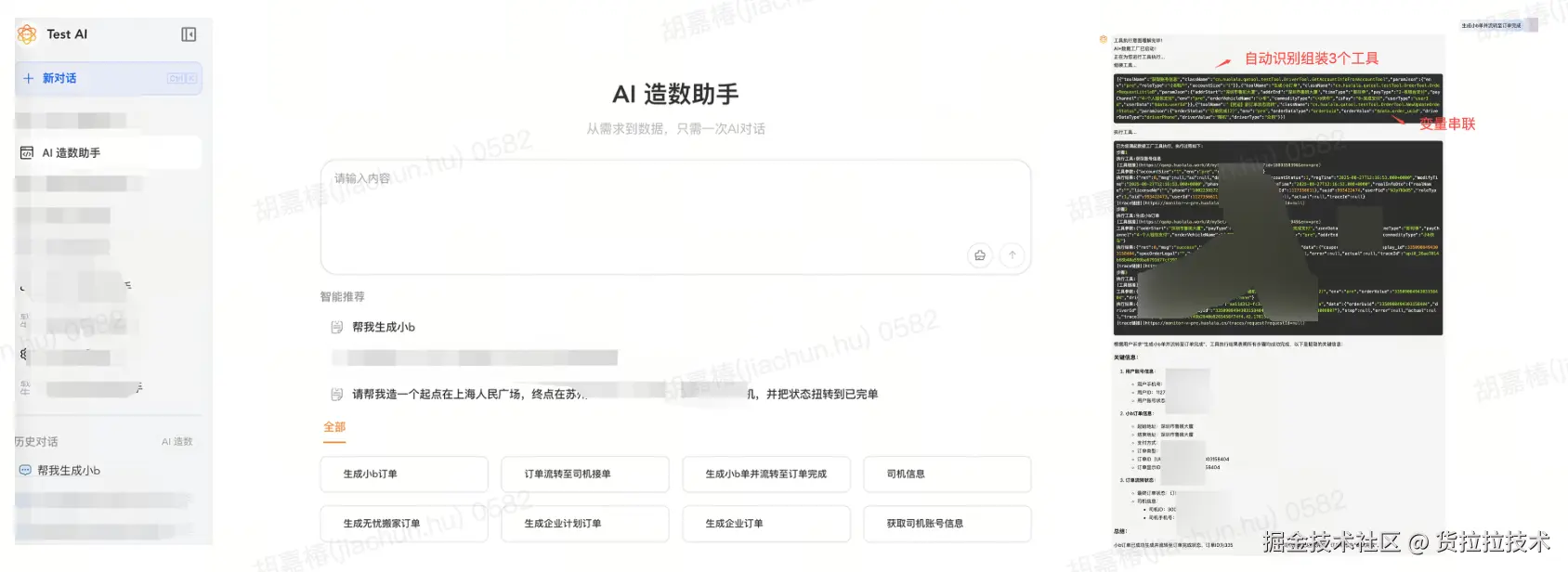
针对这些痛点,我们明确了AI升级的核心方向:打造一个能理解自然语言、自主调度工具的智能体(Agent) ,彻底改变用户与数据工厂的交互方式。
具体来说,就是要实现三个核心能力,让用户从"工具操作者"变成"需求提出者":
- 精准懂需求:不用记工具名,用日常话描述需求就行(比如"查一下司机张三的账号信息并履约完单")
- 智能配工具:系统自动选最优工具,多步骤场景自动串联,不用手动组合
- 自动跑流程:参数传递、工具调用、结果整合全自动化,直接给最终结果
我们的愿景很直接: "所想即所得,所造皆能成" 。初期目标更是明确:造数效率提升50%以上,新用户上手时间缩短到1分钟内。
三、技术方案:AI+数据工厂的三重协同落地
3.1 技术决策:从理论最优到落地可行
智能体的核心技术选型,我们围绕业务特性做了多轮评估。常见的与LLM结合方案有三种:RAG(检索增强生成)、MCP(执行引擎)和Fine-tuning(模型微调)。
从理论上看,Fine-tuning似乎是最优解------数据工厂覆盖货运、小拉出行、国际化等全业务线,沉淀了大量特有领域知识,微调能让模型深度融合这些知识,减少上下文输入量,提升稳定性。
但早期简易尝试后,我们发现了实际障碍:微调需要大量标注数据,且对算法团队的技术能力要求极高,同时持续迭代的成本也难以承受。综合落地难度与效果反馈,我们最终确定了 "LLM+RAG+MCP"的协同路径,兼顾效果、成本与落地效率。
3.2 技术方案:三大模块构筑智能体能力
我们将智能体拆解为"大脑(LLM)-知识库(RAG)-手脚(MCP)"三个核心模块,分别负责"理解决策""知识储备""执行落地",形成完整工作流。
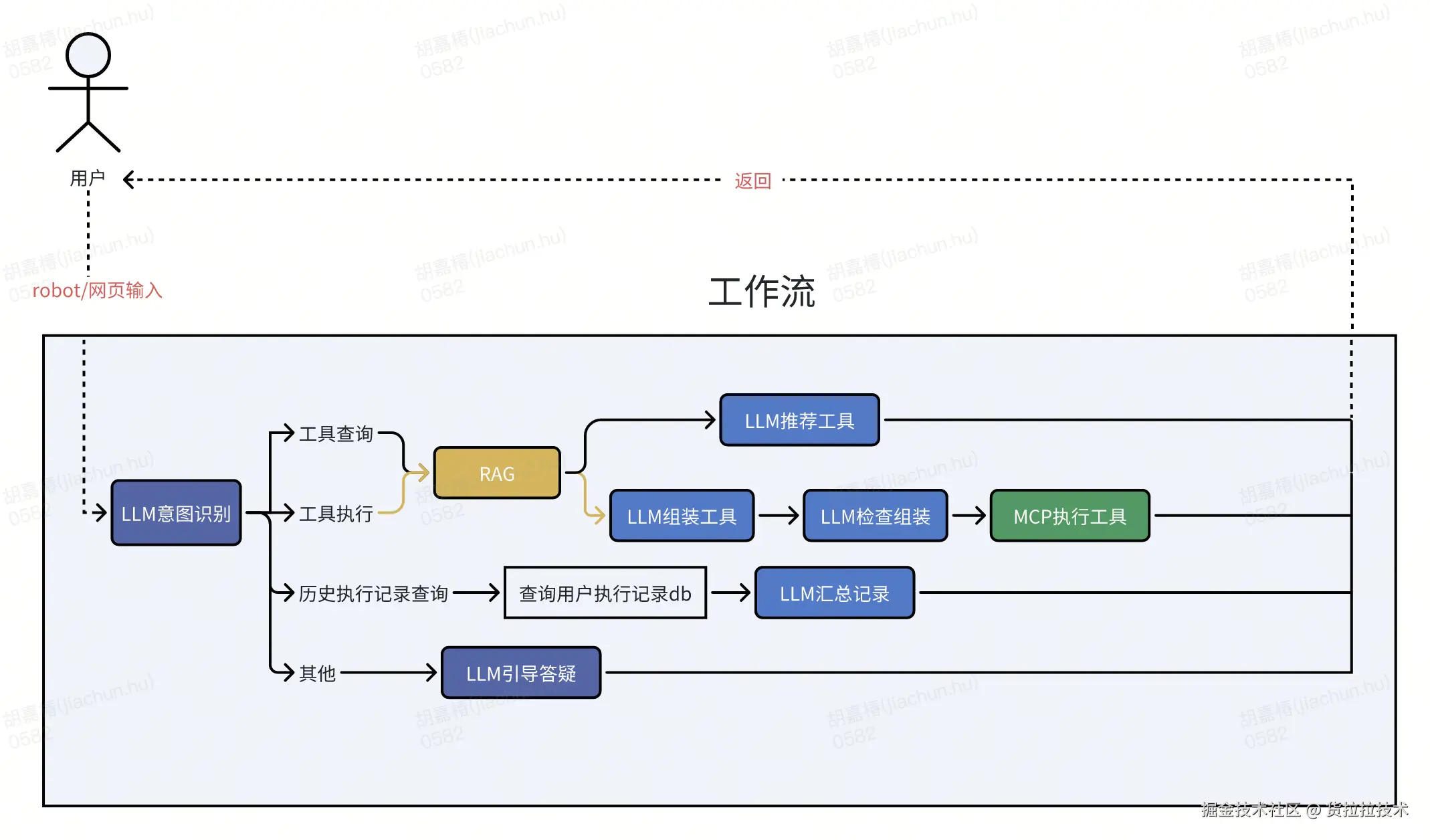
3.2.1 LLM:智能体的"决策大脑"
LLM是智能体的核心决策层,使用到LLM的共有6处,出于成本与调优效果做了如下组合与配置(精选3个展示):

3.2.2 RAG:智能体的"知识储备库"
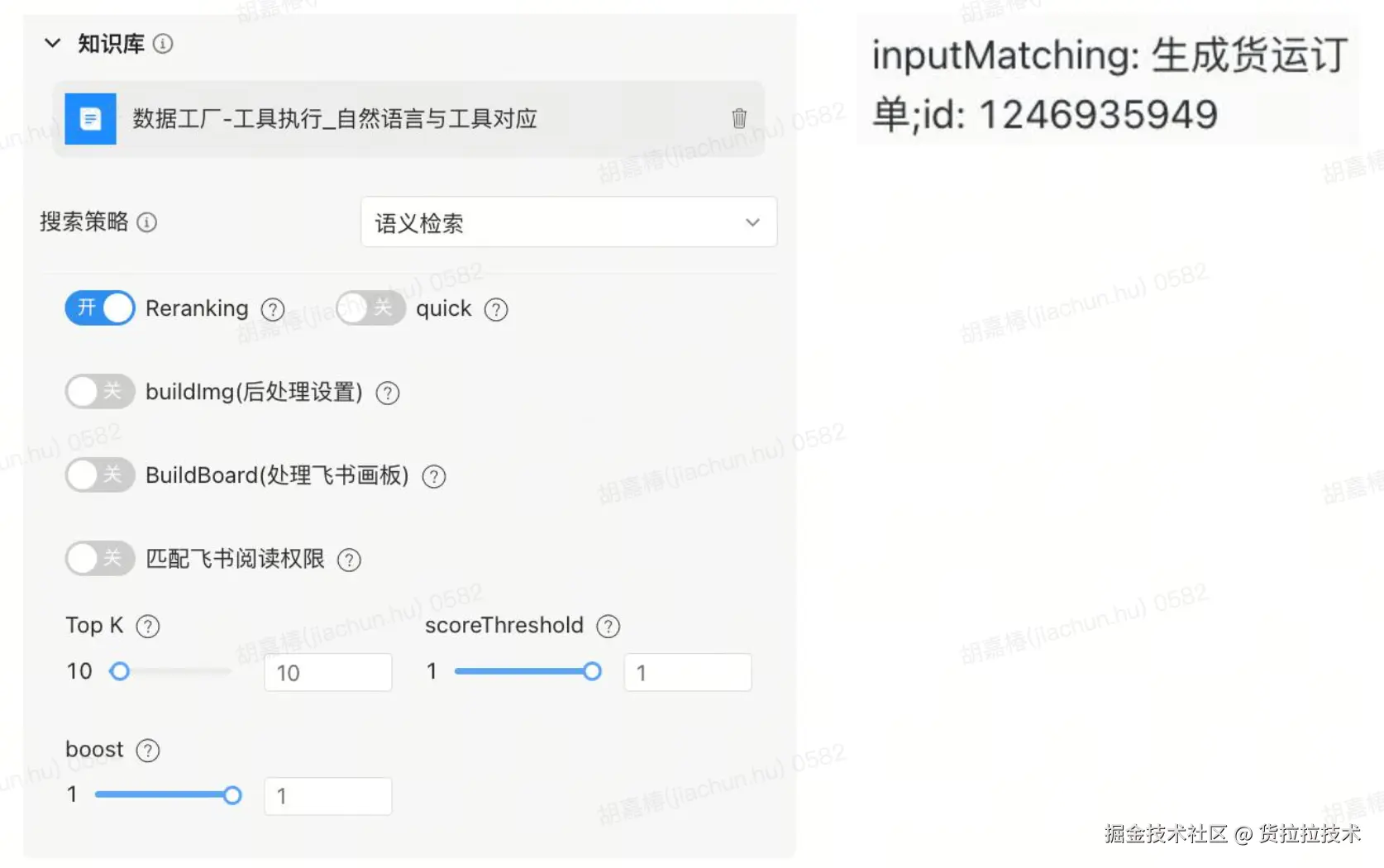
LLM 具备强大的通用能力,但对我们内部 3000 + 工具的具体信息 "一无所知"。若直接输入全量工具信息,会导致上下文过载。因此,我们通过 RAG 技术构建 "精准检索 - 高效赋能" 的知识库体系,助力智能体精准 "认知" 所需工具。
实践中,我们选用 bge_base_zh_1.5 作为 Embedding 模型,以适配中文语义理解场景;同时,为提升检索的精度与全面性,搭建了双层知识库筛选策略,并将其与固定原子工具列表组合,最终形成 toolList给到LLM使用。
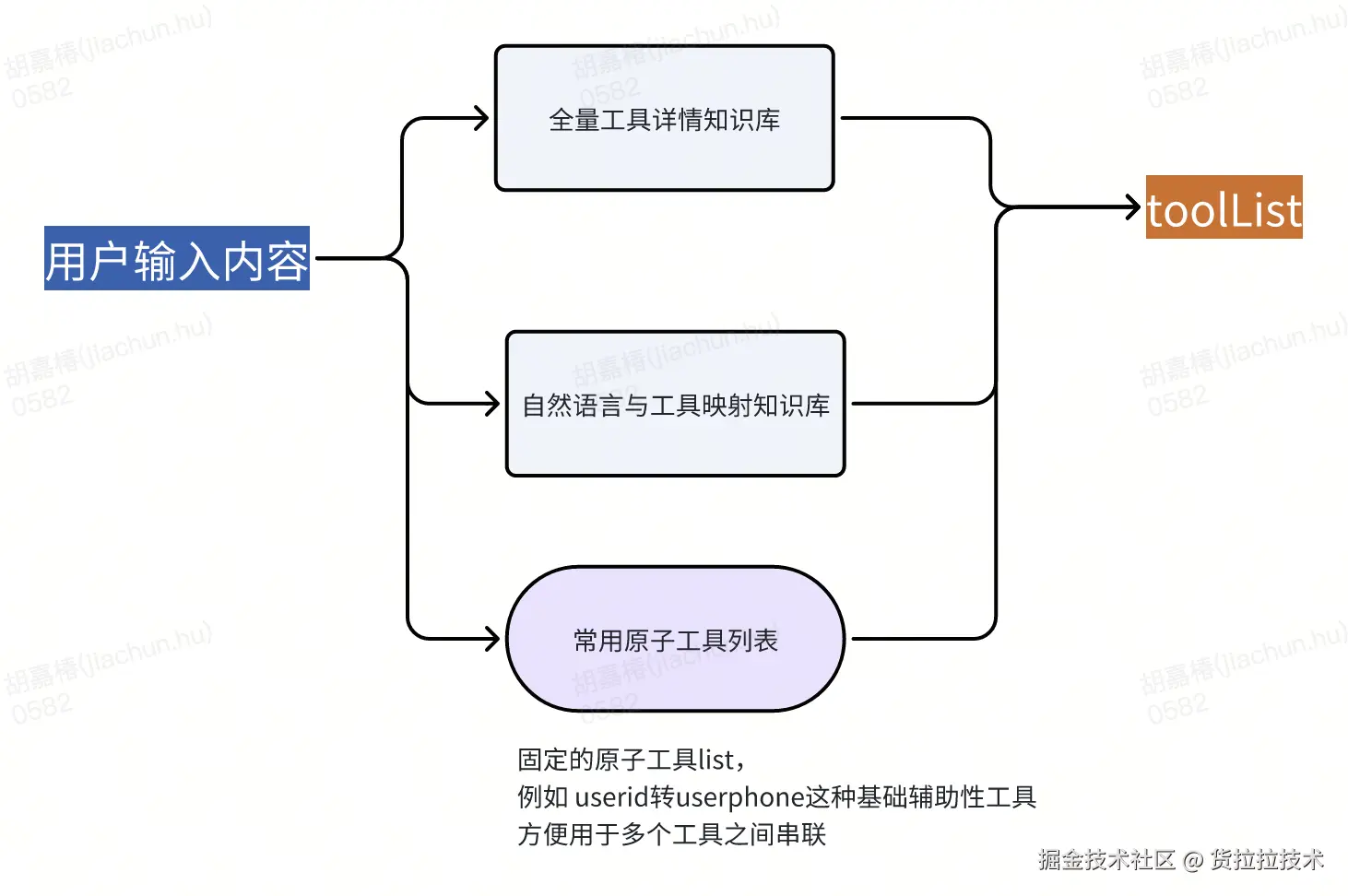
- 全量工具详情知识库:数据直接同步平台工具数据库,细分为"线上""线下"两个子库------线上库对应生产环境工具,线下库对应测试环境工具,避免智能体误调用测试工具影响线上业务,保障执行安全性。
具体配置与分段信息如下:
- 自然语言与工具映射知识库:人工维护多语义映射关系,解决"用户表述≠工具描述"的匹配难题。比如"下单""开单""创建订单"等不同说法,均映射到同一工具,大幅提升模糊需求的匹配准确率。
具体配置与分段信息如下:
3.2.3 MCP:智能体的"执行手脚"
工具组合方案确定后,就需要MCP(执行引擎)负责"落地执行",核心解决"按序执行、参数传递、失败处理、结果解析"四大问题,让智能体"会用"工具。
此处tool仅有一个,功能是单个工具运行,其执行逻辑依赖于prompt,prompt大纲设计:
- 核心任务定位:按工具序列依次执行,保障前序结果向后续传递,失败自动重试;提取执行结果并匹配用户诉求,用自然语言呈现。
- 核心执行规则: - 顺序执行:严格遵循工具列表顺序,前序工具执行成功是后序执行的前提; - 参数关联:动态参数从历史执行结果中自动提取,固定参数保持预设值不变; - 失败处理:执行失败触发重试机制(默认3次),重试失败则终止流程并记录失败状态与原因。
- 结果解析规范:根据执行状态码(如ret值)判断成败;成功则筛选核心信息分点呈现,失败则明确标注状态码、失败环节及可能原因,便于用户排查。
四、阶段性成果:上线三月,效率与口碑双丰收
今年8月AI智能体正式上线,作为内部工具的智能化升级尝试,经过一段时间的推广与迭代,在核心效率指标与用户口碑方面已取得显著成效,验证了升级方向的可行性。
4.1 核心数据:用户渗透良好,效率提升显著
上线至今,智能体的用户接纳度逐步提升,核心效率指标达到预期目标:
- 用户渗透:累计吸引500+内部用户使用,涵盖测试、产品、开发等关键技术岗位;
- 调用表现:当前支持工具100+,累计调用次数3k+,受限于部分用户使用习惯尚未完全转变和支持工具数量有限,但高频用户的周均调用频次达10次,使用粘性较高;
- 效率提升:核心业务场景的造数效率提升效果明显,以"下单并流转至完单"为例,操作时间从原有的5分钟缩短至1.5分钟左右,效率提升70%;
- 使用门槛:新用户上手适应时间从原有的3分钟压缩至1分钟内,自然语言交互方式有效降低了工具使用的学习成本;
4.2 用户反馈:跨岗位认可,痛点解决明确
尽管当前使用规模仍在拓展,但智能体精准解决了用户的核心痛点,获得了实际使用者的广泛认可,积累了不少正面反馈:
- 研发岗位:"这个太牛了,不用去数据工厂找工具了,研发联调的时候很受用"------某开发反馈;
- 产岗位:"说实话,有AI*数据工厂,产品验收轻松多了"------某产品反馈;
- 测试岗位:"太好用了,测试经常要批量造数,和它说,它可以一次完成,原来我还得在页面点多次"------某测试反馈。
4.3 成果价值:验证方向,沉淀经验
此次阶段性成果的核心价值,不仅在于效率数据的提升,更在于验证了"AI+数据工厂"模式的可行性:一方面,通过智能化手段解决了平台规模化后的核心痛点,为后续推广积累了真实使用案例;另一方面,基于用户反馈沉淀了模型调优、交互设计的经验,为进一步提升调用频次、扩大使用范围奠定了基础。
五、未来规划:在迭代中持续精进
AI智能体的初步落地验证了方向的可行性,但在实际应用中,我们也发现了需要持续优化的核心痛点。基于当前反馈,后续将聚焦问题解决与能力升级,稳步推进智能化深化。
5.1 现存核心痛点
结合用户使用数据与反馈收集,目前主要存在两类待解决的问题,也是后续优化的方向:
- 表述习惯差异导致的适配问题:不同岗位、不同使用经验的用户,对同一业务场景的表述存在差异。以"小b下单"场景为例,用户可能表述为"小b下单""货运下单""APP创建小b订单"等多种形式。尽管当前通过持续丰富RAG知识库已实现问题可控,但知识库更新存在一定后置性,未能从源头减少歧义。
- LLM 上下文过载与幻觉问题:数据工厂工具覆盖货拉拉货运、小拉出行、国际化等全业务线,为保障LLM对业务场景的理解精度,需在上下文中外挂大量业务知识与工具信息,导致上下文内容过载。这一问题直接引发LLM幻觉现象频发(如工具选错、生成逻辑有误的执行序列等),单纯通过精简上下文内容已难以有效缓解。
5.2 后续优化路径
针对上述痛点,我们制定了明确的分阶段优化计划,兼顾短期问题解决与长期能力提升:
1. 前置化引导,降低表述歧义
为解决表述差异问题,后续将从"后置知识库补充"转向"前置输入引导"。计划在交互界面增加场景化引导模块:基于历史调用数据梳理高频业务场景(如订单创建、账号查询、状态流转等),为每个场景配置标准化话术模板与关键词提示。用户输入时,系统可根据初步语义识别推荐对应场景模板,用户仅需补充关键参数即可完成需求提交,从源头降低歧义表述概率。
2. 职责拆分 + 场景固化,从架构层面降低幻觉概率
针对上下文过载引发的幻觉问题,采用 "现有平台交互改造 + 智能体职责拆分" 双轮驱动策略,具体如下:
- 现有平台交互改造:将现有平台执行底层升级为智能体执行模式,前端除了结果展示采用智能体输出效果,其他不变。该方式既能适配用户现有使用习惯,又能规避 LLM 动态组装工具带来的幻觉风险。
- 智能体职责拆分:当前智能体核心决策依赖 "工具组装" 单一 LLM,导致其同时承载业务知识存储、工具匹配判断、执行序列生成等多重职责。后续将核心职责拆分为 "业务知识解析""工具匹配筛选""执行序列生成" 三个独立模块,通过 "轻量化 LLM + 专用 RAG 知识库" 协同实现(如专用 RAG 承载业务知识、独立 LLM 负责工具匹配)。此举可显著降低单个模型的上下文负载,从架构层面减少幻觉发生概率。
3. 长期技术探索:微调路径持续验证
尽管初期因数据、成本等因素放弃了Fine-tuning方案,但随着业务数据的积累与技术成本的优化,我们将持续小范围验证微调可行性。计划选取高频业务场景(如订单全链路相关工具),构建专属微调数据集,探索"基础模型+场景微调"的混合模式,进一步提升模型对特定场景的理解精度与决策稳定性。
5.3 转型感悟:AI落地是场长期修行
在智能体落地过程中,我们深刻体会到:LLM的强大之处在于其泛化能力,但相较于传统工程代码的强可控性,它更像一个"需要持续调教的伙伴"。AI赋能并非一蹴而就,而是循序渐进的迭代过程------既要接受初期的不完美,通过实际场景反馈持续调优;也要保持对新技术的敏感度,及时将成熟的技术方案融入现有体系。