本系列文章将围绕东南亚头部科技集团的真实迁移历程展开,逐步拆解 BigQuery 迁移至 MaxCompute 过程中的关键挑战与技术创新。本篇为第十一篇,基于 MaxCompute Resource & Quota策略优化实现资源管理性能与成本最优平衡。
注:客户背景为东南亚头部科技集团,文中用 GoTerra 表示。
1. 背景
GoTerra作为东南亚互联网头部企业,其业务生态覆盖网约车、电商、外卖、物流及金融支付等多个垂直领域,内部采用多账户架构(10+ Accounts,70+ Projects)及上百个资源额度组(Quota Group)进行精细化管理。在从BigQuery迁移至阿里云MaxCompute的过程中,对资源管理的核心诉求在于通过智能弹性资源分配策略,动态适配业务负载波动,在控制成本的同时避免资源瓶颈,实现性能与成本的最优平衡。面临以下核心挑战:
多业务线资源协调复杂
- 规模庞大:跨10+独立业务单元(Account),涉及70+项目(Project),需创建100+资源额度组(Quota Group),资源管理颗粒度极细。
- 资源预留成本压力:每个Quota Group需按配置预留资源(CU),预付费模式下资源闲置与成本控制难以平衡。
计费模式差异带来的不确定性
- MaxCompute:预付费CU + 定时弹性资源模式,迁移前缺乏历史数据支撑,无法精准预估所需CU量,存在资源预留不足(性能瓶颈)或过度配置(成本浪费)的双重风险
多类型作业资源需求冲突
- ETL作业:需保障1小时内完成海量数据处理,依赖高吞吐计算资源。
- BI作业:要求10-15分钟低延迟响应,需快速分配临时资源。
- 并存挑战:长周期ETL与短周期BI作业共享资源池,如何动态调度以避免资源争抢、同时满足不同SLA(服务等级协议),成为性能与成本平衡的关键难题。
2. Resource Advisor和TopN Fair
2.1. Resource Advisor
2.1.1. 核心挑战
资源预估难题:
- 计费模式差异
- 作业类型复杂
多业务实体管理,每个业务实体需独立阿里云账号,SLA要求不同,导致资源购买量预期不一致:
- 超买:资源闲置浪费,挤占集群容量
- 少买:作业堆积,等资源时间长,影响业务数据产出
如何在控制成本的前提下,动态适配业务负载波动,避免资源瓶颈
2.1.2. 分层资源配置策略
| 资源配置 | 用途 | 配置原则 | 计费 |
|---|---|---|---|
| 预付费CU | 保障全天候基线资源需求,覆盖日常稳定负载 | 基于历史日均负载的80%-90%预购CU适用于ETL类周期性作业(如每日定时批处理)。 | 按购买量计费,24h预留,计费时间24h |
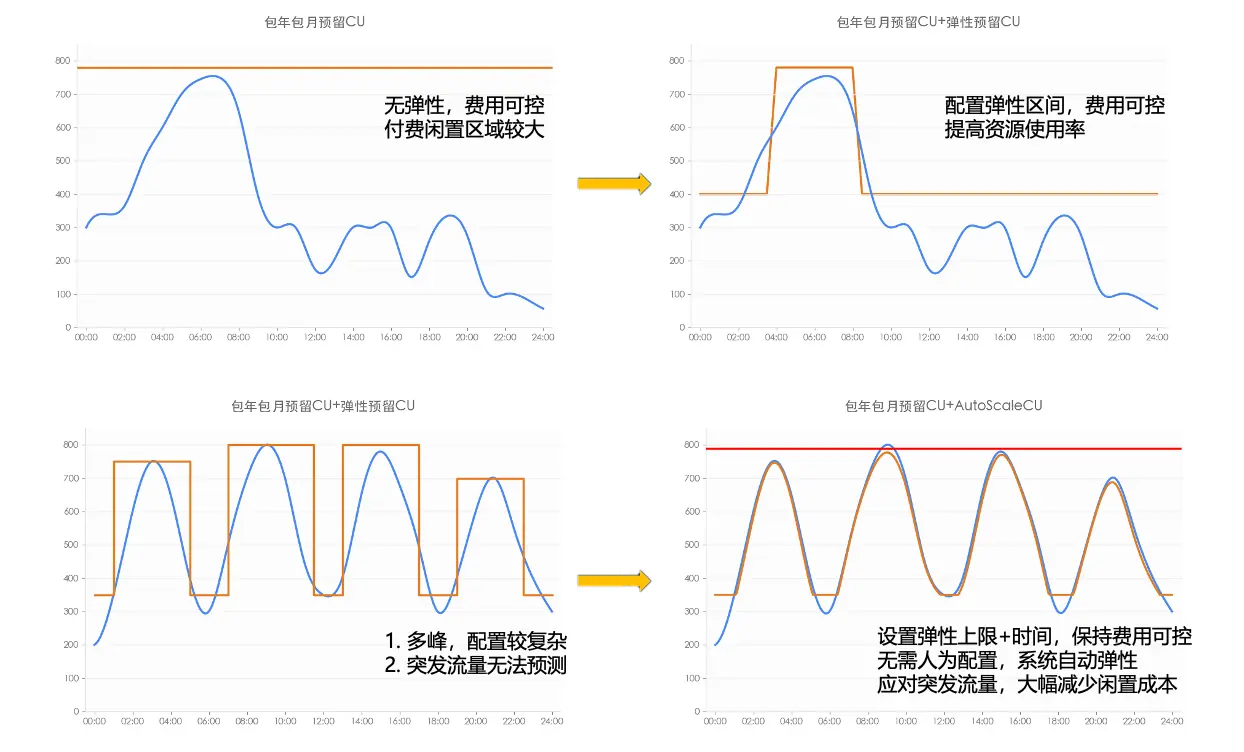
| 定时弹性CU(Adhoc) | 适用于可预测的负载波动(如BI报表每日上午集中执行) | 在业务高峰期(如早晚高峰)自动扩容资源,峰值后释放 | 指定时间计费按购买量计费,指定时间预留 |
| AutoScaleQuota | 应对突发BI作业流量 | 预估突发流量峰值,配置弹性上限 | 动态监控实时资源利用率,触发自动扩缩容。超出预付费CU+Adhoc CU部分按分钟级计费,避免突发流量导致的资源不足 |
其中AutoScaleQuota是应对GoTerra迁移场景新增的产品类型,解决迁移过程中,业务资源需求变化快,作业性能要求高的需求:
分层配置策略特点:
-
灵活组合:支持预付费、分时弹性与自动弹性任意搭配,满足不同业务场景的降本增效需求
-
极致成本:自动弹性部分,按实际使用量计费;相比扩缩槽等预留付费模式更加经济实惠
-
开箱即用:基于负载感知的自动弹性扩缩容,配置简单
-
秒级弹性:对比BigQuery限制扩缩容步长和窗口期,MaxCompute更加灵活及时
-
资源稳定:基于历史数据和预测模型进行资源调度优化,保障弹性库存供给
2.1.3. 智能资源推荐与弹性配置
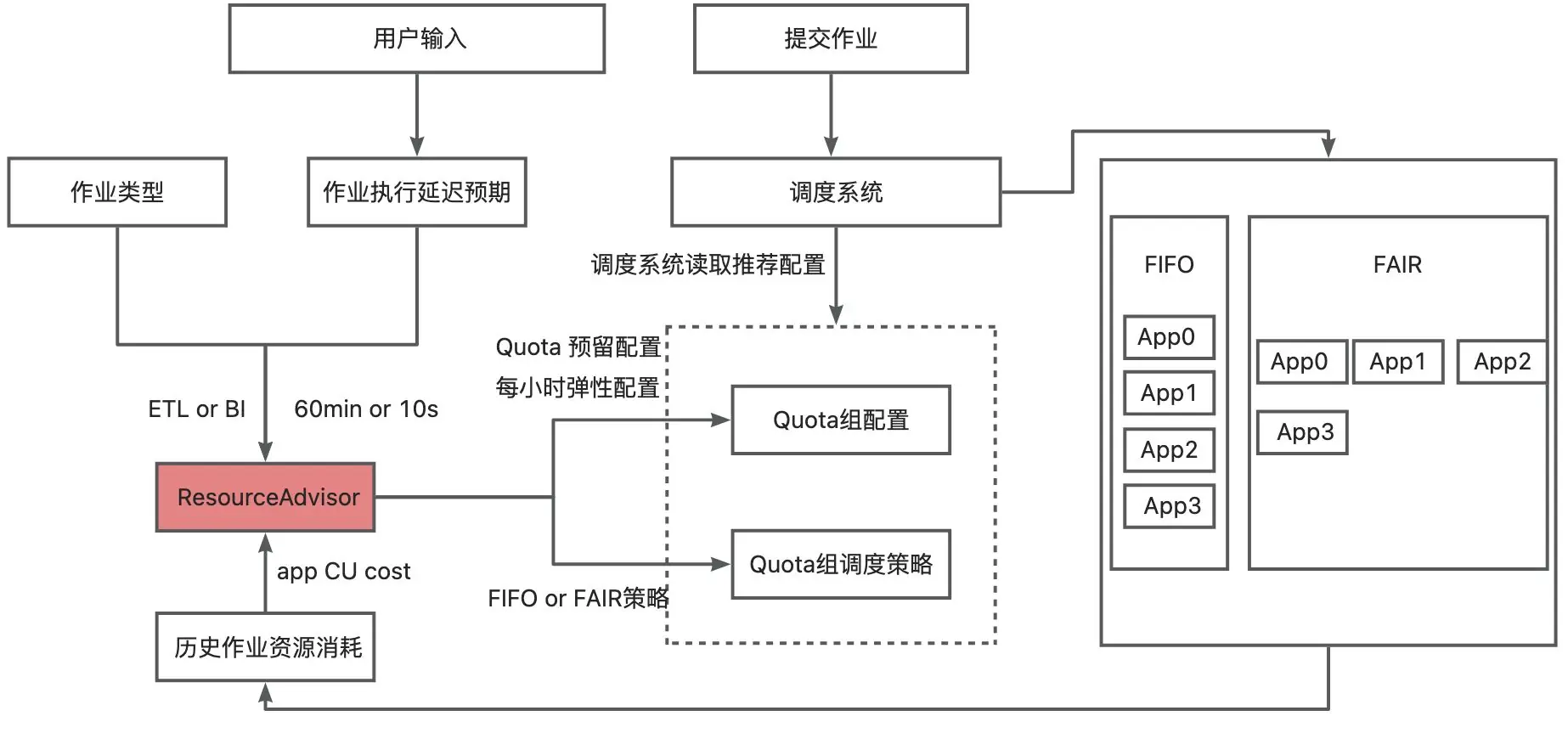
资源推荐工具(T+1动态调优)
核心功能:
- 基于历史数据的作业运行日志与资源消耗,结合作业类型(ETL/BI)的SLA要求,预测次日CU需求。
技术实现:
- 数据采集:抓取作业运行时长、CPU/内存消耗、并发度等指标。
- 作业分类模型:自动识别ETL/BI作业。
资源预测算法:
- 线性回归:基于历史资源消耗趋势预测基线需求。
- 弹性缓冲:根据业务波动率增加10%-20%冗余量。
- 反馈优化:每日对比实际资源消耗与预测值,动态调整模型参数。
2.1.4. 推荐效果
GoTerra迁入MaxCompute过程中,MaxCompute进行了深度架构升级和性能优化,同时在合理的资源配置规划下,根据用户历史作业数据定期推荐用户Quota组配置和策略,每月实际产生费用约降低到BigQuery的42%。
2.2. TopN Fair
2.2.1. 现有调度策略局限性
| FIFO | FAIR | |
|---|---|---|
| 调度策略说明 | 对于作业优先级相同的场景,资源将优先分配至先提交的作业。对于作业优先级不同的场景,即使优先级高的作业提交时间晚于优先级低的作业,资源也将优先分配至高优先级作业。 | 对于作业优先级相同的场景,资源将平均分配至同一时间提交的所有作业。对于作业优先级不同的场景,资源优先平均分配给优先级较高的作业,若有剩余,再平均分配给优先级较低的作业 |
| 优点&适用场景 | 保障先提交的作业优先执行,适合ETL类长时间任务 | 资源均分给最高优先级的所有作业,适合短时BI任务 |
| 缺点 | 小作业需等待长作业完成,导致延迟("头阻塞") | 先提交的作业可能因资源被平分走而延长执行时间 |
GOTO业务需求
混合负载场景:ETL(长作业)与BI(短作业)并存
核心诉求:
- 长作业优先:先提交的ETL作业需保障足够并发资源
- 短作业友好:后提交的BI作业可短时借用资源,但不显著影响长作业进度
2.2.2. 新策略:TopN Fair + 动态并发保障
2.2.2.1. 核心设计目标
- 资源隔离:确保长作业的最低并发度(JobMinimumConcurrency)。
- 弹性资源复用:在满足长作业的前提下,允许Quota组保留部分资源给短作业动态借用。
- 优先级分层:结合作业类型(ETL/BI)和提交时间,实现混合调度。
2.2.2.2. 关键参数定义
- JobMinimumConcurrency(最低并发度):
- 每个作业运行所需的最小并发度。
- 全局配置项,例如:JobMinimumConcurrency=10 表示每个作业至少分配10个并发单元。
- TopN Fair策略:
- TopN作业:按提交时间排序,在至少保障每个作业JobMinimumConcurrency并发度的情况下,挑选前N个作业分配Quota组资源
2.2.2.3. 动态N值计算公式

计算出N,如果 ,则
,则
符号解释:
 :第i个作业的资源需求(如CPU核数、内存)。
:第i个作业的资源需求(如CPU核数、内存)。- Runtime:Quota组当前可用的资源量
 :当前最少可参与资源分配的作业数
:当前最少可参与资源分配的作业数
公式含义: 动态计算N值,确保前N个作业的累计资源需求不超过Quota组总容量的JobMinimumConcurrency倍,且至少保障个作业参与资源分配,避免少量作业占满整个组;
2.2.3. 策略优势
| 维度 | FIFO | FAIR | TopN Fair + 短作业插队 |
|---|---|---|---|
| 长作业保障 | 强 | 弱 | 强 |
| 短作业支持 | 差 | 强 | 强 |
| 使用场景 | ETL | BI | ETL+BI混合场景 |
2.2.4. 实际效果
整集群作业平均运行数下降15.7%,作业运行时Latency 95分位值下降45.7%,GoTerra用户的效果较好的Quota组,作业平均运行数下降31.3%, 作业运行时Latency 95分位值下降75.4%。
3. 结语与展望
GoTerra迁移到MaxCompute后,Resource Advisor持续通过智能资源推荐优化成本,目标将总体费用控制在BigQuery的40%以内。随着新产品AutoScaleQuota上线,资源管理实现全自动化:基于业务负载动态调整配额,无需人工干预,彻底解决突发流量导致的资源不足与作业等待问题。同时,TopN Fair已在印尼集群全面上线,后续的发展方向:分析各Quota组作业执行模式,自动配置JobMinimumConcurrency并动态切换调度策略,进一步提升资源利用率。
在性能与成本优化的基础上,稳定性也是一个非常重要的目标,系统稳定性目标达99.99%可用性,保障GoTerra在MaxCompute上实现"低成本、高效率、强稳定"的运行体验。