引言
在标准 C 语言中,结构体(struct)、位段(Bit-field)、联合体(union)是内存操作的核心工具 ------ 结构体解决 "不同类型数据聚合" 问题
位段实现 "位级精细控制"
联合体通过 "内存共享" 优化空间。它们不依赖 C11/C17 等新版本特性,是嵌入式开发、底层编程、协议解析的基础技能。本文将基于标准 C 语言规范,从基础到实战全面拆解这三个知识点,覆盖核心用法与避坑要点。
一、结构体(struct):聚合不同类型数据的 "容器"
结构体的核心价值是将分散的不同类型变量打包成一个整体,方便数据组织、传递和维护,是 C 语言中构建复杂数据类型的基础。
1.1 基础定义与使用(标准 C 核心语法)
语法格式(3 种常用形式)
cpp
// 1. 普通命名结构体(可多次定义变量)
struct Student
{
char name[20]; // 字符串:姓名(基础类型)
int age; // 整型:年龄(基础类型)
float score; // 浮点型:成绩(基础类型)
struct Date // 嵌套结构体(成员为复杂类型)
{
int year;
int month;
int day;
} birthday; // 生日
};
// 2. 匿名结构体(无结构体名,仅能定义一次变量)
struct
{
int x; // x坐标
int y; // y坐标
} point; // 直接定义变量point,后续无法再用该结构体定义其他变量
// 3. typedef简化命名(工程最常用,避免重复写struct)
typedef struct
{
char id[10]; // 编号
float height; // 身高
} Person; // 后续可直接用Person定义变量,无需写struct Person核心操作:定义变量与访问成员
- 普通变量用 . 运算符访问成员;
- 指针变量用 -> 运算符访问成员;
- 支持整体赋值(同类型结构体)、成员单独赋值。
cpp
// 1. 普通变量定义与使用
Person p1 = {"001", 1.75f};
p1.id[0] = '1'; // 修改成员值
printf("id: %s, 身高: %.2f\n", p1.id, p1.height); // 输出:id: 101, 身高: 1.75
// 2. 指针变量定义与使用
Person *p2 = &p1;
p2->height = 1.80f; // 指针访问成员
printf("修改后身高: %.2f\n", p1.height); // 输出:1.80
// 3. 结构体整体赋值(同类型)
Person p3 = p1;
printf("p3.id: %s\n", p3.id); // 输出:101(复制p1的所有成员)
// 4. 嵌套结构体访问
struct Student s;
s.birthday.year = 2000;
s.birthday.month = 9;
printf("生日:%d年%d月\n", s.birthday.year, s.birthday.month);1.2 核心特性(标准 C 规范)
- 成员类型无限制:可包含基础类型(char/int/float)、数组、指针、其他结构体(嵌套),但不能包含自身(避免无限递归);
- 内存分配规则:总内存 = 各成员内存之和 + 内存对齐填充(核心难点,下文详解);
- 作用域:结构体定义若在函数内,仅在该函数内有效;若在函数外,全局有效(工程中建议全局定义在头文件)。
1.3 内存对齐
结构体的内存并非简单叠加,而是遵循内存对齐规则------CPU 访问内存时,要求数据存储在 "对齐边界" 上(如 int 需存在 4 的整数倍地址),目的是提升访问效率(避免 CPU 多次读取)。
标准 C 对齐规则(所有编译器通用)
- 结构体每个成员的偏移量(相对于结构体起始地址的距离)必须是该成员 "对齐值" 的整数倍;
- 结构体总大小必须是所有成员 "对齐值" 的最大公约数的整数倍;
- 基础类型的 "默认对齐值" = 其自身大小(如 char=1,short=2,int=4,float=4,double=8)。
示例:计算结构体大小(64 位 / 32 位编译器通用)
cpp
// 示例1:成员顺序影响内存大小
struct Test1
{
char a; // 偏移0(1的倍数),占用1字节
int b; // 对齐值4,偏移需是4的倍数→偏移4(填充3字节),占用4字节
char c; // 偏移8(1的倍数),占用1字节
};
// 总大小计算:8+1=9 → 需是4的倍数(最大对齐值4)→ 12字节
printf("Test1大小:%zu\n", sizeof(struct Test1)); // 输出12
// 示例2:优化成员顺序减少填充
struct Test2
{
char a; // 偏移0,占用1字节
char c; // 偏移1(1的倍数),占用1字节
int b; // 偏移4(4的倍数,填充2字节),占用4字节
};
// 总大小计算:4+4=8 → 是4的倍数→ 8字节(比Test1节省4字节)
printf("Test2大小:%zu\n", sizeof(struct Test2)); // 输出8对齐的实际意义
- 避免内存浪费:合理排序成员(小类型在前,大类型在后)可减少填充;
- 保证跨平台兼容性:不同编译器对齐规则一致,结构体大小在不同平台相同。
二、位段(Bit-field):位级精细控制的 "工具"
位段是结构体的特殊形式,核心是指定成员占用的二进制位数,实现内存的极致节省(如用 1 位存储布尔值),主要用于硬件寄存器操作、协议解析等 "按位定义数据" 的场景。
2.1 基础定义与语法(标准 C 规范)
语法格式
cpp
struct 位段名
{
// 位段成员:类型 成员名: 位数;
unsigned int flag1 : 1; // 1位:存储0/1(布尔值,推荐unsigned int)
signed int mode : 3; // 3位:存储-4~3(有符号,最高位为符号位)
unsigned int value : 4; // 4位:存储0~15(无符号)
unsigned int : 2; // 无名位段:填充2位,无访问方式
unsigned int : 0; // 位数为0:强制结束当前字节,下一个成员从新字节开始
};标准 C 核心限制(必须遵守)
- 类型限制:位段成员的类型只能是 unsigned int、signed int 或 _Bool(C99 新增),不能是 char、float 等其他类型;
- 位数限制:位数不能超过对应类型的总位数(如 32 位系统中,unsigned int 是 32 位,位数不能≥32);
- 无名位段:仅用于填充(位数≠0)或强制对齐(位数 = 0),不能被访问。
2.2 内存分配机制(标准 C 规则)
位段的内存分配以 "基础类型大小" 为单位(如 unsigned int 为 4 字节),遵循以下规则:
- 位段成员优先在当前 "基础类型字节块" 内分配,若剩余位数不足,是否跨字节分配由编译器决定(标准 C 未明确,但主流编译器默认不跨字节);
- 字节序(大端 / 小端)影响位段存储顺序:小端模式下,低位在前;大端模式下,高位在前(嵌入式开发需注意)。
示例:位段内存布局(小端模式,32 位编译器)
cpp
struct Protocol
{
unsigned int version: 4; // 版本号(4位)
unsigned int type: 2; // 类型(2位)
unsigned int reserved: 2; // 保留位(2位)→ 共8位,占1字节
unsigned int length: 16; // 长度(16位)→ 占2字节
};
// 总大小:4字节(1+2=3字节,填充1字节至4字节对齐,基础类型是unsigned int)
printf("Protocol大小:%zu\n", sizeof(struct Protocol)); // 输出42.3 核心应用场景(标准 C 实战)
场景 1:嵌入式硬件寄存器操作(最经典)
硬件寄存器的每一位对应特定功能(如使能、中断、模式),位段可直接映射寄存器地址,直观操作每一位:
cpp
// 假设0x40001000是GPIO控制寄存器的地址(32位)
#define GPIO_CTRL ((struct GPIO_Reg *)0x40001000)
// 定义寄存器位段(映射每一位功能)
struct GPIO_Reg
{
unsigned int output_en: 1; // 第0位:输出使能(1=使能,0=禁用)
unsigned int input_en: 1; // 第1位:输入使能
unsigned int mode: 2; // 第2-3位:工作模式(0=输入,1=输出,2=复用)
unsigned int reserved: 28; // 第4-31位:保留位(无功能,填0)
};
// 操作寄存器:使能GPIO输出,设置为输出模式
void GPIO_Init()
{
GPIO_CTRL->output_en = 1; // 第0位置1:使能输出
GPIO_CTRL->mode = 1; // 第2-3位置01:输出模式
}场景 2:协议解析(串口 / 网络通信)
串口协议、网络协议(如 IP、TCP)的字段常以 "位" 为单位定义,位段可直接解析数据包,无需手动移位:
cpp
// 串口通信协议:1字节数据帧(前4位命令,后4位参数)
struct Frame
{
unsigned int cmd: 4; // 命令码(4位:0=读,1=写,2=配置)
unsigned int param: 4; // 参数(4位)
};
// 解析接收到的数据包
void ParseFrame(unsigned char data)
{
struct Frame *frame = (struct Frame *)&data; // 强制转换为位段指针
printf("命令码:%d,参数:%d\n", frame->cmd, frame->param);
// 根据命令执行操作
if (frame->cmd == 1)
{
printf("执行写操作,参数:%d\n", frame->param);
}
}
// 调用示例:接收到数据0x12(二进制00010010)
ParseFrame(0x12); // 输出:命令码:1,参数:2三、联合体(union):内存共享的 "复用容器"
联合体的核心特性是所有成员共享同一块内存空间,同一时间只能存储一个成员的值,用于优化内存或实现类型转换(无未定义行为)。
3.1 基础定义与内存布局(标准 C 核心)
语法格式
cpp
// 1. 普通联合体
union Data
{
int i; // 整型(4字节)
float f; // 浮点型(4字节)
char c[4]; // 字符数组(4字节)
};
// 2. 嵌套结构体的联合体(工程常用)
struct Value
{
char type; // 联合体union类型标识:'i'=int,'f'=float(区分当前存储的成员)
union // 匿名联合体(嵌套时可省略名称)
{
int i_val;
float f_val;
};
};标准 C 核心特性
- 内存共享:所有成员的起始地址相同,总大小 = 最大成员的大小;
- 值覆盖:修改一个成员会覆盖其他成员的值(内存重叠);
- 访问规则:同一时间只能访问 "当前赋值的成员",访问未赋值成员会得到随机值(无意义)。
示例:内存共享验证(32 位编译器)
cpp
// 1. 普通联合体
union Data
{
int i; // 整型(4字节)
float f; // 浮点型(4字节)
char c[4]; // 字符数组(4字节)
};
// 2. 嵌套结构体的联合体(工程常用)
struct Value
{
char type; // 联合体union类型标识:'i'=int,'f'=float(区分当前存储的成员)
union // 匿名联合体(嵌套时可省略名称)
{
int i_val;
float f_val;
};
};
union Data d;
d.i = 0x12345678; // 给整型成员赋值(十六进制)
// 验证内存共享:所有成员地址相同
printf("d.i地址:%p\n", &d.i); // 输出:0x7ffee4b7e8ac(示例地址)
printf("d.f地址:%p\n", &d.f); // 输出:0x7ffee4b7e8ac(同一地址)
printf("d.c地址:%p\n", d.c); // 输出:0x7ffee4b7e8ac(同一地址)
// 验证值覆盖:字符数组成员读取整型内存(小端模式)
printf("d.c[0]:0x%x\n", d.c[0]); // 输出0x78(低字节在前)
printf("d.c[3]:0x%x\n", d.c[3]); // 输出0x12(高字节在后)
// 联合体总大小 = 最大成员大小(4字节)
printf("Data大小:%zu\n", sizeof(union Data)); // 输出43.2 核心应用场景(标准 C 实战)
场景 1:节省内存(嵌入式 / 受限环境)
当变量只需 "二选一" 存储(如同一字段可能是 int 或 float),用联合体替代结构体可大幅减少内存占用:
cpp
// 反面示例:结构体(占用8字节:4+4)
struct WasteMem
{
int i;
float f;
};
// 正面示例:联合体(占用4字节:max(4,4))
union SaveMem
{
int i;
float f;
};
printf("结构体大小:%zu\n", sizeof(struct WasteMem)); // 输出8
printf("联合体大小:%zu\n", sizeof(union SaveMem)); // 输出4(节省50%内存)场景 2:安全的类型转换(无未定义行为)
联合体可替代强制类型转换,直接解析二进制数据(如 int 转 float 的二进制结构):
cpp
// 用联合体实现int到float的二进制转换(标准C合法,无未定义行为)
union IntToFloat
{
int i;
float f;
};
void ConvertIntToFloat(int val)
{
union IntToFloat utf;
utf.i = val;
printf("int:%d → float:%f\n", val, utf.f);
}
// 调用示例:解析int的二进制对应的float值
ConvertIntToFloat(0x41480000); // 输出:int:1094062080 → float:10.500000场景 3:变体类型(存储不同类型数据)
如配置参数、JSON 解析结果等,需存储不同类型的值,用 "类型标识 + 联合体" 实现:
cpp
// 定义类型枚举(区分存储的成员)
typedef enum { TYPE_INT, TYPE_FLOAT, TYPE_STR } ValType;
// 变体类型结构体
typedef struct
{
ValType type; // 类型标识
union // 存储不同类型的值
{
int i;
float f;
char *s;
} val;
} Variant;
// 使用示例:存储不同类型数据
Variant v1 = {TYPE_INT, .val.i = 100};
Variant v2 = {TYPE_FLOAT, .val.f = 3.14f};
Variant v3 = {TYPE_STR, .val.s = "hello"};
// 访问示例:根据类型标识安全访问
void PrintVariant(Variant v)
{
switch (v.type)
{
case TYPE_INT:
printf("int值:%d\n", v.val.i);
break;
case TYPE_FLOAT:
printf("float值:%.2f\n", v.val.f);
break;
case TYPE_STR:
printf("字符串:%s\n", v.val.s);
break;
}
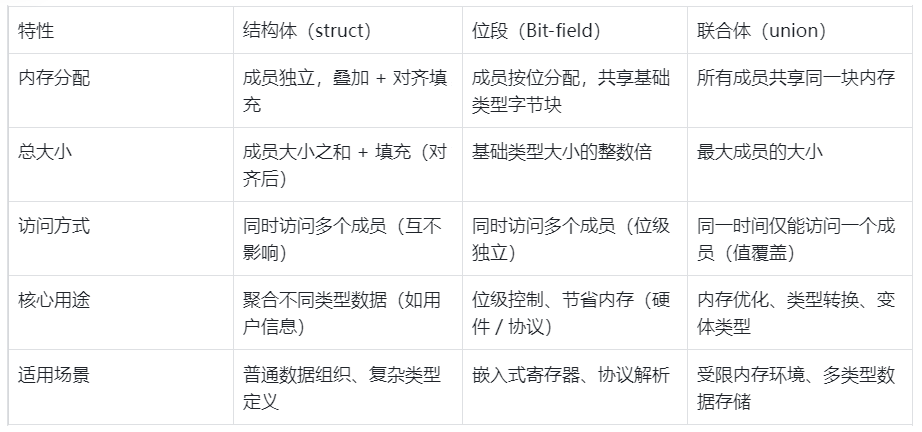
}四、结构体、位段、联合体核心对比(标准 C)
五、标准 C 常见陷阱与最佳实践
5.1 结构体陷阱
陷阱 1:成员顺序导致内存浪费
cpp
// 坏示例:1+4+8=13字节 → 对齐后16字节(填充3字节)
struct BadOrder { char a; int b; double c; };
// 好示例:1+1+4+8=14字节 → 对齐后16字节(填充2字节)?不,更优排序:
struct GoodOrder { char a; char b; int c; double d; };
// 总大小:16字节(1+1+2填充+4+8=16,无额外填充)最佳实践:按 "对齐值从小到大" 排序成员(char < short < int < float < double),最小化填充。
陷阱 2:结构体赋值与指针拷贝混淆
cpp
struct Person p1 = {"001", 1.75f};
struct Person *p2 = &p1;
struct Person p3 = p1; // 值拷贝:p3是独立变量,修改p3不影响p1
p2->height = 1.80f; // 指针操作:修改p1的height(p2指向p1)注意:结构体整体赋值是 "值拷贝"(独立内存),指针赋值是 "地址拷贝"(共享内存)
5.2 位段陷阱
陷阱 1:跨平台兼容性问题
位段的跨字节分配、字节序依赖编译器,不同平台可能有差异:
cpp
// 警告:以下代码在小端和大端平台结果不同
struct BitTest
{
unsigned int a: 4;
unsigned int b: 4;
};
union Data d;
d.bit.a = 0x1;
d.bit.b = 0x2;
// 小端:d.c[0] = 0x21(b在前,a在后);大端:d.c[0] = 0x12(a在前,b在后)最佳实践:
- 仅在 "位定义明确且平台固定" 的场景使用(如嵌入式);
- 跨平台代码用宏定义位操作替代位段(如#define BIT0 (1<<0))
陷阱 2:有符号位段的溢出问题
cpp
struct SignedBit
{
signed int val: 2; // 有符号,范围-2~1
};
struct SignedBit sb;
sb.val = 2; // 溢出:实际存储-2(二进制10是-2的补码)
printf("val: %d\n", sb.val); // 输出-2
最佳实践:存储无符号值用unsigned int,避免有符号位段溢出。
5.3 联合体陷阱
陷阱 1:访问未赋值的成员
cpp
union Data d;
d.i = 100;
printf("d.f: %f\n", d.f); // 未定义行为:用float解析int内存,结果无意义规则:赋值哪个成员,就只能访问哪个成员(类型转换场景除外)。
陷阱 2:成员大小不一致导致内存越界
cpp
union BadUnion
{
int i; // 4字节
long long l; // 8字节
};
union BadUnion bu;
bu.i = 100;
printf("bu.l: %lld\n", bu.l); // 未定义行为:l比i大,剩余4字节是随机值
cpp
最佳实践:联合体成员大小尽量一致(如 int 和 float 都是 4 字节),避免越界5.4 通用最佳实践
- 优先用typedef简化结构体 / 联合体命名(工程可读性);
- 位段仅用于 "必须按位存储" 的场景,普通场景用结构体;
- 跨平台代码避免依赖位段的内存布局,用宏定义位操作;
- 联合体类型转换时,确保成员大小一致(如 int 和 float);
- 结构体 / 联合体定义时,添加注释说明每个成员的含义(尤其是位段和硬件相关)。
总结
标准 C 语言的结构体位段联合体是底层编程的 "三剑客":
- 结构体:解决 "数据聚合" 问题,是复杂类型的基础;
- 位段:解决 "位级控制" 问题,是硬件操作和协议解析的利器;
- 联合体:解决 "内存优化" 问题,是受限环境和多类型存储的选择。
掌握它们的核心原理(内存分配、对齐规则)和标准用法,能让你在嵌入式开发、系统编程、协议解析等场景中写出更高效、更可靠的代码。实践中需注意避坑,遵循最佳实践,尤其关注跨平台兼容性和内存安全。