准备工作
- JDK17
- Postgresql
- MySQL
POM依赖
xml
<dependencies>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>自主指定依赖版本。
公共代码
java
package com.polaris.database.link;
import lombok.Data;
import java.math.BigDecimal;
import java.time.LocalDateTime;
/**
* @author DawnStar
* @since 2025/11/2
*/@Data
public class Account {
private Integer id;
private String name;
private BigDecimal balance;
private Boolean locked;
private LocalDateTime accessTime;
}
java
package com.polaris.database.link;
import java.io.InputStream;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.util.Properties;
/**
* @author DawnStar
* @since 2025/11/2
*/public class ConnectionLink {
private static Properties properties;
private static synchronized Properties getProperties() {
if (properties != null) {
return properties;
} // 加载 resources 文件下的资源
try (InputStream stream = ConnectionLink.class.getResourceAsStream("/database.properties")) {
properties = new Properties();
properties.load(stream);
} catch (Exception e) {
throw new RuntimeException(e);
} return properties;
}
public static Connection getConnection() throws SQLException {
Properties properties = getProperties();
String url = properties.getProperty("database.url");
String password = properties.getProperty("database.password");
String user = properties.getProperty("database.user");
return DriverManager.getConnection(url, user, password);
}
}项目结构
连接数据库步骤
Java使用数据库通常有以下五个步骤
- 加载数据库驱动
- 连接数据库
- 创建Statement对象
- 执行SQL并处理结果
- 关闭连接并释放资源
java
package com.polaris.database.link;
import java.io.InputStream;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.Properties;
/**
* @author DawnStar
* @since 2025/11/2
*/public class UseDatabase {
public static void main(String[] args) throws Exception {
// 加载postgresql数据库驱动
Class.forName("org.postgresql.Driver");
// 建立数据库连接
Connection connection = ConnectionLink.getConnection();
System.out.println(connection.getMetaData().getJDBCMajorVersion());
// 创建执行语句
PreparedStatement preparedStatement = connection.prepareStatement("select version();");
// 处理操作结果
ResultSet resultSet = preparedStatement.executeQuery();
while (resultSet.next()) {
System.out.println(resultSet.getString(1));
} //关闭数据库连接
connection.close();
}
}debug java.sql.DriverManager#getConnection(java.lang.String, java.util.Properties, java.lang.Class<?>)中指定的方法,可以看到registeredDrivers已经含有了我们的MySQL和Postgresql驱动。

通过迭代来获取对应的Connection连接:
java
Connection con = aDriver.driver.connect(url, info);如果匹配,则返回第一个已经匹配的连接。如Postgresql的实现,第一步匹配url来确认是否匹配当前的Driver:
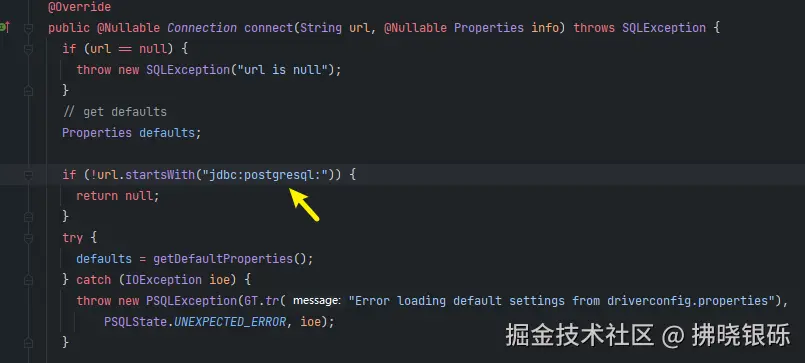
在JDBC4.0之后的版本, 可以省略 Class.forName("org.postgresql.Driver");手动加载驱动类的步骤,而是通过SPI实现自动加载驱动类。
既然可以省略手动加载驱动 的步骤,那么是如何实现的呢? 答案就在java.sql.DriverManager#ensureDriversInitialized 方法中:

核心为下述代码块:
java
ServiceLoader<Driver> loadedDrivers = ServiceLoader.load(Driver.class);这里即为SPI实现代码的入口。详情在\[Java SPI机制\|SPI机制]文章中。在这个内容为什么第一步是Class.forName去加载类,而不是使用 new 创建实例来使用数据呢?
Class.forName只会加载类并执行静态代码块,并不会直接直接实例化类。- 使用**
new** 会直接将实现类的对象暴露在我们的代码中,如果我们没有引入对应的依赖则会导致项目编译失败。而Class.forName则不会,只有执行到这一行代码的时候才会抛出ClassNotFoundException异常。实现了解耦。
CURD的基本使用
java
package com.polaris.database.link;
import java.io.InputStream;
import java.math.BigDecimal;
import java.sql.*;
import java.time.LocalDate;
import java.time.LocalDateTime;
import java.time.LocalTime;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.ThreadLocalRandom;
import java.util.function.Consumer;
/**
* @author DawnStar
* @since 2025/11/2
*/public class CurdOptions {
private static final ThreadLocalRandom RANDOM = ThreadLocalRandom.current();
public static void main(String[] args) throws Exception {
Connection connection = ConnectionLink.getConnection();
// 创建表
createTable(connection);
// 插入数据
insert(connection);
// 查询数据
System.out.println(query(10, connection));
// 更新数据
update(connection);
// 删除数据
delete(connection);
// 删除表
drop(connection);
// 创建模式
createSchema(connection);
connection.close();
}
private static void drop(Connection connection) throws Exception {
Statement statement = connection.createStatement();
int row = statement.executeUpdate("drop table if exists accounts;");
System.out.println("删除表更新的行数:" + row);
statement.close();
}
public static void createSchema(Connection connection) throws Exception {
Statement statement = connection.createStatement();
int row = statement.executeUpdate("create schema if not exists test;");
System.out.println("创建模式返回行数:" + row);
statement.close();
}
public static void createTable(Connection connection) throws Exception {
String createSql = """
create table if not exists accounts ( id integer not null primary key, name varchar(45) not null, balance numeric(16, 4) not null, access_time timestamp not null, locked boolean default false not null ); comment on table accounts is '账户表';
comment on column accounts.name is '账号名称';
comment on column accounts.balance is '余额';
comment on column accounts.access_time is '访问时间';
comment on column accounts.locked is '锁定';
""";
PreparedStatement statement = connection.prepareStatement(createSql);
int update = statement.executeUpdate();
System.out.println("创建表影响行数:" + update);
statement.close();
}
public static void insert(Connection connection) throws SQLException {
List<Account> accounts = new ArrayList<>();
for (int i = 0; i < 10; i++) {
accounts.add(generateAccount(i + 1));
} insert(accounts, connection);
}
public static void insert(List<Account> accounts, Connection connection) throws SQLException {
if (accounts == null || accounts.size() == 0) {
return;
} // 插入语句
PreparedStatement statement = connection.prepareStatement("insert into accounts(id,name,balance,access_time,locked) values (?,?,?,?,?)");
Consumer<PreparedStatement> consumer;
boolean supportsBatchUpdates = connection.getMetaData().supportsBatchUpdates();
System.out.println("支持批量更新:" + supportsBatchUpdates);
// 是否支持批量更新
if (supportsBatchUpdates) {
consumer = option -> {
try {
option.addBatch();
} catch (SQLException e) {
throw new RuntimeException(e);
} }; } else {
consumer = option -> {
try {
option.executeUpdate();
} catch (SQLException e) {
throw new RuntimeException(e);
} }; }
connection.setAutoCommit(false);
try {
for (Account account : accounts) {
statement.setInt(1, account.getId());
statement.setString(2, account.getName());
statement.setBigDecimal(3, account.getBalance());
statement.setObject(4, account.getAccessTime());
statement.setBoolean(5, account.getLocked());
consumer.accept(statement);
} if (supportsBatchUpdates) {
statement.executeBatch();
} connection.commit();
} catch (Exception e) {
connection.rollback();
} finally {
connection.setAutoCommit(true);
} statement.close();
}
public static List<Account> query(int lastId, Connection connection) throws Exception {
PreparedStatement statement = connection.prepareStatement("select * from accounts where id < ?");
statement.setInt(1, lastId);
ResultSet resultSet = statement.executeQuery();
List<Account> accounts = new ArrayList<>();
while (resultSet.next()) {
Account account = generateAccount(resultSet);
accounts.add(account);
} statement.close();
return accounts;
}
private static Account generateAccount(ResultSet resultSet) throws Exception {
Account account = new Account();
account.setId(resultSet.getInt(1));
account.setName(resultSet.getString("name"));
account.setBalance(resultSet.getBigDecimal(3));
account.setAccessTime(resultSet.getObject(4, LocalDateTime.class));
account.setLocked(resultSet.getBoolean(5));
return account;
}
public static Account generateAccount(Integer id) {
Account account = new Account();
account.setName("测试" + RANDOM.nextDouble(10.10, 50.99));
account.setBalance(BigDecimal.valueOf(RANDOM.nextDouble(100, 5000)));
account.setLocked(RANDOM.nextBoolean());
account.setId(id);
account.setAccessTime(LocalDateTime.of(LocalDate.of(2025, 10, RANDOM.nextInt(1, 31)), LocalTime.of(RANDOM.nextInt(0, 24), RANDOM.nextInt(0, 60), RANDOM.nextInt(0, 60))));
return account;
}
public static void update(Connection connection) throws Exception {
PreparedStatement statement = connection.prepareStatement("select * from accounts where id =1");
ResultSet resultSet = statement.executeQuery();
if (resultSet.next()) {
Account account = generateAccount(resultSet);
System.out.println("当前账户数据:" + account);
} PreparedStatement updateStatement = connection.prepareStatement("update accounts set balance = ? where id = ?");
updateStatement.setBigDecimal(1, BigDecimal.valueOf(555));
updateStatement.setInt(2, 1);
int i = updateStatement.executeUpdate();
System.out.println("更新行数:" + i);
ResultSet updateResult = statement.executeQuery();
if (updateResult.next()) {
Account account = generateAccount(updateResult);
System.out.println("当前账户数据:" + account);
} statement.close();
updateStatement.close();
}
public static void delete(Connection connection) throws Exception {
PreparedStatement statement = connection.prepareStatement("delete from accounts where id > -1");
int rows = statement.executeUpdate();
System.out.println("删除行数:" + rows);
statement.close();
}
}Postgresql数据库有模式的概念。MySQL 中 schema 就是 database,也就是没有物理上的模式。
java
PreparedStatement statement = connection.prepareStatement("insert into accounts(id,name,balance,access_time,locked) values (?,?,?,?,?)");上述代码创建了一个预备语句 ,通过占位符?来填充我们所需要的参数值,从而达到多次重用的的目的。对于需要填充的SQL建议使用 PreparedStatement而不是 Statement,避免SQL注入风险。如果不需要填充参数,直接使用 Statement对象即可。
占位符?通过 PreparedStatement的setXxx()方法来设置,如Int类型是setInt来设置值,如果没有对应的类型,则使用 setObject()方法来填充。 占位符从1开始计算。
对于 select语句,需要执行 executeQuery()方法获取 ResultSet 结果集。 对于 insert、 update、delete、create、drop等执行 executeUpdate()返回影响的行数。
注意的是 :create、drop执行的是表结构而不是数据,所以返回的影响行数都为0。
ResultSet结果集
查看以下query()例子,ResultSet 通过 next()方法来移动到下一行,移动到第一行时,需要执行一次 next()方法。 同类似PreparedStatement类型,根据返回数据的对应的列使用对应的getXxx方法,没有对应的类型则使用getObject来获取,如 LocalDateTime。
java
private static Account generateAccount(ResultSet resultSet) throws Exception {
Account account = new Account();
account.setId(resultSet.getInt(1));
account.setName(resultSet.getString("name"));
account.setBalance(resultSet.getBigDecimal(3));
account.setAccessTime(resultSet.getObject(4, LocalDateTime.class));
account.setLocked(resultSet.getBoolean(5));
return account;
}获取指定列同样也是从1起始 ,除了获取列索引,还提供了根据列名称匹配列值,如:
String getString(String columnLabel) throws SQLException;String getString(String columnLabel) throws SQLException;<T> T getObject(int columnIndex, Class<T> type) throws SQLException;<T> T getObject(String columnLabel, Class<T> type) throws SQLException;
事务
!info 事务是单个原子命令的命令组合,要么全部成功或全部失败。在事务完成之前对其他会话不可见。事务有ACID4个特性:
- Atomicity: 原子性,所有操作要么作为单个单元完成,要么一个都不完成。如果事务执行期间出现系统故障,会没有部分结果,恢复后可见。
- Consistency: 一致性,数据库中的数据始终符合完整性约束的性质。事务可能允许在提交之前违反一些约束,但是如果在发生时仍然没有解决则会自动回滚。
- Isolation: 隔离性,事务在提交之前对并发事务不可见的属性。
- Durability: 持久性,一旦事务被提交完成,即使系统故障和崩溃之后,更改仍然存在。
默认情况下,JDBC的数据连接处于自动提交模式(atuocommit mode),即每个SQL一旦被执行就直接提交到数据库,无法对已经修改的数据进行回滚。通过 getAutoCommit() 获取当前数据库连接的提交模式
java
System.out.println("是否自动提交:" + connection.getAutoCommit());在使用事务时候,将这个默认值设置为false,即:
java
// 设置不自动提交
connection.setAutoCommit(false);注意:无论执行的事务是否成功,都需要将当前连接修改回自动提交模式,避免后续其他SQL语句执行出现问题。
示例
java
package com.polaris.database.link;
import java.io.InputStream;
import java.math.BigDecimal;
import java.sql.*;
import java.util.*;
/**
* @author DawnStar
* @since 2025/11/2
*/public class TransactionOptions {
public static void main(String[] args) throws Exception {
Connection connection = ConnectionLink.getConnection();
System.out.println("是否自动提交:" + connection.getAutoCommit());
CurdOptions.createTable(connection);
List<Account> accounts = CurdOptions.query(100, connection);
Set<Integer> idSet = new HashSet<>();
idSet.add(88);
idSet.add(99);
accounts.forEach(item -> idSet.remove(item.getId()));
List<Account> accountInsertList = idSet.stream().map(CurdOptions::generateAccount).toList();
// 插入没有的88,99数据
CurdOptions.insert(accountInsertList, connection);
// 设置不自动提交
connection.setAutoCommit(false);
PreparedStatement preparedStatement = connection.prepareStatement("update accounts set balance = ? where id = ?");
try {
// 提交成功
preparedStatement.setBigDecimal(1, BigDecimal.valueOf(90.56));
preparedStatement.setInt(2, 88);
System.out.println("更新影响行数:" + preparedStatement.executeUpdate());
// 提交失败
// preparedStatement.setBigDecimal(1, BigDecimal.valueOf(310.56));
preparedStatement.setBigDecimal(1, null);
preparedStatement.setInt(2, 99);
System.out.println("更新影响行数:" + preparedStatement.executeUpdate());
connection.commit();
System.out.println("提交成功...");
} catch (Exception e) {
connection.rollback();
System.out.println("回滚...");
} finally {
// 恢复自动提交
connection.setAutoCommit(true);
} connection.close();
}}可以看到,通过设置connection.setAutoCommit(false);不启用默认提交。使用connection.commit();进行手动提交。
如果注释掉connection.setAutoCommit(false),那么第一个executeUpdate将会执行,同时发生错误并不会回滚。

保存点
!info 保存点(save point)是数据库提供可以更细粒度地控制回滚操作操作的机制。 创建一个保存点,意味着在执行事务失败的时候,我们可以回滚到这个保存点,而不是放弃整个事务。
下面代码为保存两条插入数据,后续的两条数据丢弃。
java
public class SavePointOptions {
public static void main(String[] args) throws Exception {
Connection connection = ConnectionLink.getConnection();
CurdOptions.createTable(connection);
// 清空数据
CurdOptions.delete(connection);
List<Account> accounts = new ArrayList<>();
accounts.add(CurdOptions.generateAccount(134));
int savePointId = 135;
accounts.add(CurdOptions.generateAccount(savePointId));
Account account2 = CurdOptions.generateAccount(136);
// 该字段不能为空,插入会报错
account2.setBalance(null);
accounts.add(account2);
accounts.add(CurdOptions.generateAccount(137));
// 插入语句
PreparedStatement statement = connection.prepareStatement("insert into accounts(id,name,balance,access_time,locked) values (?,?,?,?,?)");
connection.setAutoCommit(false);
Savepoint savepoint = null;
try {
for (Account account : accounts) {
statement.setInt(1, account.getId());
statement.setString(2, account.getName());
statement.setBigDecimal(3, account.getBalance());
statement.setObject(4, account.getAccessTime());
statement.setBoolean(5, account.getLocked());
statement.addBatch();
if (account.getId() == savePointId) {
statement.executeBatch();
savepoint = connection.setSavepoint();
} } statement.executeBatch();
connection.commit();
} catch (Exception e) {
if (savepoint != null) {
connection.rollback(savepoint);
System.out.println("回滚到保存点");
// 释放保存点
connection.releaseSavepoint(savepoint);
} else {
connection.rollback();
System.out.println("全部回滚");
} } finally {
connection.setAutoCommit(true);
} System.out.println(CurdOptions.query(140, connection));
connection.close();
}}Connection 部分API
| API | 描述 |
|---|---|
getSchema |
返回当前模式的名称,没有则返回null |
getCatalog |
返回当前数据库名称,如果没有则返回null |
isReadOnly |
当前连接是否只读模式,true为启用,false为禁用 |
setReadOnly |
设置只读模式 |
元数据,自动化构建实体类
!info DatabaseMetaData 是一个获取数据库整体的全面信息的接口,即元数据接口。 诸如 MyBatis-Plus 代码生成器 代码生成器 | MyBatis-Plus ,根据这个接口提供的API,我们可以实现类似该功能的个人数据库代码生成器模板。
示例
java
package com.polaris.database.link;
import java.math.BigDecimal;
import java.sql.Types;
import java.time.LocalDate;
import java.time.LocalDateTime;
/**
* @author DawnStar
* @since 2025/11/3
*/
public enum JdbcType {
/**
* 数据库类型与Java 类型映射
简单的例子
*/
LOCAL_DATE_TIME(Types.TIMESTAMP, LocalDateTime.class),
VARCHAR(Types.VARCHAR, String.class),
CHAR(Types.CHAR, String.class),
BIT(Types.BIT, Boolean.class),
LOCAL_DATE(Types.DATE, LocalDate.class),
DECIMAL(Types.DECIMAL, BigDecimal.class),
BOOLEAN(Types.BOOLEAN, Boolean.class),
NUMERIC(Types.NUMERIC, BigDecimal.class),
INTEGER(Types.INTEGER, Integer.class);
private final int type;
private final Class<?> clazz;
JdbcType(int type, Class<?> clazz) {
this.type = type;
this.clazz = clazz;
}
public static JdbcType getJavaType(int dataType) {
for (JdbcType value : JdbcType.values()) {
if (value.type == dataType) {
return value;
} } throw new IllegalArgumentException("没有指定对应Java类型:" + dataType);
}
public int getType() {
return type;
}
public Class<?> getClazz() {
return clazz;
}}
java
package com.polaris.database.link;
import lombok.AllArgsConstructor;
import lombok.Data;
import java.io.File;
import java.io.FileOutputStream;
import java.nio.charset.StandardCharsets;
import java.sql.Connection;
import java.sql.DatabaseMetaData;
import java.sql.ResultSet;
import java.time.LocalDate;
import java.util.*;
/**
* @author DawnStar
* @since 2025/11/2
*/
public class AutoGenerateClass {
public static void main(String[] args) throws Exception {
String targetTable = "accounts";
// 获取当前项目目录
String currentUserDir = System.getProperty("user.dir");
// 如果没有建立 database-link 子模块,可以省略该路径
String path = "database-link" + File.separator + "src" + File.separator + "main" + File.separator + "java";
// 指定的包下
String packageName = "com.polaris.database.link.gen";
String packagePath = packageName.replace(".", File.separator);
String absolutePath = currentUserDir + File.separator + path + File.separator + packagePath;
File file = new File(absolutePath);
if (!file.exists()) {
boolean mkdir = file.mkdir();
System.out.println("创建目录 " + file.getName() + ":" + mkdir);
}
Connection connection = ConnectionLink.getConnection();
System.out.println(connection.getSchema());
System.out.println(connection.getCatalog());
DatabaseMetaData metaData = connection.getMetaData();
ResultSet resultSet = metaData.getTables(null, null, null, new String[]{"TABLE"});
Map<String, Set<Class<?>>> tableDependMap = new HashMap<>(16);
Map<String, List<TypeInfo>> tableFieldMap = new HashMap<>(16);
while (resultSet.next()) {
String tableName = resultSet.getString("TABLE_NAME");
if (!targetTable.equals(tableName)) {
continue;
} String fileName = snakeCaseToLowerCameCase(tableName, true);
// 获取指定表中的数据
ResultSet columns = metaData.getColumns(null, resultSet.getString(2), tableName, null);
Set<Class<?>> set = new HashSet<>();
List<TypeInfo> fields = new ArrayList<>();
while (columns.next()) {
String columnName = columns.getString("COLUMN_NAME");
int dataType = columns.getInt("DATA_TYPE");
String remarks = columns.getString("REMARKS");
JdbcType javaType = JdbcType.getJavaType(dataType);
set.add(javaType.getClazz());
String cameCase = snakeCaseToLowerCameCase(columnName, false);
fields.add(new TypeInfo(cameCase, javaType.getClazz(), remarks));
} tableDependMap.put(fileName, set);
tableFieldMap.put(fileName, fields);
} connection.close();
for (Map.Entry<String, Set<Class<?>>> entry : tableDependMap.entrySet()) {
StringBuilder builder = new StringBuilder();
// 写入表头
builder.append("package ").append(packageName).append(";").append("\n\n");
for (Class<?> aClass : entry.getValue()) {
builder.append("import ").append(aClass.getName()).append(";\n");
} builder.append("\n\n");
builder.append("/**\n")
.append("* @author DawnStar\n")
.append("* @since ").append(LocalDate.now()).append("\n")
.append("*/\n");
builder.append("public class ").append(entry.getKey()).append(" {\n\n");
// 添加 属性
List<TypeInfo> typeInfoList = tableFieldMap.getOrDefault(entry.getKey(), new ArrayList<>());
for (TypeInfo typeInfo : typeInfoList) {
builder.append(generateField(typeInfo.getFieldName(), typeInfo.getType(), typeInfo.getRemark())).append("\n");
}
// 添加 get set for (TypeInfo typeInfo : typeInfoList) {
String methodName = snakeCaseToLowerCameCase(typeInfo.getFieldName(), true);
builder.append("\n");
// get
builder.append(" public ").append(typeInfo.getType().getSimpleName()).append(" get").append(methodName).append("() {\n");
builder.append(" return this.").append(typeInfo.getFieldName()).append(";\n");
builder.append(" }");
// set
builder.append("\n\n");
builder.append(" public void set").append(methodName).append("(").append(typeInfo.getType().getSimpleName()).append(" ").append(typeInfo.getFieldName()).append(") {\n");
builder.append(" this.").append(typeInfo.getFieldName()).append(" = ").append(typeInfo.getFieldName()).append(";\n");
builder.append(" }\n");
}
builder.append("}");
try (FileOutputStream stream = new FileOutputStream(absolutePath + File.separator + entry.getKey() + ".java")) {
stream.write(builder.toString().getBytes(StandardCharsets.UTF_8));
} }
}
private static String snakeCaseToLowerCameCase(String name, boolean firstUpper) {
StringBuilder builder = new StringBuilder();
char[] chars = name.toCharArray();
if (firstUpper) {
chars[0] = String.valueOf(chars[0]).toUpperCase().charAt(0);
} for (int i = 0; i < chars.length; i++) {
boolean b = chars[i] == '_' && (i != chars.length - 1 || i == 0);
if (b) {
chars[i + 1] = String.valueOf(chars[i + 1]).toUpperCase().charAt(0);
continue;
} builder.append(chars[i]);
} return builder.toString();
}
private static String generateField(String column, Class<?> classType, String remark) {
StringBuilder builder = new StringBuilder();
if (Objects.nonNull(remark) && !remark.isEmpty() && !remark.isBlank()) {
builder.append(" /**").append("\n");
builder.append(" * ").append(remark).append("\n");
builder.append(" */").append("\n");
} builder.append(" private ")
.append(classType.getSimpleName()).append(" ")
.append(column).append(";");
return builder.toString();
}
@Data
@AllArgsConstructor private static class TypeInfo {
private String fieldName;
private Class<?> type;
private String remark;
}
}效果如图:
DatabaseMetaData API
在上面的示例中,用到了DatabaseMetaData中的getTables和getColumns方法。它们都会返回一个 ResultSet 对象,这里直接运用[ResultSet 结果集](#ResultSet 结果集 "#ResultSet%E7%BB%93%E6%9E%9C%E9%9B%86")的知识,获取我们所需要的数据。如 getTables中的ResultSet对象。
java
ResultSet resultSet = metaData.getTables(null, null, null, new String[]{"TABLE"});获取每行表描述数据的表名称:
java
String tableName = resultSet.getString("TABLE_NAME");为什么是TABLE_NAME标签 ,进入getTables方法定义中,可以看到其对应的注释,该方法返回表描述的10个字段,其中`TABLE_NAME则是表名称。如下图:
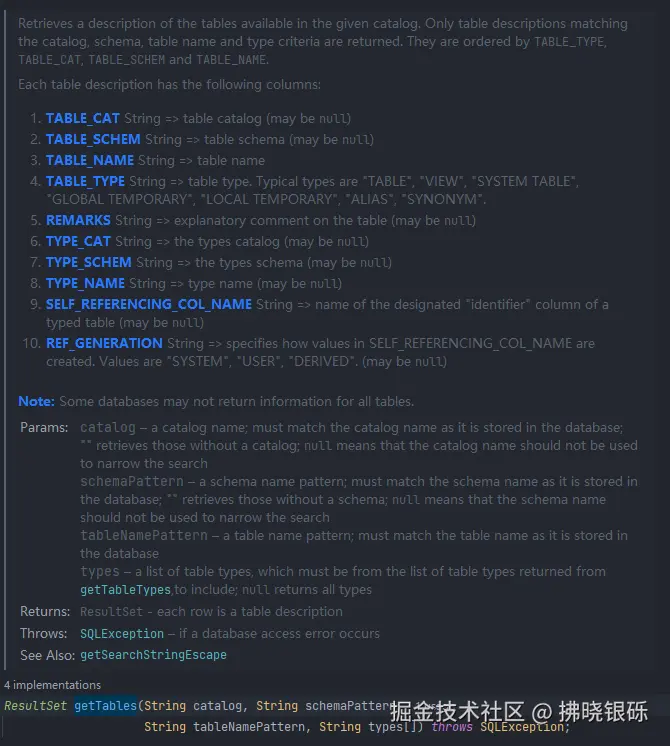
可以看出,`TABLE_NAME在第三列,我们同样可以使用:
java
String tableName = resultSet.getString(3);来获取表名称。注释中每一列都有标有其对应数据类型,我们根据对应的数据类型选择 getXxx方法。
getTables方法有四个入参:
| 参数 | 描述 |
|---|---|
| catalog | 目录名称,""检索没有目录的内容,null表示该属性不用于查询 |
| schemePattern | 模式,""检索没有模式的内容,null表示该属性不用于查询 |
| tableNamePattern | 表名称,null表示该属性不用于查询 |
| types | 表类型,null表示该属性不用于查询 |
schemePattern 和 tableNamePattern都可以使用SQL中的 %和_ 做模糊匹配查询。catalog则是全匹配。
types[]对应的类型数据可以从DatabaseMetaData的 ResultSet getTableTypes() throws SQLException; 中获取,典型的类型有 "TABLE", "VIEW", "SYSTEM TABLE", "GLOBAL TEMPORARY", "LOCAL TEMPORARY", "ALIAS", "SYNONYM"。
Postgresql与MySQL的差异化
catalog 和 schemePattern 不同的数据库会有不同的实现。Postgresql有模式的概念,而MySQL则没有。PgDatabaseMetaData 不会使用到catalog参数,下图对应的参数在其实现上并没有使用,所以传入什么都是无效的。
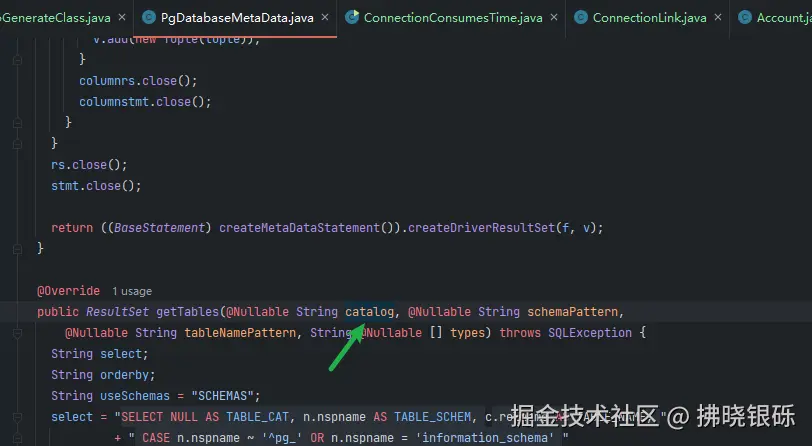
而MySQL无论不会特定区分这两种类型,无论是 catalog还是 schemePattern,最终都是TABLE_SCHEMA 区别在于是否可以模糊匹配。 catalog是全匹配,在com.mysql.cj.jdbc.DatabaseMetaDataUsingInfoSchema中下述代码可以得出

至于是选择哪个,在com.mysql.cj.jdbc.DatabaseMetaData的代码有判断,默认是CATALOG

如果想使用的是 SCHEMA,可以在URL路径下填写:
properties
jdbc:mysql://192.168.153.132:3306/learn?databaseTerm=SCHEMA连接输出的结果也会有所变化
java
System.out.println(connection.getSchema());
System.out.println(connection.getCatalog());Jdbc类型与Java类型的对应关系
接上 getTables 解析, 同理可得:getColumns方法参数:
| 参数 | 描述 |
|---|---|
| catalog | 目录名称,""检索没有目录的内容,null表示该属性不用于查询 |
| schemePattern | 模式,""检索没有模式的内容,null表示该属性不用于查询 |
| tableNamePattern | 表名称,null表示该属性不用于查询 |
| columnNamePattern | 列名称,null表示该属性不用于查询 |
getColumns 返回的 ResulSet 对象每一行有24个字段,其中前几个字段如下:

返回的数据中,我们可以根据TABLE_NAME获取当前column所属的表名称,COLUMN_NAME获取当前列的名称。DATA_TYPE获取字段类型的int值,TYPE_NAME则是获取字段类型在数据库中对应的字符串名称,如 VARCHAR等。
我们根据 resultSet.getInt("DATA_TYPE")获取字段的类型值,其对应关系在java.sql.Types类中
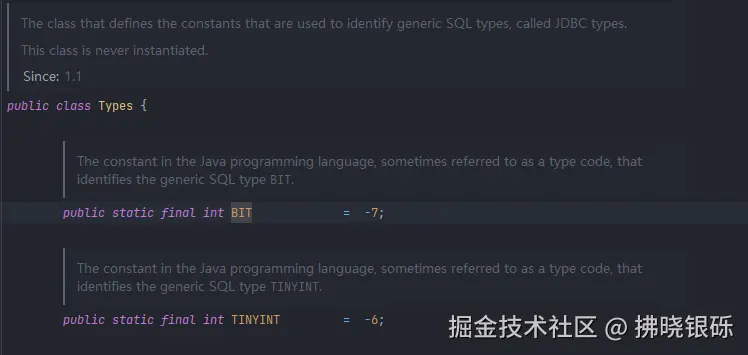
下面是Postgresql 中对应的数据类型,值得注意的是,在开发过程中,我们会使用JSON数据类型,在Postgresql中,其JSON对于的Java类型为其提供的org.postgresql.util.PGobject。
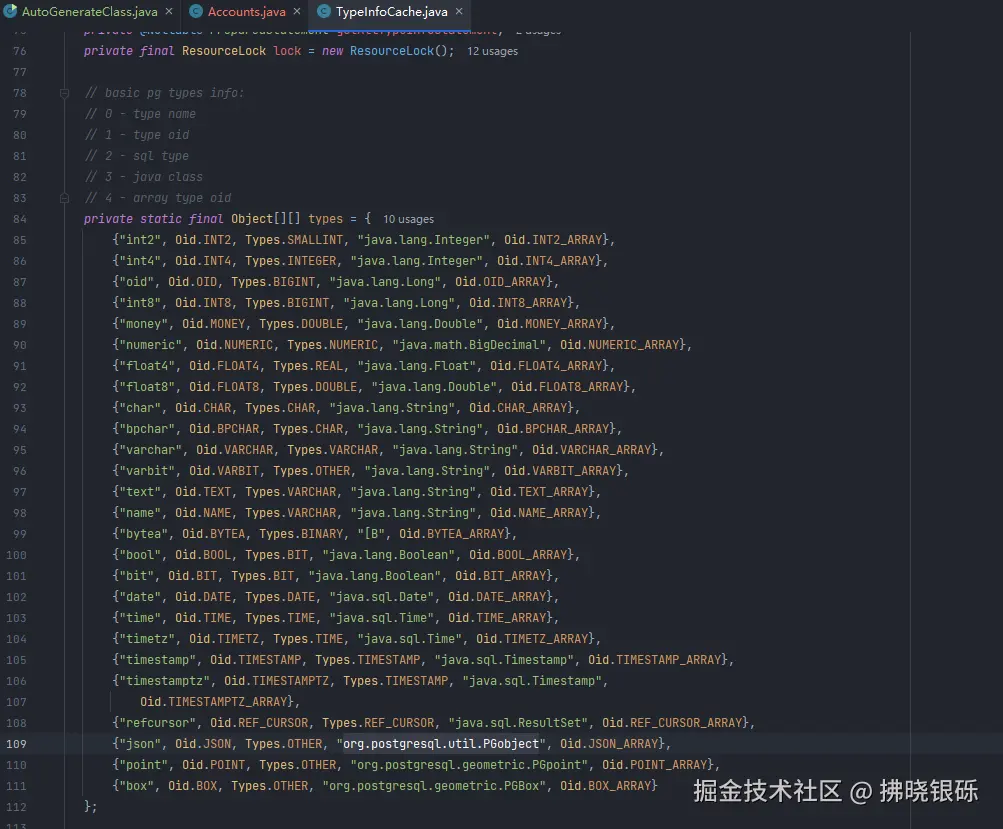
代码如下:
java
// 插入修改json类型数据
PGobject pGobject = new PGobject();
pGobject.setType("json");
pGobject.setValue("Jackson、FastJson、Gson格式化的对象字符串");
statement.setObject(1,pGobject);
...
// 获取json字段值,直接使用getString即可
statement.getString(1);
...我们可以自定义创建对应的映射关系,如本节示例中的 JdbcType
示例中优化的点
在这个示例中,一共执行了 1+ 表的数量次Sql。我们可以根据:
java
ResultSet columns = metaData.getColumns(null, resultSet.getString(2),null, null);获取需要的列数据,然后通过resultSet.getString("TABLE_NAME")获取表名,根据表名对列进行分类,再生成类,这样就只需要查询一次数据库即可。
建立数据库连接为什么耗资源
java
package com.polaris.database.link;
import java.io.InputStream;
import java.sql.Connection;
import java.sql.DriverManager;
import java.time.Duration;
import java.time.Instant;
import java.util.Properties;
/**
* @author DawnStar
* @since 2025/11/1
*/
public class ConnectionConsumesTime {
public static void main(String[] args) throws Exception {
Properties properties;
try (InputStream stream = ConnectionConsumesTime.class.getResourceAsStream("/database.properties")) {
properties = new Properties();
properties.load(stream);
} String url = "database.url";
String password = "database.password";
String user = "database.user";
Instant start = Instant.now();
Connection connection = DriverManager.getConnection(properties.getProperty(url), properties.getProperty(user), properties.getProperty(password));
System.out.println(Duration.between(start, Instant.now()).toMillis() + " ms");
int read = System.in.read();
Instant start1 = Instant.now();
connection.close();
long nanos = Duration.between(start1, Instant.now()).toNanos();
System.out.println(nanos + " ns");
System.out.println(nanos / (double) 1000 + " us");
System.out.println(nanos / (double) 1000 / 1000 + " ms");
}}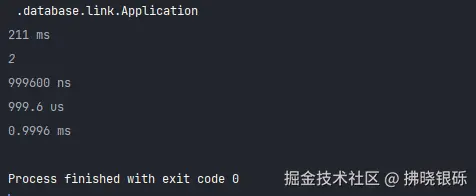
通过 int read = System.in.read(); 暂停一下,然后输入数字执行关闭数据库连接。 通过使用Wireshark软件进行抓包,可以看出:
- 建立数据库连接的耗时为:
952-810=142 ms。 - 关闭数据库连接的耗时为:
375-274=1 ms

建立连接受网络,硬件等影响,每次建立连接和关闭连接的耗时会有所偏差。以本次的耗时为例。如果10万次请求数据库,那么在建立连接和关闭连接的总耗时为 143*100000/1000/60/60 ≈ 3.97 h。
所以数据连接是非常耗资源的行为。我们有必要使用数据库连接池(pool) 来重复使用连接。