在IM中,有了长连接之后,如何完成服务端与客户端的数据同步也是很重要的一环。
通常会有两种方案,一个是服务端直接转发 ,一个是收件箱机制。我们以消息类型的数据为例。
服务端直接转发:
是服务端收到消息A,存储完成后,直接将消息A的具体内容通过长连接通道发送给客户端B。我们把这种方式叫做服务端直接转发。
收件箱:
服务端收到消息后,不直接转发该消息给客户端,而是将消息id、消息所在会话id推送给客户端的消息收件箱,客户端发现消息收件箱有数据后,择机通过长连接 or 短连接拉取消息具体内容。
服务端直接转发
服务端直接转发是最简单的,但是在实际操作运行中,会面临几个问题。
消息阻塞
首先,在富文本的场景中,一个富文本的消息大小可以达到1M。前面说过,长连接的通道是全双工的,允许同时双向通信。但是他的并发量只有1,所以在服务端向客户端传输消息A的时候,其他数据需要等待传输完成后才能再次传输。
如果用户当前在会话A中聊天,但是在会话B中,收到了上百条富文本消息,由于下行通道堵塞,会导致用户无法及时看到会话A中的消息。
ACK
在IM应用中,比实时性更优先的原则是数据真实性,即不能丢数据。所以需要有一套ACK机制,当客户端收到消息A并落库后,会给服务端发送一个回包,用于表示这条消息拉到了。
服务端直接转发方案,如果因为网络抖动原因,客户端没有收到该消息,则服务端还需要再次重试推送该消息,那么会有大量的网络带宽浪费,对服务端也有重试的成本。
消息聚合拉取
单次只拉取一条消息,对于客户端和服务端都是资源的浪费。将多条消息聚合拉取,能够节省网络资源和服务端计算资源。
消息优先级拉取
在一般的IM应用中,有很多用户不关心的群聊,但又不能退出群聊。所以会有会话分组或者折叠会话等功能。这些会话对消息实时性要求不是很高,如果服务端收到消息后直接转发该消息,会让客户端失去灵活拉取的主动权。
收件箱机制
基于前面提到的几个实际场景。结合信箱的原理,我们采用收件箱机制。
在收件箱机制中,服务端收到消息后,不直接转发该消息给客户端,而是将消息id、消息所在会话id推送给客户端的消息收件箱,这个数据量很小。
客户端收到该推送后,将该消息id落库,并回包给服务端,让服务端感知到,该消息id,客户端已经收到了,服务端无需再次推送该消息了。
回包完成后,客户端会根据该消息的优先级,确认是否获取该消息id对应的消息体。也可以做聚合,批量拉取一系列消息体。
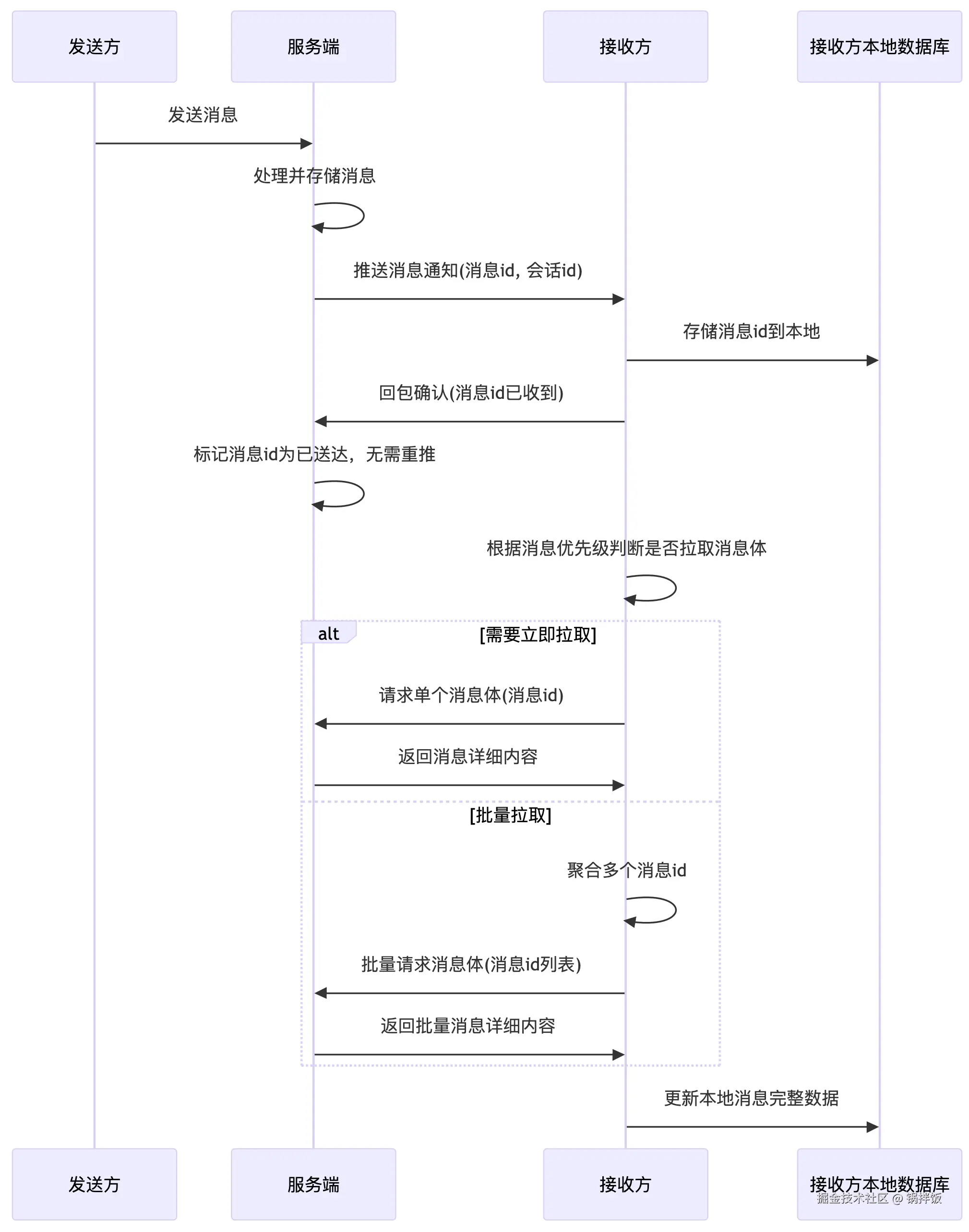
这里有人可能会疑惑,采用收件箱机制,会不会导致消息抵达实时性降低。实际上考虑到网络堵塞、消息聚合拉取等逻辑的存在,收件箱机制在业务优化后,可能比服务端直接转发效果更好。因为没有对应的A/B Test,无法确认两种方案在实时性上的区别。
采用收件箱机制后,在实际运用中,根据业务,会存在多个收件箱。比如消息收件箱、会话收件箱。在飞书中,还会有日程到期收件箱、文档变更收件箱等。
当然并不是所有服务端与客户端的通信都需要收件箱机制 ,根据业务复杂程度、信息数据量大小等,应当采用收件箱机制 与服务端直接转发相结合的方式。
我们以最复杂的业务,消息收件箱为例,查看一些技术细节。
首先,使用消息收件箱是为了保证消息有序、低延迟、数据不丢失。
有序: 按照实际消息顺序获取,保证消息顺序
低延迟: 推与拉结合,保证实时性
数据不丢失: 通过ACK、重试,确保数据不丢失
消息收件箱
命令字
收件箱是一个概念上的东西,在实际开发中,客户端会和服务端约定一个命令字,比如10001,当服务端向客户端推送10001的时候,就代表当前数据是消息收件箱消息。当客户端收到10002时,就代表当前数据是会话收件箱消息。
一般的收件箱数据如下:
json
{ // 推送命令字
"command": "10001",
"data": {
// 消息所在会话id
"conversation_id": "123456789_2",
// 消息的序列号
"sequence_id": "123456789123456789"
}
}sequenceId
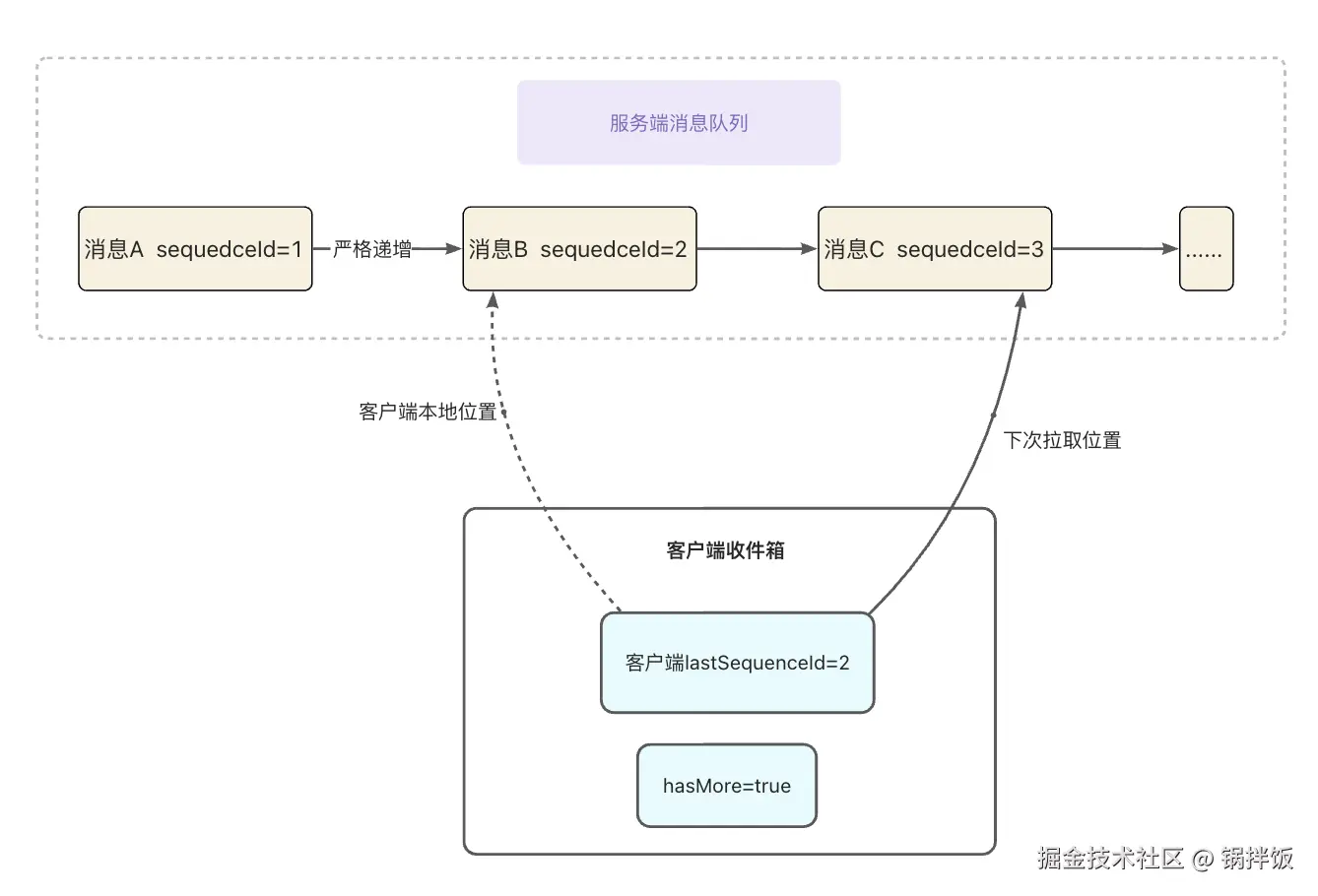
在上面的数据结构中,sequenceId是递增的(跨会话全局递增)。这个会有服务端保证,一般会分布式集群,会采用雪花算法(你可能听说过雪花算法)等方式生成,保证sequenceId的递增、唯一性。
sequenceId:
-
服务端每条消息入库前,都会生成
sequenceId,该sequenceId是跨会话唯一、递增的。 -
sequenceId的作用是用于标记收件箱数据位置,客户端基于sequenceId向服务端请求数据。 -
客户端每次请求会携带本地的
lastSequenceId,服务端响应式会返回新的lastSequenceId+hasMore。 -
客户端循环拉取,直到
hasMore=false,确保本地数据完整。
当客户端收到10001推送后,会将该数据分发到对应的收件箱处理,即MessageEmailManager,在这里,会先对该数据落库,然后回包给服务端,表示客户端已经知道会话A中有消息123。服务端收到回包后,就不会再次推送消息123给客户端。
在MessageEmailManager中,可以根据消息优先级,决定是否拉取该消息的具体内容,以及是否聚合拉取具体内容。
推拉结合
客户端在线时: 实时推送最新的sequenceId给客户端,客户端立即感知
登录/重连/冷启动时: 增量拉取,快速同步离线期间的数据
拉取失败时: 无限重试,确保拉取成功
整个流程图如下:

问题:为什么需要sequenceId?
思考这个问题:消息本身有个唯一的messageId,为什么不直接推送messageId给客户端,而是又新增了sequenceId专门用于推送呢?
首先,messageId也会保证全局的唯一性,在服务端用作消息的唯一标识,即数据库主key。
但是messageId存在两个缺陷:
-
以64位整型Long为例,一般会在
messageId中固定前几位用于声明关键信息,如会话id等信息。 -
messageId保证全局唯一,但是不保证消息是按照发送顺序递增的。
第二个缺陷,messageId不递增,导致它无法用于收件箱推送。对于消息推送来说,是推拉结合的,那么在冷启动的时候,需要上传本地已经获取到的消息:
-
如果使用
messageId,那么就要把本地所有的messageId都发送给服务端。而且服务端还要做diff,才能计算出客户端需要的消息队列。 -
使用
sequenceId,就简单很多。首先sequenceId是递增的,客户端只需要将本地的最新(or最大)sequenceId发送给服务端,服务端也只需要对比sequenceId大小,就可以计算出客户端需要的消息队列。
我们其实可以将sequenceId理解为版本号的概念,客户端只需要维护一个本地版本号,就可以和服务端同步剩余数据。
问题二:id会耗尽吗?
一般我们的id使用的都是Long类型,即64位整型的。那么思考一下,这个id会耗尽吗?
64 位有符号 Long 的最大值是 9223372036854775807,换算成亿为 92233720368.54775807 亿(约 9223 万亿)。
我们以国民级应用微信为例,假设日活有10亿,那么每个人要发送922万条消息才能耗尽这个id。我们把时间拉长到100年,那么每个人每年要发送9万条消息,每天发送250条消息。
上面的假设场景,是把所有极端情况拉满的,实际上大部分人在微信中一天内不会发送250条消息。
根据国外分析网站的数据wechat-statistics,微信每天会产生450亿条消息,那么Long型可以供使用20万天,即555年。
所以对于大部分应用,无需考虑id耗尽的问题。
消息空洞
上面几个原则很好理解,但是在实际开发中,还需要解决消息的空洞问题。
消息空洞: 即消息不连续,中间漏掉了消息
case1:网络抖动
想象这个场景,服务端依次收到了消息A,消息B,消息C。 依次通过推送告知客户端,有消息A、消息B、消息C三条新消息,需要客户端主动获取对应消息体内容。
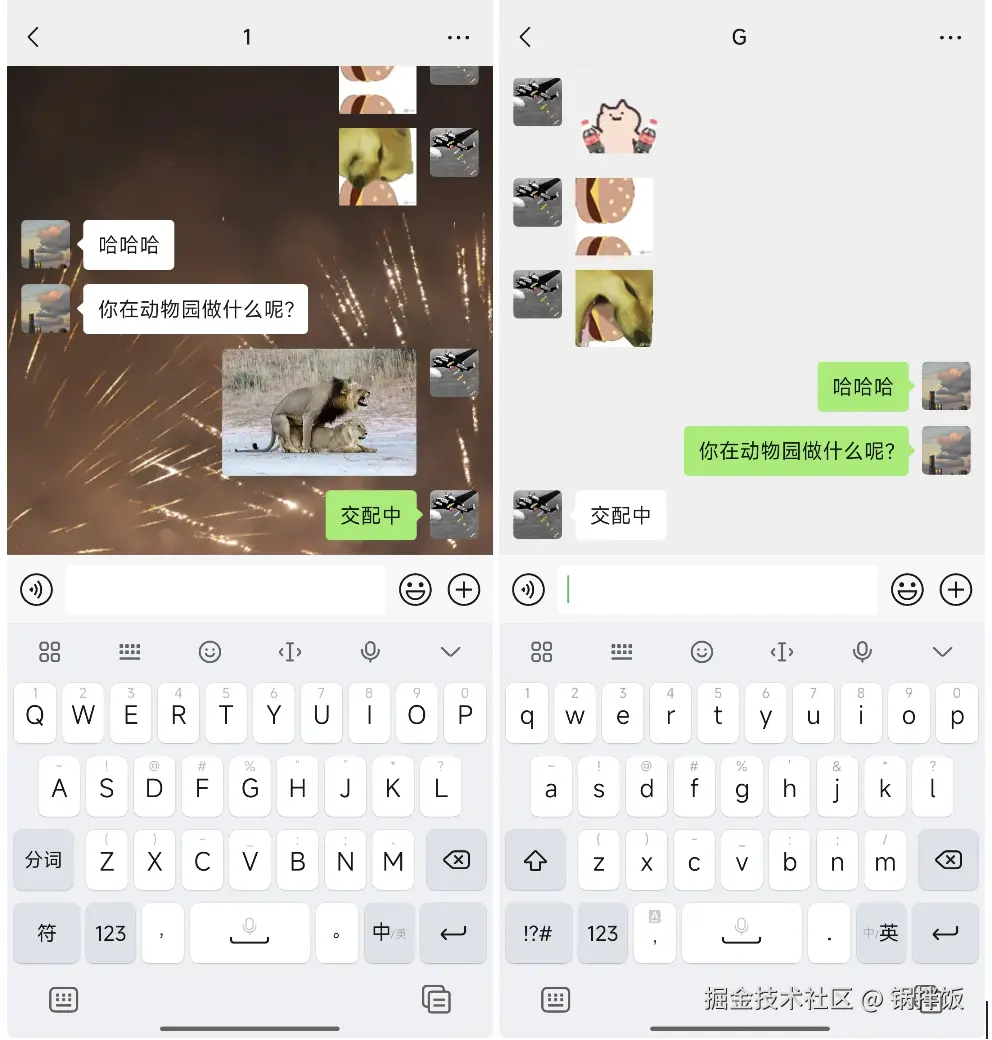
但是由于网络抖动,消息B的推送丢失了。 客户端仅收到了消息A、消息C,落库后回包给服务端。此时服务端虽然会重试推送消息B,但是用户此时正好在此会话中,需要展示消息A、消息C。对于客户端来说,并不知道还有消息B,那么就会导致消息A、消息C上屏展示了。这样就会对用户理解信息造成很大影响。
下图中,你的回复是图片+文字,但是对方只收到了"交配中"的文字,会让对方感觉很抽象。
case2:消息定位
一般来说,进入会话A,初始化只会拉取最新50条消息,用户滑动屏幕后才会触发加载。在卸载重装后,用户没有滑动屏幕加载更多消息,那么客户端SDK数据库中,只有最近50条消息。
用户通过搜索关键字,定位到了第10000条的消息。当用户在这第10000条消息滑动屏幕时,会调用loadMessage加载下一页的消息。
那么如何判断SDK数据库中的50条消息,是否能展示呢?
即SDK怎么判断第10000条消息和最近50条消息是否连续呢?
我们从文字描述上看,此时肯定是不连续的,即出现了空洞。但对于SDK来说,一定要有一个可以量化的条件。
消息定位导致的消息空洞场景有很多:
用户在离线状态,群聊中产生了10000条消息,用户点击离线推送进入会话,也会和上面情景一样,产生消息空洞。
同理,点击被回复的消息/被引用的消息/被置顶的消息等,都有可能产生消息空洞。
如何保证消息连续性:
保证消息没有空洞,即连续性很重要。一般来说,服务端会在messageId的基础上,给每条消息计算出一个continueId,continueId是连续递增的,从0、1、2、3一直到无穷大。
需要注意,continueId是绑定在具体的会话下面的,在这个会话下是连续递增的。
前面提到的sequenceId是跨会话的,在多个会话间是非连续递增的。
这样客户端就知道消息A跟消息C是不能上墙的,得主动拉取到消息B,才能一起上墙。
服务端连续递增id生成方案有很多,这里不多赘述分布式ID生成器(CosId)设计与实现
在消息收件箱中,不关心消息是否是连续的,只关心消息是递增的。在99%的情况下,消息收件箱中的消息都是连续的。而且大部分会话,用户是极低概率进入的,而且即使进入,也很极低概率会滑动查看全部的历史消息。
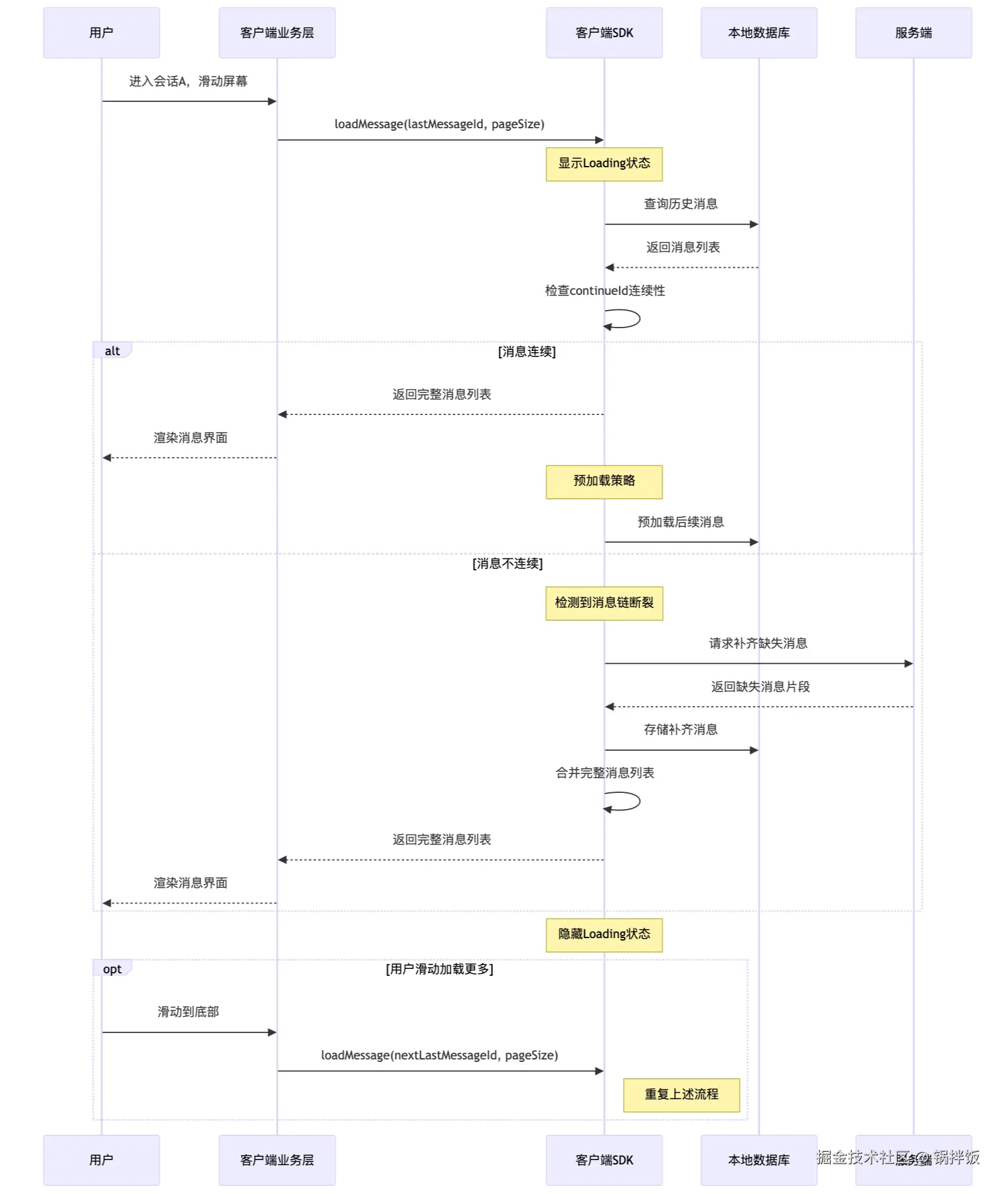
所以,我们无需在收件箱中就保证消息连续性。只需要在用户看到这部分消息时,保证连续即可。一般来说,用户进入会话查看消息流程:
-
用户进入会话A后,客户端业务会调用
loadMessage(lastMessageId, pageSize),其中,lastMessageId是描点id,pageSize是想要获取的消息数量。 -
客户端业务向客户端
SDK查询从指定锚点开始的历史消息。 -
当客户端
SDK从本地数据库捞出对应的消息列表后,需要checkcontinueId是否是连续的 -
如果消息
continueId连续,就直接返回给业务方。 -
如果不连续,客户端
SDK需要发起网络请求,向服务端拉取补齐消息,最终返回给客户端业务。 -
这个过程会有预加载、loading等方式优化用户体验
消息中各种id
| **** | 含义 | 作用 |
|---|---|---|
| messageId | 消息的唯一id,具有全局唯一性,但是不保证按照发送顺序递增 | 消息的主key |
| sequenceId | 全局唯一性,且是递增的,按照发送顺序一次递增 | 用于客户端-服务端的消息同步 |
| continueId | 单个会话内连续递增 | 用于保证消息连续不空洞 |