一、Callable 接口
Callable 是一个interface,相当于把线程封装了一个"返回值",方便程序猿借助多线程的方式计算结果。
是对标的runnable,但是又不一样,是一个泛型
代码示例:创建线程计算1+2+3+...+1000,不使用Callable版本
• 创建一个类Result,包含一个sum表示最终结果,lock表示线程同步使用的锁对象。
• main方法中先创建Result实例,然后创建一个线程 t ,在线程内部计算1+2+3+...+1000。
• 主线程同时使用wait等待线程 t 计算结束。(注意,如果执行到wait之前,线程 t 已经计算完了,就不必等待了)。
• 当线程 t 计算完毕后,通过notify唤醒主线程,主线程再打印结果。
Thread没有提供给他一个传递Callable() 的构造方法,想要传递只能借助其他力量传入
java
static class Result {
public int sum = 0;
public Object lock = new Object();
}
public static void main(String[] args) throws InterruptedException {
Result result = new Result();
Thread t = new Thread() {
@Override
public void run() {
int sum = 0;
for (int i = 1; i <= 1000; i++) {
sum += i;
}
synchronized (result.lock) {
result.sum = sum;
result.lock.notify();
}
}
};
t.start();
synchronized (result.lock) {
while (result.sum == 0) {
result.lock.wait();
}
System.out.println(result.sum);
}
}
可以看到,上述代码需要一个辅助类Result,还需要使用一系列的加锁和waitnotify操作,代码复杂,容易出错。
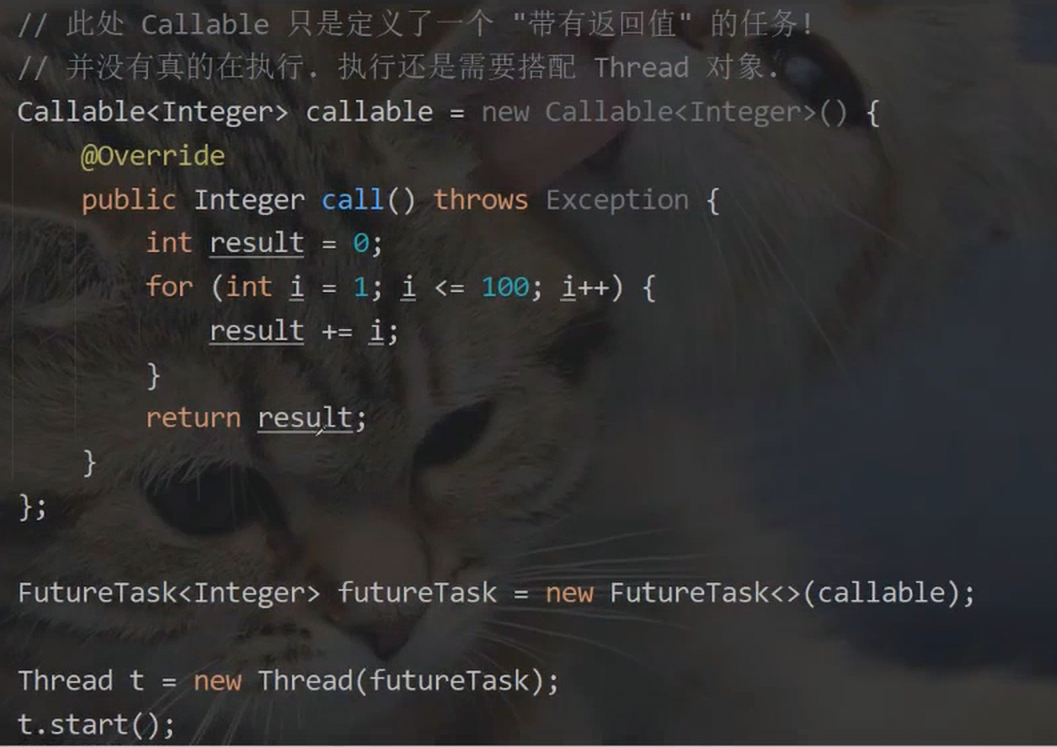
代码示例:创建线程计算1+2+3+...+1000,使用Callable版本
• 创建一个匿名内部类,实现Callable接口,Callable带有泛型参数,泛型参数表示返回值的类型。
• 重写Callable的call方法,完成累加的过程,直接通过返回值返回计算结果。
• 把callable实例使用FutureTask包装一下。
• 创建线程,线程的构造方法传入FutureTask,此时新线程就会执行FutureTask内部的Callable的 call 方法,完成计算,计算结果就放到了FutureTask对象中。
• 在主线程中调用 futureTask.get() 能够阻塞等待新线程计算完毕,并获取到FutureTask中的结果。
java
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
public class Main {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Callable<Integer> callable = new Callable<Integer>() {
@Override
public Integer call() throws Exception {
int sum = 0;
for (int i = 1; i <= 1000; i++) {
sum += i;
}
return sum;
}
};
FutureTask<Integer> futureTask = new FutureTask<>(callable);
Thread t = new Thread(futureTask);
t.start();
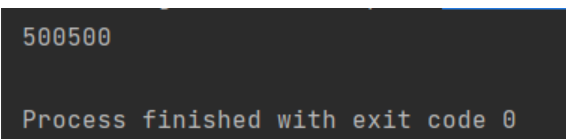
int result = futureTask.get();
System.out.println(result);
}
}
可以看到,使用Callable和FutureTask之后,代码简化了很多,也不必手动写线程同步代码了。
理解Callable
Callable 和 Runnable相对,都是描述一个"任务",Callable描述的是带有返回值的任务,Runnable 描述的是不带返回值的任务。
Callable 通常需要搭配FutureTask来使用,FutureTask用来保存Callable的返回结果,因为Callable 往往是在另一个线程中执行的,啥时候执行完并不确定。
FutureTask 就可以负责这个等待结果出来的⼯作。
理解FutureTask
想象去吃麻辣烫,当餐点好后,后厨就开始做了。同时前台会给你一张"小票",这个小票就是 FutureTask,后⾯我们可以随时凭这张小票去查看自己的这份麻辣烫做出来了没。
经过上面的学习,外面到现在5种的创建线程的方法了:
第一种:Thread 类(继承 Thread 并重写 run ()):
java
class MyThread extends Thread {
@Override
public void run() {
System.out.println("Thread 方式执行任务");
}
}
// 使用
new MyThread().start(); // 必须调用 start() 启动线程也可以写成:Thread 匿名内部类:
java
public static void main(String[] args) {
// 使用匿名内部类创建Thread子类对象并启动线程
new Thread() {
@Override
public void run() {
// 线程要执行的任务
System.out.println("匿名内部类(Thread子类)执行任务");
System.out.println("当前线程名:" + Thread.currentThread().getName());
}
}.start(); // 启动线程特点:
- 优点:简单直接,可直接操作线程对象(如
setName()、interrupt())。 - 缺点:Java 单继承限制,无法再继承其他类;任务与线程耦合,重用性差。
第二种:Runnable 接口(实现 Runnable 接口)
用法 :自定义类实现 Runnable 接口,重写 run() 方法,将实例传入 Thread 启动。
java
class MyRunnable implements Runnable {
@Override
public void run() {
System.out.println("Runnable 方式执行任务");
}
}
// 使用
Thread thread = new Thread(new MyRunnable());
thread.start();实现形式:
1. 定义Runnable实现类(单独类)
java
// 1. 定义任务类,实现Runnable接口
class MyRunnableTask implements Runnable {
@Override
public void run() {
// 线程要执行的任务逻辑
for (int i = 0; i < 3; i++) {
System.out.println("任务执行中:" + i + ",当前线程:" + Thread.currentThread().getName());
try {
Thread.sleep(500); // 模拟任务耗时
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
// 2. 使用Runnable创建并启动线程
public class RunnableDemo {
public static void main(String[] args) {
// 创建任务对象
Runnable task = new MyRunnableTask();
// 将任务交给Thread,创建线程并启动
Thread thread = new Thread(task);
thread.setName("MyRunnable-Thread"); // 给线程命名
thread.start(); // 启动线程(会创建新线程执行run())
// 主线程执行自己的逻辑
for (int i = 0; i < 3; i++) {
System.out.println("主线程执行中:" + i + ",当前线程:" + Thread.currentThread().getName());
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}2. 直接用匿名内部类(更简洁,适合简单任务)
如果任务逻辑简单,无需单独定义类,可直接通过匿名内部类实现Runnable:
java
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
}
});核心要点:
Runnable的作用 :仅定义线程要执行的任务(run()方法),不负责线程的创建和启动。- 线程的创建和启动 :必须通过
Thread类,将Runnable对象作为参数传给Thread构造器,再调用thread.start()。 - 优势 :
- 避免单继承限制(一个类可同时实现
Runnable和继承其他类)。 - 便于多个线程共享同一个任务对象(例如共享资源场景)。
- 符合 "单一职责原则"(任务逻辑与线程控制分离)。
- 避免单继承限制(一个类可同时实现
第三种:Lambda 表达式(简化 Runnable/Callable)
用法 :针对函数式接口(Runnable、Callable),用 Lambda 简化匿名内部类的写法。
java
// 简化 Runnable(无返回值)
new Thread(() -> System.out.println("Lambda + Runnable")).start();
// 简化 Callable(有返回值,配合线程池)
ExecutorService executor = Executors.newSingleThreadExecutor();
Future<Integer> future = executor.submit(() -> 1 + 2); // Lambda 实现 Callable1. Lambda 简化Runnable
java
public class LambdaRunnableDemo {
public static void main(String[] args) {
// 传统匿名内部类方式
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("匿名内部类执行任务,线程:" + Thread.currentThread().getName());
}
}).start();
// Lambda表达式简化(最简洁形式)
new Thread(() -> {
System.out.println("Lambda执行任务1,线程:" + Thread.currentThread().getName());
}).start();
// 如果任务逻辑只有一行代码,可省略大括号
new Thread(() -> System.out.println("Lambda执行任务2,线程:" + Thread.currentThread().getName())).start();
}
}2. Lambda 简化Callable
Callable<T>也是函数式接口(抽象方法T call()),有返回值且可能抛出异常,适合有返回结果的线程任务。配合FutureTask或线程池使用时,可用 Lambda 简化。
java
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
public class LambdaCallableDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 传统匿名内部类方式
Callable<Integer> callable1 = new Callable<Integer>() {
@Override
public Integer call() throws Exception {
System.out.println("Callable1执行计算,线程:" + Thread.currentThread().getName());
return 100; // 返回计算结果
}
};
// Lambda表达式简化(指定返回值类型)
Callable<Integer> callable2 = () -> {
System.out.println("Callable2执行计算,线程:" + Thread.currentThread().getName());
return 200;
};
// 启动线程并获取结果(通过FutureTask)
FutureTask<Integer> future1 = new FutureTask<>(callable1);
FutureTask<Integer> future2 = new FutureTask<>(callable2);
new Thread(future1).start();
new Thread(future2).start();
// 获取返回结果(会阻塞直到任务完成)
System.out.println("Callable1结果:" + future1.get());
System.out.println("Callable2结果:" + future2.get());
}
}核心优势:
- 代码极简 :省略了接口名、方法名、
@Override注解,只保留核心逻辑。 - 可读性高:对于简单任务,Lambda 表达式比匿名内部类更直观。
- 与函数式接口适配 :
Runnable和Callable都是函数式接口,天然适合 Lambda。
注意:
- Lambda 表达式仅适用于函数式接口(只有一个抽象方法的接口)。
Runnable无返回值,Lambda 中无需return;Callable有返回值,需明确返回结果。- 如果 Lambda 体只有一行代码,可省略
{}和return(如上述Runnable的单行示例)。
第四种:线程池
用法 :通过线程池管理线程生命周期,提交 Runnable 或 Callable 任务执行。
java
public ThreadPoolExecutor(
int corePoolSize, // 核心线程数(常驻线程,即使空闲也不销毁)
int maximumPoolSize, // 最大线程数(核心线程+临时线程的上限)
long keepAliveTime, // 临时线程的空闲存活时间
TimeUnit unit, // keepAliveTime的时间单位
BlockingQueue<Runnable> workQueue, // 任务等待队列(核心线程满时,新任务进入队列)
ThreadFactory threadFactory, // 线程创建工厂(自定义线程名、优先级等)
RejectedExecutionHandler handler // 任务拒绝策略(队列和最大线程都满时的处理方式)
)特点:
- 优点:复用线程,减少创建 / 销毁开销;控制并发数,避免资源耗尽;支持任务排队和拒绝策略。
- 缺点:需手动关闭线程池;参数配置不当可能导致性能问题(如无界队列 OOM)。
Executors提供了 5 种常用线程池,但部分存在资源耗尽风险(如newCachedThreadPool可能创建无限线程),需根据场景选择。
1. 固定大小线程池(newFixedThreadPool)
- 特点 :核心线程数 = 最大线程数(无临时线程),队列无界(
LinkedBlockingQueue)。 - 适用场景:任务数量固定、CPU 密集型任务(避免线程过多导致上下文切换)。
java
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class FixedThreadPoolDemo {
public static void main(String[] args) {
// 创建固定大小为3的线程池
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(3);
// 提交10个任务
for (int i = 0; i < 10; i++) {
int taskId = i;
fixedThreadPool.execute(() -> { // 提交Runnable任务
System.out.println("任务" + taskId + "执行,线程:" + Thread.currentThread().getName());
try {
Thread.sleep(1000); // 模拟任务耗时
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
// 关闭线程池(不再接收新任务,等待现有任务完成)
fixedThreadPool.shutdown();
}
}2. 单线程化线程池(newSingleThreadExecutor)
- 特点:核心线程数 = 1,最大线程数 = 1,队列无界。所有任务按顺序执行(串行)。
- 适用场景:需要任务顺序执行、避免并发的场景(如日志记录、单例资源操作)。
java
ExecutorService singleThreadExecutor = Executors.newSingleThreadExecutor();
// 提交任务(与固定线程池用法相同,但始终由同一个线程执行)
singleThreadExecutor.execute(() -> System.out.println("单线程执行任务"));
singleThreadExecutor.shutdown();3. 可缓存线程池(newCachedThreadPool)
- 特点 :核心线程数 = 0,最大线程数 = Integer.MAX_VALUE(几乎无限),临时线程空闲 60 秒销毁,队列是
SynchronousQueue(不存储任务,直接传递给线程)。 - 适用场景:大量短期、轻量任务(如网络请求),线程会动态增减。
- 风险:任务过多时可能创建大量线程,导致 OOM(内存溢出)。
java
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
// 提交大量短期任务
for (int i = 0; i < 100; i++) {
cachedThreadPool.execute(() -> {
System.out.println("缓存线程执行,线程:" + Thread.currentThread().getName());
});
}
cachedThreadPool.shutdown();4. 定时任务线程池(newScheduledThreadPool)
- 特点 :核心线程数固定,可执行延迟任务或周期性任务,底层用
DelayedWorkQueue。 - 适用场景:定时任务(如心跳检测、定时备份)。
java
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
public class ScheduledThreadPoolDemo {
public static void main(String[] args) {
// 核心线程数为2的定时线程池
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(2);
// 1. 延迟3秒后执行一次任务
scheduledThreadPool.schedule(() -> {
System.out.println("延迟3秒执行");
}, 3, TimeUnit.SECONDS);
// 2. 延迟1秒后,每2秒执行一次任务(周期从任务开始时计算)
scheduledThreadPool.scheduleAtFixedRate(() -> {
System.out.println("周期任务执行,当前时间:" + System.currentTimeMillis()/1000);
}, 1, 2, TimeUnit.SECONDS);
// 3. 延迟1秒后,每2秒执行一次任务(周期从任务结束时计算)
scheduledThreadPool.scheduleWithFixedDelay(() -> {
System.out.println("固定延迟任务执行");
try { Thread.sleep(1000); } catch (InterruptedException e) {}
}, 1, 2, TimeUnit.SECONDS);
// 注意:定时线程池需手动关闭,否则会一直运行
// scheduledThreadPool.shutdown();
}
}5. 单线程定时任务线程池(newSingleThreadScheduledExecutor)
- 特点:核心线程数 = 1,定时任务串行执行,避免并发冲突。
- 适用场景:需要顺序执行的定时任务(如单线程处理定时消息)。
java
ScheduledExecutorService singleScheduledExecutor = Executors.newSingleThreadScheduledExecutor();
singleScheduledExecutor.schedule(() -> System.out.println("单线程定时任务"), 1, TimeUnit.SECONDS);6.手动创建ThreadPoolExecutor(推荐,更可控)
Executors的线程池可能存在资源风险(如无界队列导致 OOM),阿里开发手册明确推荐手动配置ThreadPoolExecutor,根据业务场景定制参数。
java
import java.util.concurrent.*;
import java.util.concurrent.atomic.AtomicInteger;
public class CustomThreadPoolDemo {
public static void main(String[] args) {
// 1. 定义线程工厂(自定义线程名,便于调试)
ThreadFactory threadFactory = new ThreadFactory() {
private final AtomicInteger threadNumber = new AtomicInteger(1);
@Override
public Thread newThread(Runnable r) {
Thread thread = new Thread(r, "custom-thread-" + threadNumber.getAndIncrement());
thread.setDaemon(false); // 非守护线程
thread.setPriority(Thread.NORM_PRIORITY);
return thread;
}
};
// 2. 定义任务拒绝策略(当队列和最大线程都满时触发)
RejectedExecutionHandler handler = new ThreadPoolExecutor.CallerRunsPolicy();
// 可选策略:
// - AbortPolicy(默认):抛出RejectedExecutionException
// - DiscardPolicy:直接丢弃任务
// - DiscardOldestPolicy:丢弃队列中最旧的任务,尝试提交新任务
// - CallerRunsPolicy:让提交任务的线程自己执行(减缓提交速度)
// 3. 手动创建线程池
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(
2, // 核心线程数:2
5, // 最大线程数:5(核心2 + 临时3)
60, // 临时线程空闲60秒销毁
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(10), // 有界队列(容量10,避免OOM)
threadFactory,
handler
);
// 4. 提交任务(可提交Runnable或Callable)
// 提交Runnable(无返回值)
threadPool.execute(() -> {
System.out.println("Runnable任务,线程:" + Thread.currentThread().getName());
});
// 提交Callable(有返回值,通过Future获取结果)
Future<String> future = threadPool.submit(() -> {
Thread.sleep(1000);
return "Callable任务结果";
});
try {
System.out.println("获取Callable结果:" + future.get()); // 阻塞等待结果
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
// 5. 关闭线程池
threadPool.shutdown(); // 温和关闭:等待任务完成
// 若需强制关闭:threadPool.shutdownNow();(尝试中断正在执行的任务)
}
}第五种:Callable()
型函数式接口(仅含一个抽象方法),定义如下:
java
@FunctionalInterface
public interface Callable<V> {
V call() throws Exception; // 执行任务,返回结果,可抛出异常
}用法 :实现 Callable<V> 接口,重写 call() 方法(有返回值、可抛异常),需配合线程池 submit() 执行。
Callable 是一个泛
java
class MyCallable implements Callable<Integer> {
@Override
public Integer call() throws Exception {
return 1 + 2; // 返回结果,可抛出异常
}
}
// 使用(必须通过线程池或 FutureTask 执行)
ExecutorService executor = Executors.newSingleThreadExecutor();
Future<Integer> future = executor.submit(new MyCallable());
int result = future.get(); // 获取结果(会阻塞)
executor.shutdown();特点:
- 优点:有返回值,可抛出受检异常,适合需要结果的任务。
- 缺点:不能直接通过
Thread启动,必须配合线程池或FutureTask。
二、ReentrantLock
一、核心锁操作方法

二、与条件对象(Condition)配合的方法
ReentrantLock 可通过 newCondition() 创建 Condition 对象,实现线程间的 "等待 - 通知" 协作。

三、锁状态查询方法

四、公平性相关方法
ReentrantLock 支持 "公平锁" 和 "非公平锁",可通过构造参数指定。

java
import java.util.concurrent.locks.ReentrantLock;
public class ReentrantLockDemo {
private final ReentrantLock lock = new ReentrantLock(true); // 公平锁
private int count = 0;
public void increment() {
lock.lock(); // 获取锁
try {
count++;
System.out.println("当前计数:" + count + ",线程:" + Thread.currentThread().getName());
} finally {
lock.unlock(); // 释放锁(必须在finally中,确保锁释放)
}
}
public void tryIncrement() {
if (lock.tryLock()) { // 尝试获取锁,成功则执行
try {
count++;
System.out.println("尝试获取锁成功,计数:" + count);
} finally {
lock.unlock();
}
} else {
System.out.println("尝试获取锁失败,线程:" + Thread.currentThread().getName());
}
}
public static void main(String[] args) {
ReentrantLockDemo demo = new ReentrantLockDemo();
// 测试可重入性
new Thread(() -> {
demo.lock.lock();
try {
System.out.println("线程1第一次获取锁,计数:" + demo.count);
demo.lock.lock(); // 可重入,再次获取锁
try {
demo.count++;
System.out.println("线程1第二次获取锁,计数:" + demo.count);
} finally {
demo.lock.unlock(); // 释放一次锁
}
} finally {
demo.lock.unlock(); // 释放最后一次锁
}
}).start();
}
}可重入互斥锁和synchronized定位类似,都是用来实现互斥效果,保证线程安全。
ReentrantLock 也是可重入锁,Reentrant这个单词的原意就是"可重入"。
ReentrantLock 的用法:
• lock():加锁,如果获取不到锁就死等。
• trylock(超时时间):加锁,如果获取不到锁,等待一定的时间之后就放弃加锁。
• unlock():解锁。
java
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 50000; i++) {
locker.lock();
count++;
locker.unlock();
}
}
});ReentrantLock 和synchronized 的区别:
• synchronized是一个关键字,是JVM内部实现的(大概率是基于C++实现),ReentrantLock是标准 库的一个类,在JVM外实现的(基于Java实现)。
• synchronized 使用时不需要手动释放锁,ReentrantLock 使用时需要手动释放,使用起来更灵活,但是也容易遗漏 unlock。
• synchronized在申请锁失败时,会死等,ReentrantLock可以通过trylock的方式等待一段时间就放 弃。
• synchronized是非公平锁,ReentrantLock默认是非公平锁,可以通过构造方法传入一个true开启 公平锁模式。
ReentrantLock 除了基础的加锁 / 解锁,还提供了 synchronized 不具备的功能:
tryLock()方法 :尝试加锁时不会阻塞 。加锁成功返回true,失败返回false。调用者可根据返回值灵活决定后续逻辑(比如放弃加锁、执行其他操作)。- 此外,ReentrantLock 还支持公平锁 / 非公平锁 的选择(通过构造器指定)、可中断锁 (
lockInterruptibly()方法)等高级特性。
java
ReentrantLock locker = new ReentrantLock(true);构造方法:
java
// ReentrantLock 的构造⽅法
public ReentrantLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
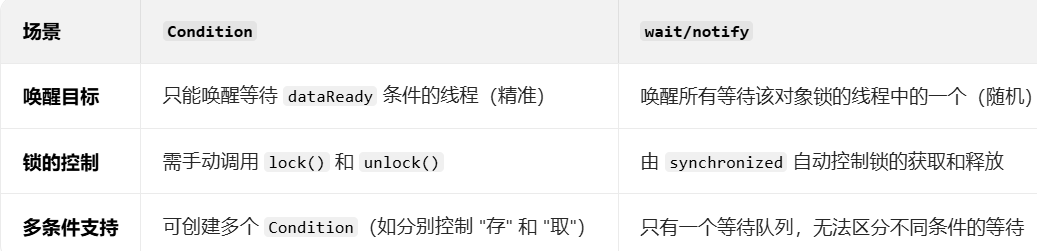
}• 更强大的唤醒机制,synchronized是通过Object的wait/notify实现等待---唤醒,每次唤醒的是一个 随机等待的线程,ReentrantLock搭配Condition类实现等待---唤醒,可以更精确控制唤醒某个指定 的线程。
如何选择使用哪个锁?
• 锁竞争不激烈的时候,使用synchronized,效率更高,自动释放更方便。
• 锁竞争激烈的时候,使用ReentrantLock,搭配trylock更灵活控制加锁的行为,而不是死等。
• 如果需要使用公平锁,使用ReentrantLock。
Condition 和 wait/notify 的用法,核心场景是:
一个线程存数据,另一个线程取数据,当数据未准备好时取线程等待,数据准备好后存线程通知取线程。
例子 1:用 Condition 实现
java
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.ReentrantLock;
public class ConditionSimple {
private String data; // 共享数据
private boolean hasData = false; // 数据是否准备好
private final ReentrantLock lock = new ReentrantLock();
private final Condition dataReady = lock.newCondition(); // 数据准备好的条件
// 存数据的方法
public void setData(String data) {
lock.lock(); // 获取锁
try {
this.data = data;
hasData = true;
System.out.println("存数据:" + data + ",通知取数据线程");
dataReady.signal(); // 精准唤醒等待"数据准备好"的线程
} finally {
lock.unlock(); // 释放锁
}
}
// 取数据的方法
public String getData() throws InterruptedException {
lock.lock(); // 获取锁
try {
// 数据未准备好时,等待
while (!hasData) {
System.out.println("数据未准备好,取数据线程等待...");
dataReady.await(); // 等待"数据准备好"的信号
}
// 取数据
String result = data;
hasData = false;
System.out.println("取数据:" + result);
return result;
} finally {
lock.unlock(); // 释放锁
}
}
public static void main(String[] args) {
ConditionSimple demo = new ConditionSimple();
// 取数据线程(启动后先等待,直到数据准备好)
new Thread(() -> {
try {
demo.getData();
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
// 存数据线程(延迟1秒存数据,然后通知)
new Thread(() -> {
try {
Thread.sleep(1000); // 模拟准备数据的时间
demo.setData("Hello Condition");
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
}例子 2:用 wait/notify 实现
java
public class WaitNotifySimple {
private String data;
private boolean hasData = false;
// 存数据的方法(用synchronized加锁)
public synchronized void setData(String data) {
this.data = data;
hasData = true;
System.out.println("存数据:" + data + ",通知取数据线程");
this.notify(); // 随机唤醒一个等待的线程
}
// 取数据的方法(用synchronized加锁)
public synchronized String getData() throws InterruptedException {
// 数据未准备好时,等待
while (!hasData) {
System.out.println("数据未准备好,取数据线程等待...");
this.wait(); // 释放锁,进入等待队列
}
// 取数据
String result = data;
hasData = false;
System.out.println("取数据:" + result);
return result;
}
public static void main(String[] args) {
WaitNotifySimple demo = new WaitNotifySimple();
// 取数据线程(先等待)
new Thread(() -> {
try {
demo.getData();
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
// 存数据线程(延迟1秒存数据)
new Thread(() -> {
try {
Thread.sleep(1000);
demo.setData("Hello wait/notify");
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
}核心区别对比:
 三、原子类
三、原子类
原子类内部用的是CAS实现,所以性能要比加锁实现i++高很多。原子类有以下几个
• AtomicBoolean
• AtomicInteger
• AtomicIntegerArray
• AtomicLong
• AtomicReference
• AtomicStampedReference
以AtomicInteger 举例,常见方法有
java
addAndGet(int delta); i += delta;
decrementAndGet(); --i;
getAndDecrement(); i--;
incrementAndGet(); ++i;
getAndIncrement(); i++;一、基本类型原子类
用于对基本数据类型进行原子操作:
AtomicInteger:原子更新整型,常用于计数器场景,提供incrementAndGet()、decrementAndGet()等方法。AtomicLong:原子更新长整型,用法与AtomicInteger类似,在 32 位 JVM 上可避免long类型操作的拆分风险。AtomicBoolean:原子更新布尔类型,常用于线程安全的标志位控制,如compareAndSet(false, true)实现原子性的开关操作。
AtomicInteger 是 Java 并发包中用于原子性操作整数 的类,基于 CAS(Compare-And-Swap)机制实现线程安全,性能优于加锁的 i++ 操作。以下是其常见方法的详细解释:
1. 核心字段与构造方法
java
public class AtomicInteger extends Number implements java.io.Serializable {
// 用 volatile 保证可见性,CAS 保证原子性
private volatile int value;
// 内存偏移量,用于 Unsafe 类直接操作内存
private static final long valueOffset;
// 构造方法:初始化一个原子整数
public AtomicInteger() {
this(0);
}
public AtomicInteger(int initialValue) {
value = initialValue;
}
}2. 原子性读取与设置方法
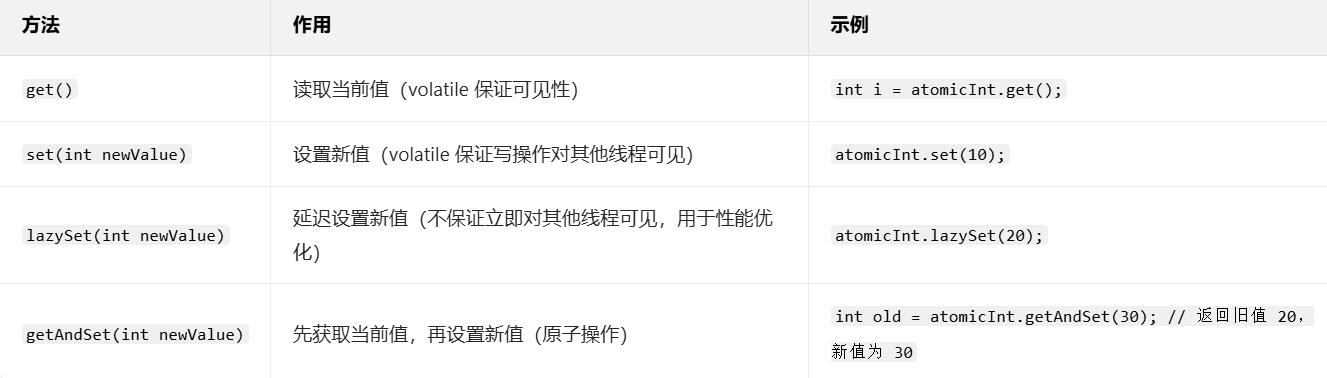
3. 原子性自增 / 自减方法

4. 原子性加法 / 减法方法
5. CAS 核心方法(Compare-And-Swap)
6. 其他工具方法
二、数组类型原子类
用于对数组元素进行原子操作:
AtomicIntegerArray:原子更新整型数组的元素,通过索引操作数组,保证多线程下数组元素更新的线程安全。AtomicLongArray:原子更新长整型数组的元素。AtomicReferenceArray:原子更新引用类型数组的元素。
1. AtomicIntegerArray(原子更新整型数组)
- 核心功能 :对
int[]数组的元素进行原子操作,通过索引操作数组,避免多线程修改同一索引元素时的线程安全问题。 - 常见方法 (以索引
i为例):

2. AtomicLongArray(原子更新长整型数组)
- 核心功能 :对
long[]数组的元素进行原子操作,用法与AtomicIntegerArray类似,针对long类型优化。 - 常见方法 :与
AtomicIntegerArray一致,仅参数和返回值为long类型(如get(int i)、incrementAndGet(int i)、compareAndSet(int i, long expect, long update)等)。 - 适用场景:多线程共享长整型数组(如分布式 ID 生成器中的分段计数器数组)。
3. AtomicReferenceArray(原子更新引用类型数组)
- 核心功能 :对引用类型数组(如
Object[])的元素进行原子操作,支持任意对象引用的原子更新。 - 常见方法 (以索引
i为例):
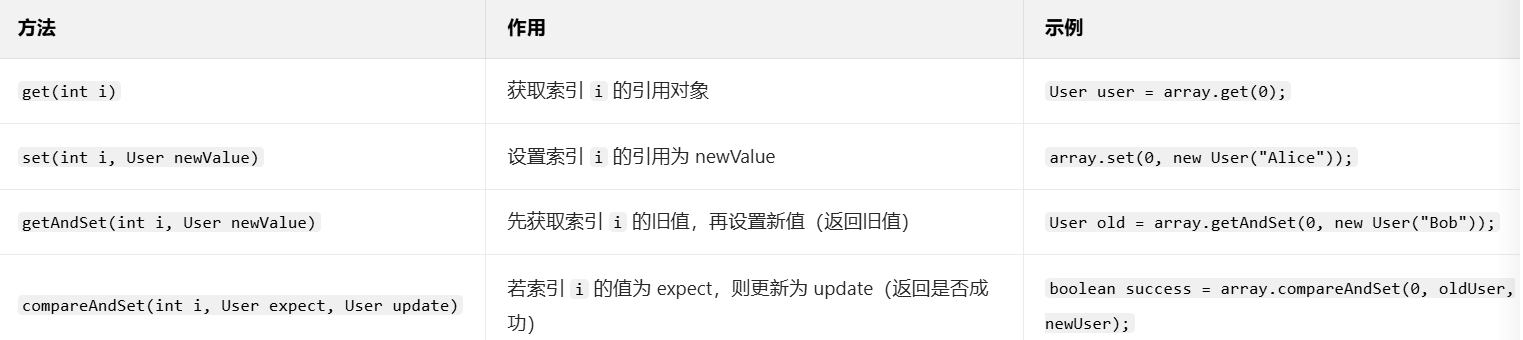
三、引用类型原子类
用于对对象引用进行原子操作:
AtomicReference<V>:原子更新对象引用,可对任意对象引用进行原子操作,例如原子更新自定义对象。AtomicStampedReference<V>:通过添加版本号(stamp)解决 CAS 中的 ABA 问题,确保引用更新的正确性。AtomicMarkableReference<V>:通过布尔标记位记录引用是否被修改,是AtomicStampedReference的简化版,仅关注是否修改过。
用于对对象引用进行原子操作,支持复杂对象的线程安全更新,解决 CAS 中的 ABA 问题。
1. AtomicReference<V>(原子更新对象引用)
- 核心功能:对任意类型的对象引用进行原子操作,可实现对象的原子替换、更新等。
- 常见方法:

2. AtomicStampedReference<V>(解决 ABA 问题的引用原子类)
- 核心功能 :在
AtomicReference基础上增加版本号(stamp),每次更新时版本号递增,解决 CAS 中的 ABA 问题(即对象被修改后又改回原值,导致 CAS 误判)。 - 常见方法:

3. AtomicMarkableReference<V>(带标记的引用原子类)
- 核心功能 :通过布尔标记位(mark) 记录引用是否被修改过,是
AtomicStampedReference的简化版(不关心修改次数,只关心 "是否修改过")。 - 常见方法:

四、字段更新器
用于原子更新对象的特定字段(需为 volatile 修饰):
AtomicIntegerFieldUpdater:原子更新对象的int类型字段。AtomicLongFieldUpdater:原子更新对象的long类型字段。AtomicReferenceFieldUpdater<V, T>:原子更新对象的引用类型字段。
用于原子更新对象的非静态 volatile 字段(无需修改对象类定义,动态实现字段的原子操作)。
1. AtomicIntegerFieldUpdater<T>(原子更新 int 类型字段)
- 核心功能 :对指定类的
int类型 volatile 字段进行原子更新,字段需为非 private、非 static。 - 使用步骤 :
- 通过
newUpdater(Class<T> tClass, String fieldName)创建更新器。 - 调用更新方法操作目标对象的字段。
- 通过
- 常见方法:

java
class User {
volatile int age; // 必须是 volatile 修饰的非静态字段
public User(int age) { this.age = age; }
}
// 创建更新器(指定类和字段名)
AtomicIntegerFieldUpdater<User> updater = AtomicIntegerFieldUpdater.newUpdater(User.class, "age");
User user = new User(20);
updater.incrementAndGet(user); // 原子自增 age,结果为 21- 适用场景:需要原子更新已有类的 int 字段,但无法修改类定义(如第三方库的类)。
2. AtomicLongFieldUpdater<T>(原子更新 long 类型字段)
- 核心功能 :与
AtomicIntegerFieldUpdater类似,针对long类型的 volatile 字段。 - 常见方法 :
incrementAndGet(T obj)、compareAndSet(T obj, long expect, long update)等,用法一致。
3. AtomicReferenceFieldUpdater<T, V>(原子更新引用类型字段)
- 核心功能 :对指定类的引用类型 volatile 字段进行原子更新(如
User类中的address字段)。 - 常见方法 :
compareAndSet(T obj, V expect, V update)、getAndSet(T obj, V newValue)等。 - 示例:
java
class User {
volatile String address; // 引用类型 volatile 字段
public User(String address) { this.address = address; }
}
// 创建更新器
AtomicReferenceFieldUpdater<User, String> updater = AtomicReferenceFieldUpdater.newUpdater(User.class, String.class, "address");
User user = new User("Beijing");
updater.compareAndSet(user, "Beijing", "Shanghai"); // 原子更新 address 为 Shanghai五、累加器类(高并发场景优化)
LongAdder/DoubleAdder:高并发下的累加器,相比AtomicLong性能更优,内部通过分段累加减少竞争。LongAccumulator/DoubleAccumulator:支持自定义累加逻辑的累加器,可实现更灵活的原子操作。
专为高并发场景设计的累加器,通过分段累加减少线程竞争,性能优于传统原子类。
1. LongAdder/DoubleAdder(高并发累加器)
- 核心功能 :高效实现
long/double类型的累加操作,高并发下性能远优于AtomicLong/AtomicDouble(内部通过多个 "单元格" 分散竞争,最终汇总结果)。 - 常见方法 (以
LongAdder为例):
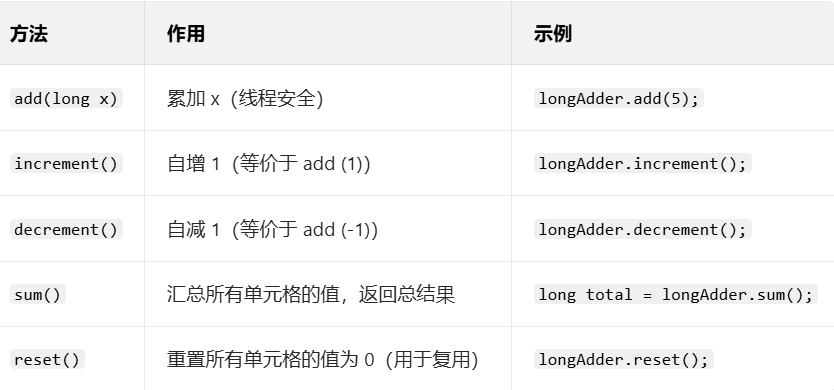
- 适用场景:高并发计数器(如 QPS 统计、接口调用次数),只需要最终结果,不需要实时精确值的场景。
2. LongAccumulator/DoubleAccumulator(自定义累加逻辑)
- 核心功能 :支持自定义累加逻辑(通过
LongBinaryOperator函数),比LongAdder更灵活(如实现 "最大值""最小值" 等聚合操作)。 - 常见方法 (以
LongAccumulator为例):
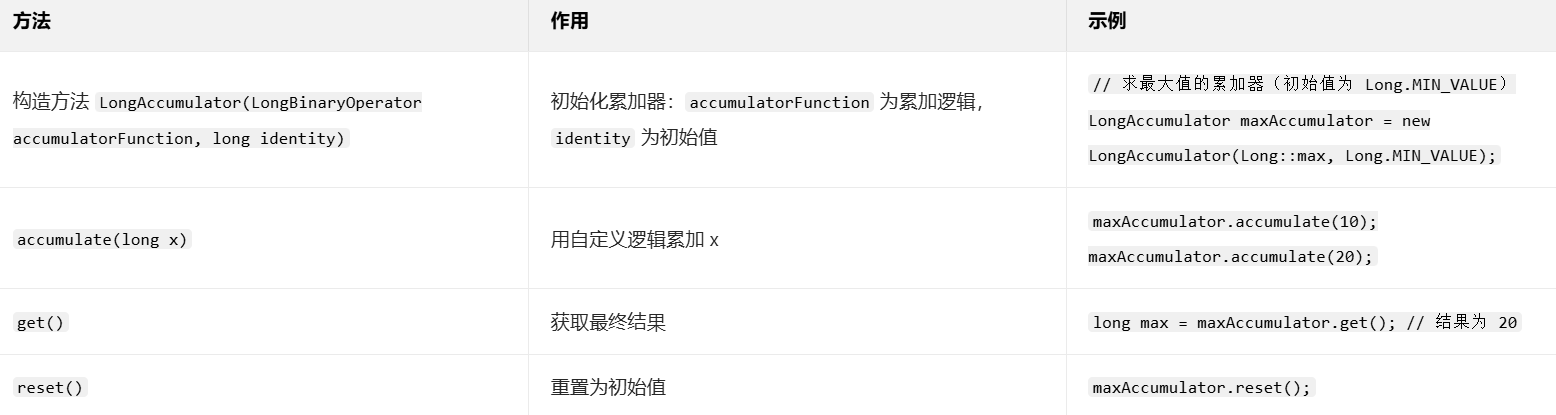
- 适用场景:高并发下需要自定义聚合逻辑的场景(如求最大值、最小值、累加乘积等)。
四、线程池
虽然创建销毁线程比创建销毁进程更轻量,但是在频繁创建销毁线程的时候还是会比较低效。
线程池就是为了解决这个问题,如果某个线程不再使用了,并不是真正把线程释放,而是放到一个"池子"中,下次如果需要用到线程就直接从池子中取,不必通过系统来创建了。
2.1ExecutorService 和 Executors
代码示例:
• ExecutorService 表示一个线程池实例。
• Executors是一个工厂类,能够创建出几种不同风格的线程池。
• ExecutorService 的 submit 方法能够向线程池中提交若干个任务。
java
ExecutorService pool = Executors.newFixedThreadPool(10);
pool.submit(new Runnable() {
@Override
public void run() {
System.out.println("hello");
}
});Executors 创建线程池的几种方式:
• newFixedThreadPool:创建固定线程数的线程池。
• newCachedThreadPool:创建线程数目动态增长的线程池。
• newSingleThreadExecutor:创建只包含单个线程的线程池。
• newScheduledThreadPool:设定延迟时间后执行命令,或者定期执行命令,是进阶版的Timer。
Executors 本质上是ThreadPoolExecutor类的封装。
2.2ThreadPoolExecutor
ThreadPoolExecutor 提供了更多的可选参数,可以进一步细化线程池行为的设定。
ThreadPoolExecutor 的构造方法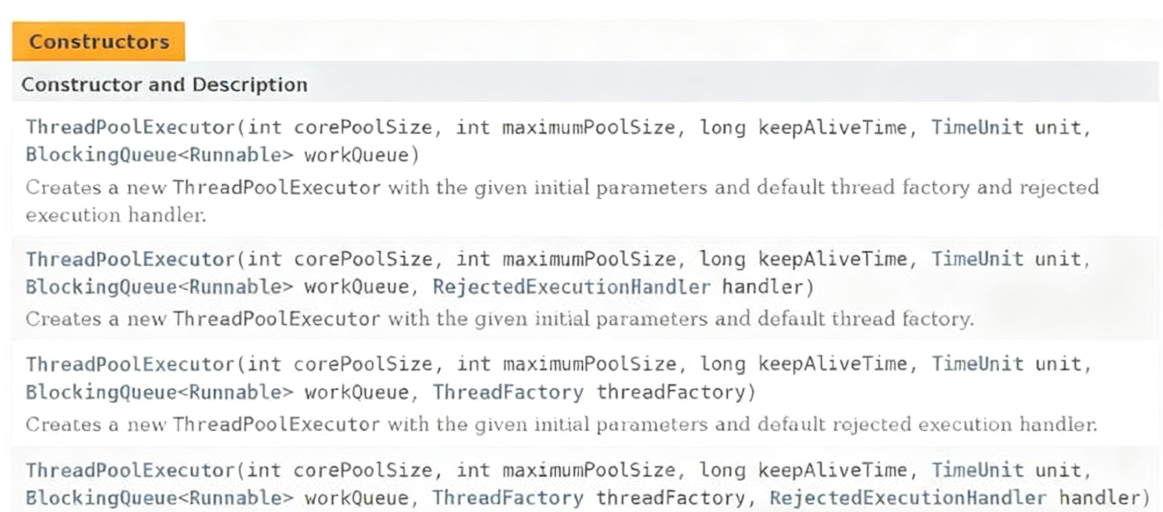
**理解ThreadPoolExecutor构造方法的参数**
把创建一个线程池想象成开个公司,每个员工相当于一个线程。
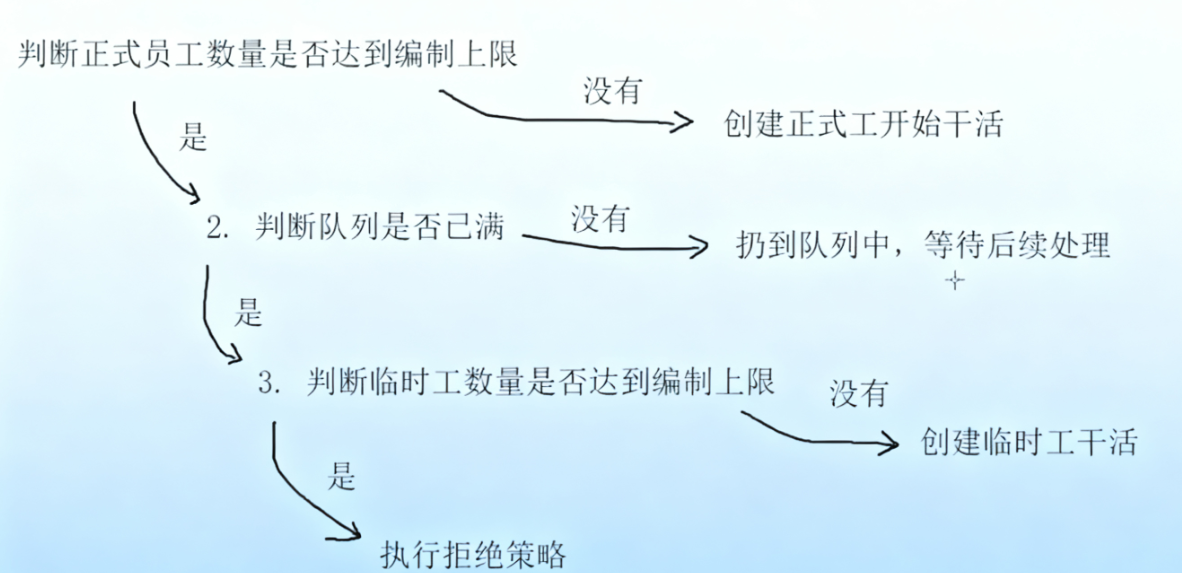
• corePoolSize:正式员工的数量。(正式员工,一旦录用,永不辞退)
• maximumPoolSize:正式员工 + 临时工的数目。(临时工:一段时间不干活,就被辞退)
• keepAliveTime:临时工允许的空闲时间。
• unit:keepaliveTime 的时间单位、是秒、分钟,还是其他值。
• workQueue:传递任务的阻塞队列。
• threadFactory:创建线程的工厂,参与具体的创建线程工作。
• RejectedExecutionHandler:拒绝策略,如果任务量超出公司的负荷了接下来怎么处理。
◦ AbortPolicy():超过负荷,直接抛出异常。
◦ CallerRunsPolicy():调用者负责处理。
◦ DiscardOldestPolicy():丢弃队列中最老的任务。
◦ DiscardPolicy():丢弃新来的任务。
代码示例:
java
ExecutorService pool = new ThreadPoolExecutor(1, 2, 1000, TimeUnit.MILLISECONDS,
new SynchronousQueue<Runnable>(),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy
for(int i=0;i<3;i++) {
pool.submit(new Runnable() {
@Override
void run() {
System.out.println("hello");
}
});
}2.3线程池的工作流程
五、信号量Semaphore
信号量,用来表示"可用资源的个数",本质上就是一个计数器。
理解信号量
可以把信号量想象成是停车场的展示牌:当前有车位100个,表示有100个可用资源。
当有车开进去的时候,就相当于申请一个可用资源,可用车位就-1(这个称为信号量的P操作)
当有车开出来的时候,就相当于释放一个可用资源,可用车位就+1(这个称为信号量的V操作)
如果计数器的值已经为0了,还尝试申请资源,就会阻塞等待,直到有其他线程释放资源。
Semaphore的PV操作中的加减计数器操作都是原子的,可以在多线程环境下直接使用。
代码示例
• 创建Semaphore示例,初始化为4,表示有4个可用资源。
• acquire方法表示申请资源(P操作),release方法表示释放资源(V操作)。
• 创建20个线程,每个线程都尝试申请资源,sleep1秒之后,释放资源,观察程序的执行效果。
java
Semaphore semaphore = new Semaphore(4);
Runnable runnable = new Runnable() {
@Override
public void run() {
try {
System.out.println("申请资源");
semaphore.acquire();
System.out.println("我获取到资源了");
Thread.sleep(1000);
System.out.println("我释放资源了");
semaphore.release();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
for (int i = 0; i < 20; i++) {
Thread t = new Thread(runnable);
t.start();
}PV 操作是操作系统中用于进程同步与互斥的核心机制,由荷兰计算机科学家迪杰斯特拉(Dijkstra)提出,用于解决多个进程(或线程)对共享资源的有序访问问题。
核心概念:信号量(Semaphore)
PV 操作基于信号量(Semaphore) 实现,信号量是一个整数变量(通常用S表示),代表可用资源的数量或进程同步的状态。
PV 操作的定义
P 操作(Proberen,荷兰语 "尝试")
- 作用:申请资源或等待信号。
- 操作逻辑:
java
S = S - 1;
若 S ≥ 0:当前进程继续执行(成功获取资源);
若 S < 0:当前进程被阻塞,并插入到该信号量的等待队列中。 2. V 操作(Verhogen,荷兰语 "增加")
- 作用:释放资源或发送信号。
- 操作逻辑:
java
S = S + 1;
若 S > 0:当前进程继续执行(无等待进程);
若 S ≤ 0:从该信号量的等待队列中唤醒一个进程,使其进入就绪状态,当前进程继续执行。 核心用途
-
**实现互斥(独占资源访问)**多个进程竞争同一共享资源时,通过 PV 操作保证同一时间只有一个进程访问资源。
- 初始化信号量
S = 1(表示资源可用)。 - 进程访问资源前执行P 操作 (申请资源,
S变为 0,其他进程再申请会被阻塞)。 - 进程用完资源后执行V 操作 (释放资源,
S变回 1,唤醒等待进程)。
- 初始化信号量
**实现同步(协调进程执行顺序)**确保进程按特定顺序执行(如 "先生产后消费")。
- 初始化信号量
S = 0(表示初始状态无资源)。 - 前驱进程完成后执行V 操作 (发送 "已完成" 信号,
S变为 1)。 - 后继进程开始前执行P 操作 (等待信号,若
S=0则阻塞,直到前驱进程唤醒)。
java
Semaphore S = 0; // 同步信号量
// 生产者进程
producer() {
生产数据;
V(S); // 通知消费者:数据已生产
}
// 消费者进程
consumer() {
P(S); // 等待生产者信号
消费数据;
}特点:
- 原子性:PV 操作是不可分割的原子操作,执行过程中不会被其他进程打断(由操作系统保证)。
- 灵活性 :通过信号量的不同初始值,可实现互斥(
S=1)、同步(S=0)、资源池管理(S=N,表示 N 个同类资源)等场景。
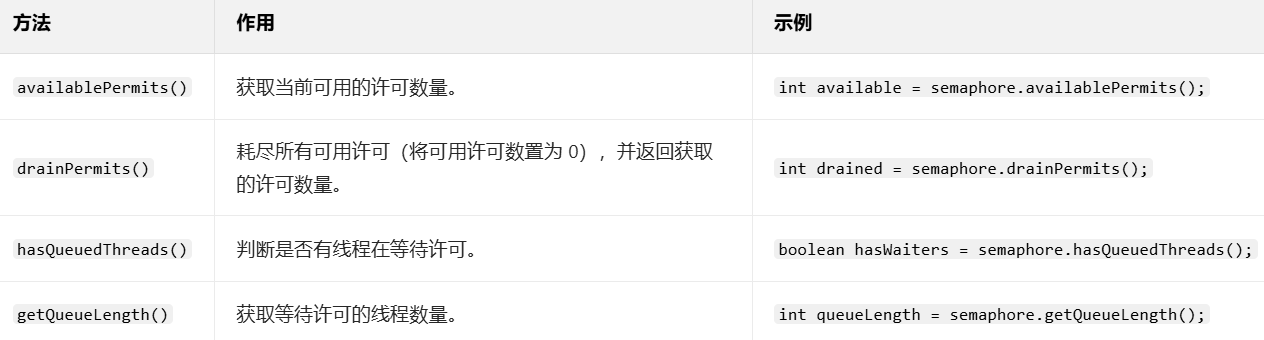
Semaphore 常用的方法
一、获取许可的方法

二、释放许可的方法

三、其他工具方法
4、CountDownLatch
同时等待N个任务执行结束。
好像跑步比赛,10个选⼿依次就位,哨声响才同时出发;所有选手都通过终点,才能公布成绩。
• 构造CountDownLatch实例,初始化10表示有10个任务需要完成。
• 每个任务执行完毕,都调用 latch.countDown() 。在CountDownLatch内部的计数器同时自减。
• 主线程中使用 latch.await();阻塞等待所有任务执行完毕,相当于计数器为0了
java
public class Demo {
public static void main(String[] args) throws Exception {
CountDownLatch latch = new CountDownLatch(10);
Runnable r = new Runable() {
@Override
public void run() {
try {
Thread.sleep(Math.random() * 10000);
latch.countDown();
} catch (Exception e) {
e.printStackTrace();
}
}
};
for (int i = 0; i < 10; i++) {
new Thread(r).start();
}
// 必须等到 10 ⼈全部回来
latch.await();
System.out.println("⽐赛结束");
}
}5、相关面试题
1)线程同步的方式有哪些?
synchronized,ReentrantLock,Semaphore 等都可以用于线程同步。
2)为什么有了 synchronized 还需要 juc 下的 lock ?
以juc的ReentrantLock为例,
• synchronized使用时不需要手动释放锁,ReentrantLock使用时需要手动释放,使用起来更灵活。
• synchronized在申请锁失败时,会
java
class AtomicInteger {
private int value;
public int getAndIncrement() {
int oldValue = value;
while ( CAS(value, oldValue, oldValue+1) != true) {
oldValue = value;
}
return oldValue;
}
}死等。ReentrantLock可以通过trylock的方式等待一段时间就放弃。
• synchronized是非公平锁,ReentrantLock默认是非公平锁。可以通过构造方法传入一个true开启公平锁模式。
• synchronized 是通过 Object 的 wait / notify 实现等待---唤醒,每次唤醒的是一个随机等待的线程。
ReentrantLock 搭配Condition类实现等待---唤醒,可以更精确控制唤醒某个指定的线程。
3)AtomicInteger 的实现原理是什么?
AtomicInteger 是 Java 中用于实现整型变量原子操作的类,其核心原理是基于 CAS(Compare And Swap,比较并交换)机制 配合 volatile 变量 实现无锁的线程安全操作,避免了传统锁机制(如 synchronized)的性能开销。
核心实现细节
java
private volatile int value;volatile保证了value的可见性 :任何线程对value的修改,其他线程都能立即看到最新值。- 但
volatile不保证原子性(如i++这类复合操作仍会有线程安全问题),因此需要 CAS 机制配合。
二.CAS 机制的实现 CAS 是一种无锁的原子操作,通过硬件指令(如 x86 的 cmpxchg)保证原子性,其逻辑可简化为:
java
// 伪代码:比较并交换
boolean compareAndSwap(int expect, int update) {
if (value == expect) { // 比较当前值是否与预期值一致
value = update; // 若一致,更新为新值
return true; // 操作成功
} else {
return false; // 若不一致,不更新,返回失败
}
}AtomicInteger的所有原子方法(如incrementAndGet、compareAndSet等)均基于 CAS 实现.
核心方法的实现逻辑(以 incrementAndGet 为例) incrementAndGet() 用于实现原子性的「自增并返回新值」,其源码(简化后)如下:
java
public final int incrementAndGet() {
for (;;) { // 自旋重试:若CAS失败则循环重试
int current = get(); // 获取当前值(volatile保证可见性)
int next = current + 1; // 计算目标值
// 执行CAS:若当前值仍为current,则更新为next
if (compareAndSet(current, next)) {
return next; // 成功后返回新值
}
// 若失败(被其他线程修改),则重新循环尝试
}
}其中 compareAndSet 是 native 方法,底层通过 Unsafe 类调用 CPU 原子指令实现:
java
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}unsafe:Java 提供的用于直接操作内存的工具类。valueOffset:value变量在对象内存中的偏移量,用于直接定位内存地址。
4)信号量听说过么?之前都用在过哪些场景下?
信号量,用来表示"可用资源的个数",本质上就是一个计数器。
使用信号量可以实现"共享锁",比如某个资源允许3个线程同时使用,那么就可以使用P操作作为加锁,V操作作为解锁,前三个线程的P操作都能顺利返回,后续线程再进行P操作就会阻塞等待,直到前面的线程执行了V操作。