引用
在Redis高效表现的背后,是一套精密的存储引擎设计。全局哈希表作为数据的"总目录",通过指针灵活指向各种RedisObject,实现了统一的快速访问。
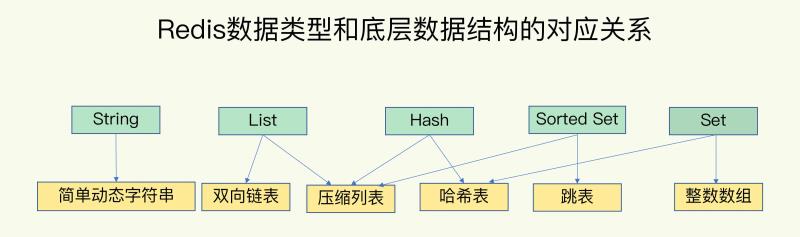
更巧妙的是,Redis会根据数据特征智能选择最优存储结构:
-
Set: 在纯整数场景下采用紧凑的整数数组 ,复杂场景切换到哈希表。
-
**SDS字符串:**通过5种精确定制的头部类型,实现极致的内存效率。
-
Zset/List/Hash: 在小数据量时使用内存友好的压缩列表 ,大数据量时自动切换至性能更优的跳表 或哈希表。
Redis的全局哈希表
如果值是集合类型的话,作为数组元素的哈希桶怎么来保存呢?
哈希桶中的元素保存的并不是值本身,而是指向具体值的指针。不管值是 String,还是集合类型,哈希桶中的元素都是指向它们的指针。
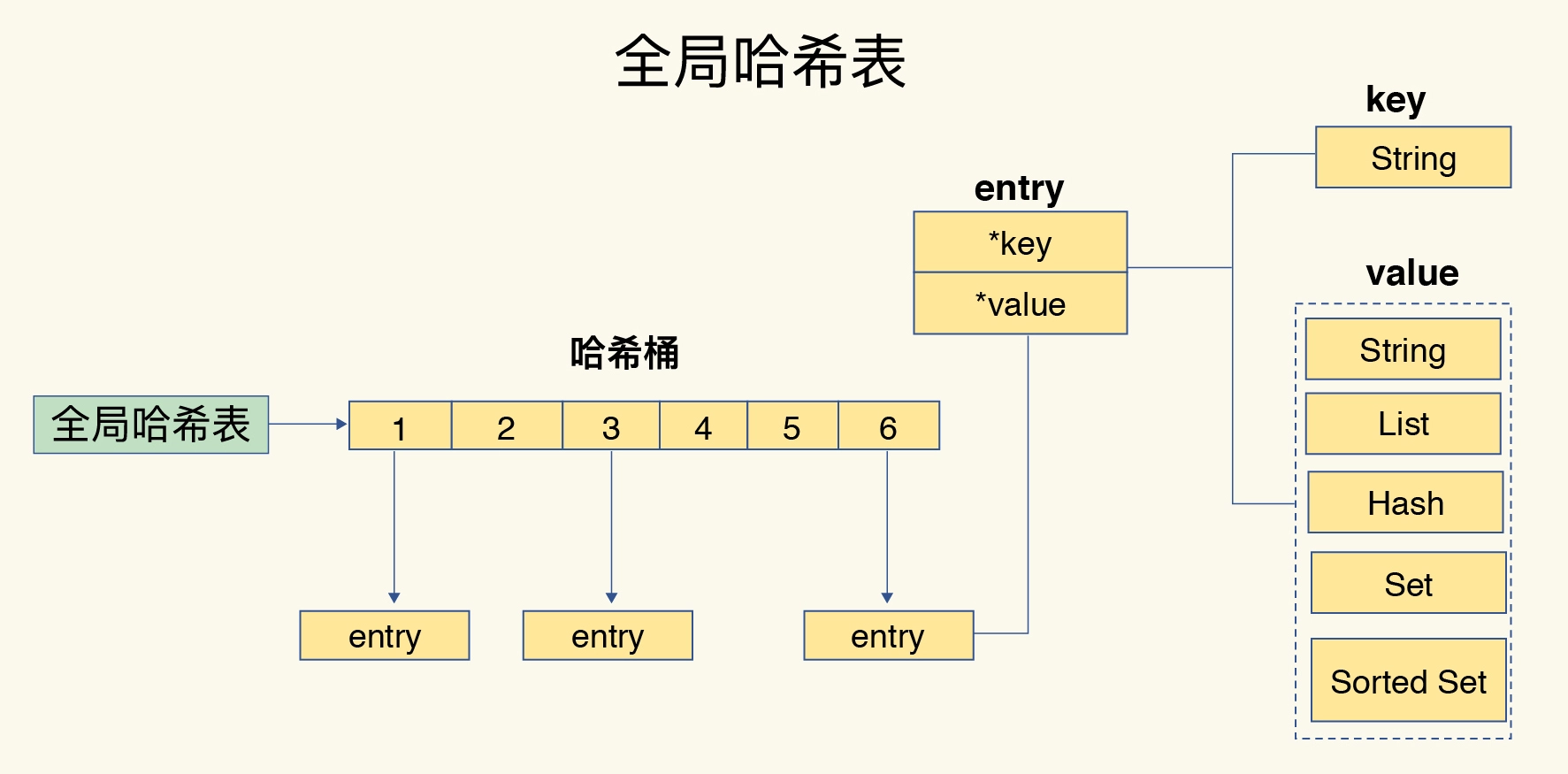
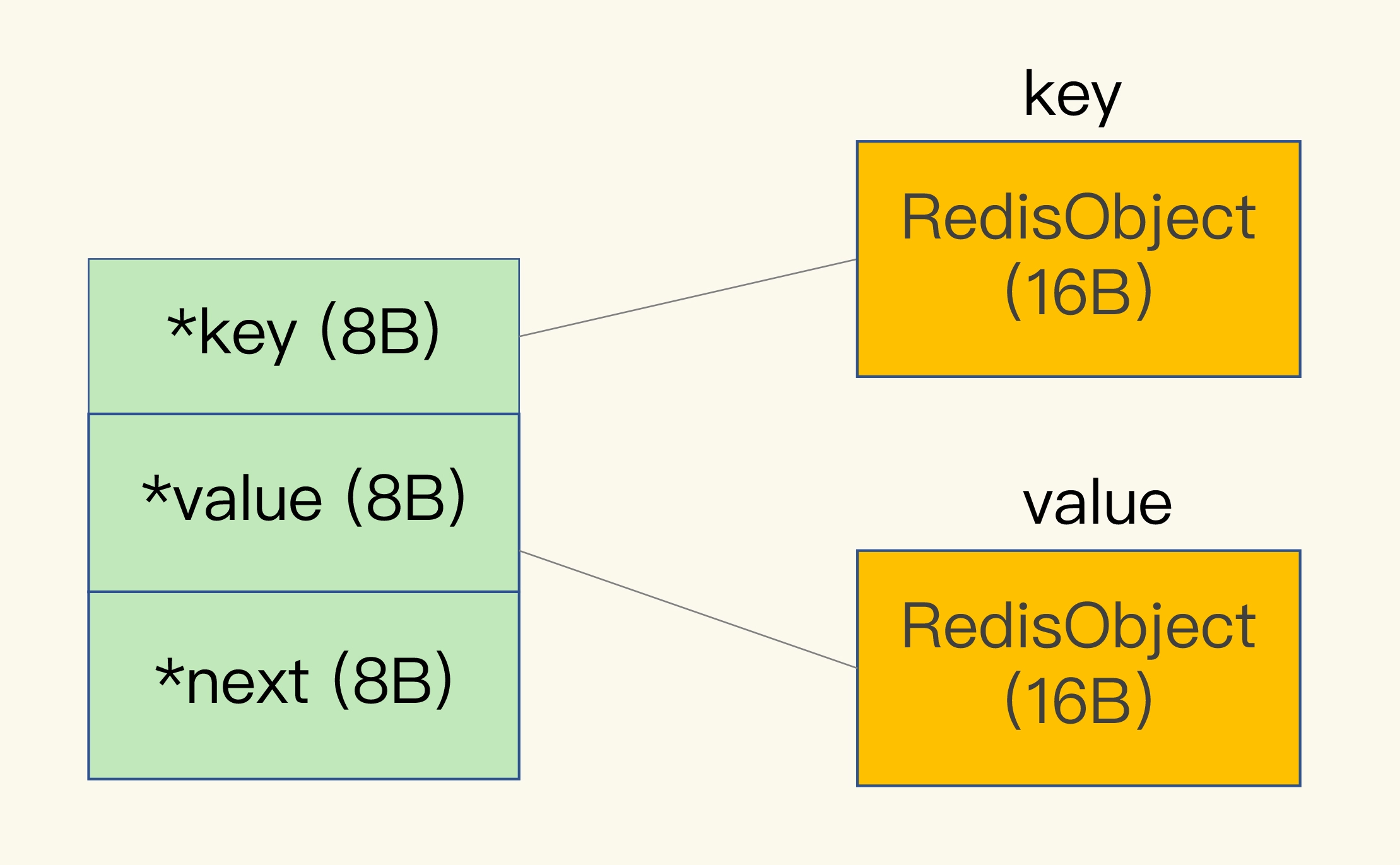
哈希桶的entry结构图,key和value都指向一个RedisObject。
Redis的数据类型
Zset底层数据结构的切换
压缩列表
- 当一个 zset 中的元素个数小于 zset-max-ziplist-entries 配置的阈值(默认值为 128)。
- 当 zset 中的每个元素的长度小于 zset-max-ziplist-value 配置的阈值(默认值为 64 字节)。
- 当同时满足这些条件时,Redis 将使用压缩列表来保存 zset。
跳表
- 如果 zset 中的元素个数超过 zset-max-ziplist-entries。
- 如果 zset 中的任何元素长度超过 zset-max-ziplist-value。
- 当同时满足任一条件时,Redis 将使用跳表来保存 zset。
List底层数据结构的切换
压缩列表
- 当一个 list 中的元素个数小于 list-max-ziplist-entries 配置的阈值(默认值为 512)。
- 当 list 中的每个元素的长度小于 list-max-ziplist-value 配置的阈值(默认值为 64 字节)。
- 当同时满足这些条件时,Redis 将使用压缩列表来保存 list。
双向链表
- 如果 list 中的元素个数超过 list-max-ziplist-entries。
- 如果 list 中的任何元素长度超过 list-max-ziplist-value。
- 当同时满足任一条件时,Redis 将使用双向链表来保存 list。
Hash底层数据结构的切换
压缩列表
- 当一个 list 中的元素个数小于 hash-max-ziplist-entries 配置的阈值(默认值为 512)。
- 当 list 中的每个元素的长度小于 hash-max-ziplist-value 配置的阈值(默认值为 64 字节)。
- 当同时满足这些条件时,Redis 将使用压缩列表来保存 hash。
哈希表
- 如果 list 中的元素个数超过 hash-max-ziplist-entries。
- 如果 list 中的任何元素长度超过 hash-max-ziplist-value。
- 当同时满足任一条件时,Redis 将使用双向链表来保存 hash。
Set底层数据结构的切换
整数数组
- 当 Set 中的所有元素都是整数,且元素个数小于 set-max-intset-entries 配置的阈值(默认值为 512)。
哈希表
- 如果 Set 中包含非整数类型的元素时。
- 如果 Set 中的元素个数超过 set-max-intset-entries。
- 当同时满足任一条件时,Redis 将使用哈希表来保存 Set。
Redis的底层数据结构
简单动态字符串
Redis 5.0 的 SDS 数据结构:

len:记录了字符串长度。这样获取字符串长度的时候,只需要返回这个成员变量值就行,时间复杂度只需要 O(1)。
alloc:分配给字符数组的空间长度,不包括SDS头部和结尾的空字符。这样在修改字符串的时候,可以通过 alloc - len 计算出剩余的空间大小,可以用来判断空间是否满足修改需求,如果不满足的话,就会自动将 SDS 的空间扩展至执行修改所需要的大小,然后才执行实际的修改操作,所以使用 SDS 既不需要手动修改 SDS 的空间大小,也不会出现前面所说的缓冲区溢出的问题。
flags:用来表示不同类型的 SDS。一共设计了 5 种类型,分别是 sdshdr5、sdshdr8、sdshdr16、sdshdr32 和 sdshdr64。
buf\[\]:字符数组,用来保存实际数据。不仅可以保存字符串,也可以保存二进制数据。
扩容机制
- 如果所需的 sds 长度小于 1 MB,那么最后的扩容是按照翻倍扩容来执行的,即 2 倍 的 newlen,并适当升级flags类型。
- 如果所需的 sds 长度超过 1 MB,那么最后的扩容长度应该是 newlen + 1MB,并适当升级flags类型。
flags如何节省内存空间
sdshdr5、sdshdr8、sdshdr16、sdshdr32 和 sdshdr64,这5种类型的区别就在于,它们数据结构中的 len 和 alloc 成员变量的数据类型不同,头部占用空间也不同。
头部占用空间区别:
-
sdshdr5:
struct sdshdr5 {
unsigned char flags; // 低5位表示字符串长度,高3位表示类型
char buf[];
};
占用空间:1字节(仅包含flags)。 -
sdshdr8:
struct sdshdr8 {
uint8_t len; // 当前字符串长度
uint8_t alloc; // 分配的空间大小
unsigned char flags; // 类型标识
char buf[];
};
占用空间:1(len) + 1(alloc) + 1(flags) = 3字节。 -
sdshdr16:
struct sdshdr16 {
uint16_t len; // 当前字符串长度
uint16_t alloc; // 分配的空间大小
unsigned char flags; // 类型标识
char buf[];
};
占用空间:2(len) + 2(alloc) + 1(flags) = 5字节。 -
sdshdr32:
struct sdshdr32 {
uint32_t len; // 当前字符串长度
uint32_t alloc; // 分配的空间大小
unsigned char flags; // 类型标识
char buf[];
};
占用空间:4(len) + 4(alloc) + 1(flags) = 9字节。 -
sdshdr64:
struct sdshdr64 {
uint64_t len; // 当前字符串长度
uint64_t alloc; // 分配的空间大小
unsigned char flags; // 类型标识
char buf[];
};
占用空间:8(len) + 8(alloc) + 1(flags) = 17字节。
压缩列表
压缩列表实际上类似于一个数组,数组中的每一个元素都对应保存一个数据。和数组不同的是,压缩列表在表头有三个字段 zlbytes、zltail 和 zllen,分别表示压缩列表占用字节数、列表尾的偏移量和列表中的 entry 个数;压缩列表在表尾还有一个 zlend,表示列表结束。
如果我们要查找定位第一个元素和最后一个元素,可以通过表头三个字段的长度直接定位,复杂度是 O(1)。而查找其他元素时,就没有这么高效了,只能逐个查找,此时的复杂度就是 O(N) 了。

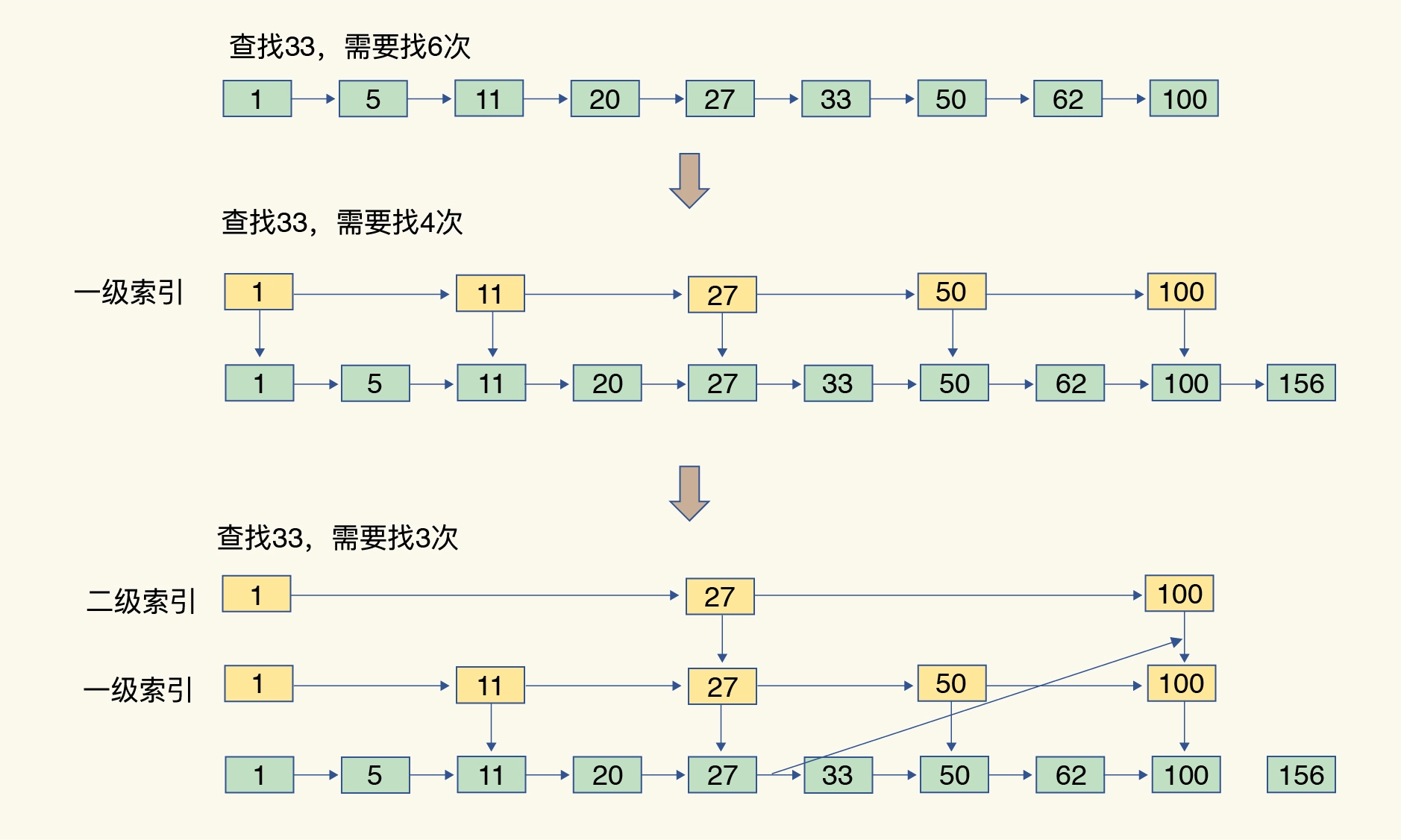
跳表
跳表在链表的基础上,增加了多级索引,通过索引位置的几个跳转,实现数据的快速定位。查找、删除、新增的时间复杂度都是log(n)。
感谢您的阅读!如果文章中有任何问题或不足之处,欢迎及时指出,您的反馈将帮助我不断改进与完善。期待与您共同探讨技术,共同进步!