我想用文字表达一下业内许多人正在经历,但却没有人公开谈论的感受。
直播流订阅量过大。实际上,太多公司都在争夺同一个相对较小的发布/订阅/事件直播市场,以及极其微小的流媒体处理市场。
我的预测很简单------我们将看到大量的市场整合。我认为我们正处于整合的初期阶段。原因如下:
1. 行业领导者已经不太行
Confluent 无疑是事件流和流处理领域的领导者。但 Confluent 目前的表现并不理想。
股价是最简洁明了的指标。该股首次公开募股时股价为36美元,最高曾达到91美元,并在过去三年多的时间里主要在20至30美元之间波动。
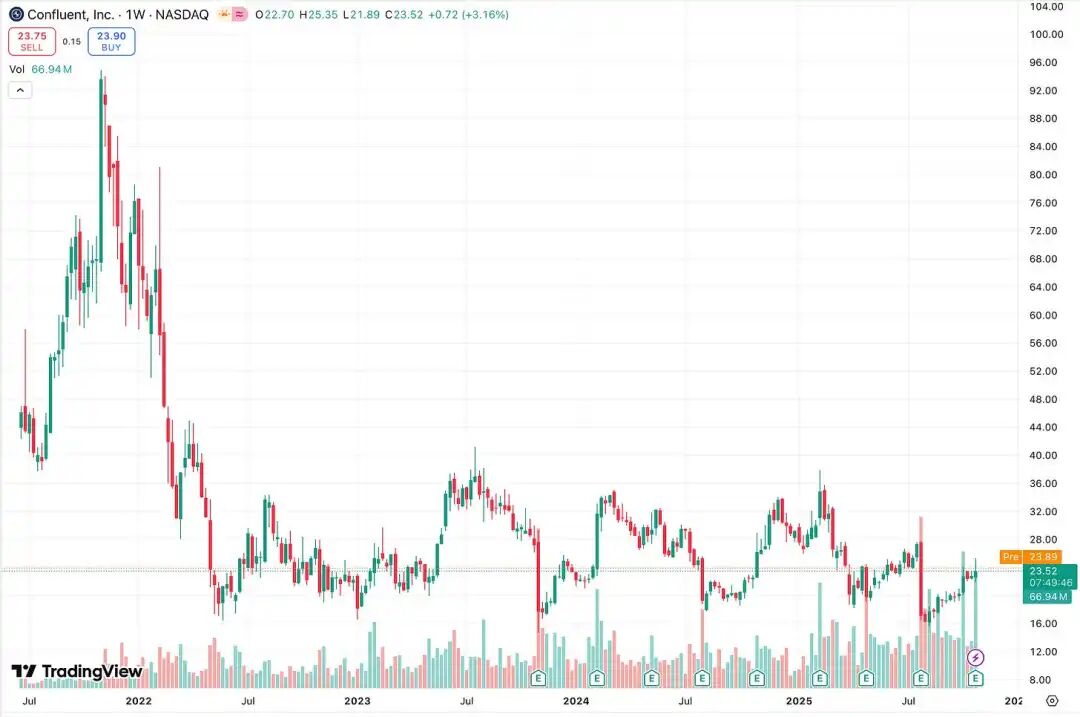
这表现简直糟糕透了,毋庸置疑。
即使我们忽略91美元的峰值,将其视为泡沫时期,截至撰稿时,该股仍比IPO发行价下跌了36%。作为该股的长期跟踪者,我无法形容它在20-30美元区间徘徊的感受。
为什么股票会这样?
Confluent的增长已接近顶峰。他们曾经快速增长的明星产品------云计算产品,如今增长速度正在迅速放缓。
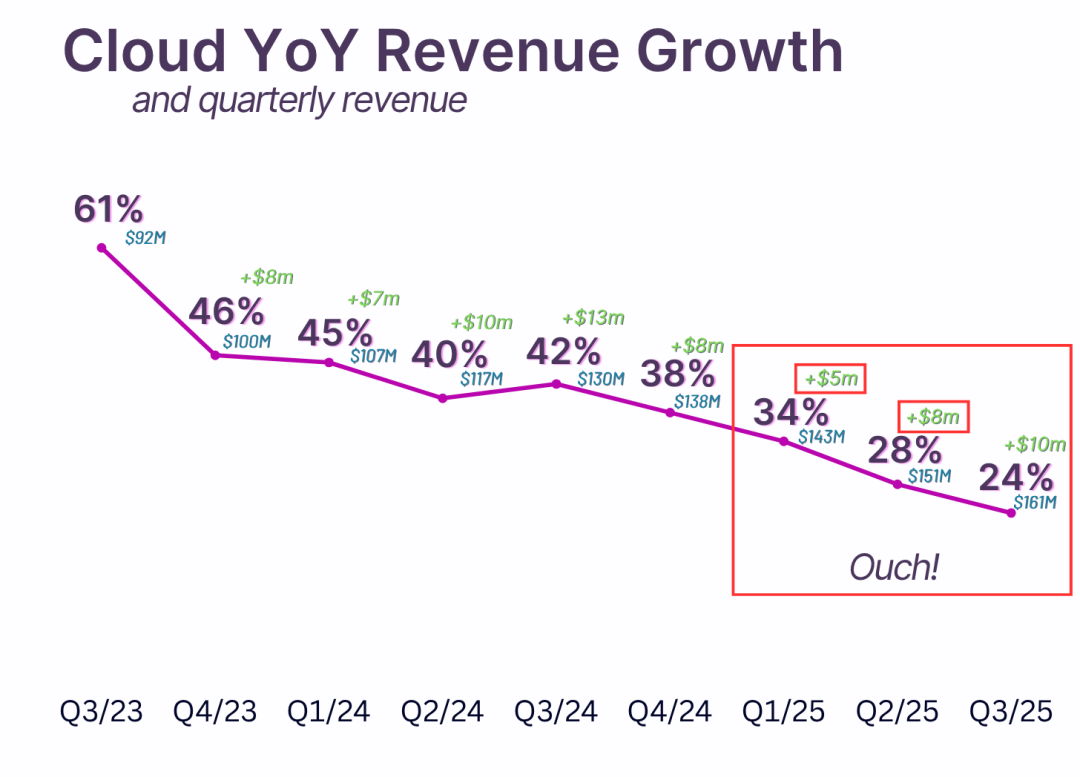 Confluent Cloud 的同比营收增长情况,以及季度营收和季度名义增长情况,都十分明显。可以看出,他们每季度新增营收很难超过 800 万至 1000 万美元。
Confluent Cloud 的同比营收增长情况,以及季度营收和季度名义增长情况,都十分明显。可以看出,他们每季度新增营收很难超过 800 万至 1000 万美元。
更糟糕的是,这24%的增长率仅仅是针对他们的云产品。另一大笔业务收入来自本地部署销售(Confluent平台)。这部分收入在2025年第三季度为1.254亿美元,仅增长了14%。
总计收入增长率为 19.4%。
2025年还没结束,Confluent的增长率就已经达到两位数了。如果接下来的几个季度保持同样的趋势,到明年年底我们可能会看到个位数的增长率。
达到这样的营收水平绝非易事,但市场对你的价值是相对于其他机会而言的。而且其他公司的表现要好得多:
-
Confluent 的年度经常性收入 (ARR) 为 11 亿美元,增长率为 19.4%。
-
Snowflake 过去 12 个月的营收为 41 亿美元,增长率为29.2%。
-
Databricks 的估值约为 40 亿美元,并且据称以 50% 的速度增长。
-
(一个极端且略微不相关的例子)Azure 的年度经常性收入 (ARR) 为 750 亿美元,并且以39% 的 速度增长。
从图中可以看出,Confluent 销售的产品的潜在市场总规模似乎比 Snowflake/Databricks 销售的产品要小得多。
这些财务数据是流媒体发展已达顶峰的最有力证据。你无法用任何说辞来掩盖事实。
接下来我要介绍的内容更偏向定性分析,但也很有趣。
Confluent == Kafka
Confluent 的性能对于 Kafka 来说至关重要,因为他们是 Kafka 的创建者和领导者。从某种意义上说,他们就是 Kafka 本身:
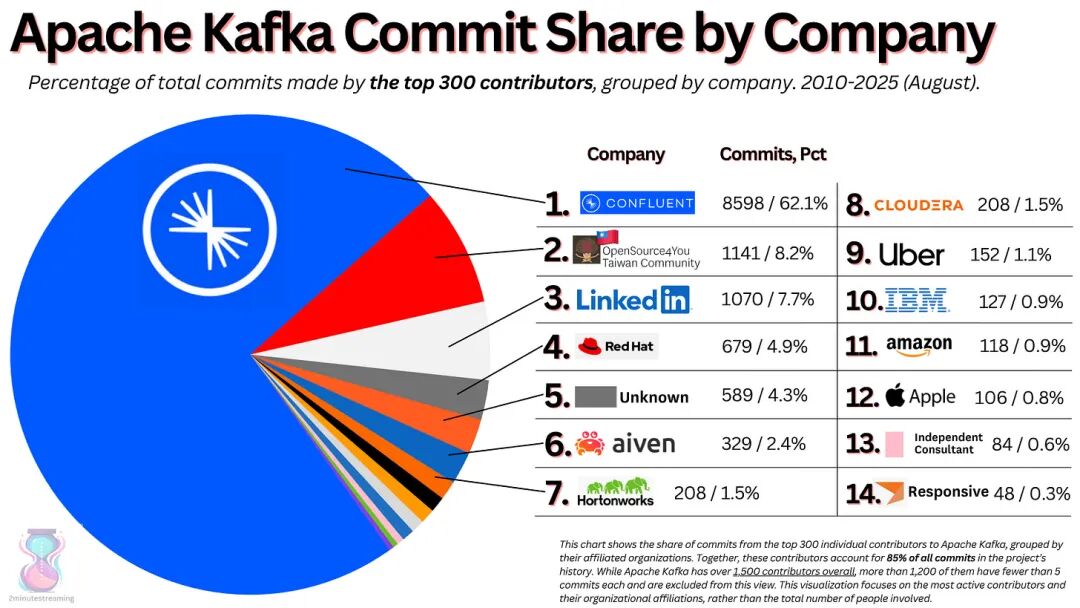 对 2010 年至 2025 年间 85% 以上的 Apache Kafka 开源贡献进行分析。
对 2010 年至 2025 年间 85% 以上的 Apache Kafka 开源贡献进行分析。
他们不公布产品收入明细,但最近分享了Flink的数据。Flink的年度经常性收入(ARR)勉强达到1400万美元左右。在10亿美元的总收入中,这很难成为公司增长放缓的救星。除了Kafka和Flink之外,我看不出公司还有其他产品有潜力带来可观的利润。
因此,据称他们的大部分收入都来自 Kafka。从这个角度来看,我们就能理解增长放缓的合理原因了。
2. 竞争空前激烈
Kafka 正在变得司空见惯。现在几乎人人都用 Kafka 服务,连奶奶奶奶都用上了。
-
AWS MSK已经推出6年了。据传,它的收入将超过Confluent的全部业务(年度经常性收入达10亿至15亿美元)。1
-
Google Cloud Kafka(2024 年 7 月发布)
-
Oracle Kafka(预计于2025年8月发布)
-
Azure 事件中心(具有Kafka API )
-
阿里云 Kafka
-
OVHCloud Kafka
-
Heroku Kafka
-
Canonical(Ubuntu 背后的公司)Kafka(2024 年 2 月发布)
还有创业公司:
-
Aiven
-
Redpanda
-
StreamNative(Pulsar,但使用 Kafka API)
-
AutoMQ
-
布夫斯特里姆
-
Instaclustr Kafka
目前只有 Snowflake 和 Databricks 这两家巨头尚未涉足该领域。但它们很可能会这样做。Snowflake差点在 2025 年初收购了 Redpanda 。
这些巨头们处境有利,因为它们可以观望市场走向,并四处寻找合适的收购目标。它们收购上述部分公司只是时间问题。
顺便说一下,我当时介绍的是 Kafka 市场。当然,还有很多其他竞争对手。
-
Google PubSub
-
Azure 事件中心
-
Cloudflare Pipelines
-
Redis 流
-
s2.dev(小型创业公司)
-
NATS
3. Kafka 的价格将跌至历史新低
Kafka 的价格正在大幅下跌。
现在每个云厂商都可以买到 Kafka 产品------仅此一项就使价格下降了约6.5 倍。
对业界来说不幸的是,真正的价格战始于 2023 年,当时一种新的架构表明,你可以立即将 Kafka 的价格降低10 倍以上。
WarpStream率先采用了无盘Kafka架构,该架构不再将数据存储在本地代理磁盘上并在它们之间进行复制,而是将这项工作外包给了S3。虽然这种架构的延迟更高(速度更慢),但可以完全消除Kafka的网络成本。
这是一个极其重要的进展,因为一个优化良好的 Kafka 部署,其成本的 80% 都来自跨可用区网络。换句话说,每年 21.5 万美元的费用中,可能有 17.6 万美元用于网络。
此外,正是对延迟 敏感的工作负载导致了高网络带宽需求。换句话说,那些对延迟不敏感的工作负载反而会造成最高的网络成本。因此,通过这种架构,它们非常适合降低成本。
该架构在 2023/2024 年被限制在专有产品中,但在 2025 年,Aiven 开始将其发布到开源的 Apache Kafka 。

不仅如此,Aiven 还是首个在同一发行版中同时支持快主题和慢主题的发行版。此前,用户必须二选一,这阻碍了其普及,因为用户的工作负载必然是混合的。
一旦 Diskless 被接受并合并到开源项目中(预计在 2027 年左右)5据我猜测,精明的运营商将能够把 Kafka 网络成本降低97% !
4. 流处理并不赚钱
好吧,看来Kafka肯定不会成为未来营收增长的主要驱动力。那么,企业能否通过流处理来弥补这部分缺口呢?
不,绝对不是。
Confluent 在其整个发展历程中,始终未能实现流处理技术的显著盈利。
-
2016年左右:他们发布了Kafka Streams。他们试图通过推广事件驱动架构(EDA)来实现其商业化。
-
2020 年左右:他们尝试通过在其上添加 SQL 接口(使用 ksqlDB)来简化流处理。
-
2023 年左右:他们放弃了 ksql,收购了一家 Flink 初创公司,并全力投入 Flink。
-
2024 年左右:他们会大力推广 Flink用于人工智能代理(与微服务类似)。
-
2025年第三季度 :Flink的年度经常性收入约为11亿美元,但实际年度经常性收入仅约为1400万美元。6(1.25%)
虽然这对 Confluent 来说是灾难性的,但对该领域的其他流处理初创公司来说则更加残酷。
如果一家拥有庞大分销网络的公司汇聚了世界上最好的流处理专家7资本无法弄清楚如何正确地将流处理货币化------我不知道谁能做到。
以Responsive.dev为例,这家公司由 Confluent 的顶尖前人才创立并运营。8它是一家专注于 Kafka Streams 的精品创业公司,致力于提升流媒体应用的可靠性和可扩展性。但最近,它彻底转型,放弃了流媒体业务,转而专注于可观测性领域。

Response.dev 的主页
5. 所有实时流处理公司都很小
除了 Confluent 之外,还有哪些公司在提供实时服务?
-
🎯 Timeplus
-
🎯 RisingWave
-
🎯 Materialize
-
🎯 Deltastream
-
🎯 Ververica
-
🎯 Factor House
-
🎯 Conduktor
-
🎯 AutoMQ
-
🎯 StreamNative
-
🏃♂️ Redpanda(已于2025 年 10 月转型为 AI 代理)
-
💰 Arroyo(2025年4月收购)
-
💰 Decodable(2025年9月收购)
这些公司大多规模很小。
Redpanda是其中规模最大、历史最悠久的公司。他们知名度很高,赢得了众多开发者的青睐,并且正在向一个成熟的、价值数十亿美元的市场(Kafka)销售产品。
据传,Redpanda 运营 6 年后,到 2025 年其收入勉强超过 2000 万美元。
如果 Redpanda 无法在收入上真正赶上 Confluent 的 Kafka,而 Confluent 的流处理收入又能反映实时处理市场的规模------那么其他公司还有什么希望呢?
在我看来,这些公司有四种选择:
-
转向更大的市场并持续增长
-
获得
-
破产
选一个。
其中最引人注目、取得巨大成功的当属 WarpStream。
他们于 2023 年创立公司,并于 2024 年以 2.2 亿美元的价格被收购。Confluent 的恐慌加上 Warpstream 的技术、运气和市场定位,促成了整个流媒体行业都羡慕的成功退出。
这种情况不太可能再次发生。
6. 行业正在觉醒
人们正逐渐意识到流媒体已经达到瓶颈。他们要么失去了兴趣,要么开始寻求更简单的替代方案。如果你仔细听,就能感受到这一点:
收听会议
Current(前身为 Kafka Summit)似乎正在失去活力。以下几点可以说明问题:
-
Redpanda 被禁止参与。
-
伦敦会议(2025 年 5 月)有缩减的迹象。
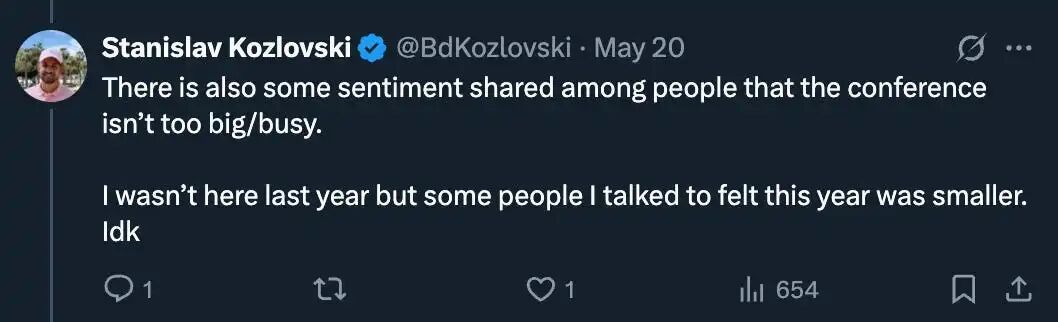
我跟一些人聊过,他们认为它的尺寸正在缩小。
- 在旗舰大会(2025年10月,新奥尔良)召开前26天, Confluent被发现在社交媒体上免费发放 门票。一张价值500-1000美元的门票,竟然在大会召开前整整一个月就开始免费发放。这说明了什么?

听听专家们怎么说
以下是两个人的想法,拥有数十年流处理和数据工程经验的------克里斯·里科米尼和瑞安·多兰:
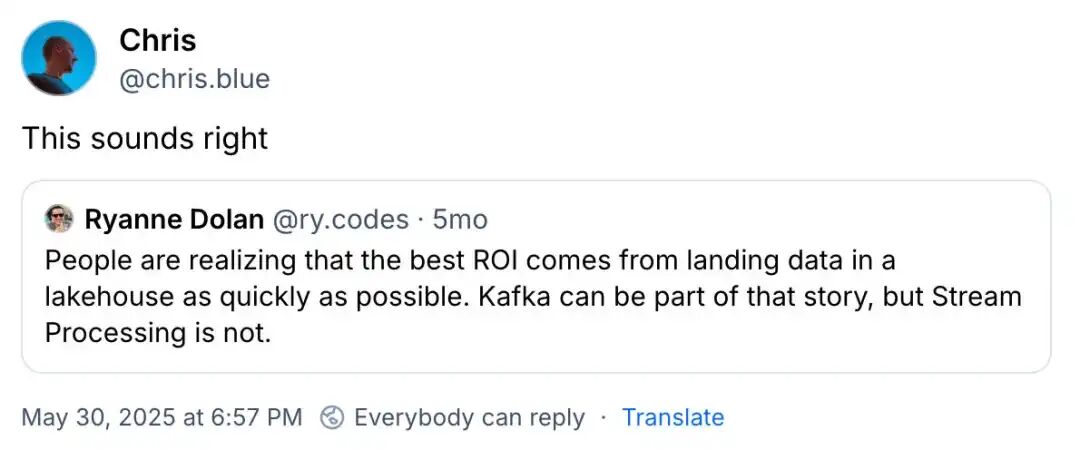
雅罗斯拉夫·特卡琴科
分享了他于2025年5月在伦敦举行的"当前伦敦"会议上的想法:
最后,我觉得数据流行业仍然处境艰难。增长缓慢,销售周期长。
我采访的一位人士表示,"展厅里 80% 的公司两年内都会倒闭"。
我不想相信他们,但这或许是真的。
(注意,他不是在跟我说话,哈哈)
在一篇题为"Kafka:终结的开始"的文章中,克里斯·里科米尼也引用了雅罗斯拉夫的那句话,表达了他对市场的总体看法:
我昨天也和人聊过,对方也说了类似的话:还是那些人,还是那些公司,还是那些技术。没有新想法,也没有新用户。
这个人说他以后不会再参加 Current 会议了;因为他没学到任何新东西。
Yaroslav 的帖子还提到 Redpanda 被禁止参加此次大会。如果属实,这很难不让人将其解读为资源匮乏和恐慌的迹象,而非资源丰富的象征。
我一直在思考这种停滞不前的状态 。我不认为我们已经解决了所有问题。例如,编写和部署流处理作业仍然非常困难;
我并不喜欢 Flink,但它在流处理领域确实胜出。不过*,厂商们心照不宣的是,真正的赢家其实是传统的 Kafka 消费者和生产者。***
倾听人民的声音
暂且这么说吧,在零利率政策(ZIRP)的余波过后,业界正在形成一股"简化"潮流。以下是一些例子:
-
Kafka 的 80% 问题------Aiven 最近承认,大多数 Kafka 工作负载都很小(< 10MB/s 甚至 < 1MB/s),而 Kafka 的开销对于这种规模较小的工作负载来说太高了。
-
Flink 的 95% 问题------Tinybird 指出,Flink 的设计过于复杂,无法解决其声称要解决的大多数用例。
看看我发的帖子得到的反响就知道了。
-
我最近发表的一篇文章声称Postgres 可以用于涵盖 Kafka 和队列的大多数用例,这篇文章迅速走红,获得了超过 6 万次的博客浏览量。
-
我引用这两篇80%/95%文章的推文也火了。
这一切都强烈表明,人们似乎正在逐渐达成共识,认为该行业相对于大多数用户的需求而言过于复杂。
我们为何会来到事件视界?
人总喜欢找人指责,这是人之常情。但我不会把这种业绩不佳归咎于任何一家公司的管理不善。
我不认为我们今天的处境是由于缺乏人才或战略失误造成的。
我认为市场根本不够大,容不下所有人。不管你多么聪明能干,要想卖掉人们不需要的东西,都是一场艰苦的战斗。

接下来是什么?
大范围的物资整合。是时候做好防护措施了。
据称,会议上有人说:"展厅里 80% 的公司两年内都会倒闭"。
我认为未来会有更多收购发生,目的是将这些产品与其他通用数据基础设施捆绑在一起。例如,据报道 Confluent 最近正在洽谈收购事宜。我相信这极有可能发生。
我认为收购 Decodable 和 Arroyo 也并非出于强势地位。我猜想这些收购是必要的------他们意识到独立发展并非制胜之道,而有人看到了将它们与自身产品捆绑销售的潜力。
对于那些尚未被出售的公司而言,转型很可能正在酝酿之中。
最近的一个很好的例子是 Redpanda 向 AI 代理转型。
Apache Kafka 呢?
Apache Kafka 本身不会消失,但管理它的公司却要消失了。
我看不出有什么真正的竞争对手能取代 Kafka。我看到的只是很多过度扩张、靠风投支持的公司,它们已经无法向投资者证明自身增长的合理性了。
开源 Kafka 将会继续存在,如果运气好的话,或许还能继续蓬勃发展。但 Confluent 被收购及其后续影响可能会在市场上留下巨大的空白,这确实存在风险。我认为目前还没有多少厂商能够填补这个理论上的空白。
或许是时候围绕 Kafka 打造一个更精简、更可持续的创业项目了?有兴趣的话请私信我。
我为什么要告诉你这些?
作为"Kafka迷",我最不应该对这个行业发表如此负面的看法。
但即便我自称是Kafka爱好者,也不意味着我必须推销我不认同的东西。我只是利用我的平台分享我认为的真理。
在某些商家试图诋毁我之前------我并非为了博取点击量而散布末日论调。我是真心实意地相信这一点。
我认为,对于那些没有深陷回音室效应、没有被"沉没成本"偏见所蒙蔽的人来说,这里所说的显而易见。如果你不同意------不妨设置个提醒,两年后再来读读这篇文章。
我做出这些预测并非出于虚荣心。事实上,如果我错了,我会更开心。我靠的正是这个日渐衰落的行业赚钱。
最后,我完全支持这个行业,不希望看到它消失。
我们越少互相欺骗,越早面对现实,就能越快渡过难关。
本文翻译自:https://bigdata.2minutestreaming.com/p/event-streaming-is-topping-out