一、问题
怎么讲MySQL表的自增主键更改为分布式ID?解决这个问题的核心在于上线时间段,会有两种id的生成方式。
为什么需要替换?数据同步的时候。假设A机房要迁移到B机房,两个机房都有流量。这里我们只讨论B机房是新机房,存量数据不会有冲突,只有增量数据才有冲突的情况。
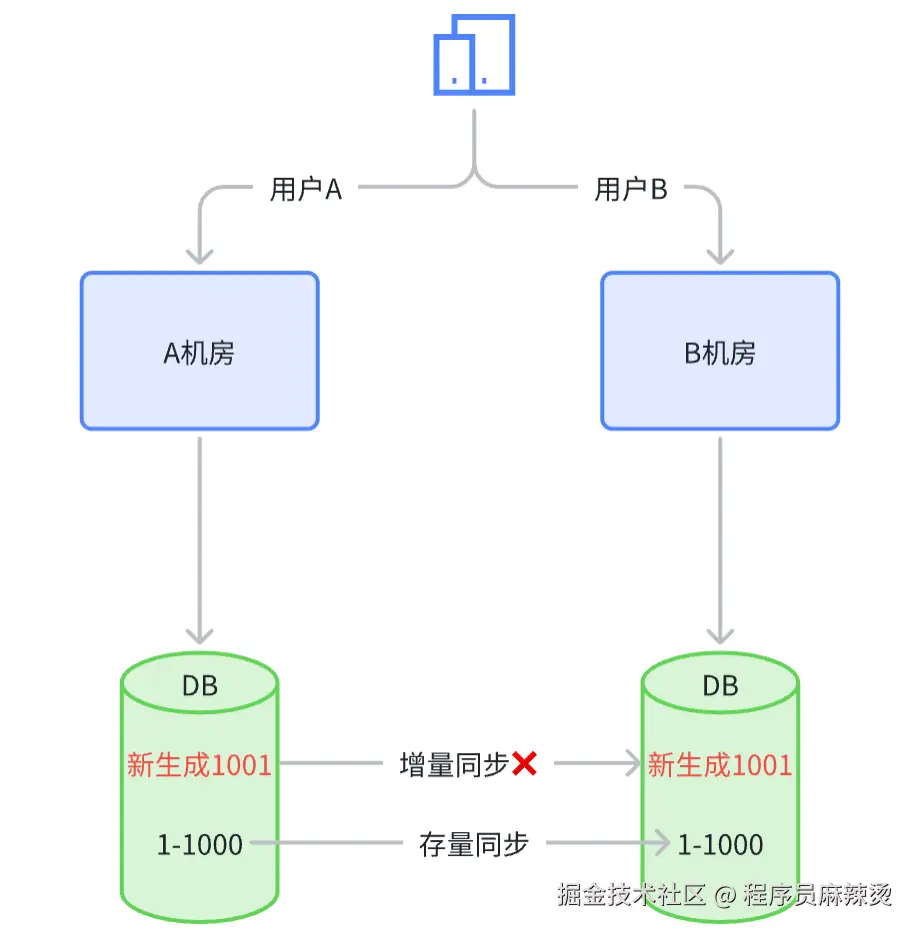
二、技术点
MySQL主键值的设置有不同的方案。
2.1MySQL自增主键
MySQL自增主键的核心逻辑是通过内存计数器分配唯一递增ID ,但不同版本在计数器持久化 和锁策略上存在关键差异,直接影响ID连续性和并发性能。
基础生成逻辑(各版本通用)
自增主键依赖表级内存计数器,分配规则如下:
- 自动分配 :插入时未指定ID/指定为
0/null,则用当前计数器值,分配后计数器+1(步长默认1,可通过auto_increment_increment调整)。 - 手动指定 :若指定ID>当前计数器,计数器更新为
ID+1;若ID≤计数器且未冲突,计数器不变。 - 不连续场景:事务回滚、唯一键冲突、批量插入失败会导致ID"浪费"(分配后未使用,不会回滚)。
版本差异核心对比
不同版本的关键区别集中在计数器持久化 和锁模式,直接影响重启后ID连续性和并发插入性能:
| 特性 | MySQL 5.7及更早 | MySQL 8.0及以后 |
|---|---|---|
| 计数器存储 | 仅内存,重启后重置为max(id)+1 |
持久化到redo log,重启后恢复原值 |
| 默认锁模式 | innodb_autoinc_lock_mode=1(连续模式) |
innodb_autoinc_lock_mode=2(交错模式) |
| 批量插入锁策略 | 表级锁(语句结束释放) | 轻量互斥锁(分配ID后立即释放) |
| ID连续性 | 批量插入保证连续,简单插入可能不连续 | 所有插入可能不连续,但并发性能最优 |
关键机制:锁模式
锁模式决定并发插入时ID的分配效率和连续性,各模式适用于不同场景:
| 锁模式值 | 名称 | 适用场景 | 并发性能 | ID连续性 |
|---|---|---|---|---|
| 0 | 传统模式 | 基于语句的复制(SBR) | 差 | 严格连续 |
| 1 | 连续模式 | 混合复制(默认,平衡性能) | 中 | 批量连续 |
| 2 | 交错模式 | 基于行的复制(RBR/GTID) | 优 | 不保证 |
2.2分布式ID生成方案
雪花算法
在分布式系统中,生成全局唯一且有序的ID是关键挑战。雪花算法(Snowflake)作为Twitter开源的经典方案,通过巧妙的位结构设计,平衡了唯一性、有序性和性能需求,成为分布式ID生成的事实标准。
核心原理:64位ID的精妙结构
雪花算法将64位长整型ID划分为4个部分,每部分承担特定职责:
| 位数 | 名称 | 作用 |
|---|---|---|
| 1位 | 符号位 | 固定为0(确保ID为正数) |
| 41位 | 时间戳 | 记录当前时间-起始时间的毫秒差,支持约69年(2^41/1000/365/24/60/60) |
| 10位 | 机器ID | 含5位数据中心ID+5位节点ID,支持最多1024台机器(2^10) |
| 12位 | 序列号 | 同一毫秒内自增,支持每节点每毫秒生成4096个ID(2^12) |
生成流程:
- 时间戳:以自定义起始时间(如2020-01-01)为基准,计算当前时间偏移量;
- 时钟回拨处理:若当前时间 < 上次生成时间,抛出异常或等待时钟同步;
- 序列号生成:同一毫秒内序列号自增,溢出则等待下一毫秒;
- 组合ID:通过位运算拼接时间戳、机器ID和序列号,生成64位整数。
核心优势:为何成为分布式首选?
-
全局唯一性:时间戳+机器ID+序列号的三重组合,确保分布式环境下ID无重复,即使多节点并发也不会冲突。
-
高性能与低延迟 :纯内存计算,无需数据库或中心节点,单机每秒可生成 400万+ ID(1000ms × 4096序列号),适合高并发场景(如秒杀、订单系统)。
-
趋势有序性:时间戳位于高位,ID天然按生成时间递增,适合作为数据库主键(减少索引碎片)或排序字段。
-
无中心依赖:去中心化设计,避免单点故障风险,支持集群横向扩展。
NT ID
公司自研的Non-Timestamp ID,非基于时间戳生成的全球唯一 ID。算是号段模式的一种,从数据库批量预分配ID段(如 [1001, 2000]),缓存在内存中逐个分配,用完后再申请新号段[4001,5000]。
三、方案
对于上面的具体场景,有两种方案可以选择:
| 方案1:仍然使用自增主键,不同机房使用不同的数据范围 | 方案2:使用NT ID | |
|---|---|---|
| 图示 | 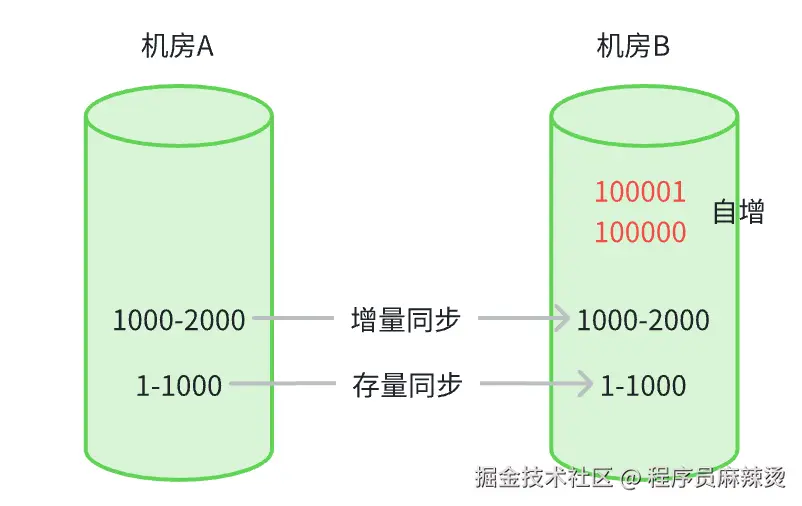 |
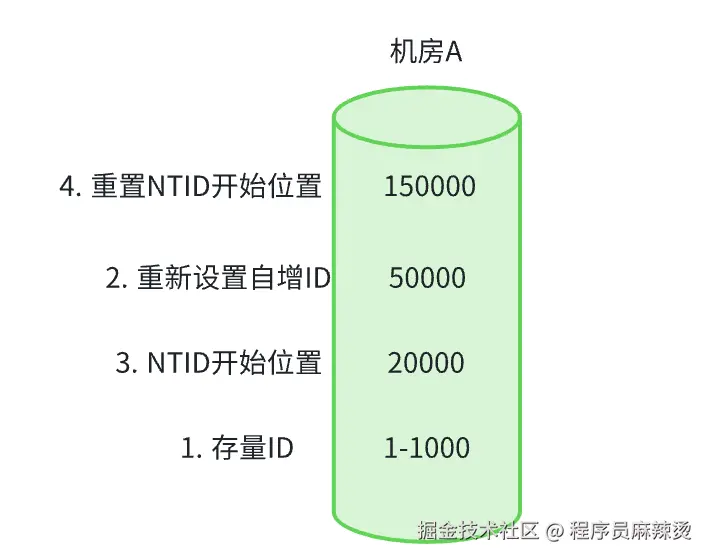 Q:为什么需要这么多操作? A:代码发布过程中,如果NTID生成的值有落库,自增主键会在此数值之上增加,可能和NTID生成的值有冲突 Q:为什么需要这么多操作? A:代码发布过程中,如果NTID生成的值有落库,自增主键会在此数值之上增加,可能和NTID生成的值有冲突 |
| 优点 | 1. 开发量:无需任何改造解决主键冲突问题,可在创建表或者通过ALTER TABLE 表名 AUTO_INCREMENT = 1000;修改自增主键值 | 1. 完美的支持双向同步 |
| 缺点 | 1. 同步方式:该方案只支持单向同步 2. 风险:需要确保A中的表自增主键不会迅速增长到B的值、确保A表中不会设置较大主键 3.全面性:除非A机房后续废弃不用,否则增量同步的数据终会出问题 | 1. 开发量:需要对表的创建操作设置主键值 2. 主键类型是不是bigint,防止越界 3. 通过接口提供的主键值,过长是否会有问题。如js对int64会丢失精度 |
最后
大家如果喜欢我的文章,可以关注我的公众号(程序员麻辣烫)
我的个人博客为:shidawuhen.github.io/
往期文章回顾: