🎙️ 前言
python是一门迷惑性很强的编程语言。
在刚开始接触的时候, 大学期间让人头疼的编程语言突然从面目狰狞的C变成了python。直接无痛入门。
从头到尾敲完一本《python编程-从入门到实践》, 总觉着自己牛逼坏了, 这不全都掌握了, 小小python一举拿下。
后面再去接触爬虫, 一整个大傻眼。这都啥? 大脑一片空白。😣
再回头重新反思自己的学习道路, 发现很大的缺陷就在于一直都是按照书本上或者是视频上的案例在誊抄代码, 并没有形成自己的编程思维; 以及底层的数据结构仍然是不了解状态。尤其是当ai工具出现之后, 本身就站立不住的腿多了这条拐杖, 更是拿走后一步都走不远。
已经拿到了python这把利器, 却无法充分发挥它的效用, 通过自己的尝试去落地有趣好玩的项目, 实在是件蛮遗憾的事情。
抛弃掉自己的自负, 踏踏实实回头重新梳理基础。不仅仅是被动接收, 而是理解为什么要这么设计? 需求可以用这种方式实现, 换种方式可不可以? 更新的版本中有没有提供更好用的模块, 从而避免自己重复造轮子?
为此我重新梳理了自己的学习笔记, 希望不仅仅是对我, 还是对像我一样仍然困在半路的苦行者, 能有一点点帮助。
🗂️ 存储管理系统
程序中直接使用的数据保存在计算机的内存储器(简称内存 )中, 内存可以通过CPU直接访问 。暂时不使用的数据存储在外存储器(磁盘、光盘等, 简称外存)中, 如果想要读取外存中的数据, 需要先装入内存, 然后CPU才能正常使用。
内存存储的结构是线性的, 每个单元的大小相同, 可以保存一个单位大小的数据。
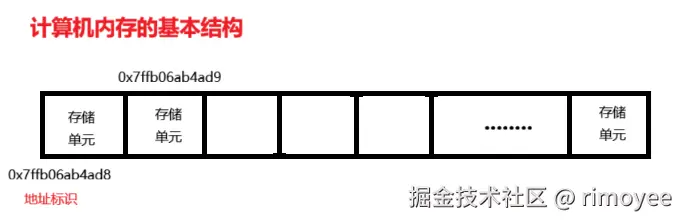
为了方便访问, 每个存储单元都有一个地址(数据标识), 在程序执行时, 直接找到地址就可以读取存储的数据内容。 同时, 程序在运行时会处理各种各样的数据, 如果数据存储在相邻的一块或者几块区域, 访问就会很方便。 内存中的存储单元是有限的, 所以要做到合理的分配和利用。
python提供存储管理系统来负责数据的存储和管理工作, 不需要像C和C++一样, 手动分配和回收内存, 大大提升了编写代码的便捷性。
同时python作为面向对象 的语言, 将数据和操作数据的方法都封装在对象中, 通过和对象的交互来完成任务。 在程序运行的过程中, 不断建立对象并使用它们, 创建的每个对象都有一个确定的唯一标识(即地址), 用于识别和使用这个对象。在一个对象的存续期间, 地址是保持不变的。
如何去查看对象在程序运行时的地址标识?
通过内置函数id()
python
a = 10
print(hex(id(a))) # 通过hex()将地址转化为十六进制, 方便观看
# 0x7ffb06ab4ad8 同时可以也通过is和is not关键字来判断是否是同一个对象, 这种方法就是通过对比地址来判断的
python
a = 10
b = 10
c = 20
print(a is b) # True
print(a is c) # False
print(b is not c) # True上面的代码有个很有意思的现象, 会发现定义的变量a和变量b是一个对象, 即内存中存储的地址是一个。
为什么会这样?
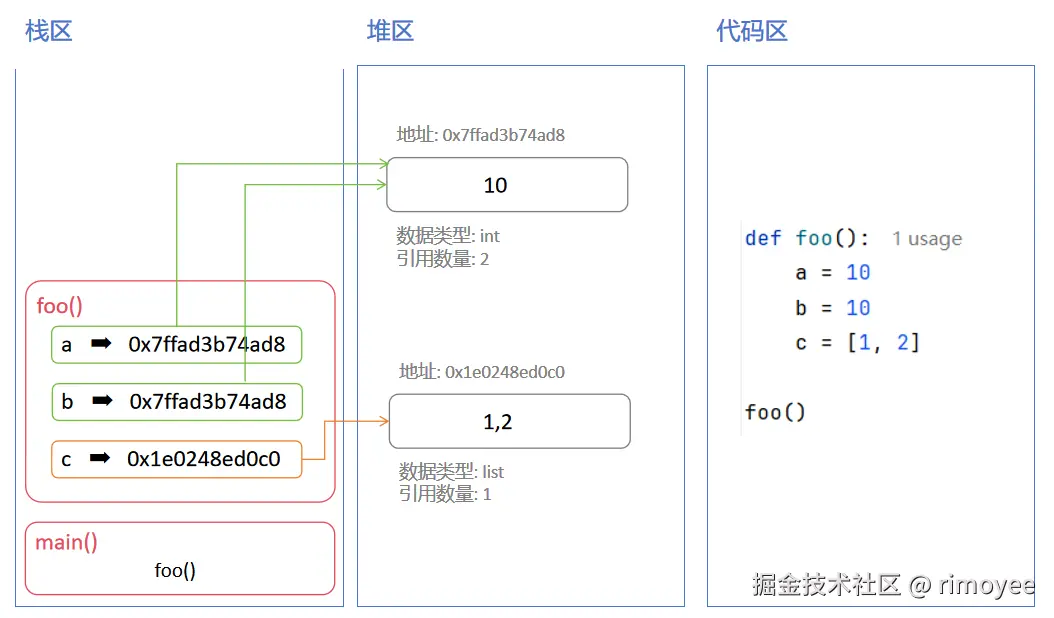
这就涉及到了内存中数据的存储方式。内存中, 包含有三个区域: 代码区、栈区和堆区。
(1) 代码区: 存储编写的代码
(2) 栈区: 存储变量名和地址, 以及函数调用相关信息, 遵循LIFO(先进后出)原则, 存储小型、临时数据
(3) 堆区: 存储真正的变量数据, 无序存储, 生命周期较长, 存储复杂或大型数据
下面先通过栈与堆的存储机制来了解这三个区域都是如何工作的。
🛒 栈与堆的存储
上面我们提到, 内存中存储了大量的数据和操作方法, 均封装在对象中, 可以称之为数据对象。这些数据对象被存储在容器中, 容器支持对这些数据存储、管理和使用。
栈和队列都是保存数据元素的容器 , 是计算中最广泛的缓存结构。主要用于在计算过程中保存临时数据, 这些数据都是在计算中发现或者产生的, 在后面的计算中可能使用它们。
在栈区主要使用栈来操作数据, 下面先来介绍一下栈的机制。
🤔 栈是什么?
栈是限制在一端进行插入操作和删除操作的线性表, 允许进行操作的一端称为"栈顶", 另一固定端称为"栈底", 当栈中没有元素时称为"空栈"。栈内元素遵循LIFO(先进后出)的原则。
栈的机制如下图所示: s1 = (a1,a2,...,an)
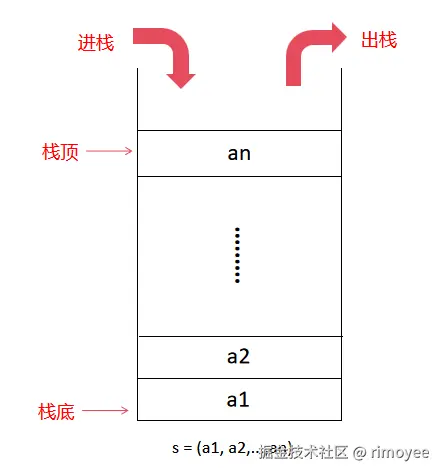
栈的抽象数据类型(预定义的操作):
- 栈的创建 (创建一个空栈)
- 判断栈是否为空
- 将元素压入栈中 (也称进栈或入栈)
- 从栈中弹出元素并将其返回 (也称退栈或出栈)
- 检查栈元素 (访问最后入栈元素)
python中的栈机制
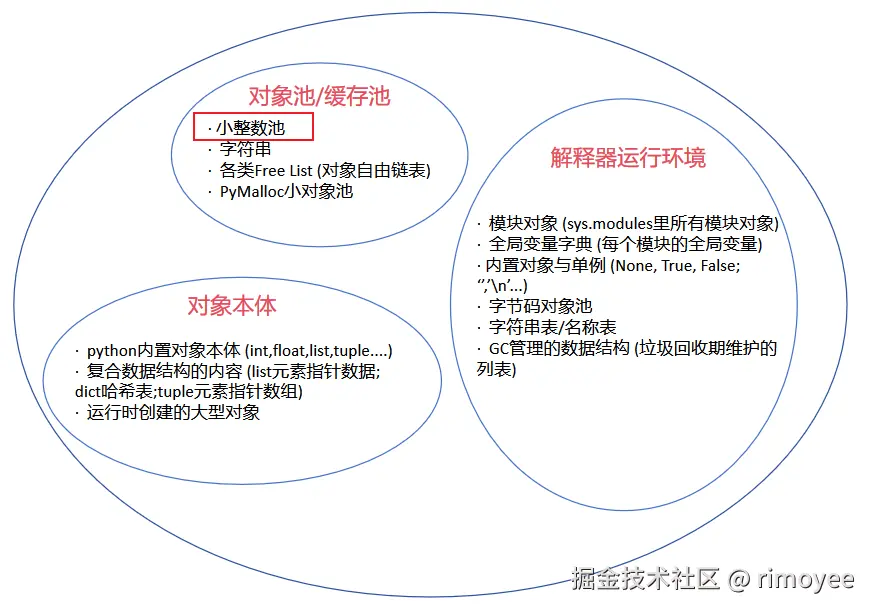
三个区域的存储情况如下图所示
栈区中存储的是对象的引用(指针),也就是说存储的并不是数据, 真正的数据存储在堆区中。
🤔 堆是什么?
上面说到, 栈本质上是一种线性表, 而python中的 "堆", 并不是一种固定的数据结构, 而是解释器向操作系统申请的动态内存区域, 由python的内存管理器在这个区域内进行灵活分配。
在区域的内部, python使用pymalloc分配器进行管理。
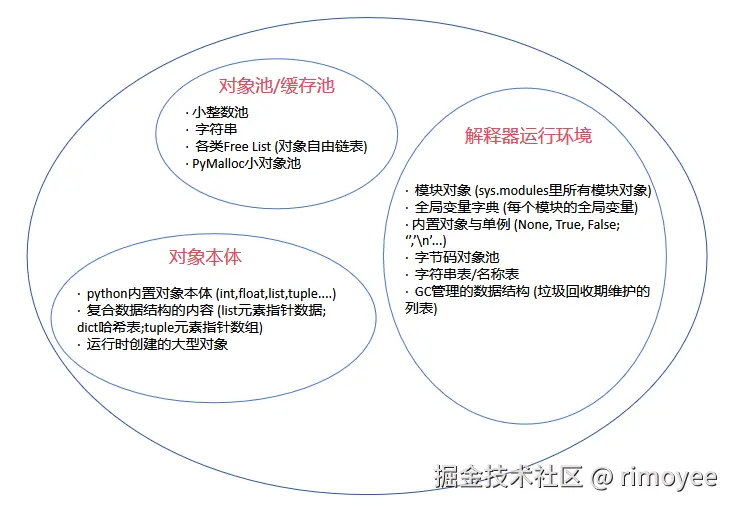
下面是堆区总体结构图:
🗑️ 垃圾回收机制
内存空间是有限的, 既然有存储, 就必然有回收。
python使用引用计数 作为主要机制, 辅以标记-清除 和分代回收来处理循环应用问题。
引用计数
如下图所示, 在堆区中, 每个对象都包含一个引用计数, 用于统计当前对象被引用的次数。当引用计数为0时, 该对象被垃圾回收机制回收。

可以通过sys.getrefcount()方法来查看引用计数的数量
📍 Note: 需要在python交互式解释器下执行, 在其他环境下, 会做优化处理, 导致结果不符
python
>>> import sys
>>> x = 532
>>> y = x
>>> sys.getrefcount(x)
3🎃 一个有趣的尝试
定义变量a和b, 并存储到变量c中, 查看各个变量的引用计数
ini
>>> a = 10
>>> b = 20
>>> c = [a,b]
>>> sys.getrefcount(a)
4294967295
>>> sys.getrefcount(b)
4294967295
>>> sys.getrefcount(c)
2在上面的代码中, 会发现a和b的计数数值尤其大。按道理来说不应该a和b的应用计数都是1吗?
🔍 原因分析
小整数对象(通常在-5~256)会被缓存和复用, 这些缓存对象的应用计数机制被优化掉了, 当sys.getrefcount()检测到这种情况时, 会返回一个特殊值。
在堆区总体结构图中, 可以看到在对象池/缓存池中, 有小整数池。常用的小整数对象存储在这里, 避免频繁创建和销毁, 减少了内存分配的开销。
🔎 相同对象判断 == 与 is
在 ⌈存储管理系统⌋ 的章节中, 我们了解到可以使用is关键字来判断是否是同一个对象。
同时, 我们也可以通过==运算符来判断两者的值是否相同, 那么在使用的时候, 这两者有什么需要注意的吗?
python
# 定义三个变量, 这三个变量的值是一样的
s1 = "helloworld"
s2 = "hello" + "world"
s3 = "".join(['hello', 'world'])
print(s1, s2, s3) # helloworld
# 看一下这些对象的地址
print(hex(id(s1))) # 0x2f489ed91f0
print(hex(id(s2))) # 0x2f489ed91f0
print(hex(id(s3))) # 0x2f489fa3570查看地址后发现, s1和s2的地址是一样的, 但是s3的地址却不同。
我们分别使用==和is来判断这些变量
python
print(s1 == s2) # True
print(s1 == s3) # True
print(s1 is s2) # True
print(s1 is s3) # False🙋 通过上面的案例, 我产生了下面的疑问:
❓ 问题1: 为什么s3和s1与s2的地址不同?
❓ 问题2: ==和is的底层判断机制是怎样的? 为什么会有不一样的返回结果?
💡 字符串驻留机制
python的一种优化技术, 它保存不可变对象(如字符串)的唯一副本, 当需要时, 让多个应用指向这个副本, 以节省内存。
但并不是所有的字符串都会被驻留, 字符串的创建方式会影响它们是否被驻留(Interned)。
自动驻留的规则:
- 编译时常量: 在代码编译时就能确定的字符串字面量
- 短字符串: 通常只包含字母、数字、下划线的短字符串
- 标识符: 变量名、函数名等
🙋 如果在定义字符串变量的时候加入空格会怎么样?
python
>>> s1 = "hello world"
>>> s2 = "hello" + " " + "world"
>>> s1 is s2
False在python交互式解释器中查看, 可以看到因为包含有空格, 定义的对象并没有被驻留, 所以s1和s2并不是同一个对象。
⬆️ 解答问题1
了解上面的知识点之后, 再去分析上面的代码
(1) s1是一个字符串字面量, 在编译时被创建, 会被驻留
(2) s2作为表达式, 在编译时会被优化成字符串字面量, 因此和s1是同一个对象
(3) s3是在运行时通过join方法动态创建的字符串, 无法在编译时确定结果, 因此并不会被驻留优化, 是一个新的字符串对象
通过上面的分析, 我们就了解了为什么会有值相同但地址不同的现象。
⬆️ 解答问题2
调用==来比对两个变量的值时, 调用对象的__eq__()方法(继承自object), 如下图所示

而上面的案例中, 两个变量的类型是字符串, str()方法会重写继承的__eq__()方法, 使得判断的时候比较的是两者的值, 而不是地址。
而调用is比较两个变量时, 比较的就是两者的地址是否相同。
📍 Tips: 内存中存储的常量, 如True, False, None, 判断的时候直接使用is关键字, 不要用==。因为这些常量在内存中的存储地址只有一个, 通过is去判断地址即可。