背景
很多客户已经建有 Prometheus/Zabbix 等采集方式,通常不会贸然替换 DataKit 进行直采,往往是通过 DataKit 去获取其它工具采集的结果。如 Prometheus remote write,Zabbix export 等。
为了增加不同数据类型的关联性,需要对已有的指标数据添加更多业务 TAG,如应用名,所属项目,部门等。为实现此类需求,需要能够获得原始的相关配置信息,如 CMDB 数据等。然后通过观测云 Pipeline 中的 refere_table() 方法实现关联数据并添加 TAG。
本文档基于客户方实际案例,介绍如何使用 reference table,以及在使用过程中的注意事项。
更多关于 refer_table 用法参考官网文档 Reference Table 。
观测云
观测云是一款专为 IT 工程师打造的全链路可观测产品,它集成了基础设施监控、应用程序性能监控和日志管理,为整个技术栈提供实时可观察性。这款产品能够帮助工程师全面了解端到端的用户体验追踪,了解应用内函数的每一次调用,以及全面监控云时代的基础设施。此外,观测云还具备快速发现系统安全风险的能力,为数字化时代提供安全保障。
实现原理
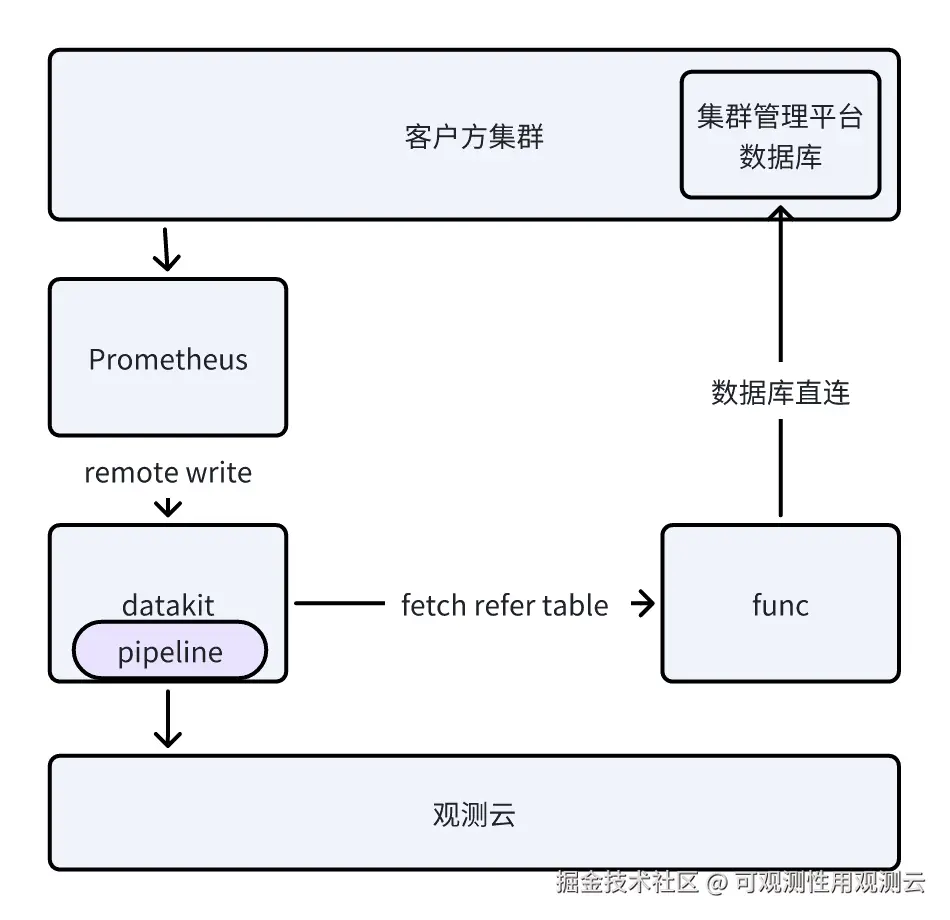
实践步骤
1. 新建 Func 脚本
python
# 创建两个方法,一个用于pipeline获取json数据(get_reference_table),一个用于获取json数据并放入redis中。这样可以减少对原业务系统数据库的访问压力。
@DFF.API('获取reference table')
def get_reference_table():
# 从redis中获取已缓存的数据
earth = json.loads(DFF.CACHE.get('refer_tab_earth'))
return [earth]
# 此处的earth平台是客户方集群管理系统。
# 此案例中需根据Prometheus中的字段关联project,app信息。
# 分页获取原始数据,组装reference table要求的数据结构,并将结果放入redis
@DFF.API('缓存earth映射表')
def get_earth_table():
db = DFF.CONN('mysql_earth')
# get project data
project_dict = {o['id']: o for o in db.query('select id,name,cmdb_app_id,cmdb_app from project')}
service_count = db.query('select count(1) count from service')[0]['count']
offset = 0
rows =[]
while offset < service_count:
rslt = db.query(f'select a.id service_id, a.name service_name, b.project_id from service a left join application b on a.application_id = b.id limit {offset},1000')
for o in rslt:
p = project_dict[o['project_id']]
cmdb_app = json.loads(p['cmdb_app'])['name'] if p['cmdb_app'] else ''
row = [f"service-{o['service_id']}", f"project-{p['id']}", o['service_name'], p['name'], p['cmdb_app_id'], cmdb_app]
rows.append(row)
offset += len(rslt)
data = {
'table_name': 'earth',
'column_name': ['earth_service', 'earth_project', 'service_name', 'project_name', 'appId', 'appName'],
'column_type': ['string', 'string', 'string', 'string', 'string', 'string'],
'row_data': rows
}
DFF.CACHE.set('refer_tab_earth', json.dumps(data))2. 创建 Func 同步链接
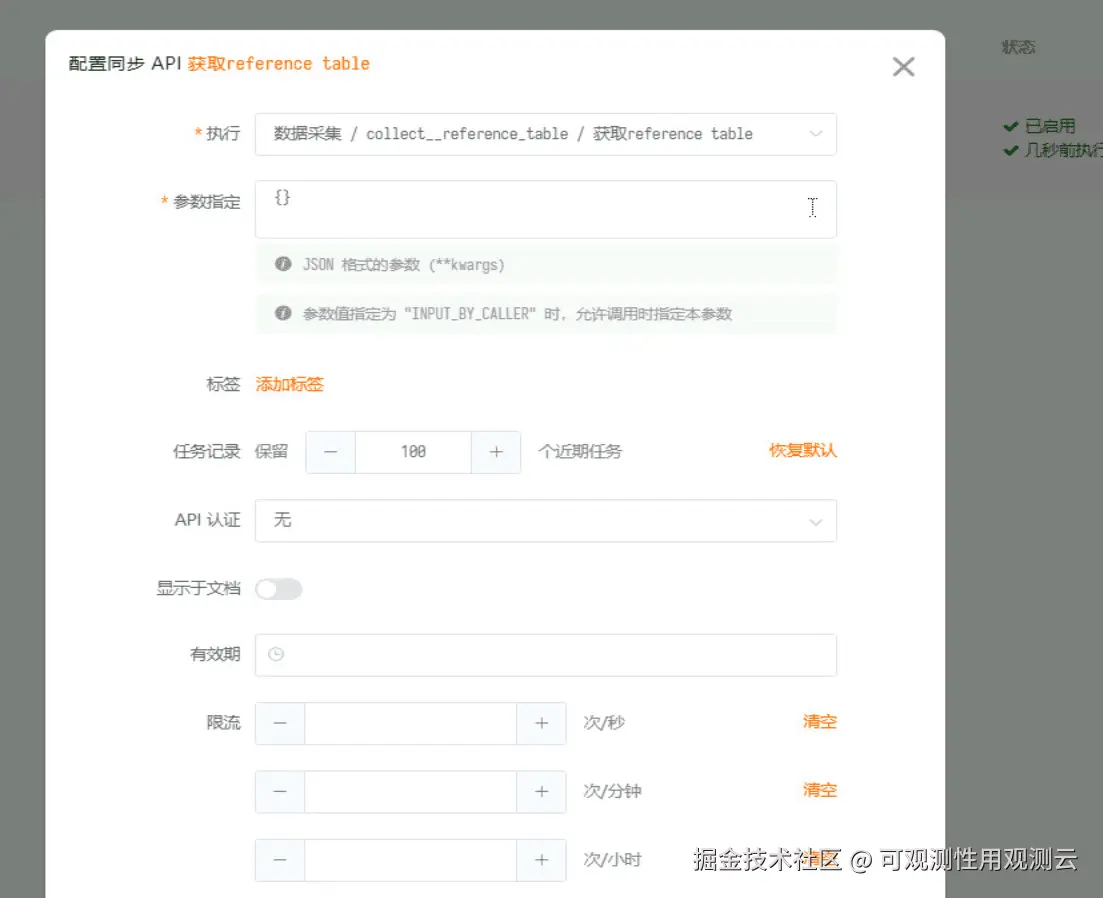
3. 配置 Pipeline 获取 Reference Table 地址
编辑 DataKit 的主配置文件 datakit.conf,配置 Pipeline 下的 refer_table_url 为上一步创建的同步 API 链接。

4. 创建 Pipeline
通过观测云管理菜单下面的 Pipeline 菜单进入 Pipeline 菜单管理页面(因为是需要对指标数据进行 Pipeline 处理,只能通过该菜单进入才能创建处理指标的 Pipeline),并创建一个新的 Pipeline。
配置 Pipeline 名称以及合适的过滤条件(由于本案例是用单独的 DataKit 采集 prom 指标,故无过滤条件)。
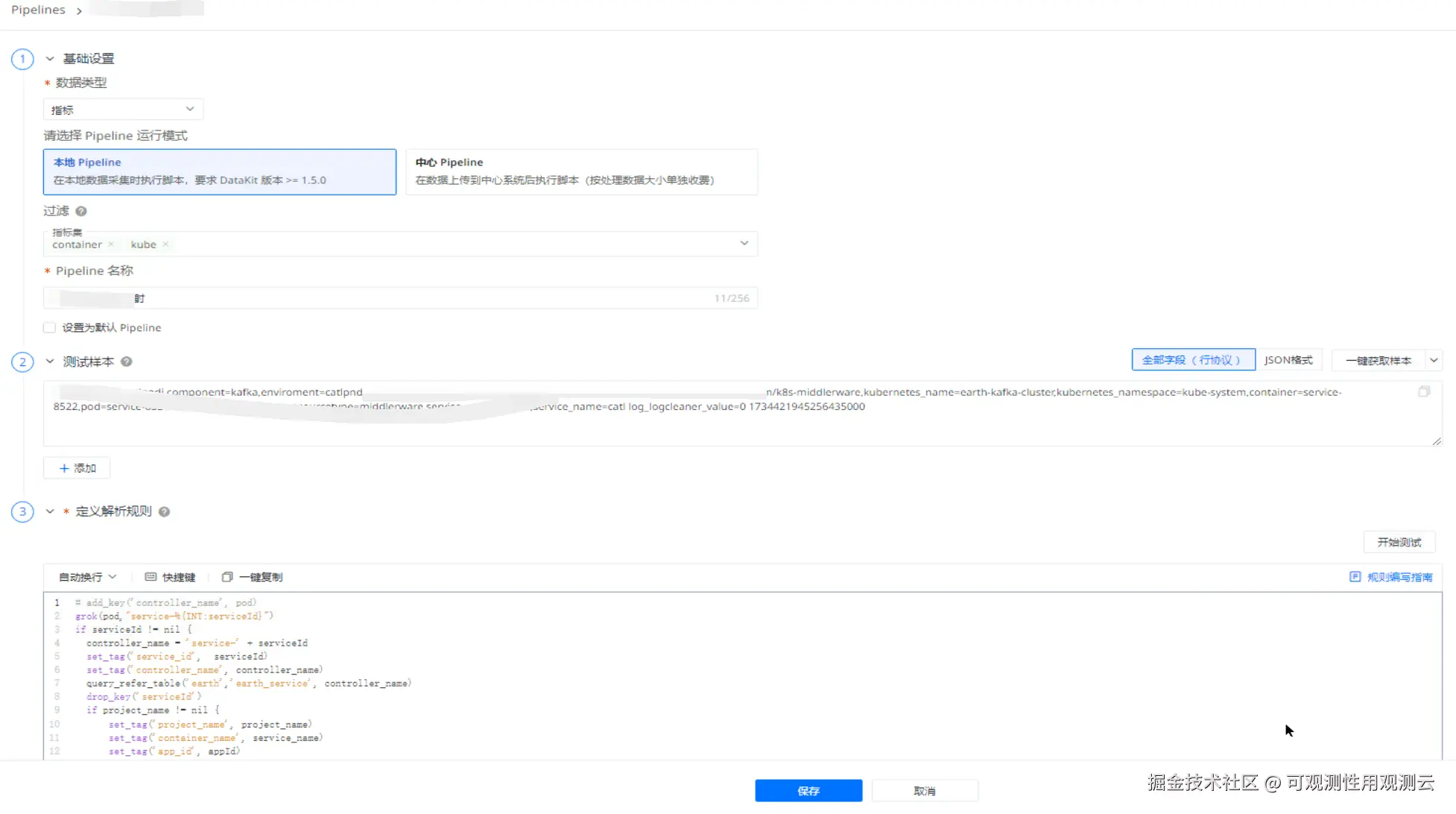
编辑 Pipeline 脚本并保存。
scss
grok(pod,"service-%{INT:serviceId}")
controller_name = 'service-' + serviceId
set_tag('service_id', serviceId)
set_tag('controller_name', controller_name)
# 从reference table中获取earth_service 为controller_name的数据
query_refer_table('earth','earth_service', controller_name)
drop_key('serviceId')
if project_name != nil {
set_tag('project_name', project_name)
set_tag('container_name', service_name)
set_tag('app_id', appId)
set_tag('app_name', appName)
k = slice_string(pod, len(container), len(pod))
k = service_name + k
set_tag('pod_name',k)
}5. 验证结果
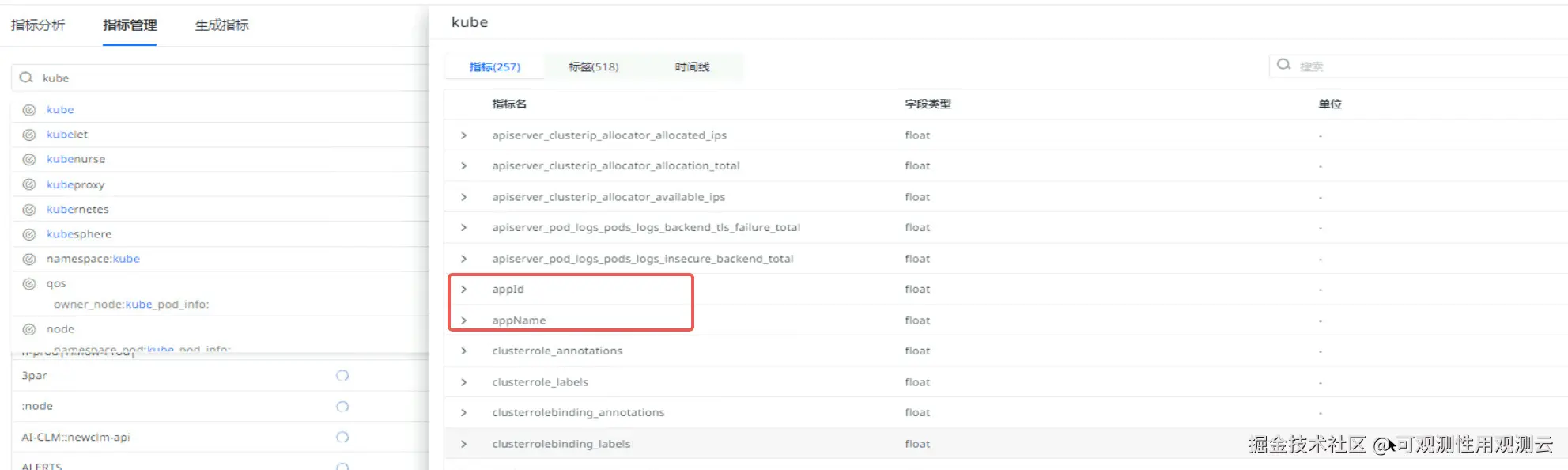
注意事项
- 如若使用中心 Pipeline,请确保中心 Pipeline 功能已开启(默认关闭);
- 如果使用本地 Pipeline,请确保每个涉及到该类数据采集的 DataKit 实例都有正确配置refere table url;
- 编辑 Pipeline 时,如果页面提示解析失败,可以忽略,因为页面调试使用的是中心 Pipeline,如果中心 Pipeline 没有配置 refer table 获取地址的话,会报错;
- JSON 文件会被加载到内存中,注意 table 大小。