【Github热门项目】DeepSeek-OCR项目上线即突破7k+星!突破10倍无损压缩,重新定义文本-视觉信息处理
当"8000行代码手搓ChatGPT"的热度还未褪去,大模型领域又迎来新惊喜------DeepSeek团队于10月20日开源的 DeepSeek-OCR ,以"上下文光学压缩"为核心突破,重新定义了OCR(光学字符识别)的效率边界。这款仅30亿参数量的模型,不仅能以100个视觉token超越传统模型256个token的性能,更在单张A100-40G显卡上实现每日20万页文档处理能力,为长文本压缩与大模型效率优化提供了全新思路。
论文标题:DeepSeek-OCR:ContextsOpticalCompression
DeepSeek-OCR的核心创新在于利用视觉模态作为文本信息的高效压缩媒介。研究表明,一张包含文档文本的图像可以用比等效文本少得多的Token来表示丰富信息,这意味着通过视觉Token进行光学压缩可以实现极高的压缩率。
其核心表现可概括为两组关键数据:
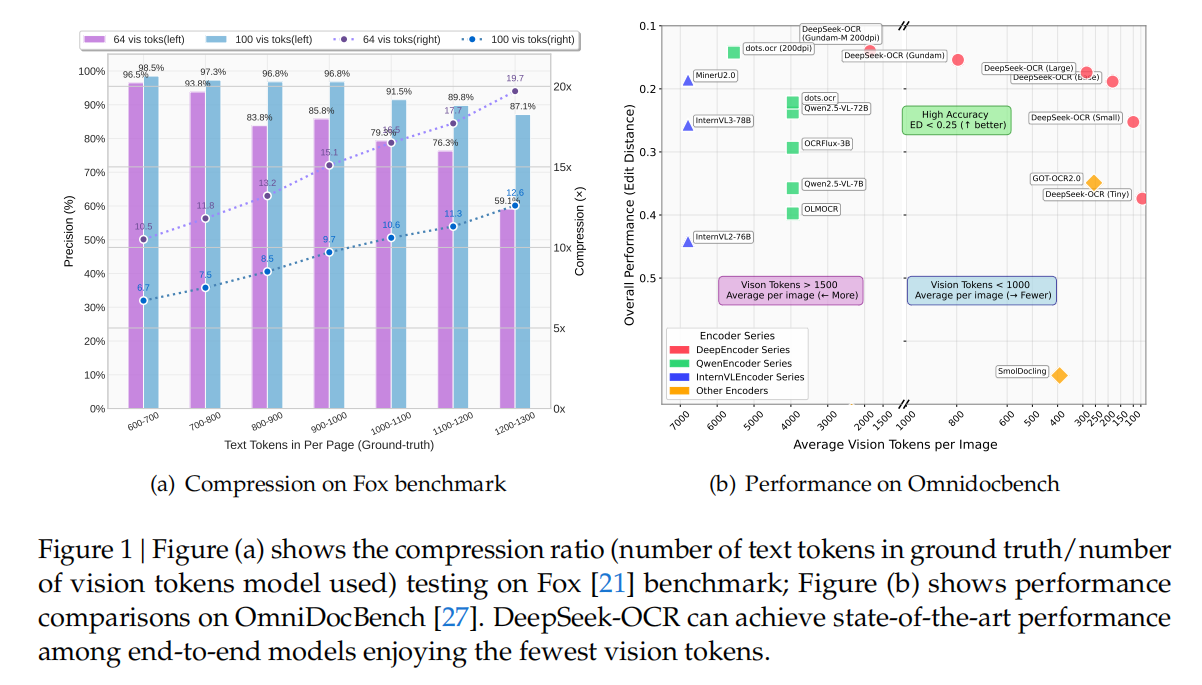
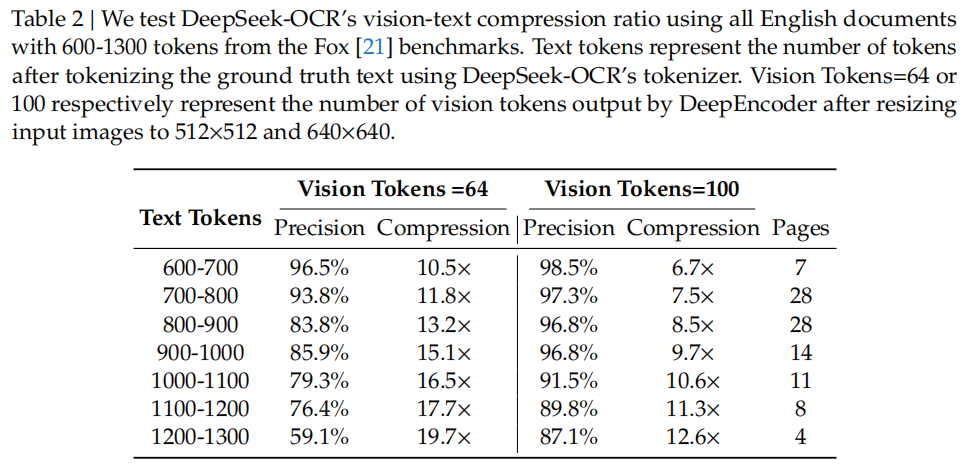
- 压缩比与精度的平衡:当文本token数量是视觉token的10倍以内(即压缩比<10×)时,OCR解码精度高达97%;即便压缩比提升至20×,精度仍能维持在60%左右,远超行业同类模型的衰减速度。
- 极致的token效率:在OmniDocBench基准测试中,它仅用100个视觉token就超越了需256个token的GOT-OCR2.0;面对MinerU2.0平均每页6000+token的消耗,它用不到800个token就能实现更优性能------相当于将文本处理的"token成本"降低了7-20倍。
这种突破的价值不仅在于OCR本身:对于受限于"长上下文处理能力"的大模型而言,DeepSeek-OCR提供了一种新解法------将超长文本转化为视觉图像后压缩输入,可大幅减少LLM的token消耗,为处理百万字级文档、历史上下文记忆等场景打开了通道。
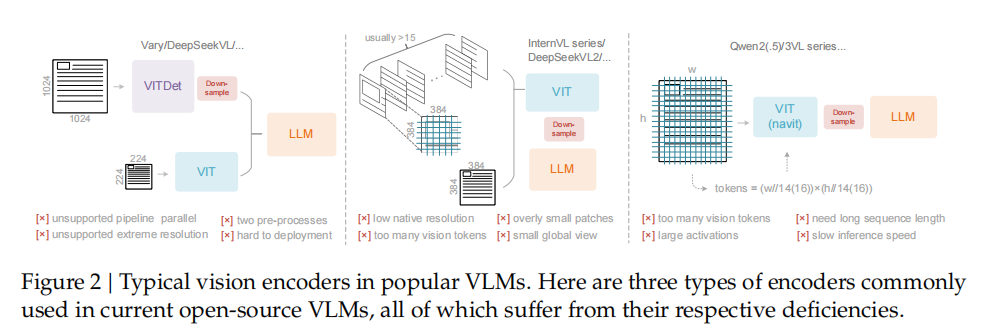
DeepEncoder:编码器+MoE解码器
为实现"高压缩比、低资源消耗"的目标,DeepSeek-OCR采用了"DeepEncoder(编码器)+DeepSeek3B-MoE(解码器)"的端到端架构,两者各司其职又高度协同。
1. DeepEncoder
作为模型的"压缩核心",DeepEncoder需同时满足"高分辨率处理、低激活开销、少token输出"三大需求,其架构设计暗藏巧思:
- 双组件串联:由8000万参数的**SAM-base(视觉感知)和3亿参数的CLIP-large(视觉知识)**串联而成。SAM-base用"窗口注意力"处理高分辨率图像细节,CLIP-large用"全局注意力"提取语义关联,兼顾精度与全局理解。
- 16倍token压缩:在双组件之间,通过2层卷积模块对视觉token进行16倍下采样。例如,1024×1024的图像先被划分为4096个patchtoken,经压缩后仅保留256个有效token,既控制了内存消耗,又不丢失关键信息。
- 多分辨率适配:支持Tiny(512×512)、Small(640×640)、Base(1024×1024)、Large(1280×1280)四种原生分辨率。还能通过"Gundam模式"实现超高分辨率输入(如报纸图像)的瓦片化处理,单个模型即可覆盖从手机截图到大幅文档的全场景需求。
2. DeepSeek3B-MoE
解码器采用混合专家(MoE)架构,在"性能与效率"间找到了平衡点:
- 参数激活策略:虽然总参数量为3B,但推理时仅激活64个"路由专家"中的6个,外加2个"共享专家",实际参与计算的参数仅5.7亿------相当于用"500M模型的资源消耗",获得了3B模型的表达能力。
- 快速文本重建:从DeepEncoder输出的压缩视觉token中,解码器能精准重建原始文本,甚至支持markdown格式转换、图表结构化提取等复杂任务,无需额外的后处理模块。
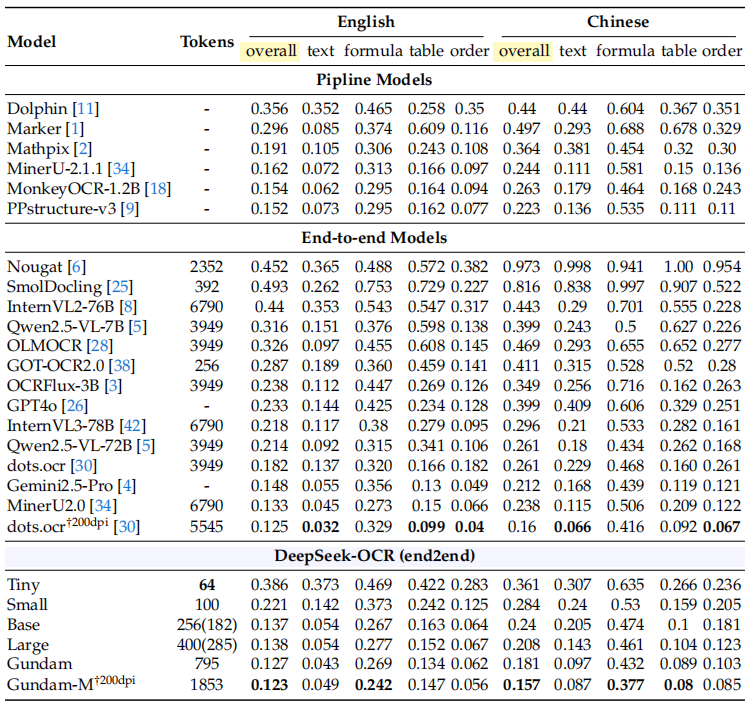
性能表现
实验数据令人印象深刻:当文本Token数量在视觉Token的10倍以内(压缩率<10×)时,模型的解码精度可达97%;即使在压缩率达到20×的情况下,OCR准确率仍保持在约60%。
在实际应用层面,DeepSeek-OCR展现出惊人效率:在OmniDocBench基准测试中,仅使用100个视觉Token就超过了GOT-OCR2.0 (每页256个Token)的表现;使用不到800个视觉Token就优于MinerU2.0(平均每页超过6000个Token)。
大模型实验室Lab4AI
值得一提的是,大模型技术社区「大模型实验室Lab4AI」已经第一时间上架了 DeepSeek-OCR论文及相关技术资料 。该社区的技术团队正在积极复现论文中的创新方法,验证其在实际场景中的表现。大模型实验室作为专注于AI前沿技术的内容社区,将持续跟踪DeepSeek-OCR的最新进展,并分享更多实践案例和技术分析。欢迎各位开发者关注社区动态,共同探索这一创新技术的更多应用可能。