Super-step 是 LangGraph 的执行单位 ------ 一个"同步的批处理轮次"。在每个 super-step 中,框架会并行/批量地运行当前所有可执行节点,收集它们的写入(updates),用事先定义好的 reducer 把写入合并成一个新的全局状态(snapshot),然后进入下一个 super-step。每个 super-step 结束都会形成一个 checkpoint(快照),用于持久化、恢复、回放与时间旅行。
下面把这个概念从高层到细节、从设计思想到工程实现,系统讲清楚------包括为什么要这样做、底层如何实现、并发模型如何介入、与 checkpoint 的关系、常见用法与调试技巧等。
1. 概念速览(一句话)
super-step = 一轮并行执行 + 收集所有节点写入 + 用 reducer 原子合并到全局状态 + 生成 checkpoint。 它来源于 Pregel / BSP(Bulk Synchronous Parallel)模型,是 LangGraph 的核心执行语义。
2. 为什么用 super-step(设计动机)
- 一致性:在同一轮次内所有节点看到的状态相同(读时点一致,Read-time Consistency),写入合并时统一处理,避免交叉依赖导致的不确定性。
- 可恢复 / 可回放:每轮结束即 checkpoint,便于恢复、时间旅行、human-in-the-loop。
- 并行表达力:多个逻辑上独立的节点可以在同一轮次中并发执行,适合并行任务与 agent 协作场景。
- 明确的合并语义:通过 reducer(或默认覆盖规则)定义如何把多个节点的写入合并为一个状态,便于设计累积型字段(例如列表累加)。
3. super-step 的执行流程(分步骤详解)
-
发现 active nodes
- 根据当前 state、图结构以及上次合并结果决定哪些节点在本轮可执行(runnable / active)。
-
执行 active nodes(并发或串行)
- 执行函数/节点体,得到每个节点的输出(通常包含
update字段,和goto/ control 指令)。 - 节点输出先写入临时缓冲区(不会立即改变全局 state)。
- 执行函数/节点体,得到每个节点的输出(通常包含
-
收集所有 writes
- 汇总所有节点的
update(状态写入)。
- 汇总所有节点的
-
对每个字段执行 reducer 合并
- 如果字段被 Annotated 指定了合并策略(例如
add),就用该策略合并;否则按默认规则(通常覆盖)。
- 如果字段被 Annotated 指定了合并策略(例如
-
生成新的 state snapshot(StateSnapshot)
- 包含
values(合并后状态)、next(下轮要执行的节点)、metadata、tasks等。
- 包含
-
持久化 checkpoint(checkpointer)
- 把 snapshot 写入保存器(InMemory/SQLite/Postgres 等),用于恢复与回放。
-
循环或结束
- 如果还有可执行节点,继续下一轮 super-step,否则图执行结束。
4. 底层实现:调度器、并发、同步(关键点与伪代码)
关键点:super-step 是调度模型,不是并发模型。 调度器负责分阶段执行与合并,但是否并发取决于节点本身或运行时选择。
伪代码(高度概括):
python
state = initial_state
while not finished(state):
active_nodes = discover_active_nodes(state)
# 1) 并发执行或串行执行 active nodes 的 node.run
results = parallel_map(execute_node, active_nodes) # 可以是并行,也可以是同步
# 2) 收集所有 writes
all_writes = collect_writes(results)
# 3) 按字段 reducer 合并成 new_state
new_state = reduce_state(state, all_writes)
# 4) 生成并持久化 checkpoint
checkpointer.save(snapshot=new_state, metadata=...)
state = new_state说明:
parallel_map可以用asyncio.gather(若节点为 async)或ThreadPoolExecutor(若你希望线程并发),也可以是普通 for-loop(单线程)。框架本身并不强制创建线程。reduce_state是原子操作:基于每个字段的合并策略(Annotated metadata),把所有写入合并成一份一致状态。
5. state 合并(reducers / Annotated 的角色)
-
LangGraph 使用 Python 类型注解(
typing.Annotated)来为状态字段附加元数据,其中常见元数据是"合并函数"(reducer)。 -
例如:
pythonclass State(TypedDict): foo: str # 覆盖式(默认) bar: Annotated[list[str], add] # 使用 add 合并(列表拼接) -
在一个 super-step 中,若两个节点都写
bar,框架会调用add(existing, new)而不是简单替换,从而实现累积语义(例如消息队列、事件收集、结果合并)。
这是 LangGraph 支持并行节点写入而仍能保证确定性的关键机制。
6. super-step 与 checkpoint / 持久化的关系
- 每个 super-step 结束都会产生一个 checkpoint(StateSnapshot) ,包含当时的
values,metadata,next,tasks等。 - Checkpoint 提供能力:恢复(restore)、回放(replay)、时间旅行(fork)、人机中断/resume(interrupt)。
- 底层实现是可插拔的
checkpointer(InMemorySaver、SqliteSaver、PostgresSaver 等),并配合Serializer(JsonPlus/EncryptedSerializer)做序列化/加密。
因此 super-step ≈ 执行单位,checkpoint ≈ 记忆/持久化副本,两者合起来就是可恢复可审计的有状态执行引擎。
7. 并发模型:多线程、协程还是同步?(工程实践)
-
super-step 本身是同步的、分阶段的调度模型(BSP)。
-
LangGraph 不强制使用多线程或协程。它在设计上允许并发执行节点,但并发是"可选的执行策略",由运行时与节点类型决定。
- 节点如果是
async def,框架可以用asyncio执行(协程)。 - 你也可以在节点内部自己使用线程池(
ThreadPoolExecutor)或外部并发资源。
- 节点如果是
-
优点:让状态合并与确定性留在框架层(避免 race condition),并发交给可控的执行策略(用户显式开启)。
-
设计理由:可重现性与确定性。自动多线程会带来写入顺序不确定,影响 reducer 行为与 snapshot 一致性。
简言之:super-step 保证"何时合并",并发实现决定"如何并发执行节点"。
8. 常见模式与示例(含 Email Agent 场景)
8.1 并行决策(B 和 C 同轮执行)
执行:
- step 1:执行 A,合并 state,checkpoint
- step 2:同时运行 B 和 C(同一 super-step),收集两者写入并合并,checkpoint
8.2 Email Agent
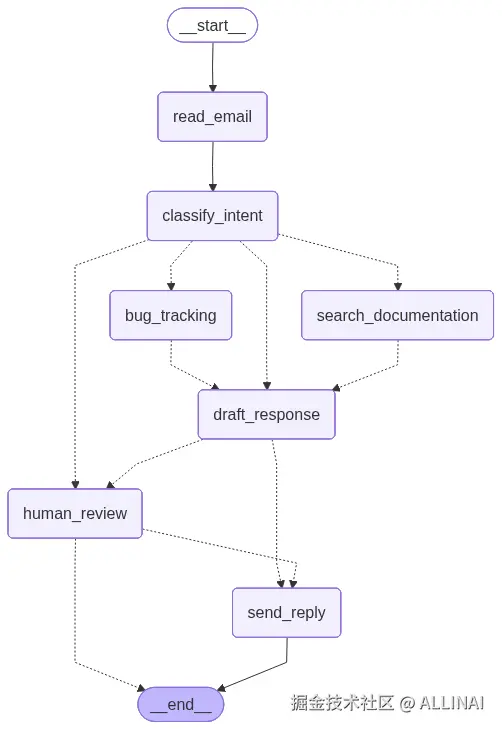
- 初始:
read_email→classify_intent - 若分类为
billing且critical:路由到human_review(interrupt) - human_review 会触发 interrupt(中断)并生成 checkpoint;第一次 invoke 返回中断 payload(没有
draft_response),等待外部 resume(人工审核) - 当 resume 提交(
app.invoke(resume))时,从中断点继续执行,进入下一轮 super-step 并合并来自人工输入的更新(例如已批准的draft_response),然后发送邮件(send_reply)
9. 优势、权衡与限制
优势
- 确定性:相同输入和相同 reducer 配置,执行可重复(对于调试与合规重要)。
- 并行表达力:可以在一轮里并执行多个逻辑独立节点。
- 强大的持久化:每步 snapshot 都可回放与恢复,是构建长期任务与对话记忆的基础。
- 清晰的合并语义:通过 Annotated 指定 reducer,避免竞态写入歧义。
权衡与限制
- 延迟的可见性:节点写入在本轮结束之前对其他节点不可见(这既是特性也是限制)。某些紧耦合场景需更细粒度交互。
- 并发不自动化:需要工程上显式选择 async/thread 才能并行,增加使用复杂度。
- 设计成本:需要为状态字段考虑合并策略(哪些字段应累积、覆盖、或用自定义 reducer)。
- 复杂 debug:多轮 super-step 与 reducer 行为结合时,理解历史演变需要读取 checkpoints(好处是可读,但需要工具)。
10. 实战建议与调试要点
- 为每个状态字段明确 reducer (用
Annotated标注),比如列表用add,字典可能用dict_merge,某些字段采用覆盖策略。 - 使用 thread_id 与 checkpoint 恰当分割会话,对话/任务用独立线程 ID,便于并行用户隔离与回放。
- 在需要并发节点时:优先使用 async 节点或显式线程池;但要确保 reducer 正确,避免顺序依赖。
- 检查点与中断调试 :当出现 KeyError(例如
draft_response不存在),检查首次 invoke 是否停在 interrupt(human_review)节点 ------ 因为 interrupt 会暂停执行且不会写回某些字段。 - 记录 metadata:开启或丰富 snapshot 的 metadata(比如哪个节点写了哪个字段),便于日后排查。
- 限制 snapshot 历史:在生产系统中需要合适保留策略或归档旧 checkpoint,避免无限膨胀。
- 加密/合规 :持久化对话数据敏感时,用
EncryptedSerializer并选择可靠后端(Postgres + AES key 管理)。
结语
LangGraph 的 super-step 并非简单的"每次执行一个节点",而是一个有意识的分阶段执行模型:保证并行表达、状态一致性与可恢复性的同时,把并发策略留给开发者显式掌控。正是这个设计,使 LangGraph 在构建复杂工作流、agent 协作、人机中断与长期记忆等场景时,既灵活又可控。