1.优化索引
1.1 初始化数据
sql
delimiter //
create procedure p_init_index_data ()
begin
declare id bigint default 100000;
declare age tinyint default 18;
declare gender bigint default 1;
declare class_id bigint default 1;
declare count int default 0;
drop table if exists index_demo;
create table index_demo (
id bigint auto_increment,
sn varchar(10) not null,
name varchar(20) not null,
mail varchar(20),
age tinyint(1),
gender tinyint(1),
password varchar(36) not null,
class_id bigint not null,
create_time datetime not null,
update_time datetime not null,
primary key (id),
index (class_id)
);
insert into index_demo values (100000, '100000', 'testUser',
'100000@qq.com', 18, 1, uuid(), 1, now(), now());
while count < 1000000 do
set id := id + 1;
if count % 10 = 0 then
set age := age + 1;
end if;
if age > 50 then
set age := 16;
end if;
if count % 3 = 0 then
set gender := 0;
else
set gender := 1;
end if;
set class_id := class_id + 1;
if class_id > 10 then
set class_id := 1;
end if;
insert into index_demo values (id, id, concat('user_',id),
concat(id,'@qq.com'), age, gender, uuid(), class_id, now(), now());
set count := count + 1;
end while;
end //
delimiter ;
call p_init_index_data();1.2 explain
作用:用于分析查询执行计划的关键字。帮助开发者理解数据库引擎如何处理特定的SQL查询,从而优化查询性能(explain本身不会执行查询,仅显示执行计划)。explain输出通常包含以下关键信息:
- id :表示查询中执行顺序的标识符。如果查询包含子查询或联合查询,id 会反映执行的层级关系。id 值越大,执行优先级越高
- select_type: 描述查询的类型,最常见的是simple(简单查询,不包含子查询或联合查询)
- table:查询涉及的表名
- partitions :表示查询涉及到的分区表的具体分区名称。如果没有分区,该字段为null
- 分区表:是一种数据库优化技术,将逻辑上的单一表按特定规则划分为多个物理存储的独立部分(称为分区),但对用户而言仍表现为一张完整的表
- type:连接类型(性能关键)
- possible_keys:可能使用的索引
- key:实际选择的索引
- key_len:索引使用的字节数
- ref :记录在查询过程中哪些列或常量与key列中指定的索引进⾏⽐较
- const:与常量值比较,例如where id = 1
- null:未使用索引
- db.table.column:多表连接时,显示另一个表的列名
- func:使用了函数或表达式,例如where upper(name) = 'ABC')
- rows:预估需要检查的行数(非精确值),值越小越好
- filtered:表示条件过滤后剩余行数的百分比,可使用row*filtered估算结果集行数
- extra:额外信息

1.3 type列
作用:显示MySQL决定使用哪种方式来查找表中的行,是执行计划中非常重要的指标。其查询的性能优劣,从最优到最差 依次为:system > const > eq_ref > ref > range > index > ALL
1.3.1 system
表中只有一行数据,不用扫描,直接返回结果集,仅使用
myisam引擎时出现
sql
create table test_system_myisam(id int primary key,name varchar(128)) engine myisam;
insert into test_system_myisam values (1,'张三');
explain select * from test_system_myisam;
+----+-------------+--------------------+------------+--------+---------------+------+---------+------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------------+------------+--------+---------------+------+---------+------+------+----------+-------+
| 1 | SIMPLE | test_system_myisam | NULL | system | NULL | NULL | NULL | NULL | 1 | 100.00 | NULL |
+----+-------------+--------------------+------------+--------+---------------+------+---------+------+------+----------+-------+1.3.2 const
当查询中的条件通过
主键索引或唯⼀索引与常量进行比较时,结果最多有⼀个匹配的行,这种类型查询性能极⾼,且只会返回一行数据
sql
-- 主键索引
explain select * from index_demo where id = 500000;
+----+-------------+------------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | index_demo | NULL | const | PRIMARY | PRIMARY | 8 | const | 1 | 100.00 | NULL |
+----+-------------+------------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
-- 唯一索引:为sn列添加唯一索引
alter table index_demo add unique unique_sn(sn);
explain select * from index_demo where sn = '500000';
+----+-------------+------------+------------+-------+---------------+-----------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+---------------+-----------+---------+-------+------+----------+-------+
| 1 | SIMPLE | index_demo | NULL | const | unique_sn | unique_sn | 42 | const | 1 | 100.00 | NULL |
+----+-------------+------------+------------+-------+---------------+-----------+---------+-------+------+----------+-------+1.3.3 eq_ref
在联合查询 中,表连接的条件是
主键索引或唯一索引时出现
sql
create table test_eq_ref (id int primary key,sn varchar(10) unique);
insert into test_eq_ref values (1,'1'),(2,'2'),(3,'3');
-- 主键索引
explain select * from index_demo,test_eq_ref where index_demo.id = test_eq_ref.id;
+----+-------------+-------------+------------+--------+---------------+---------+---------+------------------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------+------------+--------+---------------+---------+---------+------------------------------+------+----------+-------------+
| 1 | SIMPLE | test_eq_ref | NULL | index | PRIMARY | sn | 43 | NULL | 3 | 100.00 | Using index |
| 1 | SIMPLE | index_demo | NULL | eq_ref | PRIMARY | PRIMARY | 8 | mysql_advance.test_eq_ref.id | 1 | 100.00 | Using where |
+----+-------------+-------------+------------+--------+---------------+---------+---------+------------------------------+------+----------+-------------+
-- 唯一索引
explain select * from index_demo,test_eq_ref where index_demo.sn = test_eq_ref.sn;
+----+-------------+-------------+------------+--------+---------------+-----------+---------+------------------------------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------+------------+--------+---------------+-----------+---------+------------------------------+------+----------+--------------------------+
| 1 | SIMPLE | test_eq_ref | NULL | index | sn | sn | 43 | NULL | 3 | 100.00 | Using where; Using index |
| 1 | SIMPLE | index_demo | NULL | eq_ref | unique_sn | unique_sn | 42 | mysql_advance.test_eq_ref.sn | 1 | 100.00 | NULL |
+----+-------------+-------------+------------+--------+---------------+-----------+---------+------------------------------+------+----------+--------------------------+1.3.4 ref
使用
普通索引查询,可能返回多行记录
sql
explain select * from index_demo where class_id = 1;
+----+-------------+------------+------------+------+---------------+----------+---------+-------+--------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+------+---------------+----------+---------+-------+--------+----------+-------+
| 1 | SIMPLE | index_demo | NULL | ref | class_id | class_id | 8 | const | 209914 | 100.00 | NULL |
+----+-------------+------------+------------+------+---------------+----------+---------+-------+--------+----------+-------1.3.5 range
索引范围扫描 ,常见于
<>, >, >=, <, <=, is null, between, in等操作符
sql
explain select * from index_demo where id > 500000;
+----+-------------+------------+------------+-------+---------------+---------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+---------------+---------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | index_demo | NULL | range | PRIMARY | PRIMARY | 8 | NULL | 476754 | 100.00 | Using where |
+----+-------------+------------+------------+-------+---------------+---------+---------+------+--------+----------+-------------+1.3.6 index
全索引扫描 ,只遍历索引树而不需要回表查数据
sql
-- 遍历主键索引树
explain select id from index_demo;
+----+-------------+------------+------------+-------+---------------+----------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+---------------+----------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | index_demo | NULL | index | NULL | class_id | 8 | NULL | 953508 | 100.00 | Using index |
+----+-------------+------------+------------+-------+---------------+----------+---------+------+--------+----------+-------------+1.3.7 ALL
全表扫描 ,性能最差的情况。当表数据量大时需特别关注这种类型,应考虑添加合适的索引
sql
explain select * from index_demo;
+----+-------------+------------+------------+------+---------------+------+---------+------+--------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+------+---------------+------+---------+------+--------+----------+-------+
| 1 | SIMPLE | index_demo | NULL | ALL | NULL | NULL | NULL | NULL | 953508 | 100.00 | NULL |
+----+-------------+------------+------------+------+---------------+------+---------+------+--------+----------+-------+1.4 extra列
1.4.1 Using where
使用非索引列进行全表扫描 或者使用索引列发生回表查询
sql
-- 非索引列进行全表扫描
explain select * from index_demo where class_id = 1;
+----+-------------+------------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | index_demo | NULL | ALL | NULL | NULL | NULL | NULL | 953508 | 10.00 | Using where |
+----+-------------+------------+------------+------+---------------+------+---------+------+--------+----------+-------------+
-- 索引列发生回表查询
explain select * from index_demo where id > 500000;
+----+-------------+------------+------------+-------+---------------+---------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+---------------+---------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | index_demo | NULL | range | PRIMARY | PRIMARY | 8 | NULL | 476754 | 100.00 | Using where |
+----+-------------+------------+------------+-------+---------------+---------+---------+------+--------+----------+-------------+1.4.2 Using index
使用索引列发生覆盖索引
sql
explain select id from index_demo;
+----+-------------+------------+------------+-------+---------------+----------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+---------------+----------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | index_demo | NULL | index | NULL | class_id | 8 | NULL | 953508 | 100.00 | Using index |
+----+-------------+------------+------------+-------+---------------+----------+---------+------+--------+----------+-------------+1.4.3 Using filesort
需要额外排序操作,通常出现在
order by未使用索引 时。优化方案是为排序字段添加索引
sql
explain select * from index_demo where id < 200000 order by age limit 10;
+----+-------------+------------+------------+-------+---------------+---------+---------+------+--------+----------+-----------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+---------------+---------+---------+------+--------+----------+-----------------------------+
| 1 | SIMPLE | index_demo | NULL | range | PRIMARY | PRIMARY | 8 | NULL | 203406 | 100.00 | Using where; Using filesort |
+----+-------------+------------+------------+-------+---------------+---------+---------+------+--------+----------+-----------------------------+
-- 添加索引
alter table index_demo add index index_age(age);
explain select * from index_demo where id < 200000 order by age limit 10;
+----+-------------+------------+------------+-------+---------------+-----------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+---------------+-----------+---------+------+------+----------+-------------+
| 1 | SIMPLE | index_demo | NULL | index | PRIMARY | index_age | 2 | NULL | 46 | 21.33 | Using where |
+----+-------------+------------+------------+-------+---------------+-----------+---------+------+------+----------+-------------+1.4.4 Using temporary
当使用非索引列进行分组时,会用临时表进行排序,优化时可以考虑为分组的列加索引
sql
explain select avg(age) from index_demo group by gender;
+----+-------------+------------+------------+------+---------------+------+---------+------+--------+----------+-----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+------+---------------+------+---------+------+--------+----------+-----------------+
| 1 | SIMPLE | index_demo | NULL | ALL | NULL | NULL | NULL | NULL | 953508 | 100.00 | Using temporary |
+----+-------------+------------+------------+------+---------------+------+---------+------+--------+----------+-----------------+
-- 添加索引
alter table index_demo add index index_gender(gender);
explain select avg(age) from index_demo group by gender;
+----+-------------+------------+------------+-------+---------------+--------------+---------+------+--------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+---------------+--------------+---------+------+--------+----------+-------+
| 1 | SIMPLE | index_demo | NULL | index | index_gender | index_gender | 2 | NULL | 953508 | 100.00 | NULL |
+----+-------------+------------+------------+-------+---------------+--------------+---------+------+--------+----------+-------+1.5 索引覆盖
定义:当查询的列全部包含在索引树中时,查询语句只需要通过索引树即可获取所需数据,无需回表操作
2.最左匹配原则
定义:是MySQL中联合索引使用的核心规则,指查询条件必须从联合索引的最左侧字段开始,并按索引定义的字段顺序依次匹配,才能充分利用索引。若跳过最左字段或中间字段,索引可能失效
3.MySQL优化器
作用:MySQL内置优化器是数据库系统的核心组件之一,负责在执行SQL查询时生成高效的执行计划。其主要作用包括:
- 查询重写:优化器会对原始SQL语句进行语法分析和重写
- 成本估算与分析:优化器通过成本模型(Cost Model,一种量化评估机制)评估查询执行计划的性能
- 执行计划选择:优化器比较多种可能的执行方案,选择成本最低的计划
- 索引优化策略:优化器决定是否使用索引以及使用哪些索引
以下是MySQL优化器对select语句的重要优化机制
3.1 范围优化
3.1.1 单列索引范围访问
当满足以下范围定义时,MySQL优化器才可能使用单列索引进行范围访问
- BTREE和HASH索引在使用
=、<=>、in()操作符时,索引部分与常量值的比较会被视为范围条件- BTREE索引在使用
>、<、>=、<=、between、<>(!=)操作符时,索引部分与常量值的比较会被视为范围条件- like的参数是一个不以通配符开头的常量字符串 ,例如
like'abc%'- 无论索引类型如何,多个范围条件通过
or或and组合时,会形成一个复合范围条件
示例:
sql
-- key为索引列,nokey为非索引列
select * from table1 where
(key < 'abc' and (key like 'abcd%' or key like '%c')) or
(key < 'bar' and nokey = 4) or
(key < 'uux' and key > 'z');优化过程如下 :
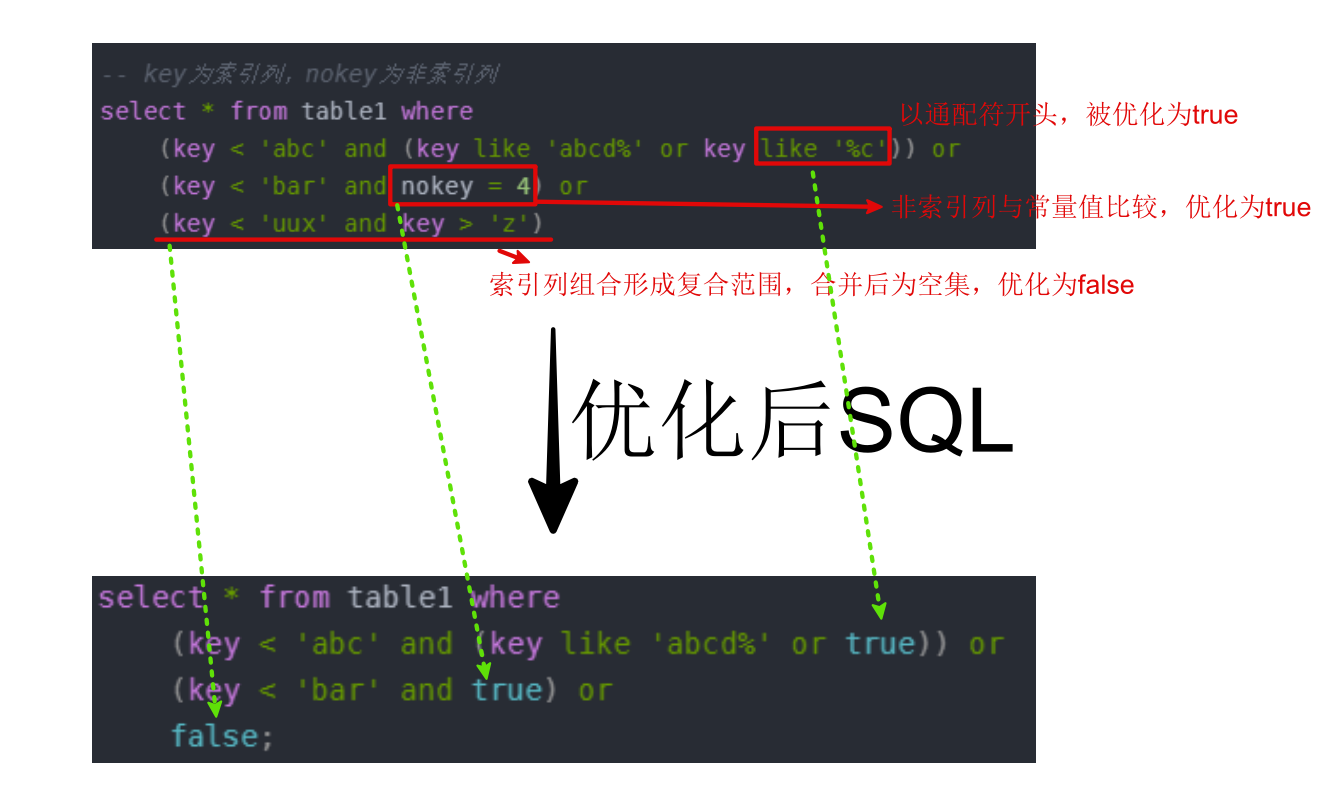
优化后SQL:
sql
select * from table1 where
(key < 'abc' and (key like 'abcd%' or true)) or
(key < 'bar' and true) or
false;
-- 化简
-- 1.(key like 'abcd%' or true)始终为true
select * from table1 where
(key < 'abc' and true) or
(key < 'bar' and true)
-- 2.合并范围
select * from table1 where key < 'bar'3.1.2 多列索引范围访问
当满足以下情况时,MySQL优化器才可能使用多列索引进行范围访问(此处多列索引指联合索引)
-
1.索引前导列:前导列是多列索引中的第一列。优化器使用多列索引时,必须包含前导列才能生效。例如,索引(a, b, c)在以下查询中有效:sqlwhere a = 1 and b = 2 and c = 3 -- (完全匹配) where a = 1 and b > 2 --(部分匹配,范围查询) where a = 1 --(仅前导列) -- 在以下查询中失效 where b = 2 and c = 3 -- (缺少前导列) where a > 1 and b = 2 -- (范围查询后无法使用后续列) -
2.HASH索引:当N个索引列与N个常量值进行=、<=>、is null操作时生效。例如:sql-- key1 ~ keyN 均是索引列,const1 ~ constN均是常量值 -- compare是(=、<=>、is null)运算符之一 key1 compare const1 and key2 compare const2 and key3 compare const3 and ... keyN compare constN -
3.BTREE索引:-
当前导索引使用
=、<=>、is null操作符时,优化器使用索引确定单个区间 -
当某一个条件开始使用
>、<、>=、<=、between、<>(!=)、like操作符时,当前条件使用索引,后续条件不再使用索引。BTREE结构对上述范围查询支持有限。当查询条件中包含范围操作符时,数据库只能利用索引快速定位到范围的起始点,但后续数据需要线性扫描,导致索引失效sql-- key1 ~ keyN 均是索引列 key1 = 'abc' and key2 >= 10 and key3 = 'MySQL' -- 上述SQL可以表示为 ('abc',10,-∞) < (key1,key2,key3) < ('abc',+∞,+∞)
-
3.2 索引合并优化
在SQL查询中,当where子句包含多个条件时,数据库优化器会根据索引选择最有效的执行计划。通常只能利用一个索引进行初步过滤,其他条件会在回表后进行检查
- 1.索引选择与回表机制:数据库优化器会评估各个索引的选择性(过滤能力),选择一个最有利的索引进行初步数据定位
- 2.回表后的处理流程:通过第一个索引定位到数据后,需要根据主键值回表获取完整行数据。此时会对其他where条件进行逐行检查
当回表的记录数很多时,需要进行大量的随机IO,这可能导致查询性能下降。MySQL在5.x版本后推出索引合并(Index Merge)来解决该问题
索引合并(Index Merge):对⼀个表同时使用多个索引进行条件扫描时,将满⾜条件的多个主键集合取交集或并集后再进行回表,可以提升查询效率(索引合并仅合并单个表中的索引扫描,而不能跨表扫描。合并的结果是多个索引扫描的并集、交集或交集的并集)
3.3 索引下推优化
定义:在传统查询流程中,存储引擎仅根据索引筛选数据,然后将满足条件的数据返回给服务层进行进一步过滤。索引下推允许将部分过滤条件下推到存储引擎层执行,减少回表操作和无效数据传输
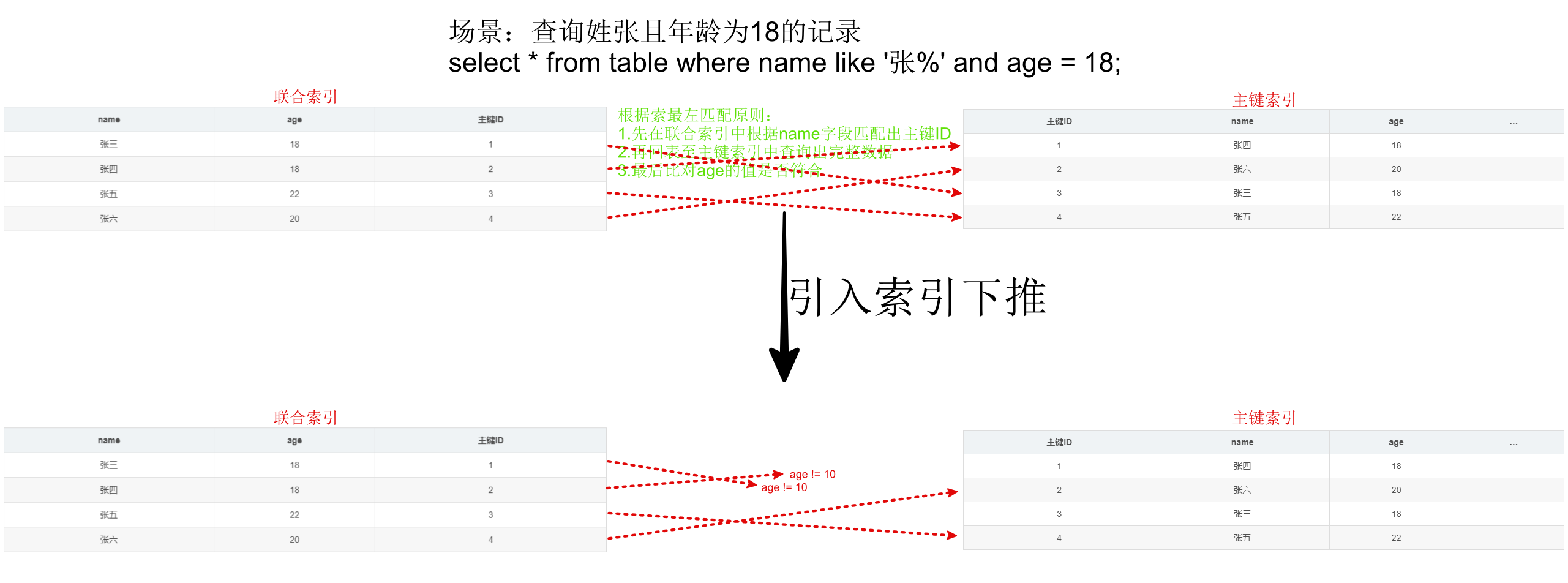
3.4 order by优化
3.4.1 使用索引进行order by
在为表中某列创建索引时,默认是有序的,如果使用索引对查询结果进行排序,就可以避免额外的资源消耗。以下是使用+索引进行order by的情况
-
对于单列索引key-
使用索引进行排序
sqlselect * from table order by key; -
key1与常量值进行比较,结果集按照key1排序(可能使用索引排序,取决于MySQL优化器的判断)
sqlselect * from table where key < | > order by key asc | desc;
-
-
对于联合索引(key1,key2)-
仅使用order by而未使用where,两列可以按同一方向排序(都是asc,或者都是desc),也可以按相反方向排序(⼀个asc,⼀个desc)
sqlselect * from table order by key1,key2; -
key1取常量值,结果集按照key2排序
sqlselect * from table where key1 = const1 order by key2;
-
3.4.2 使用filesort进行order by
以下情况MySQL不使⽤索引来处理order by
-
使用不同索引进行排序
sql-- key1和key2是不同的索引 select * from table order by key1,key2; -
不符合最左原则
sqlselect * from table order by key1,key3; -
where的索引与order by的索引不一致
sqlselect * from table where key1 = const1 order by key2; -
对索引列进行运算或转化
sql-- 对索引取绝对值 select * from table where abs(key);
⽂件排序会用到额外的内存空间,可以通过sort_buffer_size来设置排序内存的大小,默认大小256KB。如果结果集太大超出sort_buffer_size内存限制,则文件排序会根据需要使用临时磁盘文件,这样会严重影响查询效率
- 如果explain输出的extra列包含Using filesort时,说明查询语句执行了文件排序,强烈建议进行优化
3.5 group by优化
在执行group by分组查询时,会先把符合where条件的结果保存在⼀个新创建的临时表中,临时表中每个分组字段的所有行都是连续的,然后再分离每个组并应用聚合函数(如果存在)。由于索引本身就是连结的,通过使用索引可以避免创建临时表
-
分组时遵循最左原则
sqlalter table index_demo add index index_mail_age(mail,age); explain select mail,age from index_demo group by mail,age; -- 使用max和min之外的聚合函数,优化器分析性能后决定是否使用索引 +----+-------------+------------+------------+-------+---------------------------------------+----------------+---------+------+--------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+------------+------------+-------+---------------------------------------+----------------+---------+------+--------+----------+-------------+ | 1 | SIMPLE | index_demo | NULL | index | index_mail_age_classid,index_mail_age | index_mail_age | 85 | NULL | 953508 | 100.00 | Using index | +----+-------------+------------+------------+-------+---------------------------------------+----------------+---------+------+--------+----------+-------------+ explain select max(mail),min(age) from index_demo group by mail,age; +----+-------------+------------+------------+-------+---------------------------------------+----------------+---------+------+--------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+------------+------------+-------+---------------------------------------+----------------+---------+------+--------+----------+-------------+ | 1 | SIMPLE | index_demo | NULL | index | index_mail_age_classid,index_mail_age | index_mail_age | 85 | NULL | 953508 | 100.00 | Using index | +----+-------------+------------+------------+-------+---------------------------------------+----------------+---------+------+--------+----------+-------------+
3.6 函数调用优化
- MySQL函数分为确定性函数和非确定性函数。多次调用同⼀个函数并传⼊相同的参数,如果返回不同的结果,那么这个函数就是非确定性函数,比如rand(),uuid()
- 当查询中使用了非确定性函数则无法使用索引,但将非确定性函数的值保存在变量中,然后在查询语句中使用则可以使用索引
sql
-- 确定性函数,使用索引
select * from table where id = pow(1,2);
-- 非确定性函数,不使用索引
select * from table where id = floor(1 + rand() * 49);
-- 创建变量接收非确定性函数的返回值
set @value = floor(1 + rand() * 49);
-- 使用索引
select * from table where id = @value;4.索引失效
定义:通常是由于查询语句的编写方式或数据特征导致数据库优化器无法有效利用索引
-
不遵循最左原则
sqlalter table index_demo add index index_mail_age_classid(mail,age,class_id); explain select * from index_demo where age = 16; +----+-------------+------------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+------------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | 1 | SIMPLE | index_demo | NULL | ALL | NULL | NULL | NULL | NULL | 953508 | 10.00 | Using where | +----+-------------+------------+------------+------+---------------+------+---------+------+--------+----------+-------------+ -
where条件中存在or,且存在列没有索引
sqlexplain select * from index_demo where id = 500000 or age = 16; +----+-------------+------------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+------------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | 1 | SIMPLE | index_demo | NULL | ALL | PRIMARY | NULL | NULL | NULL | 953508 | 10.00 | Using where | +----+-------------+------------+------------+------+---------------+------+---------+------+--------+----------+-------------+ -
联合索引第一个使用范围查询的条件之后的列不使用索引
sqlexplain select * from index_demo where mail > '123' and age = 16 and class_id = 1; +----+-------------+------------+------------+------+------------------------+------+---------+------+--------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+------------+------------+------+------------------------+------+---------+------+--------+----------+-------------+ | 1 | SIMPLE | index_demo | NULL | ALL | index_mail_age_classid | NULL | NULL | NULL | 953508 | 0.50 | Using where | +----+-------------+------------+------------+------+------------------------+------+---------+------+--------+----------+-------------+ -
模糊查询以通配符开头
sqlexplain select * from index_demo where mail like '%123'; +----+-------------+------------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+------------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | 1 | SIMPLE | index_demo | NULL | ALL | NULL | NULL | NULL | NULL | 953508 | 11.11 | Using where | +----+-------------+------------+------------+------+---------------+------+---------+------+--------+----------+-------------+ -
隐式转换,如字符串不加引号
sqlexplain select * from index_demo where sn = 1000000; +----+-------------+------------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+------------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | 1 | SIMPLE | index_demo | NULL | ALL | unique_sn | NULL | NULL | NULL | 953508 | 10.00 | Using where | +----+-------------+------------+------------+------+---------------+------+---------+------+--------+----------+-------------+ -
where 子句中存在表达式或函数
sql-- 不使用索引 explain select * from index_demo where id + 1 = 1000000; +----+-------------+------------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+------------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | 1 | SIMPLE | index_demo | NULL | ALL | NULL | NULL | NULL | NULL | 953508 | 100.00 | Using where | +----+-------------+------------+------------+------+---------------+------+---------+------+--------+----------+-------------+ -- 使用索引 explain select * from index_demo where id = 1000000 + 1; +----+-------------+------------+------------+-------+---------------+---------+---------+-------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+------------+------------+-------+---------------+---------+---------+-------+------+----------+-------+ | 1 | SIMPLE | index_demo | NULL | const | PRIMARY | PRIMARY | 8 | const | 1 | 100.00 | NULL | +----+-------------+------------+------------+-------+---------------+---------+---------+-------+------+----------+-------+