1. 引言
在数据与AI深度融合的时代,数据库不再只是"存储与查询"的工具,而是智能应用的核心底座。openGauss作为企业级开源关系型数据库,既具备OLTP/OLAP混合负载的能力,也在向量计算、AI检索等新场景上持续演进。
本篇作为系列开篇,不仅完成在华为云 CentOS 7.9 环境的极简部署与可用性验证,还将引入更贴近生产的进阶内容:架构与版本要点、性能与SQL优化、企业级安全实践、向量与RAG场景的落地路径。文末的"进阶与实践"模块与后续两篇《使用DBeaver可视化管理与实战》《Python开发与AI向量数据库应用》形成顺畅衔接。
2. openGauss 数据库简介
openGauss是一款开源关系型数据库,深度融合了华为在数据库领域超过十年的经验,结合企业级场景需求,在架构、事务、存储引擎、优化器及AI能力上持续创新。其技术生态兼容PostgreSQL,便于客户端、驱动与工具的复用,同时在关键内核能力上增强以适配复杂负载。

2.1 核心特性与进阶解读
- 高性能与高可靠:NUMA感知线程池、混合行列式存储、并行执行与基于代价的优化器,在TP/AP混合负载下保持稳定吞吐;支持主备与容灾架构,保障连续性与合规。
- 智能化运维:慢SQL诊断、索引建议、参数自调优与在线热加载配合丰富日志与观测指标,降低排障与调优门槛。
- 生态兼容与扩展:兼容PostgreSQL生态(JDBC/ODBC/psycopg2等);在向量类型、距离算子与专用索引上扩展,服务AI检索与RAG场景。
- 原生AI支持 :提供
VECTOR(n)类型与距离算子<->,优化向量化计算,使图像、文本等非结构化数据的向量检索高效可用,为大模型时代的知识检索与增强生成夯实数据底座。
提示:产品说明与版本细节参考文档中心 https://docs.opengauss.org/zh/。 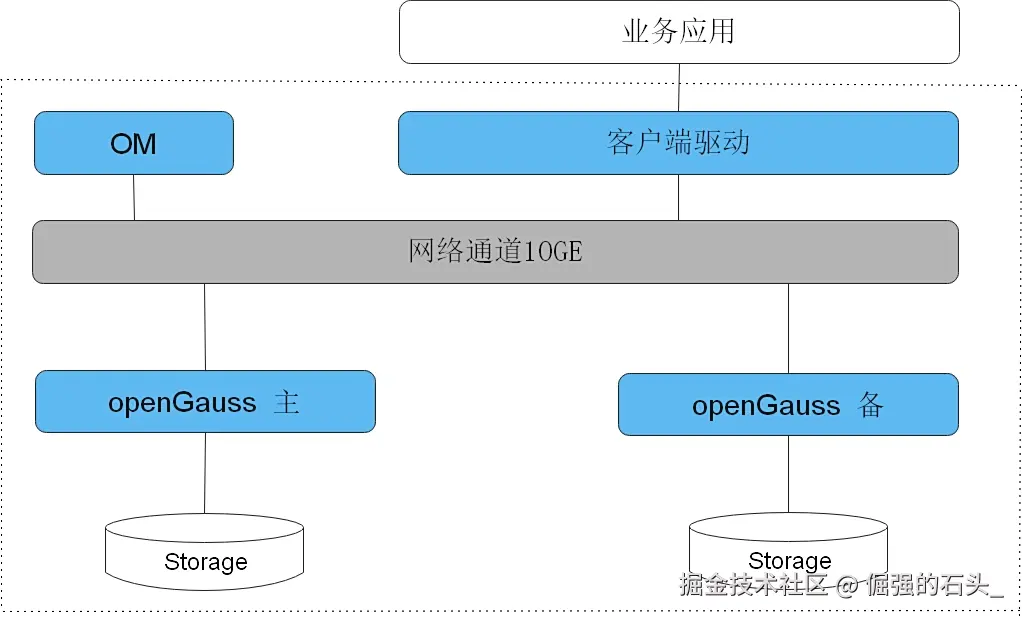
3. 在CentOS 7.9上部署 openGauss
接下来,我们将进入实战环节,演示如何在华为云的CentOS 7.9服务器上部署openGauss。
3.1 基础环境准备
在开始安装之前,请确保您的服务器满足以下基本配置,并完成相应的环境准备工作。
硬件配置
关于CentOS 7.9的兼容性说明:
官方显示支持 CentOS 7.6,7.x 系列差异较小,通常可在 7.9 成功安装。安装脚本主要检查依赖与系统环境,二者在 7.6 与 7.9 间基本一致。 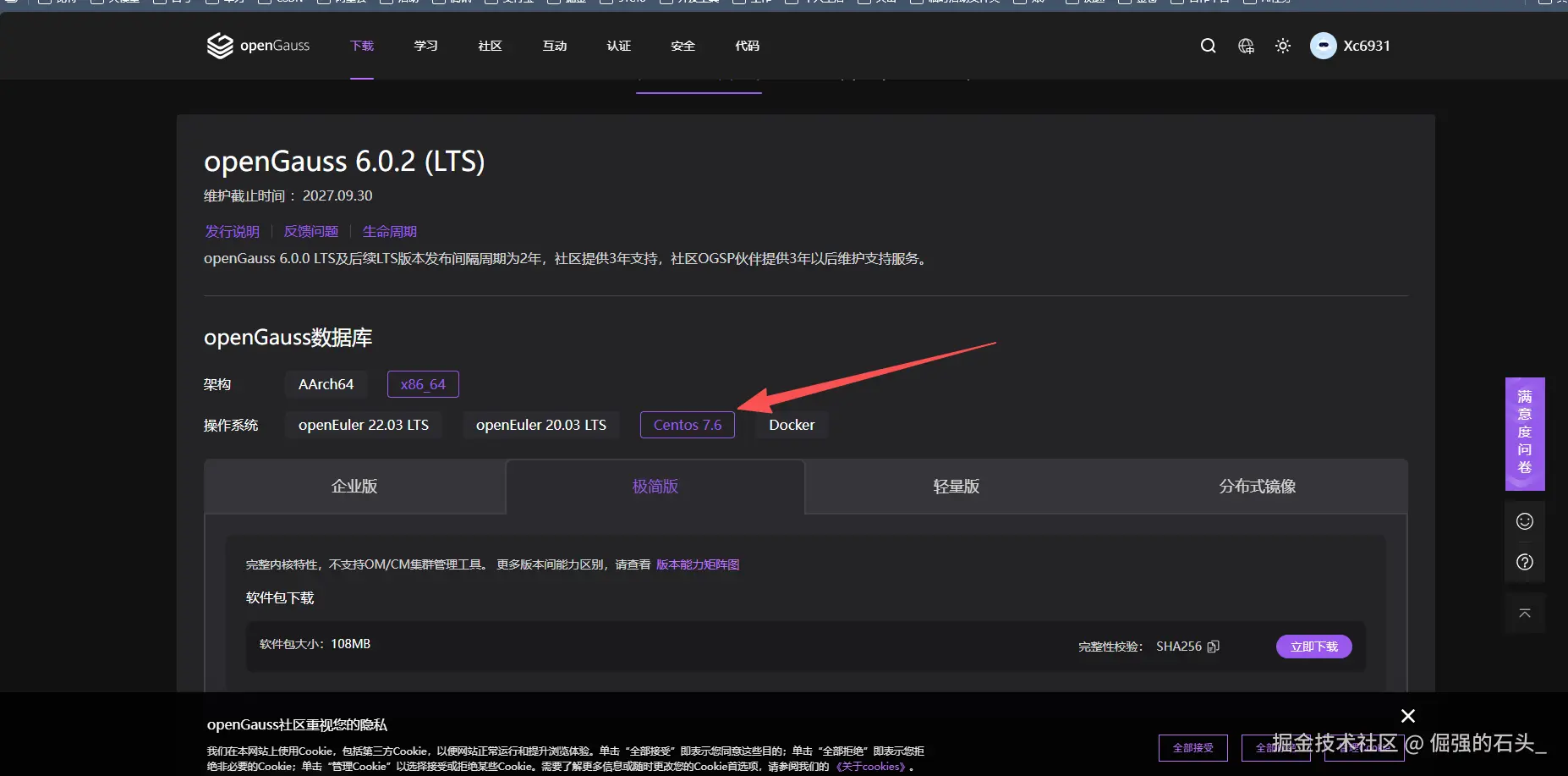
为了确保安装脚本顺利通过检查,可在安装期间临时将系统版本标识修改为"7.6",安装完成后恢复。该方法仅影响脚本检查流程,不改变系统内核与库版本。
bash
# 备份当前的系统版本文件
sudo cp /etc/redhat-release /etc/redhat-release.bak
# 临时修改为7.6
sudo echo "CentOS Linux release 7.6.1810 (Core)" > /etc/redhat-release安装完成后,记得恢复原始文件:
bash
sudo mv /etc/redhat-release.bak /etc/redhat-release环境依赖安装:
首先,通过yum安装openGauss所需依赖;建议同步进行系统层面的基础优化(见后文"进阶优化")。
bash
sudo yum install -y bzip2 libaio-devel flex bison ncurses-devel glibc-devel patch redhat-lsb-core readline-devel
关闭防火墙和SELinux:
为了简化安装过程,我们先关闭防火墙和SELinux。在生产环境中,建议您根据实际需求配置更精细的安全策略。
bash
sudo systemctl stop firewalld
sudo systemctl disable firewalld
sudo setenforce 0
# 永久关闭SELinux,需要修改配置文件
sudo sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config这里我是切换了root用户操作 
3.2 下载并解压 openGauss 安装包
您可以从openGauss的官方社区下载页面获取最新的安装包。请选择与您的操作系统和架构匹配的版本。 下载完之后用自己喜欢的方式传过去
3.3 初始化和安装数据库
openGauss提供了简单易用的安装脚本,可以帮助我们快速完成数据库的初始化。
创建用户和组:
为了安全起见,我们创建一个专门的用户omm来运行openGauss。
bash
groupadd dbgrp
useradd -g dbgrp omm
mkdir -p /opt/gaussdb/app # 程序安装路径
mkdir -p /opt/gaussdb/data # 数据存储路径
chown -R omm:dbgrp /opt/opengauss /opt/gaussdb # 授权给 omm 用户
上传并解压安装包 (假设包已上传到 /opt/opengauss):
bash
cd /opt/opengauss
# 解压(注意后缀是 .tar.bz2,用 -j 参数)
tar -jxvf openGauss-Server-6.0.2-CentOS7-x86_64.tar.bz2
# 解压后会生成 `simpleInstall` 目录,进入该目录
cd simpleInstall
执行安装:
切换到omm用户,并执行安装脚本。
bash
sh install.sh -w "Gauss@123456" 
安装脚本会自动完成数据库的初始化、配置和启动。
进阶提示:生产环境建议将程序与数据目录置于独立磁盘或分区,数据目录开启合适的挂载参数(如 noatime),并规划独立的归档与备份路径,降低IO干扰与运维风险。
4. 验证数据库可用性
安装完成后,需通过gs_ctl(状态检查工具)和gsql(命令行客户端)验证数据库是否正常运行。由于极简版未生成env.sh环境变量脚本,需手动配置核心环境变量以确保命令可用。
4.1 手动设置环境变量
openGauss 需通过omm用户(安装时创建的专属用户)操作,且需手动指定数据库安装路径、二进制文件路径等核心环境变量:
bash
# 手动设置核心环境变量(路径需与实际安装目录一致,此处为/opt/opengauss)
export GAUSSHOME=/opt/opengauss # 数据库安装根目录
export PATH=$GAUSSHOME/bin:$PATH # 将数据库二进制命令(如gsql、gs_ctl)加入系统路径
export LD_LIBRARY_PATH=$GAUSSHOME/lib:$LD_LIBRARY_PATH # 加载数据库依赖库
# 验证环境变量是否生效(执行后显示openGauss版本即成功)
gsql --version预期输出(类似如下内容,版本号以实际安装为准):

4.2 检查数据库运行状态
在连接数据库前,先通过gs_ctl确认数据库是否已启动(极简版安装脚本默认自动启动,但建议手动验证):
bash
# 执行状态检查命令(-D 指定数据存储目录,极简版默认路径为/opt/opengauss/data/single_node)
gs_ctl status -D /opt/opengauss/data/single_node关键判断依据:
bash
# 启动数据库(同样指定数据目录)
gs_ctl start -D /opt/opengauss/data/single_node -Z single_node
```

### 4.3 连接数据库
通过`gsql`命令行客户端连接到默认数据库`postgres`(openGauss 默认端口为 5432,需指定用户和安装时设置的密码):
```bash
# 连接命令格式:gsql -d 数据库名 -p 端口 -U 用户名 -W 密码
gsql -d postgres -p 5432 -U omm -W "Gauss@123456"- 参数说明:
-d postgres:连接默认系统数据库postgres;-p 5432:使用 openGauss 默认端口;-U omm:通过omm用户(数据库超级管理员)连接;-W "Gauss@123456":指定安装时设置的密码(需替换为您实际设置的密码)。
预期输出(出现如下交互界面,说明连接成功):

4.4 执行简单查询验证功能
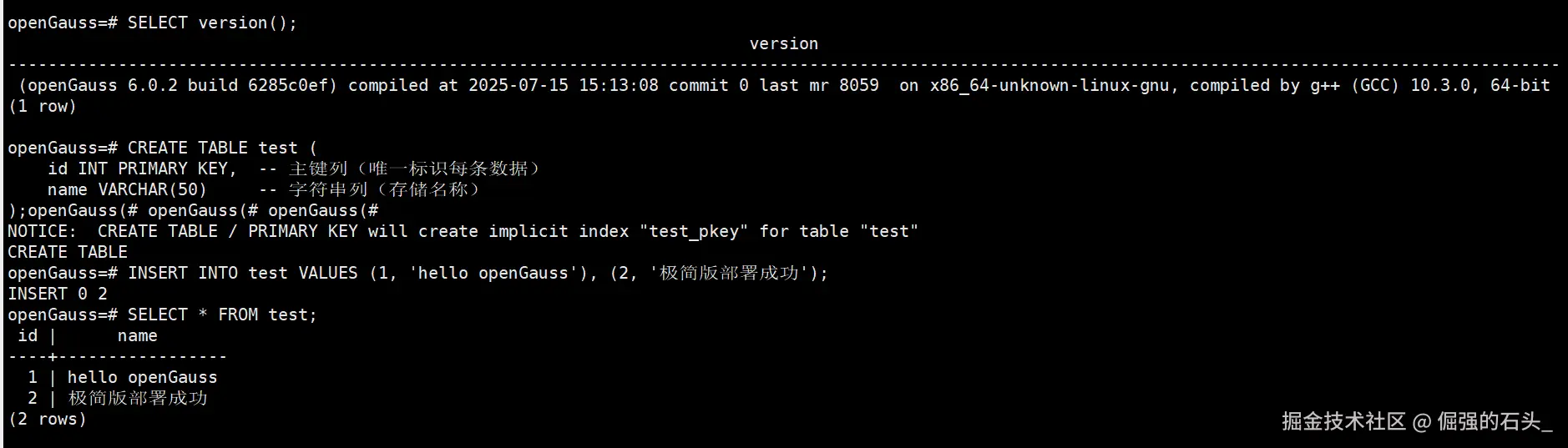
在openGauss=#交互界面中,执行 SQL 语句验证数据库读写能力:
sql
-- 1. 查看数据库版本(确认当前连接的数据库信息)
SELECT version();
-- 2. 创建测试表(验证表创建功能)
CREATE TABLE test (
id INT PRIMARY KEY, -- 主键列(唯一标识每条数据)
name VARCHAR(50) -- 字符串列(存储名称)
);
-- 3. 插入测试数据(验证数据写入功能)
INSERT INTO test VALUES (1, 'hello openGauss'), (2, '极简版部署成功');
-- 4. 查询测试数据(验证数据读取功能)
SELECT * FROM test;预期结果:
- 执行
SELECT version();后显示 openGauss 版本及编译信息; - 执行
SELECT * FROM test;后显示如下数据(无报错即说明功能正常):
4.5 环境变量持久化(可选,避免重复配置)
手动设置的环境变量仅在当前终端生效,关闭终端后需重新配置。若需每次登录omm用户自动加载环境变量,可将配置写入omm用户的环境变量文件~/.bashrc:
bash
# 1. 编辑 omm 用户的 .bashrc 文件
vi ~/.bashrc
# 2. 在文件末尾添加以下内容(与4.1中的环境变量配置一致)
export GAUSSHOME=/opt/opengauss
export PATH=$GAUSSHOME/bin:$PATH
export LD_LIBRARY_PATH=$GAUSSHOME/lib:$LD_LIBRARY_PATH
# 3. 保存并退出(按Esc → 输入:wq → 回车)
# 4. 使配置立即生效(无需重启终端)
source ~/.bashrc验证 :关闭当前终端,重新登录omm用户,直接执行gsql --version,若正常显示版本信息,说明持久化配置成功。
5. 进阶优化:从可用到好用
部署成功只是开始,良好的性能与稳定性需要合理的参数、SQL实践与可观测性。以下步骤可在极简版基础上逐步引入,并与后续两篇形成连贯实践。
5.1 关键参数与观测
-
参数自查:
sqlSHOW shared_buffers; SHOW work_mem; SHOW effective_cache_size; SHOW max_connections; SHOW enable_nestloop; SHOW log_min_duration_statement; -
建议策略:在保证内存安全的前提下适度增大
shared_buffers与effective_cache_size;针对复杂聚合或排序增大work_mem;开启慢SQL日志(如设置log_min_duration_statement=500ms)并定期分析。 -
在线热加载:针对
pg_hba.conf与部分postgresql.conf变更,可使用gs_ctl reload -D /opt/opengauss/data/single_node,减少重启成本。
5.2 SQL优化与执行计划
-
基础操作:
sqlEXPLAIN (ANALYZE, BUFFERS) SELECT u.user_name, SUM(o.order_amount) FROM users u JOIN orders o ON u.user_id=o.user_id GROUP BY u.user_name ORDER BY SUM(o.order_amount) DESC LIMIT 10; -
关注指标:行数估算、连接方式(Nested Loop/Hash Join/Merge Join)、并行度、IO命中(Buffers Hit/Read)。必要时考虑创建合适索引、更新统计信息或调整启用/禁用某些连接策略(
enable_nestloop/enable_hashjoin/enable_mergejoin)。
5.3 索引策略与统计信息
-
索引类型:优先使用 B-tree;针对文本检索与JSON等可考虑 GIN/GiST。创建索引后执行示例:
sqlCREATE INDEX idx_orders_user_id ON orders(user_id); ANALYZE orders; -
统计信息:提升
default_statistics_target或对关键表定向ALTER TABLE ... SET STATISTICS,确保优化器更准确。
5.4 备份与恢复(逻辑备份)
-
建议在例行变更前进行逻辑备份:
bashgs_dump -h 127.0.0.1 -p 5432 -U omm -d postgres -F p -f /opt/backup/postgres_$(date +%F).sql -
恢复示例:
bashgsql -d postgres -U omm -p 5432 -f /opt/backup/postgres_2025-11-01.sql
5.5 批量导入与数据上云
-
高效导入:优先使用
COPY/\copy进行批量数据导入,显著提升吞吐;\copy在客户端执行,权限更灵活:sql\copy public.orders(user_id, order_amount, order_date) FROM '/opt/data/orders_2025.csv' WITH (FORMAT csv, HEADER true); -
并行导入:将大文件按时间或主键范围切分为多份,使用多会话并行
\copy;导入后执行ANALYZE更新统计信息。 -
数据落盘策略:将导入源文件置于独立磁盘并开启顺序读参数,避免与数据库数据盘产生IO争用;必要时降低数据库并行度,优先保障导入带宽。
5.6 分区表与冷热分层
-
适用场景:订单、日志、审计等按时间增长的大表,推荐使用范围分区,提升查询与维护效率:
sqlCREATE TABLE orders_big ( id BIGSERIAL PRIMARY KEY, user_id INT, order_amount NUMERIC(10,2), order_date DATE ) PARTITION BY RANGE (order_date) ( PARTITION p2024 VALUES LESS THAN ('2025-01-01'), PARTITION p2025 VALUES LESS THAN ('2026-01-01'), PARTITION pmax VALUES LESS THAN (MAXVALUE) ); CREATE INDEX idx_orders_big_user_date ON orders_big(user_id, order_date); -
维护与归档:按月或季度添加/切换分区;对历史分区进行
VACUUM/ANALYZE或脱机归档,减少主库膨胀与备份体积。
5.7 会话与锁观测(并发稳定性)
-
观察活动与长事务:
sqlSELECT pid, usename, state, query_start, now()-query_start AS runtime, query FROM pg_stat_activity WHERE state <> 'idle' ORDER BY runtime DESC LIMIT 10; -
观察锁冲突:
sqlSELECT locktype, mode, granted, relation::regclass AS rel, pid FROM pg_locks WHERE NOT granted; -
建议策略:通过连接池降低
max_connections带来的上下文切换;对热点行采用更合理的更新策略(分桶/排队);出现序列化冲突时在应用侧进行指数退避重试。
6. 安全实践:从默认安全到远程访问
openGauss坚持"安全缺省"原则。为保证生产安全与远程可达,建议按以下路径配置(与第二篇可视化管理内容保持一致):
-
监听与访问控制:
bashvi /opt/opengauss/data/single_node/postgresql.conf listen_addresses = '*' vi /opt/opengauss/data/single_node/pg_hba.conf host all all 0.0.0.0/0 md5 -
初始用户远程限制:不建议使用初始超级用户(如
omm)进行远程业务访问;在本机以omm登录后创建业务账号并授权:sqlCREATE USER dbuser WITH PASSWORD 'S@fePwd_2025'; GRANT USAGE ON SCHEMA public TO dbuser; GRANT SELECT, INSERT, UPDATE, DELETE ON TABLE public.test TO dbuser; -
加密与认证:根据合规要求启用更强口令加密与认证方式(如
sha256),并保证pg_hba.conf与数据库参数保持一致;必要时评估启用SSL并在客户端设置sslmode。
6.1 认证规则的优先级与收敛
- 规则匹配自上而下执行,建议将更严格的网段/IP规则置于靠前位置;保留本机
local/127.0.0.1/::1的便捷规则,远程一律使用口令或更强方式: host all all 10.0.0.0/24 sha256 host all all 0.0.0.0/0 md5 - 禁止远程
trust以避免误配导致的非授权访问。
6.2 更强口令加密与一致性
-
在
postgresql.conf设置password_encryption_type=2(SHA-256)后,需为相关用户重置口令以生成新密文:sqlALTER USER dbuser WITH PASSWORD 'S@fePwd_2025_New'; -
保证
pg_hba.conf使用与数据库侧一致的认证算法(如sha256),否则会出现握手失败或认证异常。
6.3 快速启用 SSL(可选)
-
生成自签证书并配置:
bashopenssl req -new -x509 -days 365 -nodes -text -out /opt/opengauss/server.crt -keyout /opt/opengauss/server.key chmod 600 /opt/opengauss/server.key -
在
postgresql.conf: ssl = on ssl_cert_file = 'server.crt' ssl_key_file = 'server.key' -
重启后,客户端在URL或连接属性中设置
sslmode=require;若服务器未启用SSL,则使用sslmode=disable保持一致。
7. AI与向量检索:从入门到落地
为与系列第三篇形成衔接,本篇提供最小化向量能力验证,引导读者在后续文章中完成端到端的RAG示例。
-
启用向量扩展与创建示例表:
sqlCREATE EXTENSION vectors; CREATE TABLE t_image_vectors ( id SERIAL PRIMARY KEY, image_path VARCHAR(255) NOT NULL, image_vector VECTOR(512) ); -
最小检索示例(占位向量,演示距离算子):
sqlINSERT INTO t_image_vectors(image_path, image_vector) VALUES ('assets/images/cat.jpg', '[0.1,0.2,0.3,...]'::vector), ('assets/images/dog.jpg', '[0.2,0.1,0.4,...]'::vector); SELECT image_path, image_vector <-> '[0.12,0.18,0.33,...]'::vector AS dist FROM t_image_vectors ORDER BY dist LIMIT 3;
以上"向量能力验证"与第三篇的sentence-transformers编码流程、Python入库与检索代码完全对齐,避免割裂阅读体验。
7.1 索引加速与召回质量(可选)
-
若扩展版本支持近似向量索引(如
ivfflat或hnsw),可创建索引以提升检索性能;具体语法以扩展版本文档为准:sql-- ivfflat(L2 距离示例) CREATE INDEX idx_img_vec_ivf ON t_image_vectors USING ivfflat (image_vector); -- 建议在创建索引前对向量表执行 ANALYZE,提高索引构建效果 ANALYZE t_image_vectors; -
参数调优:
lists(ivfflat)或ef_search/M(hnsw)会影响召回率与性能;可在万级以上数据量下进行A/B测试,选择适中参数。
7.2 数据准备与向量质量
- 统一模型与维度:确保入库向量来自同一模型与版本,如
clip-ViT-B-32(512维);混用模型会降低距离度量的意义。 - 归一化与预处理:对某些模型可在应用侧进行归一化处理,提高与L2/余弦等度量的一致性。
- 冷热分层:将低频图片或文本向量归档至历史分区或冷存储,前台索引主打热数据,降低检索延迟。
7.3 执行计划与观测
-
观察检索开销:
sqlEXPLAIN (ANALYZE, BUFFERS) SELECT image_path FROM t_image_vectors ORDER BY image_vector <-> '[...]'::vector LIMIT 10; -
指标参考:是否命中索引、扫描行数、缓冲命中与读取比例;在大数据量下对比有无索引的耗时差异,评估可接受的召回与延迟。
7.4 常见问题排查
- 扩展不可用:
\dx检查是否已启用vectors/vector;若未安装请参考发行版文档或按平台构建。 - 兼容性问题:在客户端URL增加
preferQueryMode=simple或使用官方openGauss JDBC;对Python驱动保持版本一致并验证基础CRUD与事务。 - 权限问题:为业务用户授予表与序列权限;在分区表与向量表上单独验证
INSERT/SELECT/UPDATE/DELETE。
8. 与可视化与应用开发的衔接
- 可视化管理:第二篇使用 DBeaver 进行连接、对象管理、事务演示与远程连接排障,建议在完成本篇部署后直接跟进实践。
- 应用开发与RAG实战:第三篇通过 Python
psycopg2驱动完成 CRUD 与事务示例,并实现以文搜图的向量检索;参数与对象命名与本篇保持一致,便于无缝复用。
9. 总结与展望
本篇在完成极简部署与基础验证的同时,补充了架构与版本要点、进阶优化路径、安全实践以及向量与RAG的入门引导,形成可向后续两篇延伸的完整链路。下一篇以 DBeaver 提供更直观的管理与调优体验;再下一篇以 Python 与向量能力实现端到端的RAG应用,完成从"入门"到"落地"的闭环。