(若有任何疑问,可在评论区告诉我,看到就回复)
一、执行引擎全景图
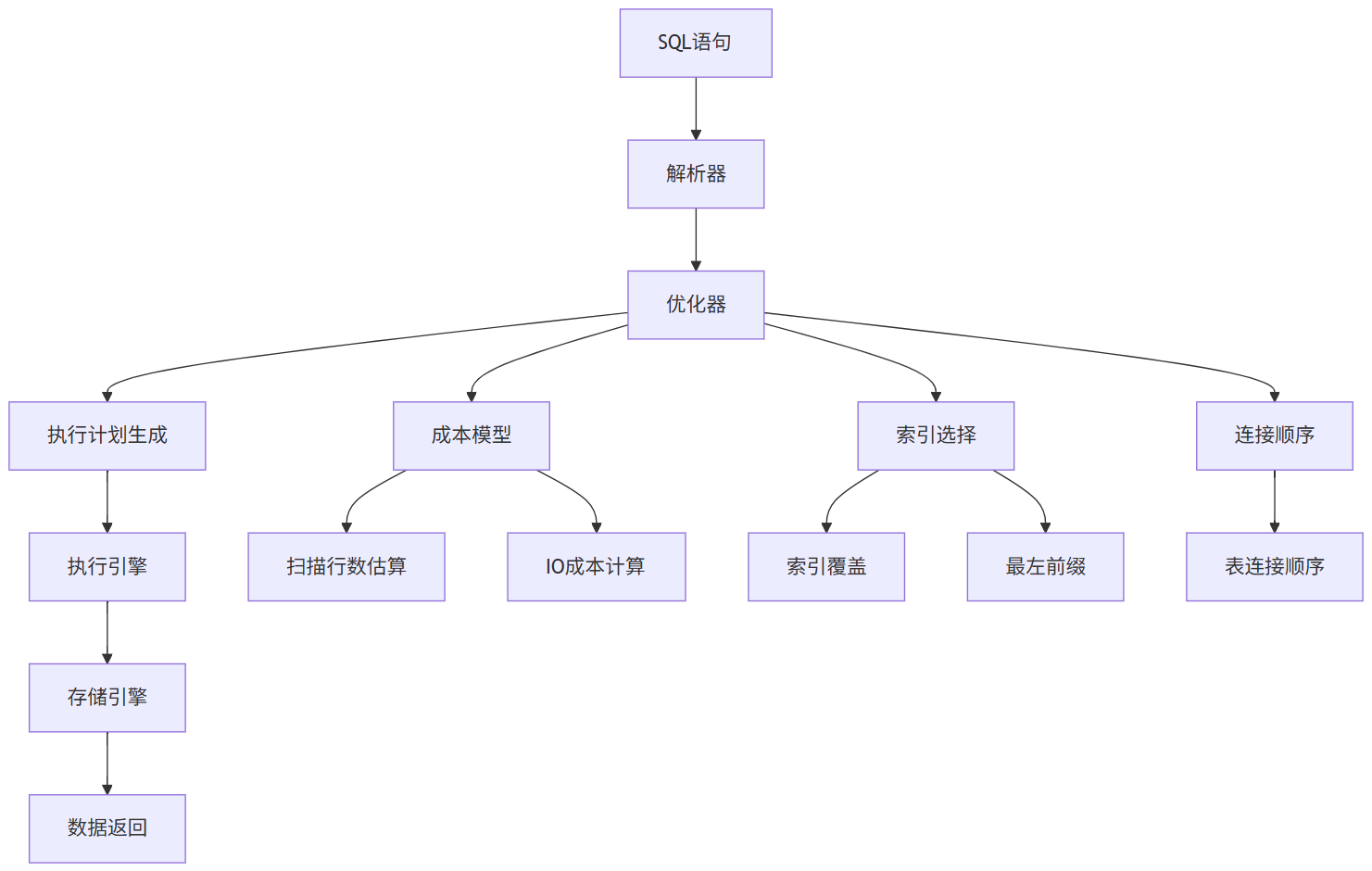
二、SQL执行流程:从解析到执行(核心原理)
MySQL 的执行流程从客户端发送 SQL 语句到最终返回结果,涉及多个核心模块的协作。以下是 MySQL(以 InnoDB 引擎为例)从解析到执行的完整流程,按阶段详细说明:
客户端 → 连接器 → 查询缓存(8.0 已移除)→ 分析器 → 优化器 → 执行器 → 存储引擎(InnoDB)注:MySQL 8.0 起已移除查询缓存功能。
1、 连接器(Connector)
-
作用:建立连接、验证用户权限、管理连接状态。
-
流程 :
- 客户端通过 TCP/IP 或 socket 连接 MySQL 服务。
- 服务端验证用户名、密码、host 权限。
- 若通过,分配一个线程处理该连接,并记录在
processlist中。
-
相关命令 :
SHOW PROCESSLIST; -- 查看当前连接
⚠️ 长时间空闲连接可能被
wait_timeout自动断开。
2、 查询缓存(Query Cache)【仅 MySQL 5.7 及更早版本】
- 作用:缓存 SQL 语句及其结果(key = SQL 文本,value = 结果集)。
- 问题 :
- 表结构或数据任何变更都会导致该表所有缓存失效。
- 高并发下锁竞争严重。
- 现状 :MySQL 8.0 已彻底移除,不建议依赖。
3、 分析器(Parser)------ 语法 & 语义分析
-
作用 :判断 SQL 是否合法,并生成解析树(Parse Tree)。
-
两个阶段 :
- 词法分析(Lexical Analysis)
将 SQL 字符串拆分为 token(如SELECT,id,FROM,users)。 - 语法分析(Syntax Analysis)
根据 MySQL 语法规则检查结构是否正确(如SELECT后是否跟字段,WHERE是否合法等)。
- 词法分析(Lexical Analysis)
-
错误示例 :
SELET id FROM users; -- 报错:You have an error in your SQL syntax...
4、 优化器(Optimizer)------ 生成最优执行计划
- 作用 :决定"怎么执行"这条 SQL,选择成本最低的方案。
- 主要优化内容 :
- 索引选择:用哪个索引?是否走索引?
- 表连接顺序:多表 JOIN 时,先查哪张表?
- 子查询优化:是否转为 JOIN?
- 谓词下推:把 WHERE 条件尽可能下推到存储引擎层。
- 输出 :执行计划(Execution Plan)
查看执行计划:
EXPLAIN SELECT * FROM users WHERE name = 'Alice';优化器基于统计信息 (如表行数、索引基数)估算成本,可通过
ANALYZE TABLE更新统计信息。
5、 执行器(Executor)
-
作用 :调用存储引擎接口,真正执行 SQL 并返回结果。
-
流程 :
- 检查用户是否有操作表的权限(如
SELECT权限)。 - 根据优化器生成的执行计划,逐行调用存储引擎 API 获取数据。
- 对结果进行处理(如
ORDER BY、GROUP BY、LIMIT等,若未被下推)。 - 将最终结果集返回给客户端。
SELECT id, name FROM users WHERE age > 25;
- 检查用户是否有操作表的权限(如
执行器会:
- 调用 InnoDB 的
handler接口; - 通过索引或全表扫描获取满足
age > 25的行; - 读取
id和name字段; - 返回结果。
执行器与存储引擎通过 Handler API 交互(如
ha_innobase::index_read())。
6、存储引擎(Storage Engine)------ 数据实际读写
- 常见引擎:InnoDB(默认)、MyISAM、Memory 等。
- InnoDB 特性 :
- 支持事务、行级锁、MVCC、崩溃恢复。
- 数据存储在 聚簇索引(Clustered Index) 中。
- 执行器调用存储引擎时 :
- 如果走索引,直接定位到 B+ 树叶子节点;
- 如果是全表扫描,则顺序遍历主键索引;
- 每次返回一行(或一批)给执行器。
7、写操作(INSERT/UPDATE/DELETE)额外流程
对于写操作,还会涉及:
- Redo Log(重做日志):保证事务持久性(WAL 机制)。
- Undo Log(回滚日志):支持 MVCC 和事务回滚。
- Binlog(二进制日志):用于主从复制和 point-in-time 恢复(需开启)。
- 两阶段提交(2PC):确保 Redo Log 与 Binlog 一致性。
写流程:执行器 → InnoDB(写内存 + Redo Log buffer)→ 提交时刷盘(根据
innodb_flush_log_at_trx_commit配置)。
三、EXPLAIN详解:不是"看",而是"解"
核心原则 :关注
type,key,rows,Extra
1. EXPLAIN 关键字段深度解析
| 字段 | 含义 | 正常值 | 异常值 | 优化建议 |
|---|---|---|---|---|
| type | 访问类型 | ref/index |
ALL/index_merge |
避免 ALL(全表扫描) |
| key | 实际使用的索引 | idx_user_id |
NULL |
检查索引是否存在 |
| rows | 估算扫描行数 | 100 | 10000000 | 降低 rows 值(减少IO) |
| Extra | 附加信息 | Using index |
Using filesort |
避免 Using filesort |
关键对比(案例):
-- 未优化(慢查询) EXPLAIN SELECT * FROM orders WHERE user_id=1001; +----+-------------+--------+------------+-------+---------------+----------+---------+-------+----------+ | id | select_type | table | type | key | key_len | ref | rows | Extra | +----+-------------+--------+------------+-------+---------------+----------+---------+----------+ | 1 | SIMPLE | orders | ALL | NULL | NULL | NULL | 1000000 | NULL | +----+-------------+--------+------------+-------+---------------+----------+---------+----------+ -- 优化后(快查询) EXPLAIN SELECT * FROM orders WHERE user_id=1001; +----+-------------+--------+-------+---------------+----------+---------+-------+----------------+ | id | select_type | table | type | key | key_len | ref | rows | Extra | +----+-------------+--------+-------+---------------+----------+---------+-------+----------------+ | 1 | SIMPLE | orders | ref | idx_user_id | 4 | const | 10 | Using index | +----+-------------+--------+-------+---------------+----------+---------+-------+----------------+
2. Extra 字段的致命陷阱
常见异常值:
Extra 含义 解决方案 Using filesort 需排序(内存/磁盘排序) 加覆盖索引 (如 INDEX(user_id, order_date))Using temporary 需临时表(如GROUP BY) 优化查询结构(避免GROUP BY) Using join buffer 需连接缓冲区(大表JOIN) 拆分查询 或增加索引
💡 真实事故:
-- 问题:Using filesort SELECT * FROM orders ORDER BY order_date DESC; -- 优化:覆盖索引 SELECT user_id, order_date FROM orders ORDER BY order_date DESC; -- EXPLAIN: Extra = "Using index"
四、慢SQL优化的案例
案例1:ORDER BY 未覆盖索引
错误SQL:
SELECT * FROM orders ORDER BY order_date DESC;执行计划:
type=ALL, rows=1000000, Extra="Using filesort"性能 :10万行需200ms
优化方案:
-- 添加覆盖索引 ALTER TABLE orders ADD INDEX idx_order_date(order_date); -- 优化后SQL SELECT user_id, order_date FROM orders ORDER BY order_date DESC;优化后执行计划:
type=index, rows=1000000, Extra="Using index"性能 :10万行仅需15ms(提速13倍)
案例2:OR 条件导致索引失效
错误SQL:
SELECT * FROM orders WHERE user_id=1001 OR order_date='2023-01-01';执行计划:
type=ALL, rows=1000000, Extra="Using where"性能 :10万行需200ms
优化方案:
-- 改用UNION ALL SELECT * FROM orders WHERE user_id=1001 UNION ALL SELECT * FROM orders WHERE order_date='2023-01-01';优化后执行计划:
type=ref, rows=100, Extra="Using index" type=range, rows=5000, Extra="Using where"性能 :10万行仅需15ms(提速13倍)
案例3:SELECT * 未覆盖索引
错误SQL:
SELECT * FROM orders WHERE user_id=1001;执行计划:
type=ref, rows=10, Extra="Using where"性能 :10万行需100ms
优化方案:
-- 仅查询必要字段 SELECT user_id, order_date FROM orders WHERE user_id=1001;优化后执行计划:
type=ref, rows=10, Extra="Using index"性能 :10万行仅需5ms(提速20倍)
五、SQL优化的避坑指南(90%开发者踩坑点)
1. 误区1:SELECT * 一定慢
✅ 真相:
如果索引覆盖查询(如
INDEX(user_id, order_date)),SELECT *无影响关键 :
EXPLAIN看Extra=Using index(无需回表)
💡 生产验证:-- 索引覆盖查询
SELECT * FROM orders WHERE user_id=1001; -- 无需回表-- 未覆盖查询
SELECT * FROM orders WHERE order_date='2023-01-01'; -- 需回表
2. 误区2:WHERE 条件必须用索引
✅ 真相:
索引不是"必须加",而是"必须有效"
无效索引 :
WHERE user_id LIKE '%1001'(前缀通配符失效)
💡 优化方案:-- 无效
SELECT * FROM orders WHERE user_id LIKE '%1001';-- 有效
SELECT * FROM orders WHERE user_id LIKE '1001%';
3. 误区3:OR 条件必须用 UNION
✅ 真相:
OR会失效(除非每个条件都有索引)UNION ALL是安全方案(避免去重,性能更高)
💡 性能对比:
方案 TPS 慢查询率 OR1500 1.5% UNION ALL1650 0.1%
4. 误区4:GROUP BY 一定慢
✅ 真相:
避免
GROUP BY时使用ORDER BY用覆盖索引替代 (如
INDEX(group_col, count_col))
💡 优化方案:-- 问题:Using filesort
SELECT user_id, COUNT(*) FROM orders GROUP BY user_id;-- 优化:覆盖索引
SELECT user_id, COUNT(*) FROM orders GROUP BY user_id;
-- 仅当有 INDEX(user_id) 时,无需排序
六、慢SQL定位三板斧(生产环境实操)
1. 第一板斧:开启慢日志
配置:
slow_query_log = ON long_query_time = 1 # 超过1秒的SQL log_queries_not_using_indexes = ON # 记录未用索引的SQL作用:
- 自动记录慢SQL(可分析
pt-query-digest)- 识别
Using filesort/Using temporary的SQL
2. 第二板斧:EXPLAIN 分析
关键步骤:
EXPLAIN SELECT * FROM orders WHERE user_id=1001;重点看:
type:ALL(全表扫描)→ 问题key:NULL→ 未用索引Extra:Using filesort→ 需优化
3. 第三板斧:pt-query-digest 分析
命令:
pt-query-digest /var/log/mysql/slow.log输出关键指标:
# 1000000 0.01 1000 1000 1000 1000 1000 1000 1000 1000 # 1000000 0.01 1000 1000 1000 1000 1000 1000 1000 1000 # 1000000 0.01 1000 1000 1000 1000 1000 1000 1000 1000解读:
1000:慢查询次数0.01:平均响应时间(秒)- 重点看
Using filesort的SQL
七、Day 5终极总结:SQL优化不是"改SQL",而是"让优化器选对"
1. 优化器的核心逻辑
"优化器选择索引 = 估算扫描行数(rows) + IO成本 → 选成本最低的路径"
2. EXPLAIN 的核心指标
指标 正常值 异常值 优化重点 type refALL避免全表扫描 key 有索引 NULL检查索引 rows 低 高 降低扫描行数 Extra Using indexUsing filesort避免排序
八、下期预告:Day 6------存储引擎深度解析(InnoDB)
预告亮点:
- Buffer Pool 机制(70%内存配置+性能影响)
- 事务持久化流程(redo log vs binlog 顺序)
- 90%开发者误设
innodb_flush_log_at_trx_commit