NeurIPS(Conference on Neural Information Processing Systems)是神经信息处理系统领域最具影响力的会议,专注于机器学习、计算神经科学和统计学的交叉研究。NeurIPS 2025将于12月2日至12月7日在美国加利福尼亚州圣地亚哥举办,本届共收到了21,575篇有效论文提交,最终有5,290篇被接收,整体录用率为24.52%。其中快手共有13篇论文入选NeurIPS2025,包括可灵团队的8篇。这些论文涵盖视频生成与优化、多模态大模型评估与鲁棒性研究、视频压缩与表征、情感计算与跨模态同步、以及实时视频流分析与应用等方向。

论文精选
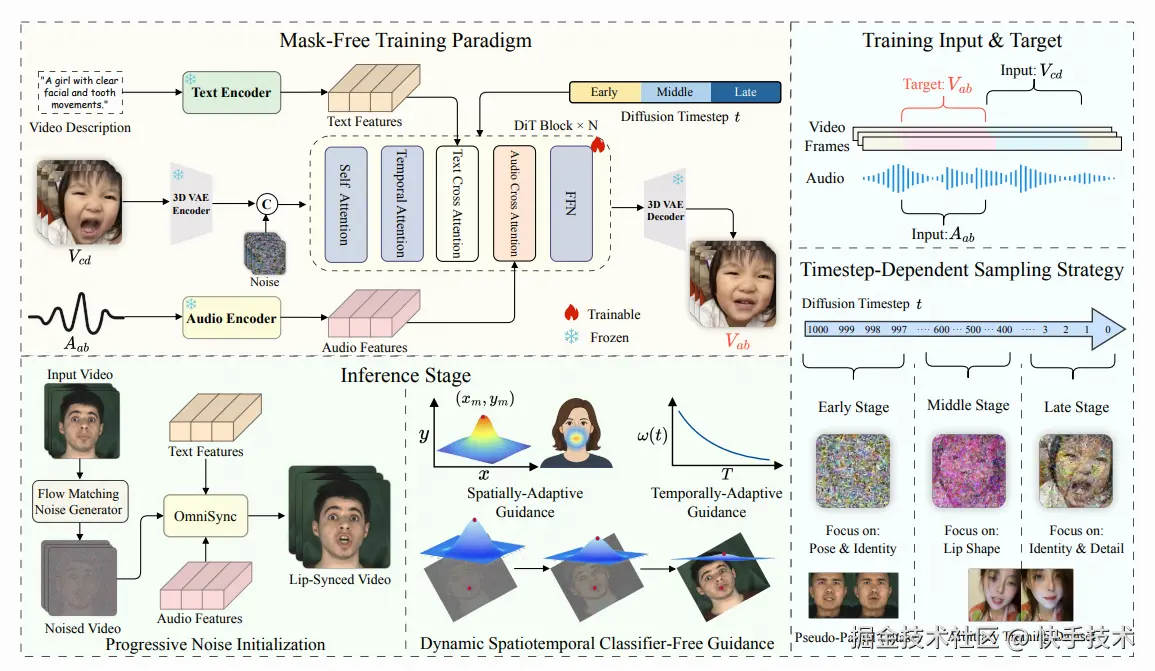
论文01:OmniSync: Towards Universal Lip Synchronization via Diffusion Transformers
| 论文链接:arxiv.org/abs/2505.21...
| 项目地址:ziqiaopeng.github.io/OmniSync/
**|****论文简介:**唇语同步技术旨在将视频中人物的唇部运动与对应的语音音频进行精准对齐,该任务对制作逼真且富有表现力的视频内容至关重要。然而现有方法普遍依赖参考图+显式掩码再修复的方案,导致其在身份一致性、姿态变化、面部遮挡及风格化内容处理上的鲁棒性受限。此外,由于音频信号提供的条件约束弱于视觉线索,原始视频中的唇形信息泄露会显著影响同步质量。本文提出了通用唇语同步框架OmniSync,通过引入基于扩散变换器模型的无掩码训练范式,实现无需显式掩码的直接帧编辑,在保持自然面部动态与角色身份的同时支持无限时长推理。推理过程中采用基于流匹配的渐进噪声初始化策略,在确保姿态与身份一致性的前提下实现精准的口型编辑。针对音频弱条件问题,创新性地开发动态时空分类器无引导机制(DS-CFG),可自适应调整时空维度的引导强度。同时构建首个面向AI生成视频的AIGC-LipSync多场景评估基准。大量实验表明,OmniSync在真实视频与AI生成视频中均显著超越现有方法,在视觉质量与唇语同步精度上均达到最优效果。
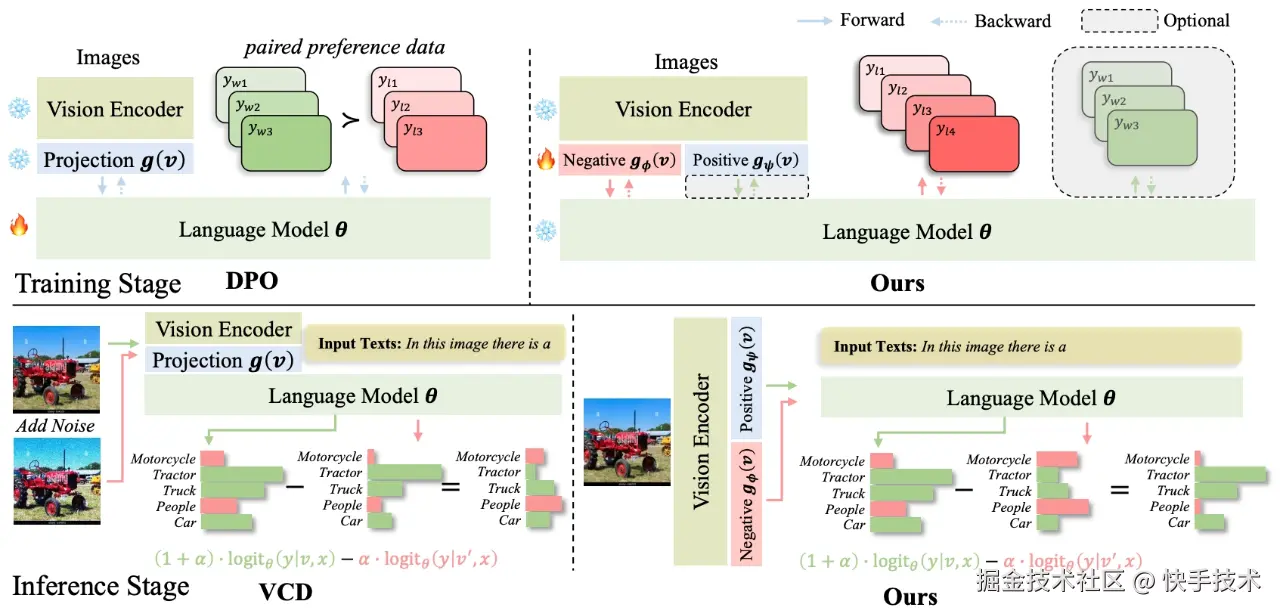
**论文02:**Decoupling Contrastive Decoding: Robust Hallucination Mitigation in Multimodal Large Language Models
| 论文链接 :arxiv.org/abs/2504.08...
**| 论文简介:**尽管多模态大型语言模型(MLLMs)在复杂的多模态理解任务中展现出了卓越的推理能力,但它们仍存在众所周知的"幻觉"问题:生成的输出与明显的视觉或事实证据不符。目前,基于训练的解决方案,如直接偏好优化(DPO),利用成对的偏好数据来抑制幻觉。然而,由于可能性位移,它们有可能牺牲一般的推理能力。同时,无需训练的解决方案,如对比解码,通过从失真的输入中减去估计的幻觉模式来实现这一目标。然而,这些手工制作的干扰(例如,向图像添加噪声)可能无法很好地捕捉真实的幻觉模式。为了避免现有方法的这些弱点,并实现"稳健"的幻觉缓解(即保持一般的推理性能),我们提出了一种新的框架:解耦对比解码(DCD)。具体而言,DCD 在偏好数据集中解耦正样本和负样本的学习,并在 MLLM 内分别训练正图像投影和负图像投影。负向投影隐式地模拟了真实的幻觉模式,这使得在对比解码推理阶段能够生成具有视觉感知的负向图像。我们的 DCD 通过避免成对优化来缓解似然位移,并且无需手工降质就能稳健地泛化。在幻觉基准测试和一般推理任务上的大量消融研究表明 DCD 的有效性,即它在抑制幻觉方面与 DPO 相当,同时保持了一般能力,并且优于手工设计的对比解码方法。
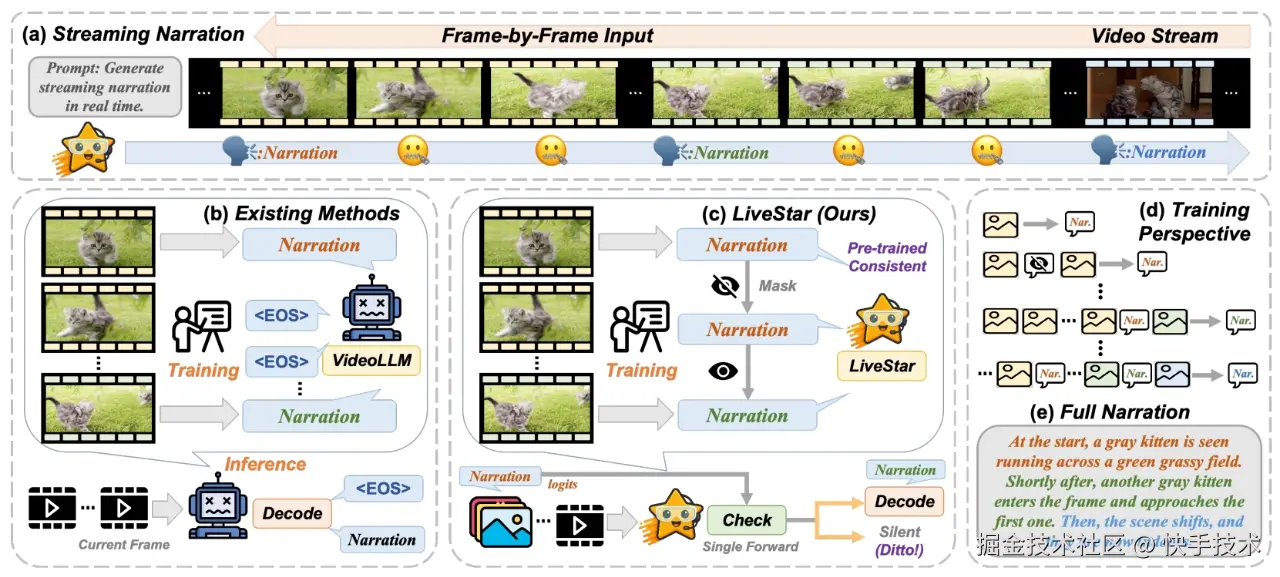
论文03:LiveStar: Live Streaming Assistant for Real-World Online Video Understanding
| 论文链接:openreview.net/forumid=4n7...
| 项目地址:github.com/yzy-bupt/Li...
**| 论文简介:**尽管离线视频理解的视频大型语言模型(Video-LLMs)取得了显著进展,但现有的在线 Video-LLMs 通常难以同时处理连续的逐帧输入并确定最佳响应时机,这往往会影响实时响应能力和叙事连贯性。为了解决这些局限性,我们推出了 LiveStar,这是一款开创性的直播助手,通过自适应流解码实现了始终在线的主动响应。具体而言,LiveStar 包含:(1)一种训练策略,能够对可变长度的视频流进行增量视频语言对齐,保持动态变化的帧序列中的时间一致性;(2)一种响应沉默解码框架,通过单次前向传递验证来确定最佳主动响应时机;(3)通过峰值末尾内存压缩实现内存感知加速,以便在 10 分钟以上的视频上进行在线推理,并结合流式键值缓存实现 1.53 倍的推理速度提升。我们还构建了一个 OmniStar 数据集,这是一个用于训练和基准测试的全面数据集,涵盖了 15 种不同的真实世界场景以及 5 项在线视频理解的评估任务。在三个基准测试中的广泛实验表明,LiveStar 达到了最先进的性能,在语义正确性方面平均提高了 19.5%,与现有的在线视频语言模型相比,时间差异减少了 18.1%,同时在 OmniStar 的所有五项任务中,每秒帧数提高了 12.0%。
**论文04:**MME-VideoOCR: Evaluating OCR-Based Capabilities of Multimodal LLMs in Video Scenarios
| 论文链接:arxiv.org/abs/2505.21...
| 项目地址:mme-videoocr.github.io/
**| 论文简介:**多模态大语言模型(MLLM)在静态图像光学字符识别(OCR)任务中已取得显著成效,然而其在视频OCR场景下的性能却因运动模糊、时序变化及视频特有的视觉效果等因素大幅受限。为给实用型MLLM训练提供明确指导,推出了涵盖全场景视频OCR应用的评估体系MME-VideoOCR。该基准包含10大类任务(共25项子任务),覆盖44种差异化场景,不仅涉及文本识别任务,更包含需要对视频文本内容进行深度理解与推理的任务类型。数据集包含1,464段不同分辨率、宽高比及时长的视频,并配有2,000组精心构建的人工标注问答对。通过对15个前沿MLLM模型的评估发现,表现最佳的模型(Gemini-2.5 Pro)在2000分满分中得分仍不足1500。细粒度分析表明:现有模型在单帧或少量帧包含目标文本的任务中表现优异,但对需要全局视频理解的任务响应能力明显不足。

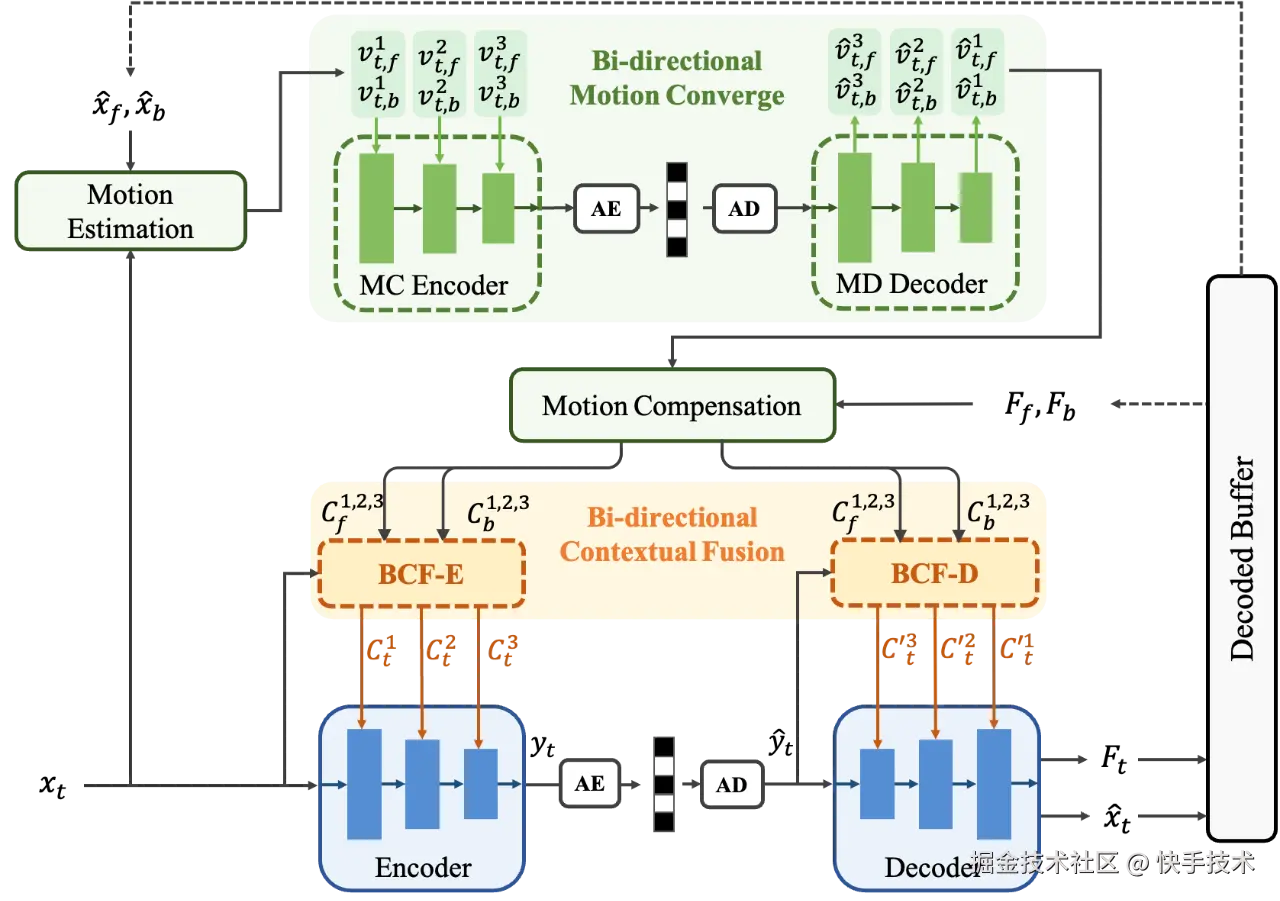
**论文05:**Neural B-frame Video Compression with Bi-directional Reference Harmonization
| 项目地址:github.com/kwai/NVC
**| 论文简介:**近年来,基于深度学习的端到端视频压缩(NVC)取得了显著进展,但与 P 帧压缩相比,对端到端视频 B 帧压缩的研究仍相对不足。B 帧压缩可采用双向参考帧以获得更优的压缩性能。然而,B 帧的分层编码结构使得时域预测变得复杂,尤其是在帧跨度较大的层级,这会导致两个参考帧的贡献不均匀。为了充分利用双向参考信息,我们提出了一种新的端到端视频 B 帧压缩方法,称为双向参考均衡的视频压缩,其结合了我们提出的双向运动聚合和双向上下文融合技术。双向运动聚合技术在运动压缩中聚合多个尺度光流,从而在大范围内实现更精确的运动补偿。然后,双向上下文融合技术在运动补偿精度的指导下,显式地对参考上下文的权重进行建模。凭借更高效的运动和上下文,我们方法可以有效地平衡双向参考信息。实验结果表明,我们的方法优于以往最先进的 NVC 方法,甚至在 HEVC 数据集上超越了传统编码器 VTM-RA 配置。
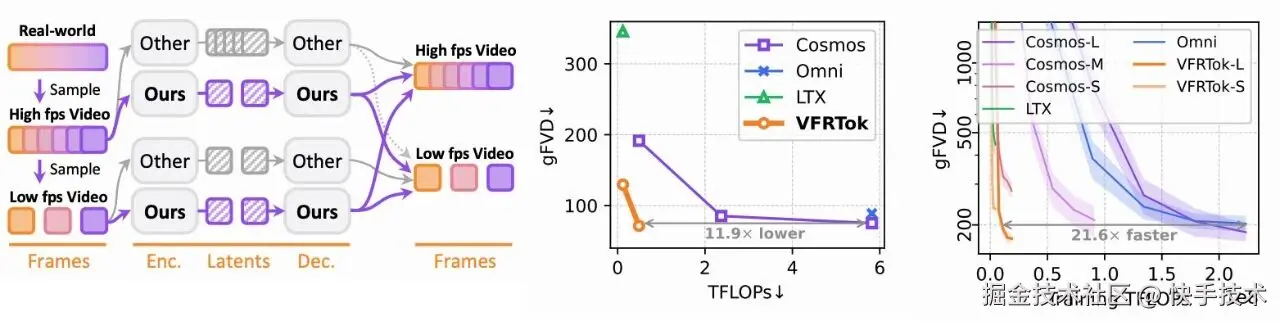
**论文06:**VFRTok: Variable Frame Rates Video Tokenizer with Duration-Proportional Information Assumption
| 论文链接:arxiv.org/abs/2505.12...
| 项目地址:github.com/KwaiVGI/VFR...
**| 论文简介:**基于潜扩散模型的现代视频生成框架,受限于帧比例信息假设而存在表征低效问题。现有分词器提供固定的时间压缩率,导致扩散模型计算成本随帧率线性增长。本文提出时长比例信息假设:视频信息容量的上限与时长而非帧数成正比。基于该洞见,推出了VFRTok------基于Transformer的视频分词器,通过编码器与解码器间的非对称帧率训练,实现可变帧率编解码。此外,本文提出部分旋转位置嵌入(Partial RoPE)技术解耦位置建模与内容建模,从而探索模型语义跟随能力。该技术有效增强内容感知能力,显著提升视频生成质量。得益于紧凑连续的时空表征,VFRTok仅需现有分词器1/8的token量即可实现具有竞争力的重建质量,并达成业界领先的生成保真度。
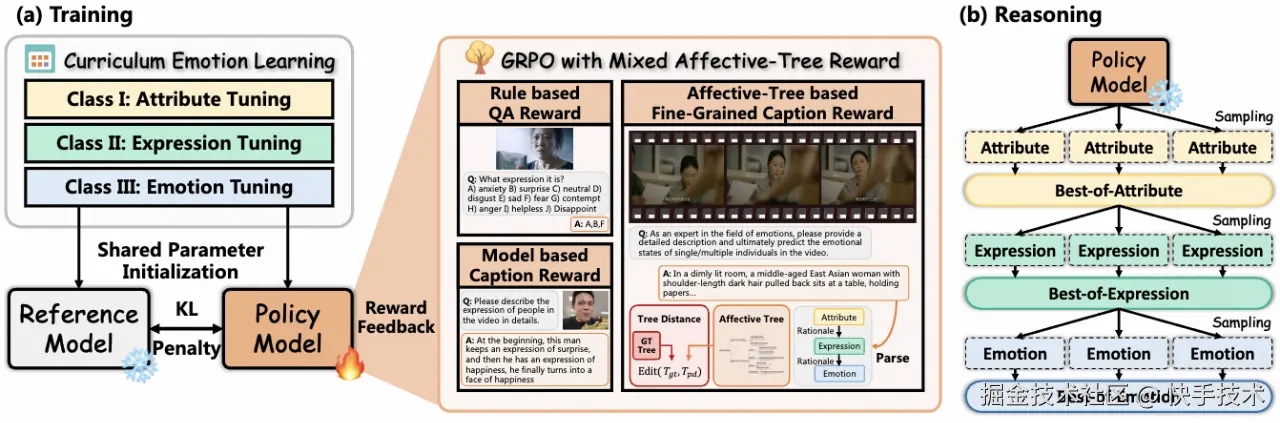
**论文07:**VidEmo: Affective-Tree Reasoning for Emotion-Centric Video Foundation Models
| 论文链接:arxiv.org/pdf/2511.02...
**| 论文简介:**尽管视频大语言模型(VideoLLMs)在视频情感分析领域取得了重要进展,但情感的动态性与依赖多种线索的复杂特性,依然对模型的推理能力提出了巨大挑战。本研究提出了情感线索引导的推理框架,系统整合了基础属性感知、表达分析与高阶情感理解三大阶段。核心在于设计了专注于情感推理与指令遵循的视频情感基础模型家族VidEmo,并通过两阶段调优策略实现性能提升:第一阶段采用课程式情感学习逐步注入情感知识,第二阶段通过情感树强化学习增强推理能力。此外,构建了情感驱动的数据基础设施,推出细粒度情感数据集Emo-CFG,涵盖2.1M多样化指令样本,包括可解释的情感问答、细粒度描述及相关推理。实验表明,VidEmo在15项人像任务中树立了新SOTA,显著提升了复杂情感状态理解的合理性与准确性。
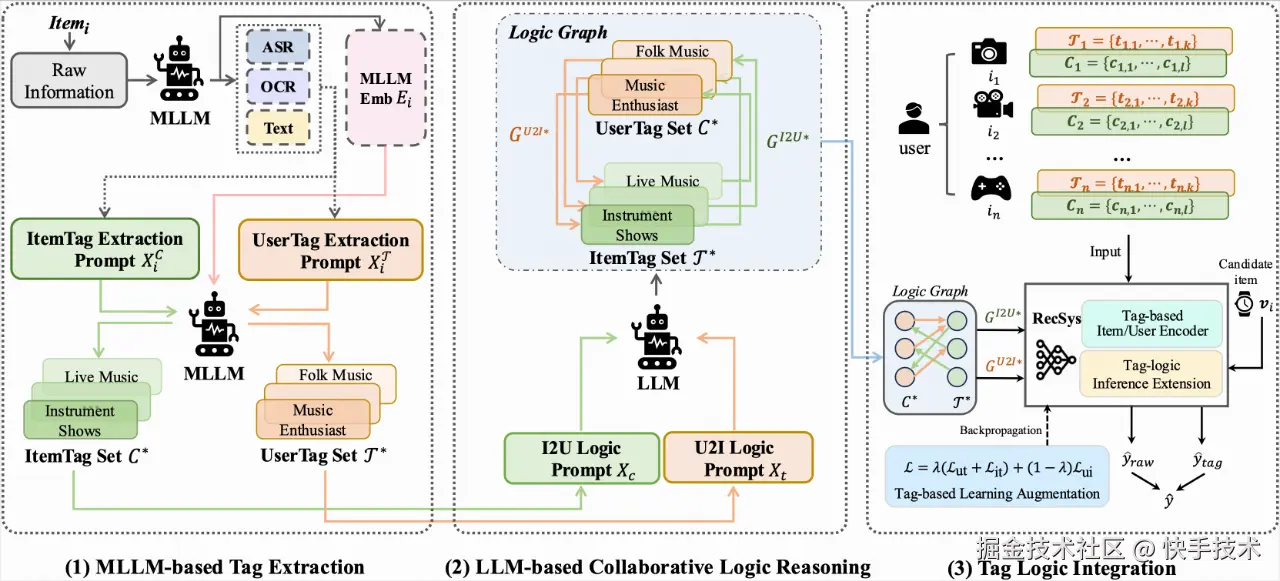
**论文08:**Who You Are Matters: Bridging Topics and Social Roles via LLM-Enhanced Logical Recommendation
| 论文链接:arxiv.org/abs/2505.10...
| 项目地址:github.com/Code2Q/TagC...
****| 论文简介:推荐系统通过推断用户特征和历史行为中的偏好,筛选出对用户有价值的内容或兴趣点。主流方法都侧重于发现和建模 item 粒度的内容兴趣点(即 topic modeling),并基于历史交互捕捉用户对这些兴趣点的偏好。这种范式虽然有效,但往往过于注重以 item 为单位的理解任务,忽视了用户粒度对特征、社交角色和其需求特性的建模,即 user role modeling 。然而,这些因素在建模上很可能是影响相关兴趣和用户偏好迁移的关键逻辑混杂因素。
**
为了弥补这一缺失的建模角度,让推荐系统从"知其然"进步到"知其所以然":1)团队引入了用户角色识别任务和行为逻辑建模任务,旨在显式建模用户角色和特性,并学习 item topic (tag) 与 user role (tag) 之间的逻辑关系,使推荐系统研究从回归社会科学本质。2)此外,文章也证明了可以通过一种高效的大语言模型(LLM)与推荐系统的集成框架来显式解决这些任务,并提出了 TagCF 方法,做到理解用户社会角色和需求的同时提升推荐效果。3)最后,作者在工业环境中的在线实验和公开数据集上的离线实验中验证了 TagCF 的有效性。实验证明,与兴趣点建模相比,用户角色建模策略可能是更优的选择。同时,文章也提供了证据表明,提取的逻辑图在经验上是一种通用且可迁移的知识,能够惠及广泛的推荐任务。
**
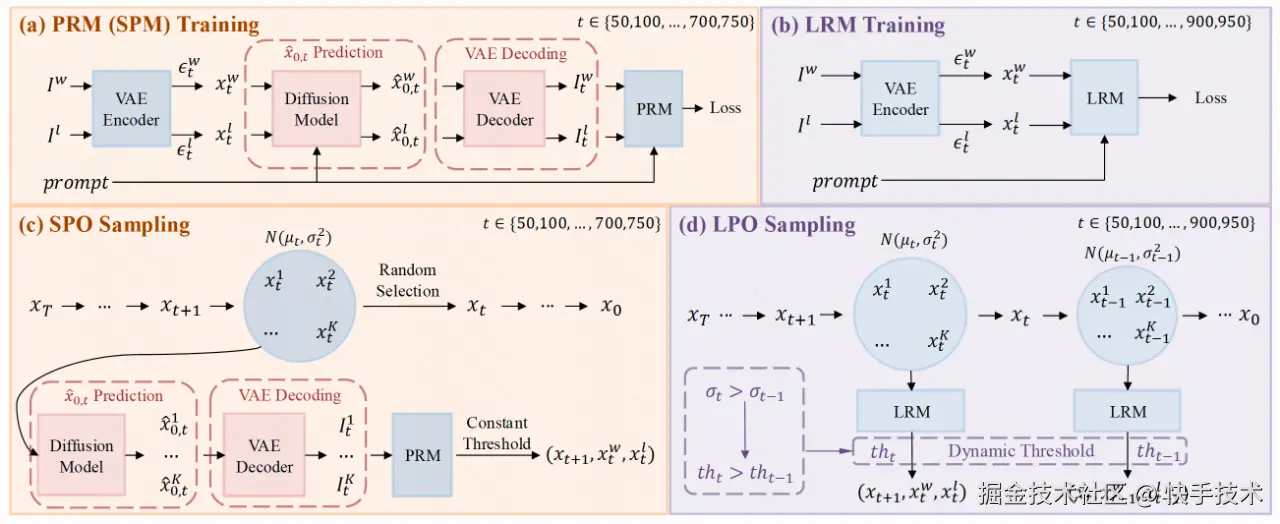
**论文09:**Diffusion Model as a Noise-Aware Latent Reward Model for Step-Level Preference Optimization
| 论文链接:arxiv.org/abs/2502.01...
| 项目地址:github.com/Kwai-Kolors...
| 论文简介:在图像生成领域,偏好优化的目标是让模型更好地符合人类的审美标准。以往的做法通常依赖视觉-语言模型(VLMs)作为像素级的奖励模型,以此来近似人类的偏好。然而,当这些模型应用于步骤级(step-aware)的偏好优化时,它们在处理不同时间步的噪声图像时常常遇到困难,并且需要复杂的转换才能回到像素空间。我们发现预训练的扩散模型在噪声潜在空间中进行步骤级奖励建模的能力非常出色,因为它们本身就是为了处理不同噪声水平的潜在图像而设计的。基于这一发现,我们提出了潜在奖励模型(Latent Reward Model, LRM),该模型利用扩散模型的组件来预测任意时间步的潜在图像偏好。在此基础上,我们推出了潜在偏好优化(Latent Preference Optimization, LPO),这是一种全新的步骤级偏好优化方法,能够直接在噪声潜在空间中进行。实验结果显示,LPO不仅显著提升了模型在整体人类偏好得分、图文相关性和图像美学质量的偏好一致性,而且在训练速度上也比现有的偏好优化方法快了2.5到28倍。
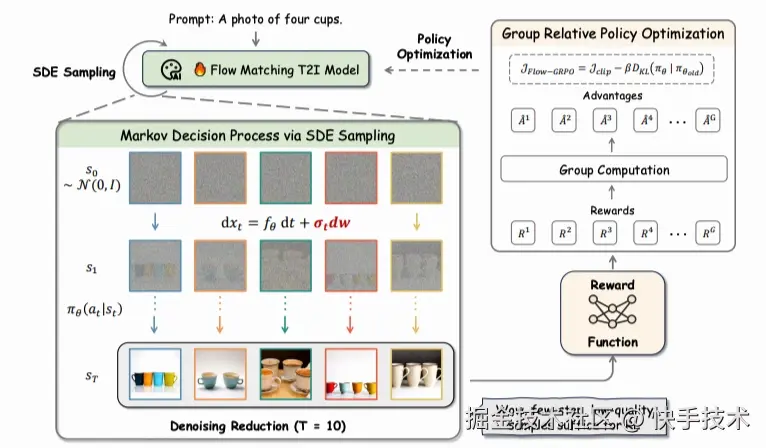
论文10: Flow-GRPO: Training Flow Matching Models via Online RL
| 论文链接:arxiv.org/abs/2505.05...
| 项目地址:github.com/yifan123/fl...
| **论文简介:**提出Flow-GRPO,这是首个将在线强化学习(RL)融入流匹配模型的方法。该方法采用两大核心策略:(1)通过ODE到SDE的转换,将确定性常微分方程(ODE)转化为等价随机微分方程(SDE),该转换过程在全部时间步上保持原始模型的边际分布一致性,为强化学习探索提供统计采样基础;(2)采用降噪步骤缩减策略,在保持原始推理步数的同时减少训练降噪步骤,显著提升采样效率且不牺牲性能。实验表明,Flow-GRPO在多项文本生成图像任务中成效显著:在组合生成任务中,经RL调优的SD3.5-M模型实现了近乎完美的物体数量、空间关系及细粒度属性生成,将GenEval准确率从63%提升至95%;在视觉文本渲染任务中,准确率从59%跃升至92%,大幅优化了文本生成质量;该方法还显著提升了人类偏好对齐度。尤为重要的是,实验基本未出现奖励作弊现象------即奖励提升未伴随可感知的图像质量下降或多样性减损。
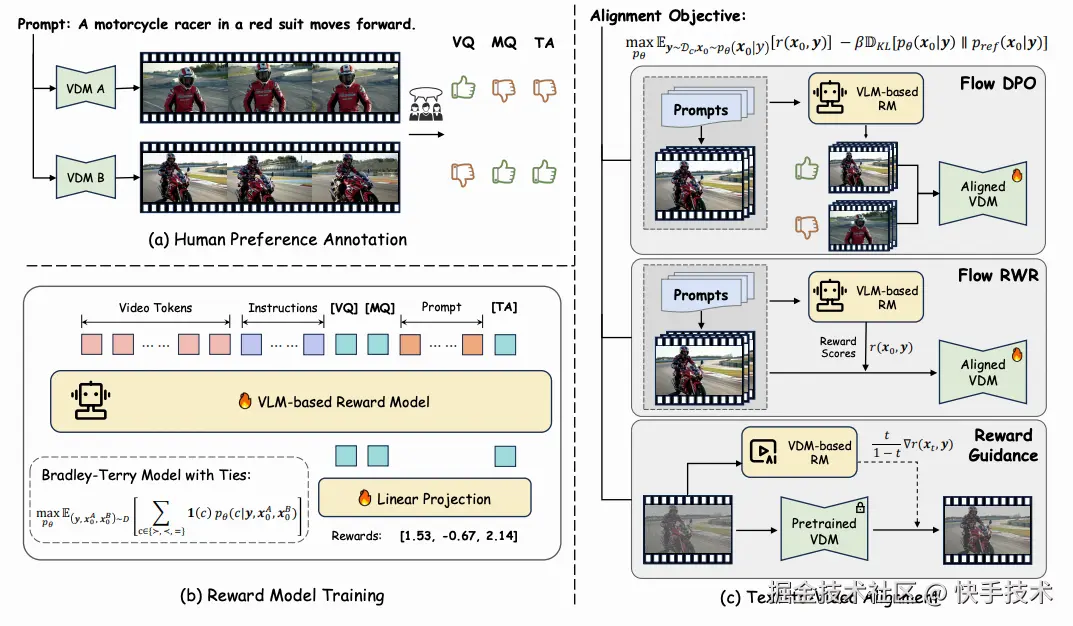
论文11:Improving Video Generation with Human Feedback
| 论文链接:arxiv.org/abs/2501.13...
| 项目地址:gongyeliu.github.io/videoalign/
| **论文简介:**尽管flow matching技术推动视频生成取得重大进展,但运动质量不佳及文本遵循等问题依然存在。本研究构建了系统性流程,利用人类反馈优化视频生成模型优化上述问题。具体而言,首先构建了针对现代视频生成模型的大规模人类偏好数据集,涵盖多维度的成对标注;随后提出VideoReward多维度视频奖励模型,深入探究标注方案与不同设计选择对奖励效能的影响。基于统一强化学习框架------即在KL正则化约束下实现奖励最大化,为基于流的模型提出三种对齐算法:包括两种训练时策略(直接偏好优化Flow-DPO、奖励加权回归Flow-RWR),以及一种推理时技术Flow-NRG,该技术将奖励引导直接应用于含噪视频。实验表明:VideoReward显著超越现有奖励模型,Flow-DPO性能优于Flow-RWR及监督微调方法;此外Flow-NRG支持用户在推理时自定义多目标权重,满足个性化视频质量需求。
论文12:MVU-Eval: Towards Multi-Video Understanding Evaluation for Multimodal LLMs
| 论文链接:arxiv.org/abs/2511.07...
| 项目地址:huggingface.co/datasets/MV...
| **论文简介:**多模态大语言模型(MLLM)的出现将人工智能能力扩展至视觉领域,然而现有评估基准仍局限于单一视频理解,忽视了现实场景(如体育赛事分析与自动驾驶)中对多视频理解的迫切需求。为弥补这一重要空白,推出了首个综合性评估基准MVU-Eval,专门用于评测MLLM的多视频理解能力。该基准主要通过1,824组跨领域精选问答对(覆盖4,959段视频)评估八项核心能力,涵盖基础感知任务与高阶推理任务。这些能力严格对标自动驾驶中的多传感器信息合成、体育赛事多视角分析等实际应用场景。通过对前沿开源与闭源模型的广泛评测,揭示了当前MLLM在多视频理解能力方面存在的显著性能差距与局限。本基准数据集已公开共享,以推动未来研究发展。

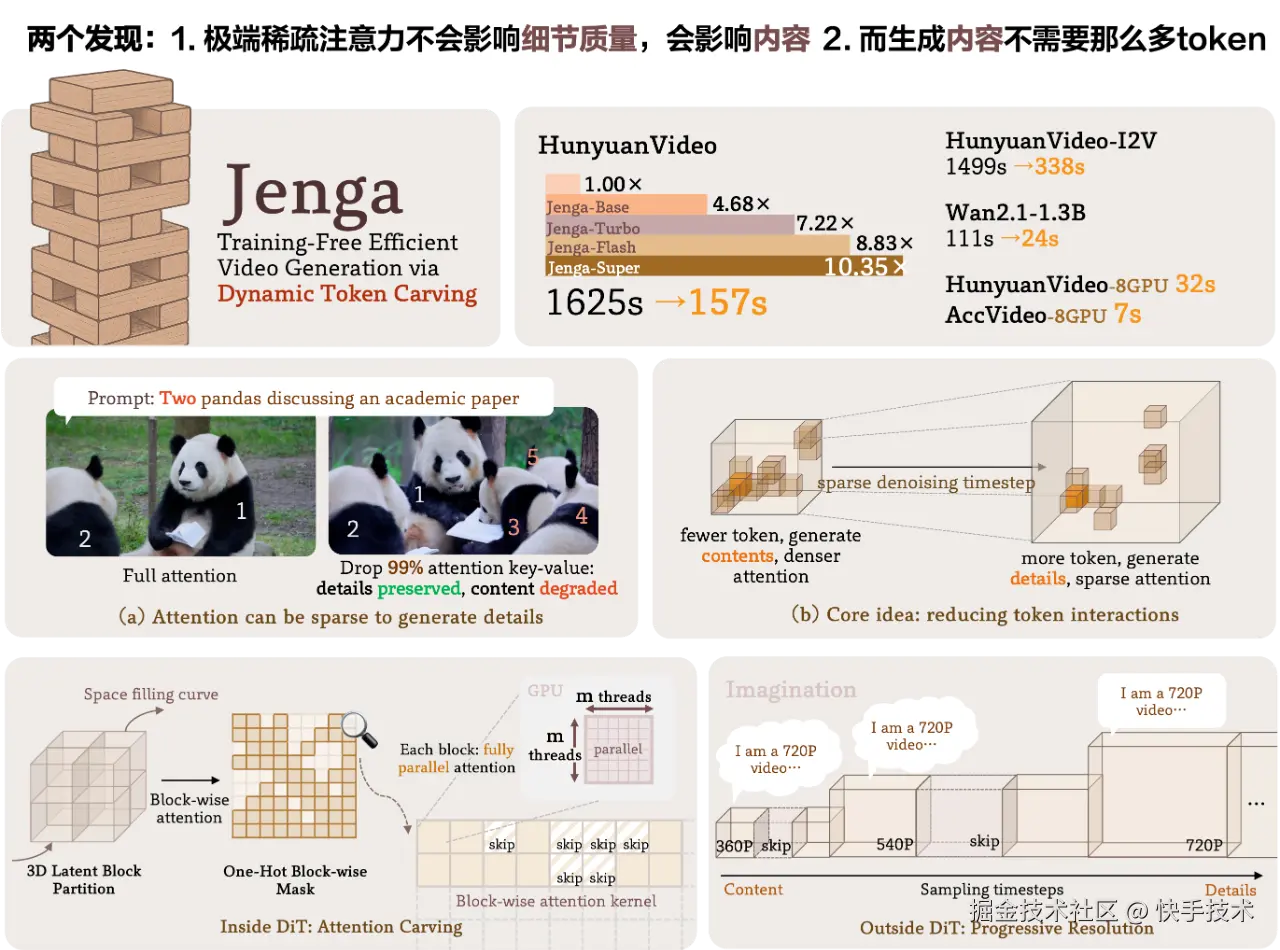
论文13:Training-Free Efficient Video Generation via Dynamic Token Carving
| 论文链接:arxiv.org/abs/2505.16...
| 项目地址:julianjuaner.github.io/projects/je...
**| 论文简介:**尽管视频扩散变换器(DiT)模型展现出卓越的生成质量,但其实际部署因庞大的计算需求而受到严重阻碍。这种低效性源于两个关键挑战:自注意力机制相对于令牌长度的二次方复杂度,以及扩散模型固有的多步生成特性。为突破这些限制,提出了Jenga------一种创新推理框架,整合了动态注意力雕刻与渐进式分辨率生成技术。该方法基于两个核心洞见:(1) 早期去噪步骤无需高分辨率潜在表征;(2) 后期步骤无需密集注意力计算。Jenga通过基于3D空间填充曲线的块状注意力机制动态筛选关键令牌交互,同时采用渐进分辨率策略在生成过程中逐步提升潜在表征清晰度。实验表明,Jenga在多个前沿视频扩散模型上实现显著加速(在VBench基准测试中取得8.83倍加速且性能仅下降0.01%)。作为即插即用解决方案,Jenga无需模型重训练即可将推理时延从数分钟缩短至秒级,使现代硬件设备能够实现实用化的高质量视频生成。
快手展位速览
全球顶会 NeurIPS 2025 已就位,快手带着众多前沿技术干货等你来! 现场更有设计感拉满的 token 实体卡、定制款冰箱贴等专属礼品,到场互动就能收入囊中~期待和每一位热爱技术的你,在会场碰撞思想火花,共探 AI 未来!
NeurIPS 2025 会场平面图

定制款冰箱贴
结语
作为一家以人工智能为核心驱动力和技术依托的科技公司,快手致力于持续深化研发投入,将技术打造为驱动业务增长的强劲引擎。同时,公司将在人工智能领域不断探索,积极推动前沿技术在业务场景中的落地应用。欲获取相关论文的详尽内容与深度解读,敬请关注快手技术公众号的后续更新。