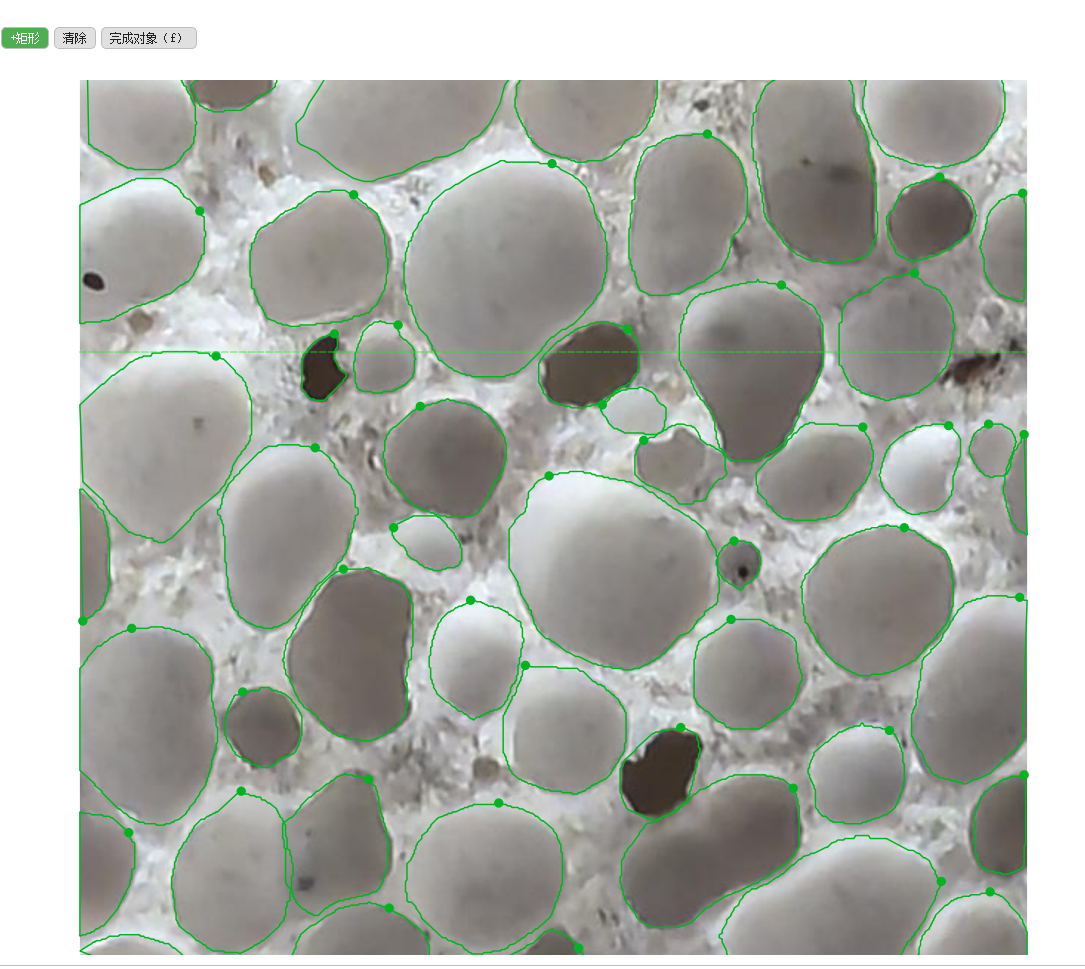
有一个工程,从相机获取到训练图的尺寸是4096*3072像素,图上有很多密集的小目标,用anylabeling进行标注后,送进YOLO训练时出了问题,由于电脑显存不大,如果用原图尺寸训练,即使很小的batch_size,也会显存溢出,如果用YOLO默认的imgsz=640,则由于缩小倍数过大,小目标被过度压缩,造成学习效果不佳。解决问题的办法是将大图裁切成小图(640*640)后再训练,下面的脚本实现了这个目的,并且在裁切图片的同时将已经标注好的数据随图片裁切。
python
import copy
import json
import cv2
import os
from pathlib import Path
# 将图像尺寸调整为640的倍数
def split_image_into_blocks(image_path, output_dir, block_width=640, block_height=640):
# 创建输出目录
os.makedirs(output_dir, exist_ok=True)
# 读取图片
image = cv2.imread(image_path)
if image is None:
raise ValueError(f"无法读取图片: {image_path}")
# 调整图片尺寸
height, width = image.shape[:2]
_, b = divmod(width, block_width)
w_out = width + block_width - b # 调整为640的倍数
_, b = divmod(height, block_height)
h_out = height + block_height - b # 调整为640的倍数
img = cv2.resize(image, (w_out, h_out), interpolation=cv2.INTER_CUBIC)
# 放大比例
w_scale = w_out / width
h_scale = h_out / height
# 获取同名json文件
file_name = Path(image_path).stem
with open(file_name + '.json', encoding="utf-8") as f:
json_data = json.load(f) # 同名图片文件的json数据
# 获取图片尺寸
height, width = img.shape[:2]
print(f"调整后的大图片尺寸: 宽{width} x 高{height}")
print(f"分割块尺寸: 宽{block_width} x 高{block_height}")
# 计算可以分割的块数(按完整块计算)
num_blocks_width = width // block_width
num_blocks_height = height // block_height
print(f"将分割为 {num_blocks_width}x{num_blocks_height} 个图片块")
# 分割并保存块
block_count = 0
for i in range(num_blocks_height):
for j in range(num_blocks_width):
# 计算当前块的坐标(左上角开始)
start_x = j * block_width
start_y = i * block_height
end_x = start_x + block_width
end_y = start_y + block_height
# 提取图片块
block = img[start_y:end_y, start_x:end_x]
# 保存图片块(文件名包含行列信息)
block_filename = os.path.join(
output_dir,
f"{file_name}_row{i}_col{j}_index{block_count}.jpg"
)
json_filename = os.path.join(
output_dir,
f"{file_name}_row{i}_col{j}_index{block_count}.json"
)
cv2.imwrite(block_filename, block)
# 更新json文件
data= copy.deepcopy(json_data)
for shape in data['shapes']:
points = []
for point in shape['points']:
w = round(point[0] * w_scale, 0) - start_x # 坐标按照小块的0点重新定位
h = round(point[1] * h_scale, 0) - start_y
if 0 <= w <= block_width and 0 <= h <= block_height: # 如果坐标在小块内,则添加到points中
points.append([w, h])
# 如果points的长度大于20,则保留,否则删除
if len(points) > 20:
shape['points'] = points
else:
shape['points'] = []
data['shapes'] = [item for item in data['shapes'] if item['points'] != []] # 删除points为空的形状
data['imagePath'] = f"{file_name}_row{i}_col{j}_index{block_count}.jpg" # 更新图片路径
data['imageHeight'] = block_height # 更新图片高度
data['imageWidth'] = block_width # 更新图片宽度
# 更新json文件
with open(json_filename, 'w', encoding="utf-8") as f:
json.dump(data, f)
block_count += 1
print(f"分割完成,共生成 {block_count} 个块")
if __name__ == "__main__":
# 替换为你的图片路径
input_image_path = "img00002.jpg"
split_image_into_blocks(
image_path=input_image_path, output_dir='custom_blocks')标注好的大图(4096*3072像素):
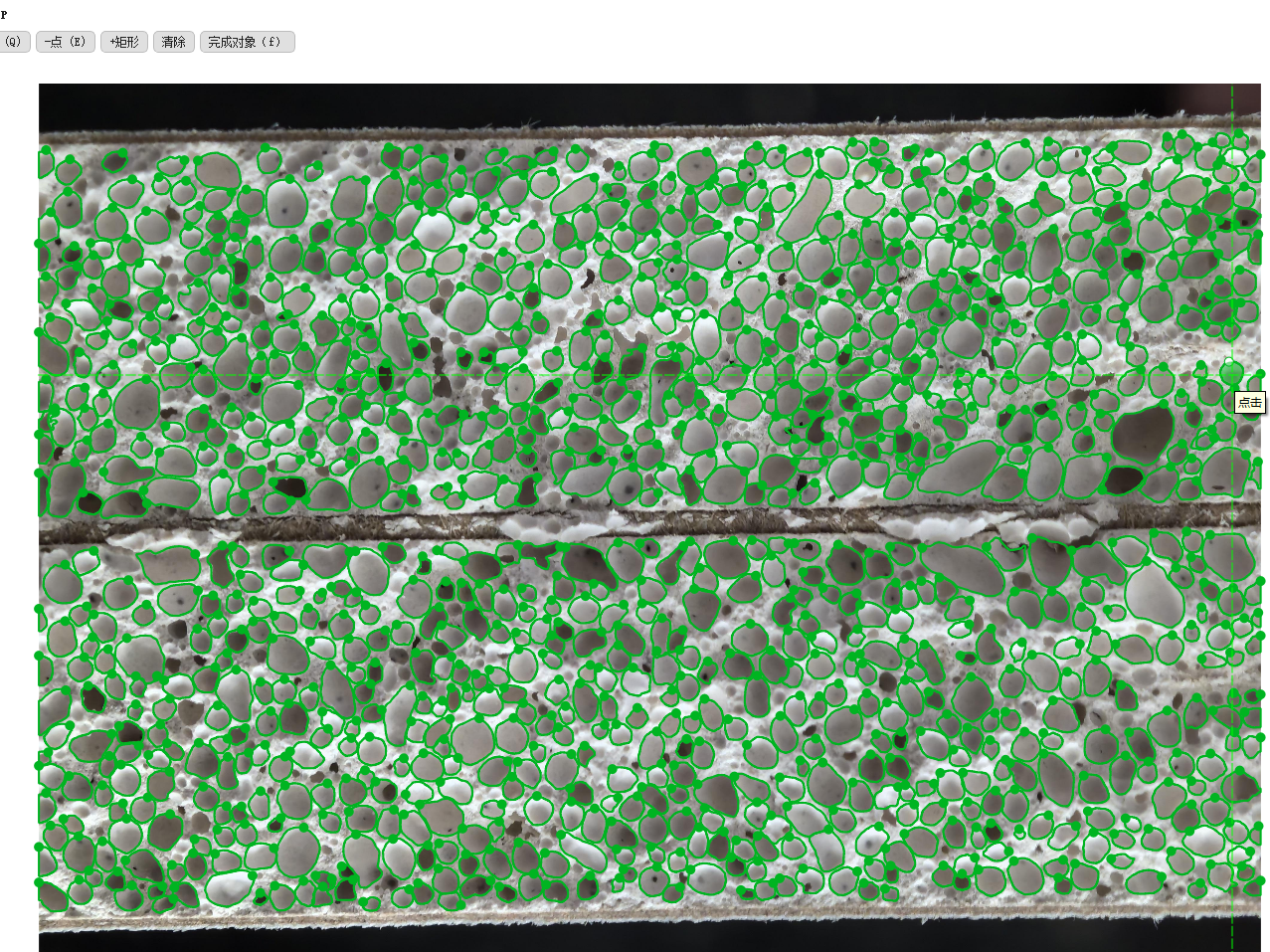
裁切得到的其中一张小图(640*640像素):