本软件工具仅限于学术交流使用,严格遵循相关法律法规,符合平台内容合法合规性,禁止用于任何商业用途!
一、背景介绍
1.1 爬取目标
您好!我是 @马哥python说 ,一枚10年+程序猿,现全职独立开发。
我用Python独立开发了一款爬虫软件:爬油管评论软件。作用是:爬取油管指定视频下的评论数据,支持批量视频的采集。
包含10个关键字段:
scss
1. cid(评论id)
2. text(评论内容)
3. time(评论时间_相对)
4. author(评论者昵称)
5. channel(评论者频道)
6. votes(评论点赞数)
7. replies(评论回复数)
8. time_parsed(评论时间转换)
9. time2(评论时间_绝对)
10. video_id(视频id)软件是通过调用YouTube的网页接口,不是模拟操作浏览器,所以稳定性较高!
开发成界面软件的目的:方便不懂编程代码的小白用户使用,无需安装python,无需改代码,双击打开即用! 软件运行界面: 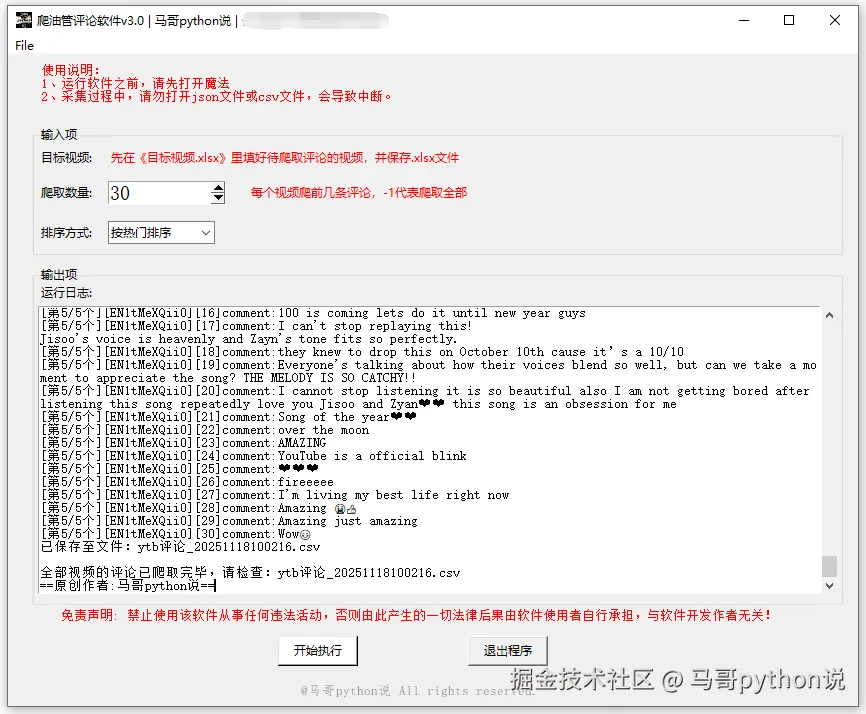
《目标视频.xlsx》模板中的填写: 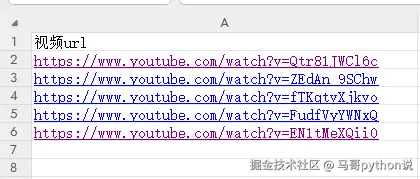
也就是说,在目标视频文件中填入了5个待爬视频,然后在软件界面上选择爬这5个视频的前30条热门评论。所以,采集结果csv文件中会自动导出150条热门评论,如下:
爬取结果截图: 
以上。
1.2 演示视频
软件使用过程演示:
1.3 软件说明
几点重要说明:
- 专为文科生研发,Win系统、Mac系统均可直接运行,无需配置python环境
- 软件通过接口爬取,并非通过模拟浏览器等RPA类工具,稳定性较高!
- 软件运行完成后,会在当前文件夹(即,软件所在文件夹)生成csv结果文件
- 爬取过程中,每爬一页,存一次结果。并非爬完最后一次性保存!防止因异常中断导致丢失前面的数据(每页请求间隔1~2s)
- 爬取过程中,有log文件详细记录运行过程,方便回溯
- 采集结果有10个字段,含:cid(评论id),text(评论内容),time(评论时间_相对),author(评论者昵称),channel(评论者频道),votes(评论点赞数),replies(评论回复数),time_parsed(评论时间转换),time2(评论时间_绝对),video_id(视频id)
以上。
二、代码概要
2.1 调用接口
为保护软件原创版权,不开放核心爬虫逻辑代码。
最后,把json数据转出到csv文件:
python
self.tk_show('[第{}/{}个][{}][{}]comment:{}'.format(video_idx, video_id_total, video_id, cnt, comment['text']))
with open('./jsons/{}.json'.format(video_id), 'a+', encoding='utf-8') as f:
f.write(json.dumps(comment, ensure_ascii=False))
f.write('\n')我采用csv库保存结果,实现每爬一条存一次,防止中途异常停止丢失前面的数据。
完整代码中,还含有:读取配置判断、循环结束条件判断、拼接频道URL、try异常保护、日志记录等关键实现逻辑。
另外,魔法是一切的前提,此处不便多说!
2.2 软件界面模块
主窗口部分:
python
# 创建主窗口
root = tk.Tk()
root.title('爬油管评论软件v3.0 | 马哥python说 |')
# 设置窗口大小
root.minsize(width=850, height=650)
# 左上角图标
root.iconbitmap('mage.ico')输入控件部分:
python
# 爬取数量
tk.Label(root, text='爬取数量:').place(x=30, y=125)
comment_num = tk.Spinbox(root, from_=-1, to=9999999, increment=1, width=10, font=('微软', 15))
comment_num.place(x=100, y=125, anchor='nw')
tk.Label(root, fg='red', text='每个视频爬前几条评论,-1代表爬取全部').place(x=240, y=125)运行日志部分:
python
# 运行日志
tk.Label(root, justify='left', text='运行日志:').place(x=30, y=280)
show_list_Frame = tk.Frame(width=780, height=260) # 创建<消息列表分区>
show_list_Frame.pack_propagate(0)
show_list_Frame.place(x=30, y=310, anchor='nw') # 摆放位置底部版权部分:
python
# 版权信息
copyright = tk.Label(root, text='@马哥python说 All rights reserved.', font=('仿宋', 10), fg='grey')
copyright.place(x=290, y=625)以上。
2.3 日志模块
好的日志功能,方便软件运行出问题后快速定位原因,修复bug。 日志核心代码:
python
def get_logger(self):
self.logger = logging.getLogger(__name__)
# 日志格式
formatter = '[%(asctime)s-%(filename)s][%(funcName)s-%(lineno)d]--%(message)s'
# 日志级别
self.logger.setLevel(logging.DEBUG)
# 控制台日志
sh = logging.StreamHandler()
log_formatter = logging.Formatter(formatter, datefmt='%Y-%m-%d %H:%M:%S')
# info日志文件名
info_file_name = time.strftime("%Y-%m-%d") + '.log'
# 将其保存到特定目录
case_dir = r'./logs/'
info_handler = TimedRotatingFileHandler(filename=case_dir + info_file_name,
when='MIDNIGHT',
interval=1,
backupCount=7,
encoding='utf-8')日志文件: 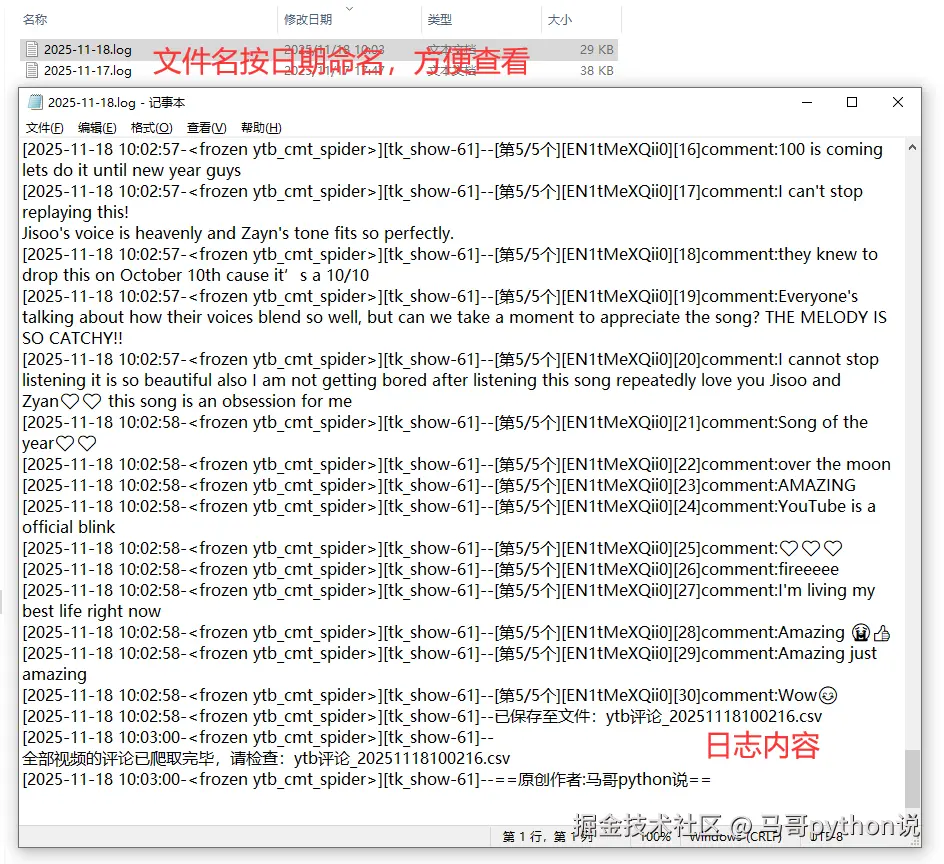
以上。
END、原创声明
工具【爬油管评论软件】首发于众公号"老男孩的平凡之路",软件仅限于学术交流技术探讨,请勿用于商业用途!