新版 Claude Opus 4.6 在编码能力上超越了前代产品。它规划更周密,能够更长时间地执行代理任务,在大规模代码库中运行更可靠,并且拥有更强大的代码审查和调试能力,可以更有效地发现自身错误。此外,Opus 4.6 还首次在测试版中加入了 100 万个 token 的上下文窗口,这在 Opus 系列模型中尚属首次。
Opus 4.6 还能将其增强的功能应用于一系列日常工作任务:运行财务分析、进行研究以及使用和创建文档、电子表格和演示文稿。在Cowork 环境中,Claude 可以自主地执行多任务,Opus 4.6 可以代表您运用所有这些技能。
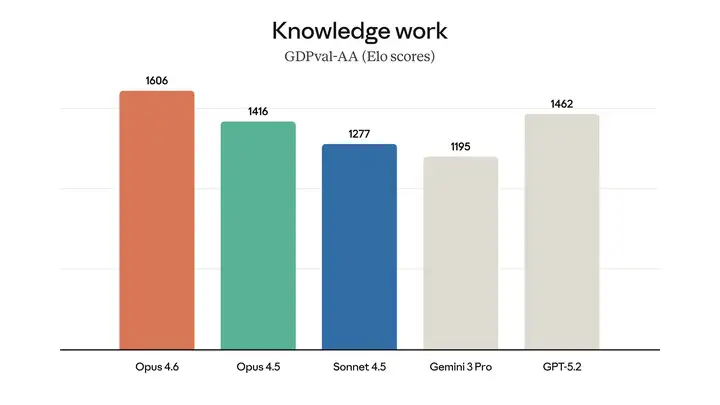
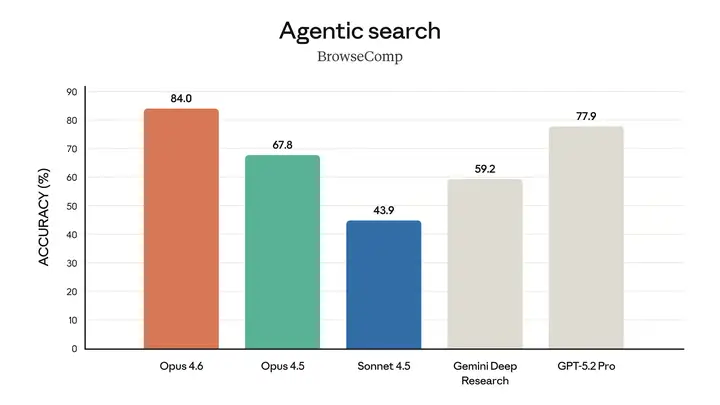
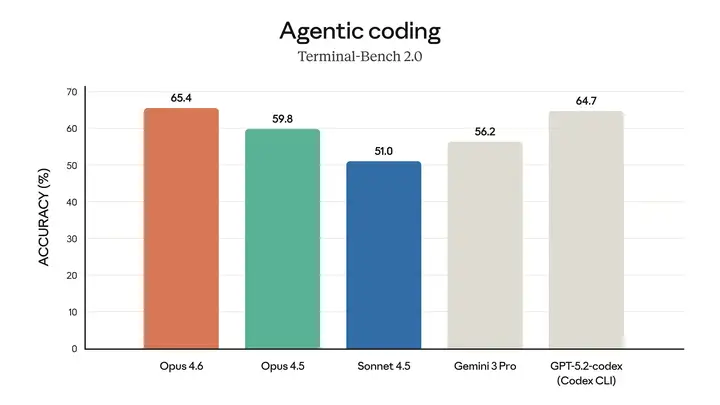
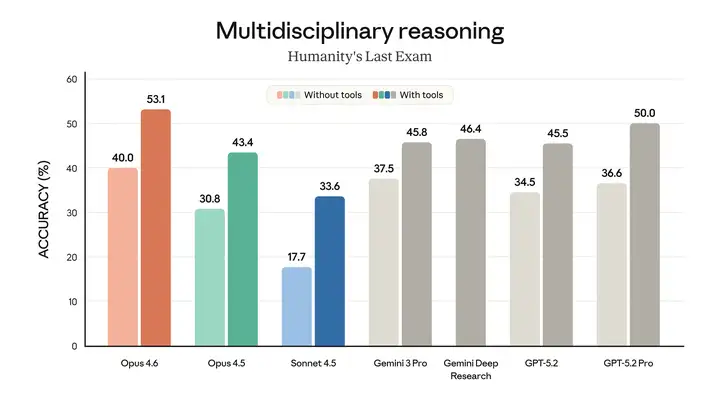
该模型在多项评估中均表现卓越。例如,它在智能体编码评估工具Terminal-Bench 2.0中取得了最高分,并在"人类最后的考试 (Humanity's Last Exam)" (一项复杂的多学科推理测试)中领先于所有其他前沿模型。在GDPval-AA (一项评估模型在金融、法律和其他领域具有经济价值的知识工作任务中表现的评估1)中,Opus 4.6 的性能比业界次优模型(OpenAI 的 GPT-5.2)高出约 144 个 Elo 分数2,比其前身(Claude Opus 4.5)高出 190 分。此外,Opus 4.6 在BrowseComp 测试中也优于其他所有模型,该测试用于衡量模型在线查找难寻信息的能力。
正如我们在详尽的系统卡 (System Card)中所展示的那样,Opus 4.6 的整体安全性能也与业内任何其他前沿模型一样好,甚至更好,在安全评估中出现不一致性行为的比例很低。
添加图片注释,不超过 140 字(可选)
Opus 4.6 在多个专业领域的实际工作任务中都达到了最先进的水平。
添加图片注释,不超过 140 字(可选)
Opus 4.6 在深度、多步骤代理搜索方面获得了业内最高分。
添加图片注释,不超过 140 字(可选)
Opus 4.6 在现实世界的智能体编码和系统任务方面表现出色。
添加图片注释,不超过 140 字(可选)
Opus 4.6 扩展了专家级推理的边界。
在 Claude Code 中,您现在可以组建代理团队 ( agent teams)来协同完成任务。在 API 方面,Claude 可以利用压缩技术来概括自身上下文,从而执行耗时更长的任务而不会触及性能限制。我们还引入了自适应思考功能,该模型能够根据上下文线索来判断如何运用其扩展思维,并新增了Effort控制功能,使开发者能够更好地控制智能、速度和成本。
我们对 Excel 版 Claude进行了大幅升级,并发布了PowerPoint 版 Claude 的研究预览版。这使得 Claude 更能胜任日常工作。
Claude Opus 4.6 现已在claude.ai 、我们的 API 以及所有主流云平台上线。如果您是开发者,请通过Claude API使用 claude-opus-4-6。定价保持不变,每百万token 5 美元/25 美元;详情请参阅我们的定价页面。

添加图片注释,不超过 140 字(可选)
下面我们将深入介绍该模型、我们的新产品更新、我们的评估以及我们广泛的安全测试。
第一印象
我们用 Claude 构建 Claude。我们的工程师每天都使用 Claude Code 编写代码,每个新模型都会首先在我们自己的工作中进行测试。在 Opus 4.6 版本中,我们发现该模型无需指令即可将注意力集中在任务中最具挑战性的部分,快速完成较为简单的部分,更好地判断如何处理模糊问题,并在长时间工作中保持高效。
Opus 4.6 通常会进行更深入的思考,并在最终确定答案前仔细地回顾其推理过程。这在处理更复杂的问题时能取得更好的结果,但在处理较简单的问题时可能会增加计算成本和延迟。如果您发现模型在处理特定任务时思考过度,我们建议您将模型的Effort从默认设置(高)调低至中等。您可以使用 /effort参数轻松控制此设置。
对Claude Code 4.6的评价
在智能体编码、计算机使用、工具使用、搜索和金融等领域,Opus 4.6 都是业界领先的模型,而且往往优势显著。下表展示了 Claude Opus 4.6 与我们之前的模型以及其他行业模型在各种基准测试中的对比情况。
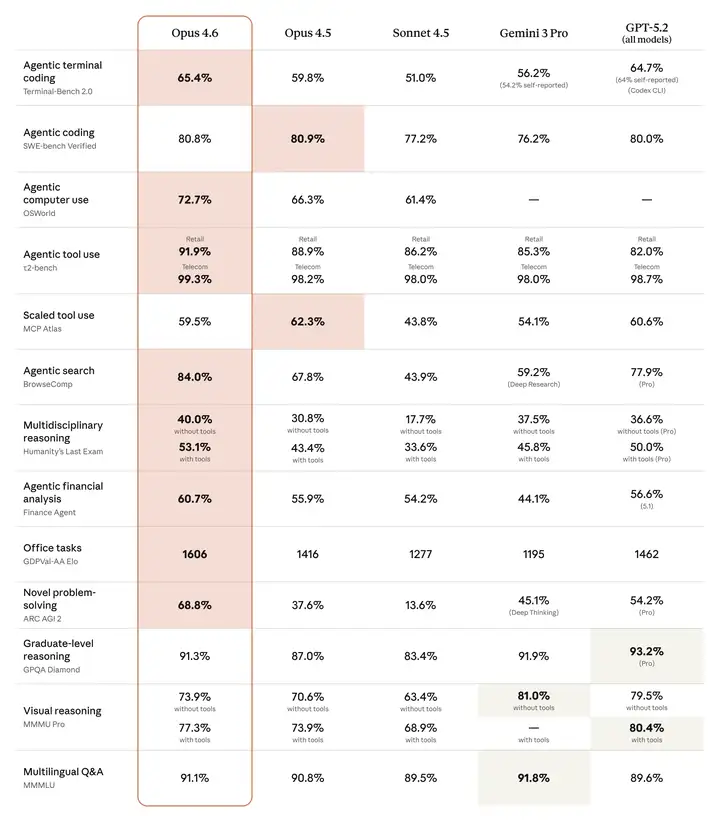
添加图片注释,不超过 140 字(可选)
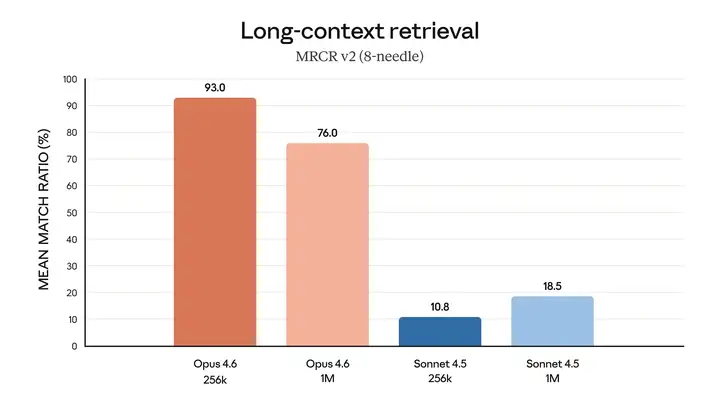
Opus 4.6 在从大型文档集中检索相关信息方面表现更佳。这同样适用于长上下文任务,它能够存储和跟踪数十万个 token 的信息,且偏差更小,甚至还能捕捉到 Opus 4.5 都无法发现的隐藏细节。
人工智能模型的一个常见诟病是"上下文腐烂 (context rot)",即当对话的 token 数量超过一定阈值时,模型性能会下降。Opus 4.6 的性能显著优于其前代产品:在MRCR v2的 8-needle 1M 变体测试中------该测试如同大海捞针,旨在检验模型从海量文本中检索"隐藏"信息的能力------Opus 4.6 的得分为 76%,而 Sonnet 4.5 的得分仅为 18.5%。这标志着模型在保持最佳性能的同时,能够利用的上下文信息量发生了质的飞跃。
总而言之,Opus 4.6 更擅长在长篇上下文中查找信息,更擅长在吸收信息后进行推理,并且总体上具有更出色的专家级推理能力。
添加图片注释,不超过 140 字(可选)
Opus 4.6 在长上下文检索方面表现出显著的改进。
添加图片注释,不超过 140 字(可选)
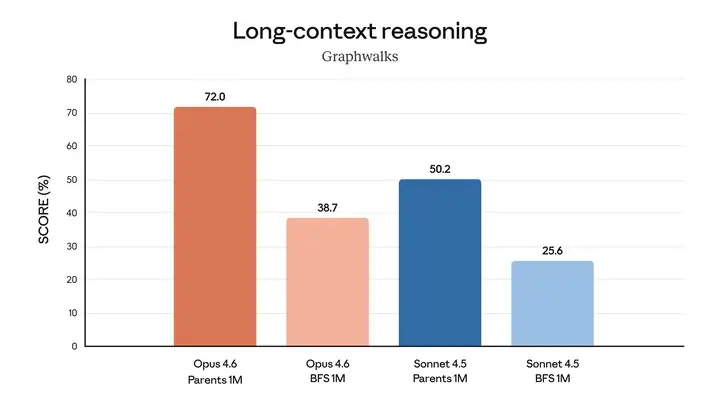
Opus 4.6 擅长在长篇背景下进行深度推理。 最后,下图显示了 Claude Opus 4.6 在各种基准测试中的表现,这些基准测试评估了其软件工程技能、多语言编码能力、长期一致性、网络安全能力和生命科学知识。
添加图片注释,不超过 140 字(可选)
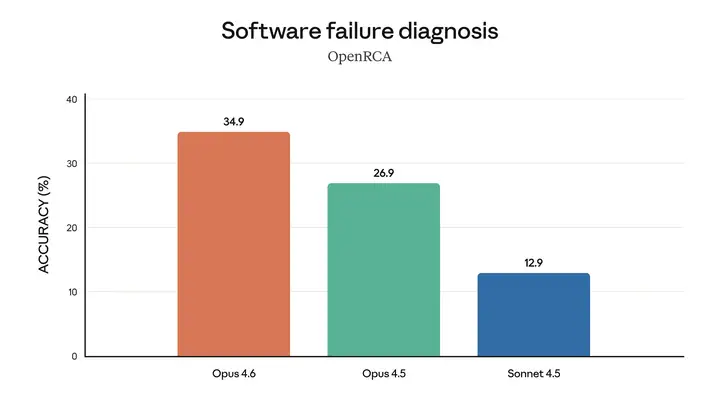
Opus 4.6 擅长诊断复杂的软件故障。
添加图片注释,不超过 140 字(可选)
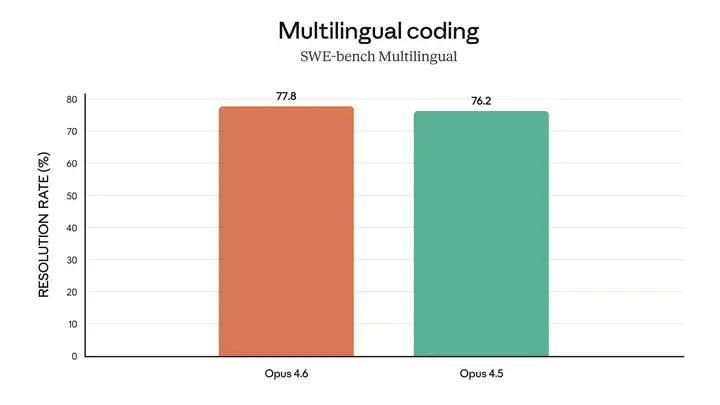
Opus 4.6 解决了跨编程语言的软件工程问题。
添加图片注释,不超过 140 字(可选)
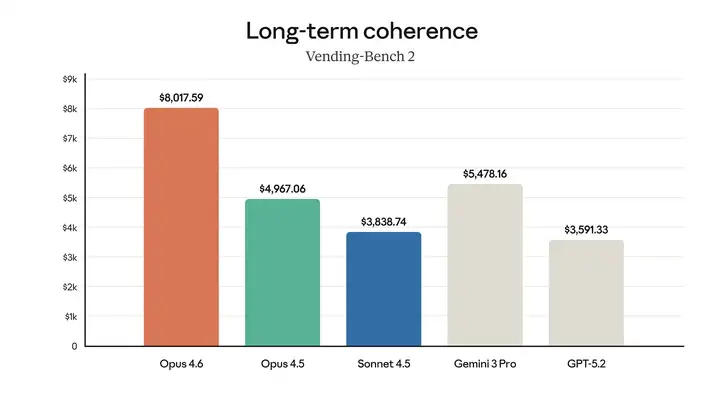
Opus 4.6 能够持续保持专注,并且在 Vending-Bench 2 上比 Opus 4.5 多赚 3,050.53 美元。
添加图片注释,不超过 140 字(可选)
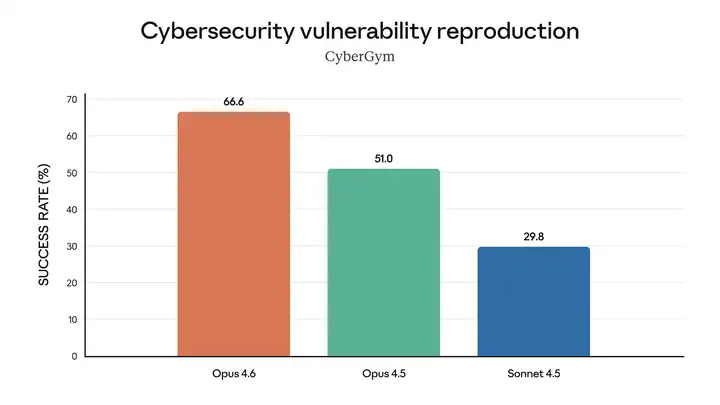
Opus 4.6 比任何其他模型都能更好地发现代码库中的真正漏洞。
添加图片注释,不超过 140 字(可选)
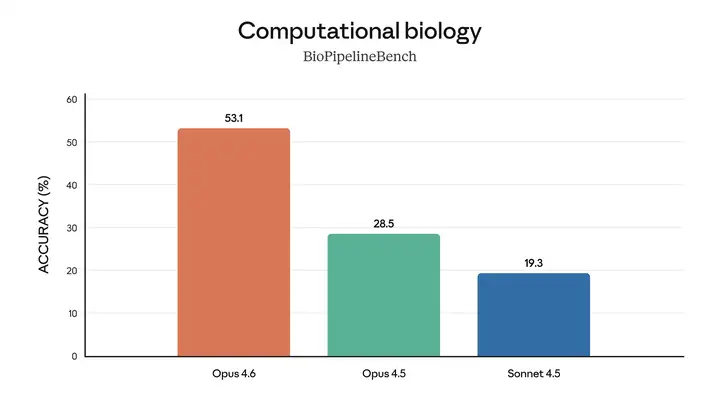
Opus 4.6 在计算生物学、结构生物学、有机化学和系统发育测试中表现比 Opus 4.5 好近 2 倍。
安全方面向前迈进了一步
这些智能提升并未以牺牲安全性为代价。在我们的自动化行为审计中,Opus 4.6 表现出较低的不匹配行为发生率,例如欺骗、奉承、诱导用户产生错觉以及与滥用行为合作。总体而言,它的匹配度与前代产品 Claude Opus 4.5 一样出色,后者是我们迄今为止匹配度最高的前沿模型。Opus 4.6 的过度拒绝率(即模型无法回答良性查询)也是所有近期 Claude 模型中最低的。
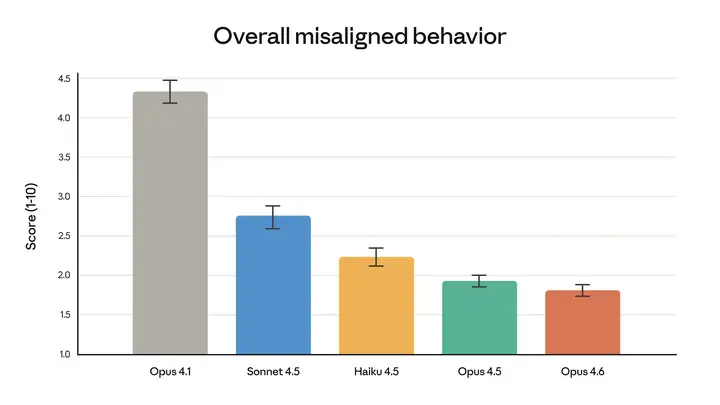
添加图片注释,不超过 140 字(可选)
我们对每个最近的 Claude 模型进行了自动化行为审核,并计算了其总体不一致性行为得分(详见Claude Opus 4.6 系统卡)。 对于 Claude Opus 4.6,我们进行了迄今为止最全面的安全评估,首次应用了许多不同的测试方法,并升级了之前使用的一些测试。我们新增了用户福祉评估,对模型拒绝潜在危险请求的能力进行了更复杂的测试,并更新了模型秘密执行有害行为的能力评估。此外,我们还尝试了可解释性(人工智能模型内部运作机制的科学)领域的新方法,以初步了解模型行为背后的原因,并最终发现标准测试可能遗漏的问题。
Claude Opus 4.6 系统卡中提供了所有功能和安全评估的详细说明。
我们还针对 Opus 4.6 展现出的特殊优势领域采取了新的安全措施,这些优势可能被用于危险或有益的用途。特别是,由于该模型展现出增强的网络安全能力,我们开发了六种新的网络安全探测方法------用于检测有害响应------以帮助我们追踪各种潜在的滥用行为。
我们也在加速将该模型应用于网络防御 领域,利用它来帮助发现和修复开源软件中的漏洞(正如我们在最新的网络安全博客文章中所述)。我们认为,网络防御者使用像 Claude 这样的 AI 模型至关重要,这有助于营造公平的竞争环境。网络安全形势瞬息万变,我们将随着对潜在威胁了解的加深而不断调整和更新我们的安全措施;在不久的将来,我们可能会实施实时干预来阻止滥用行为。
产品和 API 更新
我们对 Claude、Claude Code 和 Claude 开发者平台进行了重大更新,以使 Opus 4.6 发挥最佳性能。
Claude开发者平台
在 API 方面,我们赋予开发者对模型运行负荷的更好控制权,并为长时间运行的代理程序提供更大的灵活性。为此,我们引入了以下功能:
- **自适应思考。**以前,开发者只能在启用或禁用扩展思维之间二选一。现在,有了自适应思考,Claude 可以自行决定何时需要更深入的推理。在默认的努力程度(高)下,模型会在需要时使用扩展思维,但开发者可以调整努力程度,使其更具选择性或更不选择性。
- **Effort。**现在有四个Effort级别可供选择:低、中、高(默认)和最高。我们鼓励开发者尝试不同的选项,找到最佳方案。
- **上下文压缩(测试版)。**长时间的对话和智能体任务经常会占用上下文窗口。当对话接近可配置的阈值时,上下文压缩功能会自动总结并替换较旧的上下文,从而使 Claude 能够执行更长时间的任务而不会达到限制。
- 100万token上下文(测试版)。Opus 4.6 是我们首个支持100万token上下文的 Opus 级模型。对于超过20万token的提示,将收取额外费用(每百万输入/输出token10美元/37.50美元)。
- 128k 个输出token。Opus 4.6 支持最多 128k 个token的输出,这使得 Claude 可以一次性完成输出量较大的任务,而无需将其拆分为多个请求。
- **仅限美国地区推理。**对于需要在美国运行的工作负载,可提供仅限美国地区推理服务,价格为token价格的 1.1 倍。
产品更新
在 Claude 和 Claude Code 中,我们添加了一些功能,使知识工作者和开发人员能够使用他们日常使用的更多工具来处理更艰巨的任务。
我们在 Claude Code 中引入了代理团队功能,作为研究预览版。现在,您可以启动多个代理,它们可以并行工作,组成团队并自主协调------这最适合那些需要拆分成独立、阅读量大的任务,例如代码库审查。您可以使用 Shift+上/下箭头键或tmux直接接管任何子代理。
Claude 现在也能更好地与您常用的办公工具配合使用。Excel 版 Claude 可以更高效地处理耗时较长、难度较高的任务,并能预先规划、自动导入非结构化数据并推断出正确的结构,还能一次性处理多步骤的更改。结合 PowerPoint 版 Claude,您可以先在 Excel 中处理和构建数据,然后在 PowerPoint 中将其可视化呈现。无论您是使用模板创建演示文稿,还是根据描述生成完整的演示文稿,Claude 都能读取您的布局、字体和幻灯片母版,确保风格一致。PowerPoint 版 Claude 现已面向 Max、Team 和 Enterprise 套餐用户推出研究预览版。