
序言:上一个博客我们说了如何去自定义协议,我们采用Json串的方式实现序列化和反序列化,我们还介绍了TCP全双工,面向字节流和如何解决TCP粘包的问题。这篇博客我们将来了解我们第一个具体的协议HTTP和守护进程的相关知识。
如果没有看我上一篇博客的同学快去看吧!《计算机网络:基于TCP协议的自定义协议实现网络计算器功能》
一、HTTP简介
协议是我们程序员自己去定制的,但我们也可以使用一些别的大佬已经设计好的成熟的方案,HTTP就是其中之一。在互联网的世界中HTTP(HyperText Transfer Protocol,超文本传输协议)是一个至关重要的协议,它定义了客户端(如浏览器)与服务器之间如何去通信,交换和传输文本(如HTML文本)。
客户端可以通过HTTP协议向服务器端发送请求,服务器收到请求后处理并返回响应。HTTP是一个无连接,无状态的协议,每次访问都需要建立新的连接,且服务器不会保存客户端的状态信息。
为什么HTTP是超文本传输协议?
我们不仅仅可以通过HTTP协议传输文本数据,我们还可以通过它传输音视频等,这不就是超过文本传输嘛。
为什么HTTP是无连接的?
HTTP无连接是指HTTP并不关心双方的连接,而是关心请求报文和应答报文,至于连接的处理交给下面的TCP协议去解决。
为什么HTTP是无状态的?
在我们日常的生活中我们刷新网页的时候,对方的服务器并不会去拒绝我们的请求,对方的服务器并不会记录我们请求了多少次资源如果我们请求的次数太多就会拒接我们,这就是HTTP的无状态,简单一点来说就是对方并不会记录客户端任何状态信息。
二、认识URL

上面就是一个URL(统一资源标识符),其实就是我们日常说的网址。
我们日常见到的很多URL不像上面的那样这么完整的格式很多都是可以去省略的,比如下面的百度的网址
下面我们拿一个我们熟悉的网站来分析:
我们先把HTTPS当成HTTP协议来看
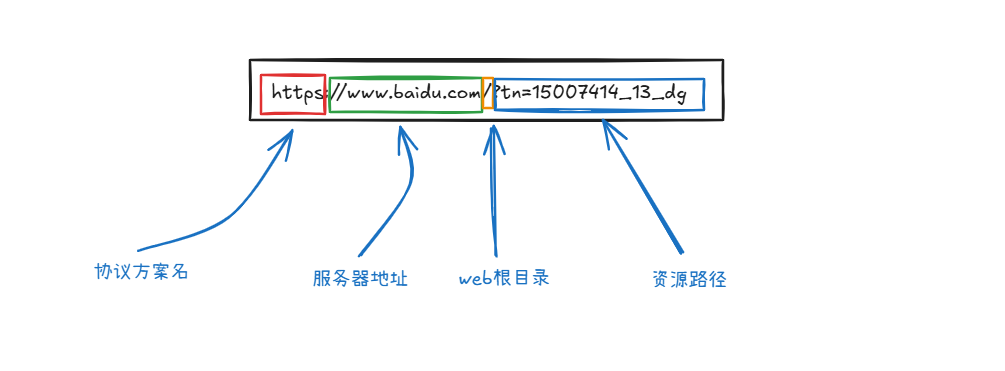
从之前的代码中我们知道我们想要去访问服务器需要知道服务器主机的IP地址和软件的端口这样我们才能在全网中找到唯一一台的主机上唯一的一个进程,那我们同学可能会有疑问了我们平时浏览网站我们不知道网站服务器的IP地址和端口号啊,我们不是也是可以依旧访问百度,B站的网站看视频嘛,那我们应该如何去理解这种现象呢?其实我们在使用网址去访问网站的时候也是使用了IP地址 + port的方式,我们上面的图上的www.baidu.com其实是百度公司的域名,什么是域名?我们可以理解成它就是我们的IP地址。我们把域名变成IP地址的过程叫做DNS解析。
1、DNS解析
当我们第一次输入一个新的域名的时候我们的浏览器会作为客户端去访问离我们主机最近的DNS服务器,向它去询问"你知道这个域名对应的IP地址是哪个吗?",如果这个DNS服务器知道的话它就直接向我们的主机发送这个域名的IP地址,如果不知道这台DNS服务器会向上级的DNS服务器(我们可以理解这台DNS服务器知道更多的域名对应的IP地址)询问,如果知道返回,如果不知道依次类推向更上层的DNS服务器询问(肯定可以找到的只是询问的次数的少和多的关系),这个时候我们知道了服务器的IP地址。
其实我们的浏览器是很聪明的它会在第一次询问之后把域名和IP地址的对应关系缓存起来,等下次用户想要去访问这个域名的时候可以直接拿到IP地址去访问服务不再去询问DNS服务器。
2、如何知道服务器端口号?
上面我们知道了浏览器如何去通过域名获得IP地址,那浏览器如何去得到端口号呢?
在我们之前的博客中我们说过0~1023号端口是知名服务才能绑定的端口号不能被普通用户绑定,其中80号端口就是HTTP服务的端口号,当我们输入网址的时候
浏览器就可以解析到它需要去访问HTTP服务,换一句话来说,这不就相当于变相的知道了访问服务的端口号了。
三、HTTP 格式
1、http请求格式

首行:【方法】+ 【uri】+ 【版本】
Header:请求的属性,冒号空格(: )分割,每组属性之间使用/r/n分割,遇到空行表示Header部分结束。
Body:空格后面的内容都是Body,Body可以为空,如果Body存在在Header中必须有Content-Length属性来标识Body的长度。

下面我们有几个问题需要解决一下:
http如何做到报头与有效载荷的分离?
空行可以作为一个分隔符分离报头和报文。
为什么要在报头中携带http版本号?
因为服务端和用户端是两个不同的软件,http分为多个版本,可以用户端的软件没有及时更新使用的还是老服务,但我们的服务器端已经更新了,如果用老客户端访问我们的新服务可能会产生错误,那么当我们的客户端访问我们新服务器的时候,新服务器可以辨别出来将这个报文转发给老服务器,如果老服务器已经停止维护了那就直接把报文抛弃,向客户端返回错误的报文。
2、http应答格式
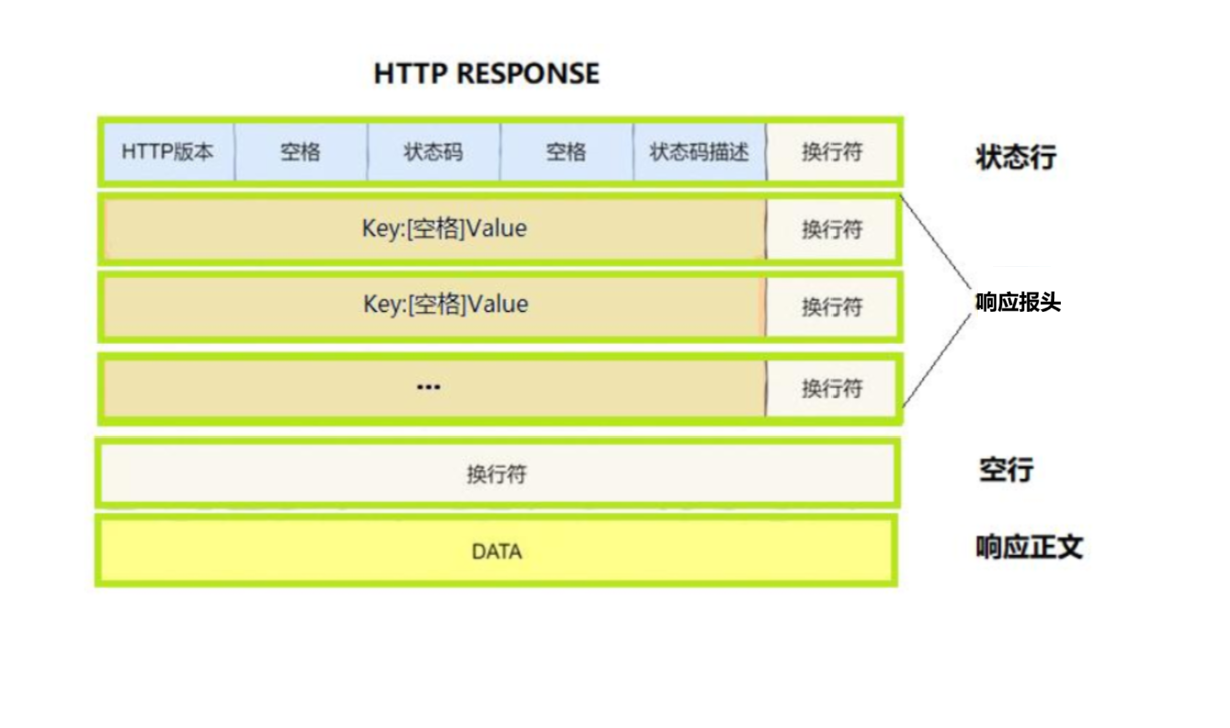
首行:【版本号】+ 【状态码】+ 【状态码解释】

我们看完http应答报文和请求报文的格式,下面我们来解释几个问题:
http是如何去分离报头的?
在报文的正文和header之间有一个空行,如果我们读取到空行说明我们把报文的报头已经全部读完了。
http是如何分离正文的?
当我们完成对报文报头的读取我们可以通过报头中的Content-Length字段,Content-Length记录了报文正文的大小,我们可以继续读取数据如果读取问Content-Length的大小的数据说明这个报文的正文我们也读取完成,如果我们读取的数据少于这个大小我们将在下次读取完成之后再去处理报文。
四、http的方法
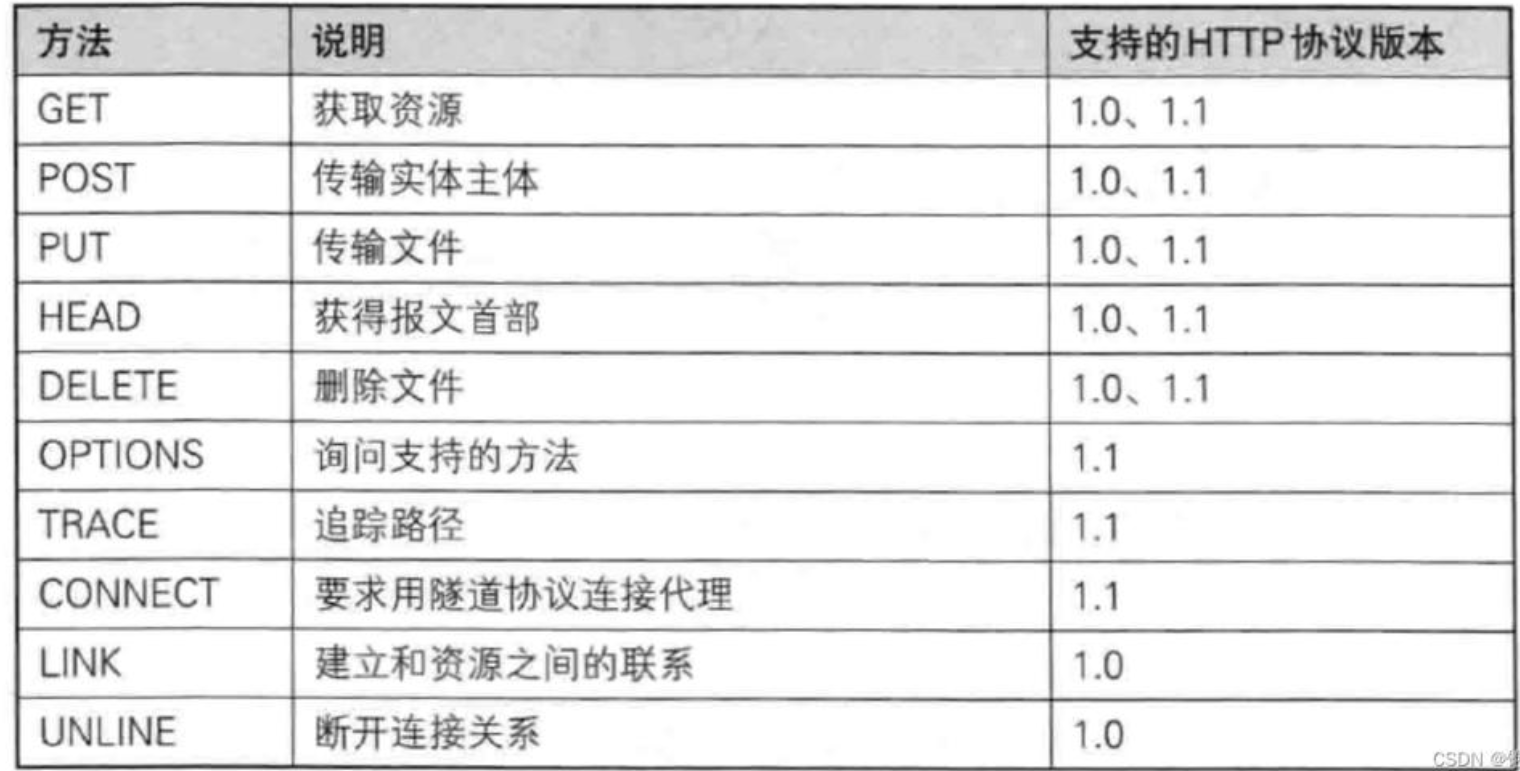
上面的图是http请求的全部方法,下面我们看一下各个方法的作用:
下面的方法中GET和POST方法是我们在HTTP中最常用的方法,其他的方法我们大概了解一下就行了。
我们知道我们使用网络可以分为两种方式一个是上传信息到网络,另一个是从网络中接受数据到我们的本地。GET和POST方法我们可以简单理解成用来解决这两个问题的,GET用来解决向从网络中获取数据,而POST是把本主机的数据发送到网络上,下面我们来详细解释这两种方法的其他用法更加深入的了解:
1、GET方法
用途:用于请求URL指定的资源。
例子:GET /index.html HTTP/1.1
在这个例子中URI是 /index.html ,我们的GET方法将从我们的服务端的web根目录下获得index.html文件资源。
其实除了去请求URI指定的资源以外,GET还可以实现传参的功能。
我们写了一个http服务,我们提供注册服务,我们如何去将用户的注册数据传回后端保存在我们的服务器中呢?
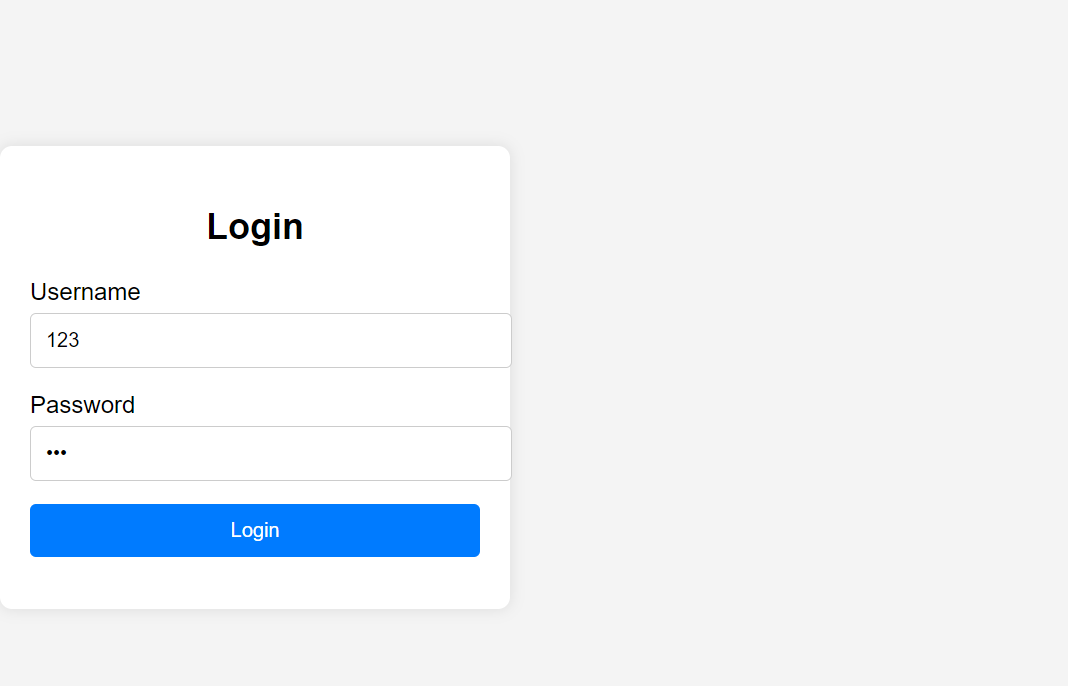
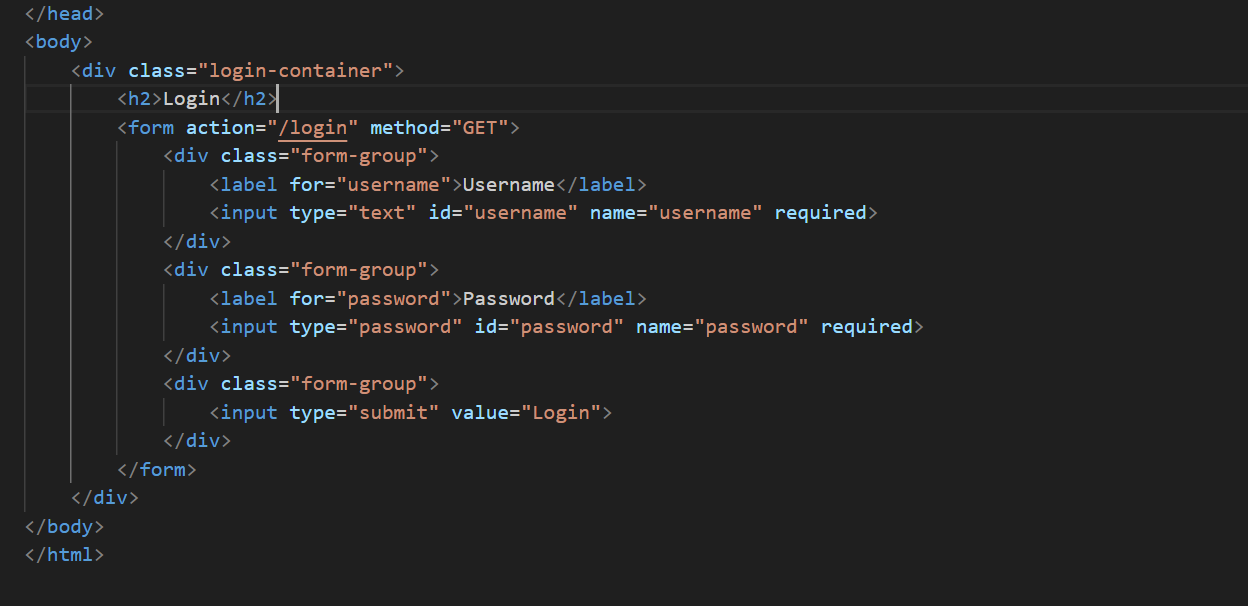
form表单:form 表单的核心作用是收集用户输入并向服务器提交数据。可以有两种方式进行向服务器提交数据分别是POST和GET,如果我们的method不写的话浏览器的默认提交方式就是GET方法。上面我们的form表单分别有两个输入一个是我们的username另一个是password,可以看我们的浏览器网页图进行理解。form表单是我们的前端的知识我们在这里简单解释可以理解它可以干什么就可以了。
当我们输入username和password点击Login按钮的时候,我们的浏览器就会发送一个http报文给我们的服务器,那我们的后端是如何知道前端客户输入的数据呢?

上面这幅图是浏览器发送的报文,我们看首行,我们可以看见我们的URI变成了
/login?username=123&password=123
在 " ?"之前是我们的请求的服务种类," ?"之后是前端提交的参数,后端可以分析报文的URI来调用不同的函数去处理对应的数据。
这个时候可能有的同学就在想一个问题:那这样的话我们如果是登录个人账号,我们账户的密码不就可以被其他人看见,因为他会回显出来呀!

这种考虑是对的这样十分的不安全,那我们上后面说了POST不是可以向网络中上传数据吗?那么POST方法可不可以传参呢?答案是可以,那么怎么做?
下面我们来介绍一下POST方法。
2、POST方法
用途:用于传输实体的主体,通常用于提交表单数据。
例子:POST /index.html HTTP/1.1
现在我们把form表单中的method方式改成POST方法。
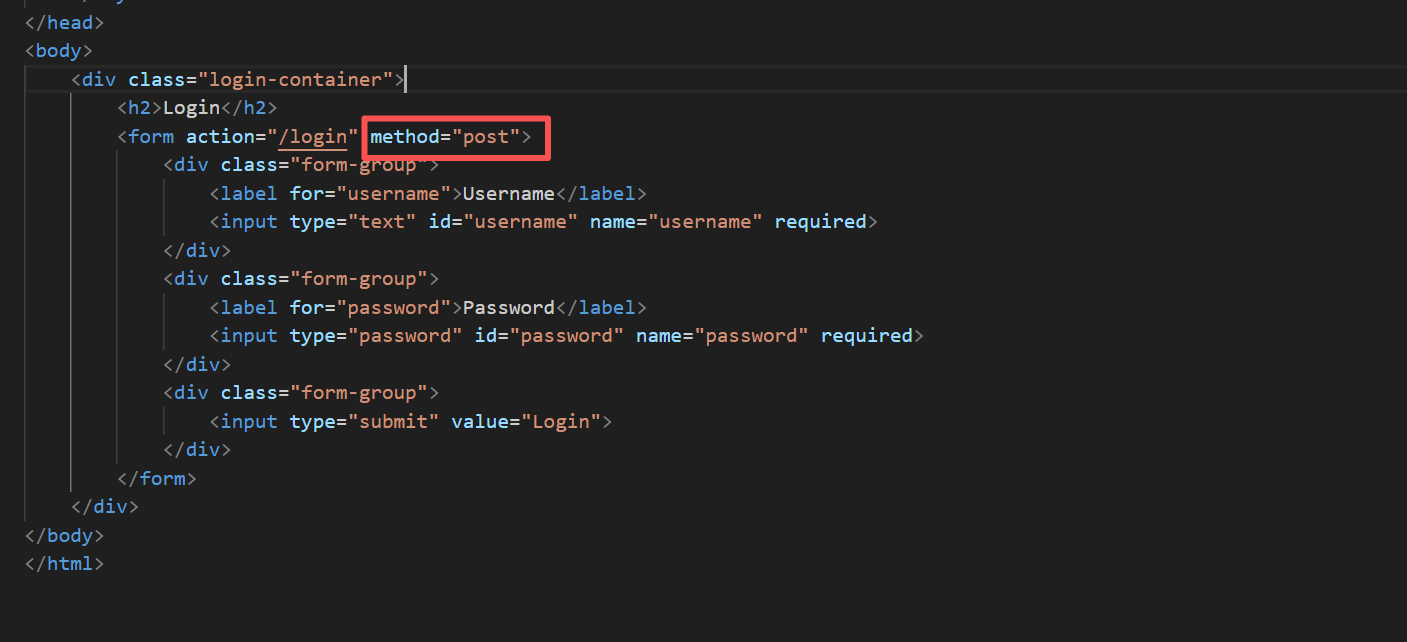
我们再次通过Login页面提交username和password。

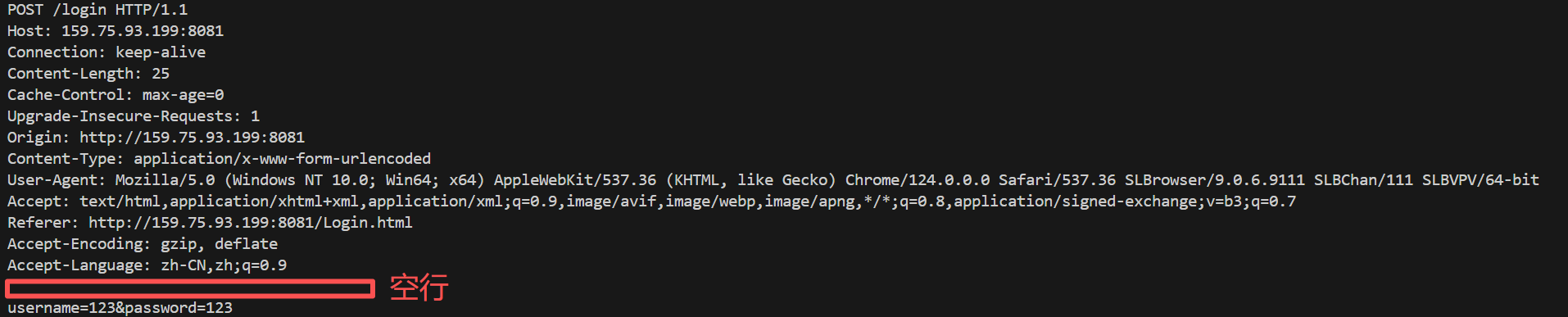
我们可以很清楚的看见在URI上没有参数了,那我们的想要传的参数在哪?答案是在我们的正文部分,这样我们就解决了我们上面GET方法参数回显的问题增加了一点安全性,但其实这种方法还是不安全的我们可以通过抓包工具抓取http报文,http是不对内容进行加密的如果真正保证安全性使用https协议进行通信。
GET vs POST
1、GET提交参数,参数不能过长,因为URI长度是有限制的。
2、POST通过正文传参
3、GET通过URI传参且参数会回显。
下面的方法都是不常用的方法我们这里只是简单了解一下就可以了。
3、PUT方法
用途:用于传输文件,将请求报文主题中的文件保存到请求URL指定的位置
例子:PUT /example.html HTTP/1.1
4、HEAD方法
用途:与GET方法类似,服务器端的应答报文不返回报文的报头。
例子:HEAD /index.html HTTP/1.1
5、DELETE方法
用途:用于删除文件,与PUT方法相反。
例子:DELETE /example.html HTTP/1.1
6、OPTIONS
用途:用于询问针对请求URL指定的资源支持的方法。
例子:OPTIONS * HTTP/1.1
五、http的状态码
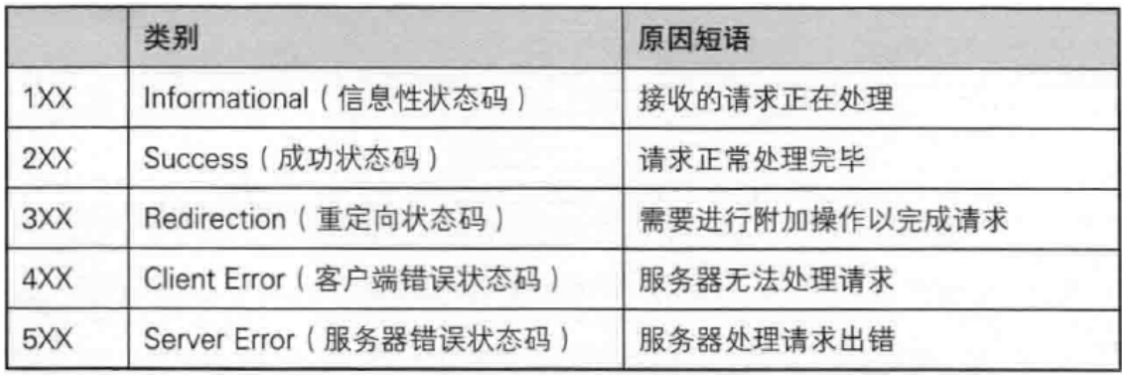
在我们使用http最常见的状态码是200,404,301,302。
1、200(OK)
当我们的服务器主机成功返回我请求的数据资源的时候返回的状态码就是200

2、301(Redirect)和 302(See Other)
301状态码用于永久重定向,302状态码用于临时重定向,那什么是永久重定向什么又是临时重定向呢?
我们举个例子:
临时重定向:
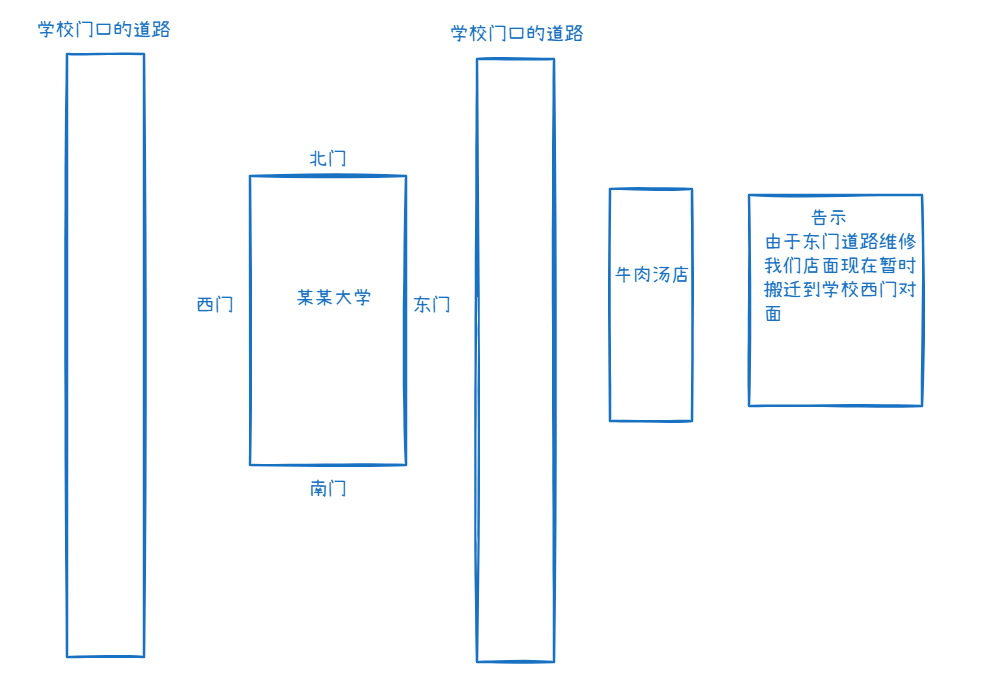
现在在我们学校的东门对面有一家牛肉汤店,张三和他的同学李四想要中午去吃牛肉汤,他们到达东门牛肉汤店看见了告示,他们知道现在牛肉汤店搬迁到了学校西门,他们现在如果想要吃到牛肉汤店需要去学校西门。等到下次张三和李四在想要去吃牛肉面的时候他们应该是去西门还是东门,答案当然还是东门,为什么?因为牛肉汤店的告示是临时搬迁到西门,如果我们下次还想去还得到东门去看他有没有搬回来。
这就是临时重定向,当我们的客户端去按照原来的URL访问服务端,服务端会返回一个新的网址并且携带302状态码,这个状态码告诉浏览器去访问这个新的网址,但当下次浏览器还要去访问这个网址的时候还是按照原有的URL去访问,临时重定向不改变客户端的相关信息(比如在浏览器中的缓存等内容)。
永久重定向:
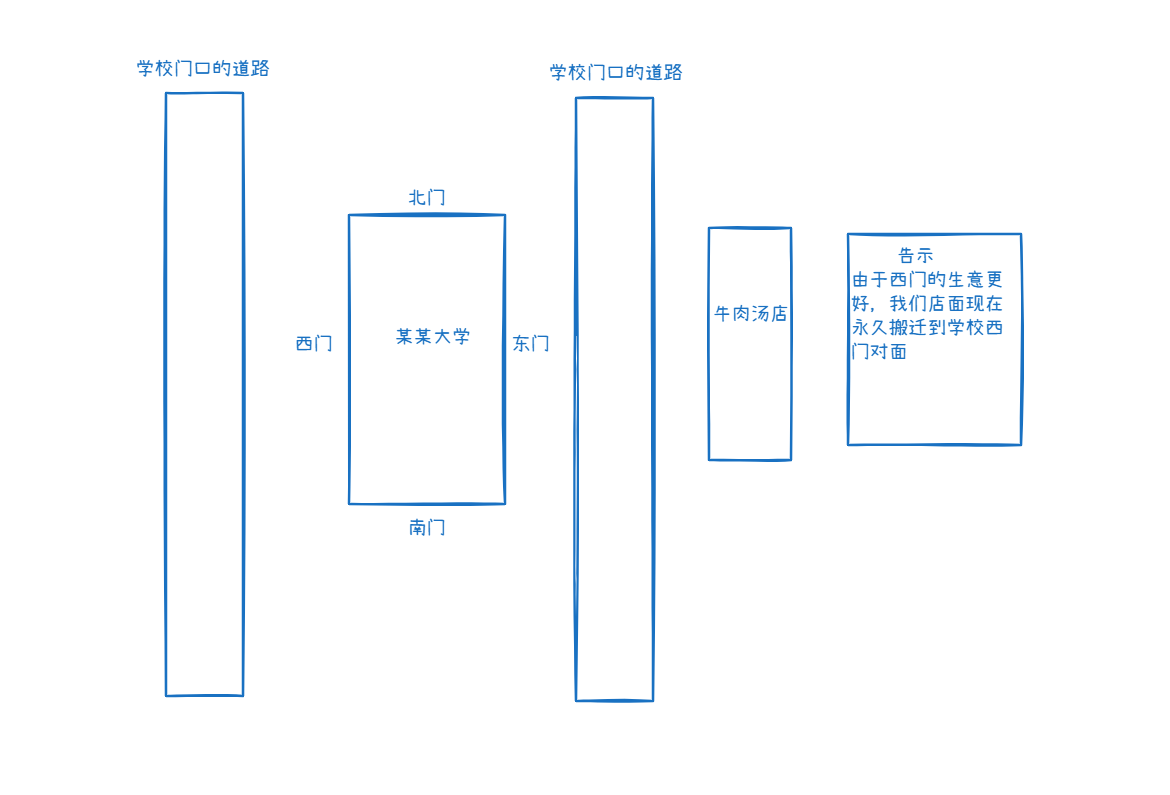
还是张三和李四去吃牛肉汤的例子,现在李四和张三还是去东门去吃牛肉汤,看见了告示,知道现在牛肉汤店现在不在东门了现在在西门,他们两跑到了西门去吃,下次他们还想吃牛肉汤他们去哪?答案是西门,因为告示中表明了现在东门的牛肉汤店永久搬迁到了西门,不用再去东门了。
这个就是永久重定向,当我们去访问原URL的时候,服务器会返回一个新的网址并且携带301状态码,这个状态码要去浏览器去访问新的网址且把新的网址缓存下来,下次再去访问这个网站的时候不要再去访问原网址了直接去访问新的网址,永久重定向会改变客户端的相关信息(比如浏览器中的缓存等内容)。
如果我们做个测试我们看见临时重定向和永久重定向的现象是相同的,他们的区别是是否改变客户端的相关信息。
临时重定向常用于网页跳转和身份验证等场景,永久重定向常用于搜索浏览器在更新内容的时候,如果有些网站的域名更换或者资源迁移到新的服务器中等情况,这些搜索浏览器在进行爬虫获得网站内容的时候会得到一个301的状态码这个时候他就知道了这个网站需要永久重定向他就会把老网址代替成新的网站。
http状态码301和302都依赖Location报头选项,Location里记录的就是新的网址。
六、http常见的header
1、Content-Type
http协议作为一种超文本传输的协议,我们可以用于传输文本内容,图片内容,视频内容等等,那浏览器如何知道我们的正文内容是哪一种,只有浏览器知道正文是哪一种浏览器才可以更好的去渲染和展示。
2、Content-Length
我们上面说到如何去分离报头,在报头中的Content-Length作为分离报文正文的一个重要的依据。注意:
Content-length的大小是报文正文的大小不是整个报文的大小。
3、Cookie
cookie的中文是曲奇/饼干的意思,那这个是干什么的?
上面我们说到http是一种无连接,无状态的协议,在我们日常的生活中我们经常去在网站上登录我们的账号,比如B站,我们登录上我们的账号之后我们点击视频观看我们还需要重新登录吗?我们知道肯定是不需要的不仅不需要再我们登录上之后可能一段时间之内我们都不需要再次登录。
这个不是与http的定义又冲突吗?http是无状态的,什么叫无状态?按照今天的情景就是我们每看一个视频都需要再次登录,http服务器并不会记录我们的状态不会记录我们是否已经登录了。
那这个我们在日常使用感受不服啊!那如何去解释呢?其实这个就是cookie的作用,它可以记录客户的一些信息当我们下次去请求服务的时候客户端发出的报文在报头部分会携带cookie里面记录了我们客户的一些信息(比如我们的账户和密码),服务端可以解析cookie去认证客户身份,这样的话就不需要客户天天登录了。
那我们的登录会在几天后失效是怎么回事?
cookie会有生命周期的,当时间周期到期了之后,服务器会判定cookie无效认证不成功需要重新登录,服务器再去返回登录报文让客户登录。
注意:
cookie是由服务端设置的,当我们第一次登录的时候,服务器在应答报文中会有一个Set-Cookie报头,里面有cookie的内容,当浏览器收到这个报文的时候就会创建cookie下次再去请求报文的时候带上。
bash
HTTP/1.1 200 OK
Content-Type: text/html; charset=utf-8
Set-Cookie: username=zhangsan; Path=/; Domain=example.com; Max-Age=3600; HttpOnly
Set-Cookie: theme=dark; Path=/; Domain=example.com
在我们日常的生活中不会真的把客户的账户密码放在cookie中,这样是不安全的,如果有黑客植入木马程序盗取cookie,他就可以以我们的身份去访问对应的网站,所以互联网公司不会把这种个人信息放在我们的客户端,通常会采用seeion+cookie的方案去解决。
cookie保存信息的缺点:
1、他人可以以我的身份去访问呢对应的网站。
2、我的个人信息泄漏。
4、Host
客户端告知服务器,所请求的资源是在哪个主机的哪个端口上。
5、User-Agent
声明用户的操作系统和浏览器版本
七、Session
上我们说到了使用cookie保存用户信息的不安全性,那我们如何去解决使用http协议但不需要重复登录的问题呢?现在我们大部分情况采用的是cookie + session的方案。
那么什么是session呢?
我们可以理解成在公司的服务器主机会有一块内存去保存用户的信息并且生成一个session id。
那如何使用cookie + session去保存用户的信息呢?
我们把生成的session id作为cookie的内容,这个session id是唯一的通过加密算法生成,当下次客户端去访问服务的时候session id作为cookie内容发给服务器端,服务器再根据客户端发来的cookie内容去找到对应的session,如果找到去读取客户信息,如果找不到就让用户重新登录。
cookie + session的方案相对于cookie方案解决了什么问题?
这个方案解决了客户个人信息泄漏的问题,因为我们的个人信息保存在公司的服务器中,这些服务器是受到保护的,这些主机的安全性相对于我们的个人主机要安全许多的。但这个方案还是没有解决我们的其他人以我的身份去登录相应网站的问题,为什么?因为我们的session id依旧可能会泄漏,但我们可以采用其他的辅助手段去解决,比如查看两次登录的IP地址来判断是否是本人登录。
本篇关于Linux的文件理解与操作的介绍就暂告段落啦,希望能对大家的学习产生帮助,欢迎各位佬前来支持纠正!!!
