【深度长文】万字攻克网络原理:从 HTTP 报文解构到 HTTPS 终极加密逻辑

我的主页: 寻星探路
个人专栏: 《JAVA(SE)----如此简单!!! 》 《从青铜到王者,就差这讲数据结构!!!》
《数据库那些事!!!》 《JavaEE 初阶启程记:跟我走不踩坑》
《JavaEE 进阶:从架构到落地实战 》 《测试开发漫谈》
《测开视角・力扣算法通关》 《从 0 到 1 刷力扣:算法 + 代码双提升》
《Python 全栈测试开发之路》
没有人天生就会编程,但我生来倔强!!!
寻星探路的个人简介:


前言:为什么每一个开发者都必须精通 HTTP/HTTPS?
在当前的互联网架构中,无论你是从事前端 UI 交互、后端分布式微服务,还是底层安全运维,HTTP/HTTPS 都是数据流通的"血脉"。根据 PDF 讲义所述,HTTP 从 1991 年诞生至今,已从简单的文本传输演变为支撑万亿级流量的核心协议。理解它,就是理解互联网的运行规则。
一、应用层协议的皇冠------HTTP 深度解构
1.1 应用层的定义与地位
在 TCP/IP 四层模型中,应用层位于最顶层。它不关心数据是如何在物理光缆中传输的(那是链路层和网络层的事),也不关心数据包是否丢失(那是传输层 TCP 的事),它只关心:数据拿到后,该如何解析并呈现给用户?
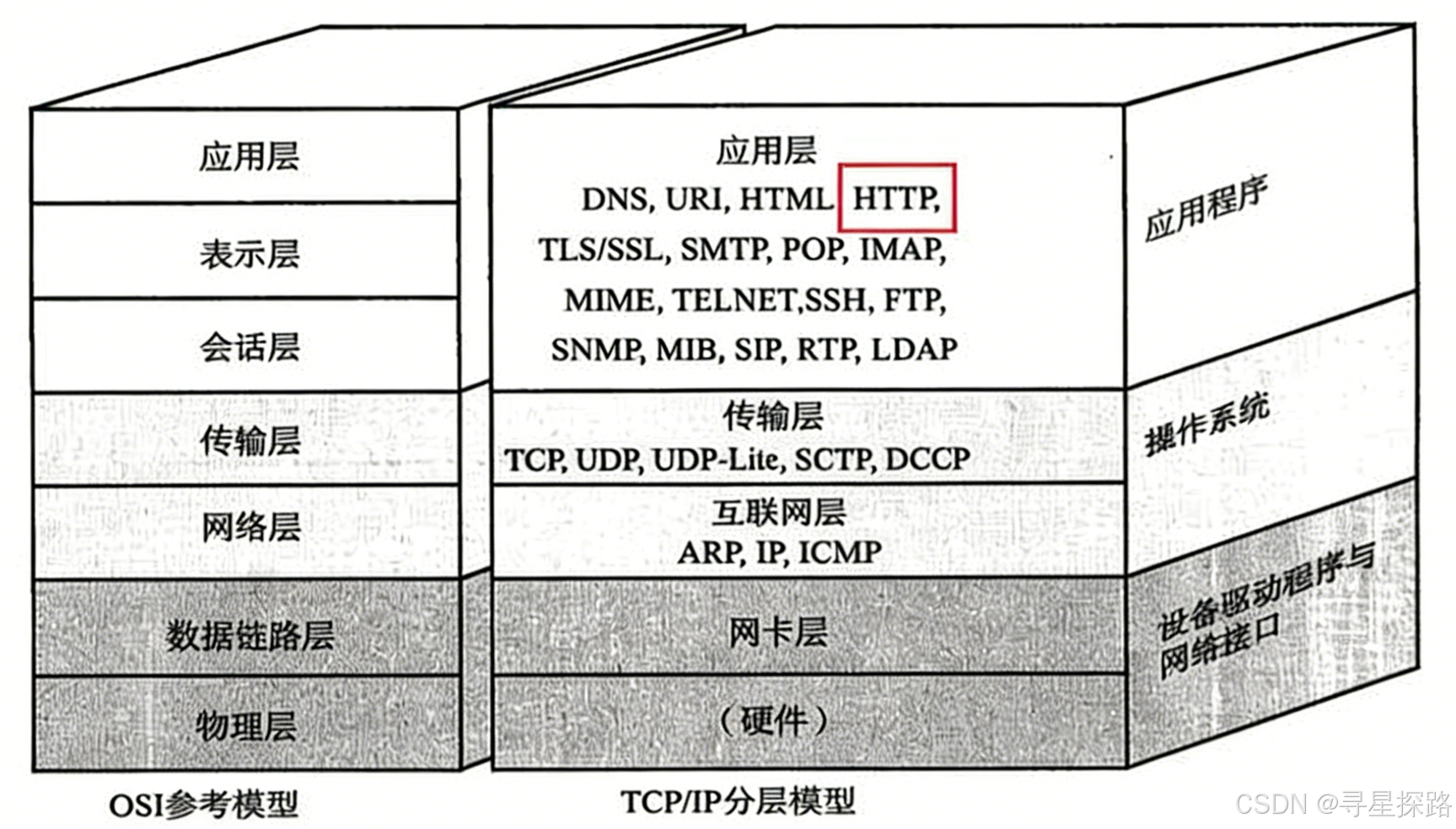
1.2 HTTP 的演进脉络
- HTTP/0.9 (1991):仅支持 GET 方法,返回纯文本。
- HTTP/1.0 (1996):引入了 Header、状态码、多媒体传输支持。
- HTTP/1.1 (1997-至今) :当前最主流版本。引入了持久连接 (Keep-Alive)、管道化 (Pipelining) 和缓存控制 (Cache-Control)。
- HTTP/2.0 (2015) :引入二进制分帧、多路复用、头部压缩(HPACK)。
- HTTP/3.0 (即将普及):基于 UDP 的 QUIC 协议,彻底解决 TCP 队头阻塞问题。

二、URL------精准定位全球资源的身份证
2.1 URL 的标准解构
URL (Uniform Resource Locator) 是 URI 的子集。一个标准的 URL 如下:
(https://datatracker.ietf.org/doc/html/rfc1738)
- 协议名 (Scheme) :
http或https。 - 服务器地址 (Host):域名或 IP。
- 端口号 (Port):HTTP 默认 80,HTTPS 默认 443。
- 路径 (Path):资源在服务器上的分层存储位置。
- 查询字符串 (Query String) :键值对形式,以
?开头,&分隔。 - 片段标识符 (Fragment) :
#后面的部分,用于页面内定位。

2.2 深度:URL Encode 与 Decode
由于 URL 中只能包含 ASCII 字符,且 / ? : 等具有特殊含义,因此非 ASCII 字符或特殊符号必须进行转义。
- 原理 :将字符转化为 16 进制,前缀
%。 - 示例 :中文字符在 UTF-8 下转义后会变成类似
%E4%BD%A0的形式。 - 避坑指南 :前端发送请求前务必
encodeURIComponent,防止参数中的特殊符号破坏 URL 结构。
三、HTTP 报文的"显微镜"解剖
3.1 请求报文:客户端的诉求
请求报文由四部分组成,每一部分都至关重要:
- 首行 (Start Line) :
方法 + URL + 版本号。 - 报头 (Header):
Host:目标服务器。Content-Length:Body 长度(防止 TCP 粘包的关键)。User-Agent:标识客户端环境。Referer:防盗链和来源统计的核心。
- 空行 (Empty Line):Header 结束的"信号弹"。
- 正文 (Body):POST 请求的数据载体。
3.2 响应报文:服务器的回应
- 首行 :
版本号 + 状态码 + 状态码描述。 - 报头 :
Content-Type(告知浏览器如何处理数据,如image/png或application/json)。 - 正文:HTML 源码或二进制流。
第四部分:核心方法与状态码的实战应用
4.1 GET 与 POST 的世纪之辩
这不仅是面试必问,更是架构设计的基石。
- 幂等性 (Idempotence):GET 是幂等的(读操作),POST 不是(写操作)。
- 缓存机制:GET 可被浏览器主动缓存,POST 默认不缓存。
- 参数传递:GET 参数暴露在 URL 中,受限于 URL 长度(一般 2KB-8KB);POST 参数在 Body 中,理论上无上限。
4.2 状态码的深度解读
- 2xx (成功):200 OK(完美)、204 No Content(操作成功但无返回)。
- 3xx (重定向):301(永久移动,SEO 权重转移)、302(临时跳转)。
- 4xx (客户端错误):403(禁止访问)、404(资源失踪)、405(方法禁用)。
- 5xx (服务器错误):500(代码逻辑崩了)、502(网关错误,通常是后端服务宕机)、504(超时)。
五、无状态协议的终结者------Cookie 与 Session
5.1 为什么需要"状态"?
HTTP 是无状态的,它不记得你是谁。为了实现购物车的持久化,必须引入会话机制。
5.2 闭环流程
- 创建身份 :用户提交登录,服务器生成一个唯一的
SessionID并存入数据库/Redis。 - 下发令牌 :通过响应头的
Set-Cookie: sessionID=xxxx发给浏览器。 - 自动携带 :浏览器后续请求会自动在 Header 中带上
Cookie: sessionID=xxxx。 - 身份识别:服务器根据 ID 找回该用户的会话状态。
5.3 分布式 Session 挑战
在微服务架构下,Session 不能只存在于单机内存。
- 解决方案 :引入 Redis 集群存储 Session,实现全网共享;或者采用 JWT (JSON Web Token) 将状态加密存放在客户端。
六、HTTPS 终极加密逻辑------安全通信的基石
这是 PDF 讲义中最硬核的部分:如何保证数据不被中间人嗅探或篡改?
6.1 混合加密:性能与安全的平衡
- 非对称加密(RSA/ECC) :安全性极高,但计算量大(慢)。用于交换对称密钥。
- 对称加密(AES/ChaCha20) :计算飞快,但密钥传输不安全。用于传输实际业务数据。
6.2 信任的阶梯------数字证书与 CA 体系
黑客可以伪造公钥,所以我们需要一个公正的第三方------CA (数字证书认证机构)。
数字签名的验证原理:
- 哈希摘要 :服务器将证书内容(域名、公钥等)通过 MD5/SHA 算法生成一个定长摘要。
- 签名生成 :CA 使用自己的私钥对该摘要进行加密,形成"数字签名"。
- 客户端验证:
- 浏览器提取证书中的公钥和签名。
- 使用内置的 CA 公钥解密签名,得到摘要 A。
- 对证书内容重新计算哈希得到摘要 B。
- 比对:若 A == B,则证明证书从未被篡改且来源真实。
6.3 深度解密:MD5 算法的三大特性
- 定长性:输出长度固定,适合作为数据的"指纹"。
- 分散性(雪崩效应):原文哪怕改动一个比特,MD5 值也会天差地别。
- 不可逆性:单向性极强,计算容易但反推极难。
七、SSL/TLS 握手全流程 (The Handshake)
这是浏览器地址栏变绿(或显示小锁)的瞬间发生的"外交仪式":
- Client Hello:客户端发送支持的加密版本、随机数 R1。
- Server Hello:服务器确认加密版本、发送随机数 R2、下发证书。
- Key Exchange:客户端验证证书,生成随机数 R3(预主密钥),用服务器公钥加密后发送。
- Finished:双方利用 R1+R2+R3 生成"主密钥",从此进入对称加密的快车道。
八、实战------如何使用 Fiddler 抓包并分析
- 配置 :开启
Decrypt HTTPS traffic,安装 Fiddler 根证书(这本质上是中间人攻击的一种应用)。 - 观察:对比蓝色的 HTTP 请求和绿色的 HTTPS 请求。
- 调试 :查看 Header 中的
Content-Type是否正确,检查Set-Cookie的生效情况。
九、总结
HTTP 协议不仅是简单的文本交换,它背后蕴含了分布式系统设计、现代密码学、计算机网络架构的无数智慧。从 GET/POST 的选择到 HTTPS 证书的校验,每一个细节都关乎着应用的性能与安全。
博主建议 :
学习网络原理不应死记硬背。打开你的 Chrome F12,在 Network 选项卡里看一眼每一条请求的 Header;尝试用 OpenSSL 查看一个证书的详情。当你能肉眼识别每一个字节的意义时,你就是真正的网络大牛。