Google昨晚重磅发布了Gemini 3.0,看指标基本碾压了现有的一系列模型。
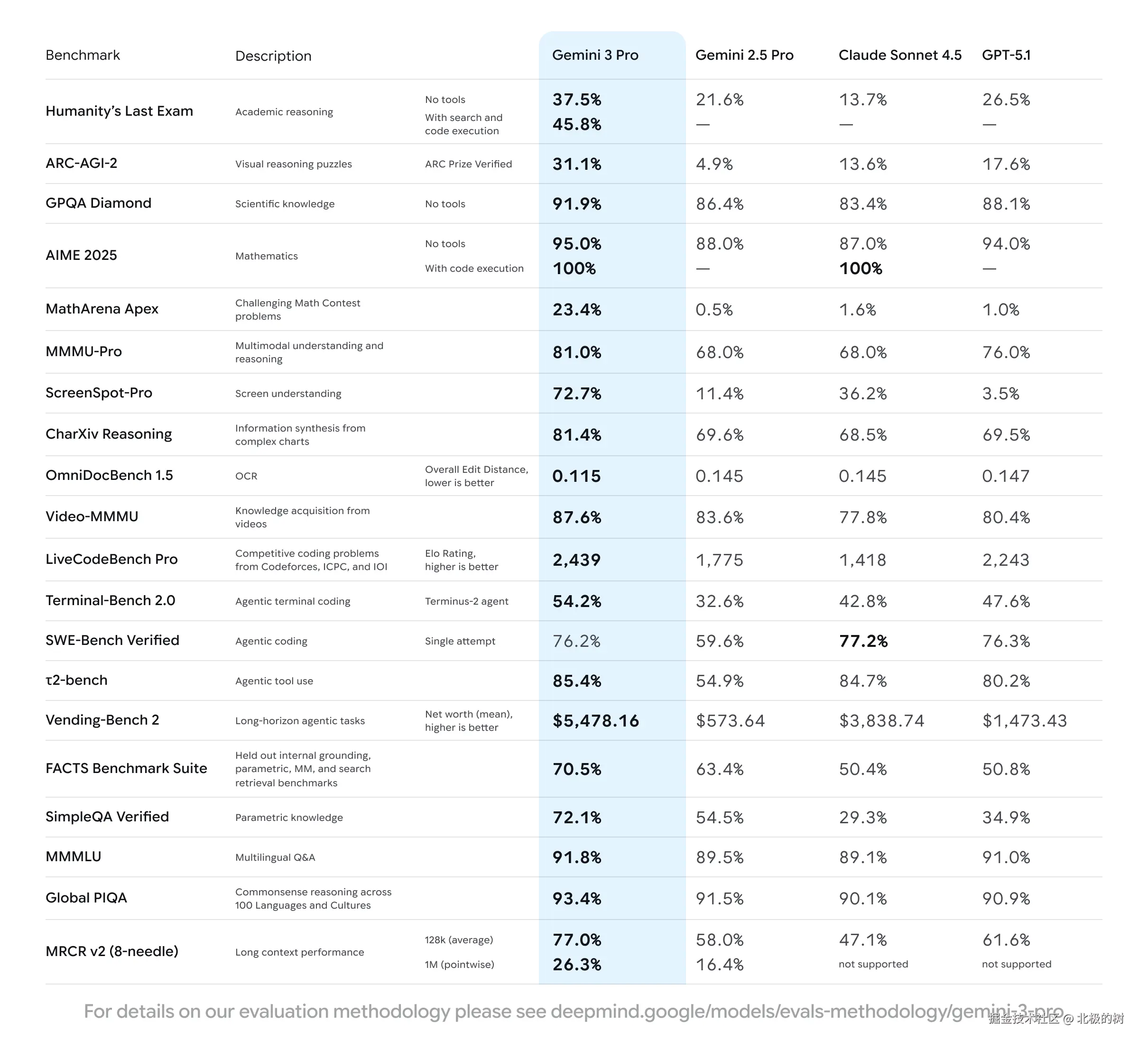
网上大量的评测文章,这里就不再赘述,在编程领域的真实实力也尚有待深度体验(以前很多模型出来时各种刷分,深度体验后还是被claude吊打)。
这次发布,我比较感兴趣的反而是一同发布的Generative UI(生成式用户界面) 。官方甚至发了专门的论文介绍实现原理,也给了一个具象化的演示。
当在Generative UI模式下提问:"RNA聚合酶如何工作?原核细胞和真核细胞的转录阶段有哪些不同?"
可以看看响应结果的形式和以前的模型有什么不同:
什么是Generative UI
在传统软件开发中,UI是固化的。设计师用Figma画好原型,开发同学按照设计稿还原UI,用户最终看到的界面,早在几周甚至几个月前就定好了。
Generative UI的核心理念完全不同:界面不再是预先存在的,而是深刻理解用户的意图和需求后,实时生成一个完整的、可交互的界面。
比如,当你问"给我规划一个北京3日游",传统的LLM只会返回一大段文字攻略。但Generative UI会:
- 生成一个交互式的地图,标注每天的景点路线
- 添加一个时间轴,展示每天的行程安排
- 配上景点卡片,点击就能看图片和介绍
- 还有一个筛选器,让你调整预算和兴趣偏好
也就是说,模型不再局限于生成内容,还生成了承载内容的界面本身。
应用场景
Generative UI看起来比较酷炫,但真正有价值的是它能解决哪些实际问题。根据论文和官方演示,我整理了几个很有想象空间的场景。
场景一:快速产品原型
做产品的同学应该了解,需求演示是沟通中比较费劲的环节。
传统流程里,产品想给开发或者老板演示一个新的想法需求,通常有两个选择:
- 画草图/PPT:快,但没法交互,全靠脑补,对方经常理解偏差。
- 做交互原型:效果好,但太慢。产品经理写文档,设计师画图,前端写Demo,等这一套下来,可能黄花菜都凉了。
Generative UI看起来就能解决"想演示但做不出来"的痛点。
产品同学不需要懂代码、也不需要懂设计,只需准确阐述需求就可快速生成交互式产品原型。不满意的地方还可以继续迭代修改。
场景二:个性化教育界面
教育应该是Generative UI最能发挥价值的领域之一,论文中花了很大篇幅展示这个场景。
传统的在线教育平台,不管学生水平如何,看到的都是同一套课件。这就像让小学生和大学生读同一本教科书,效果肯定差。Khan Academy、Coursera这些平台虽然有题目难度分级,但界面本身是固定的。
Generative UI的做法完全不同:根据学生的先验知识和理解能力,动态生成不同复杂度的学习界面。
论文中有个典型案例:教"化学实验"这个主题。
对于初中生,系统生成的是:
- 大号的彩色图标
- 每个步骤配动画演示
- 用类比的方式解释("原子就像乐高积木")
- 有互动小游戏巩固知识
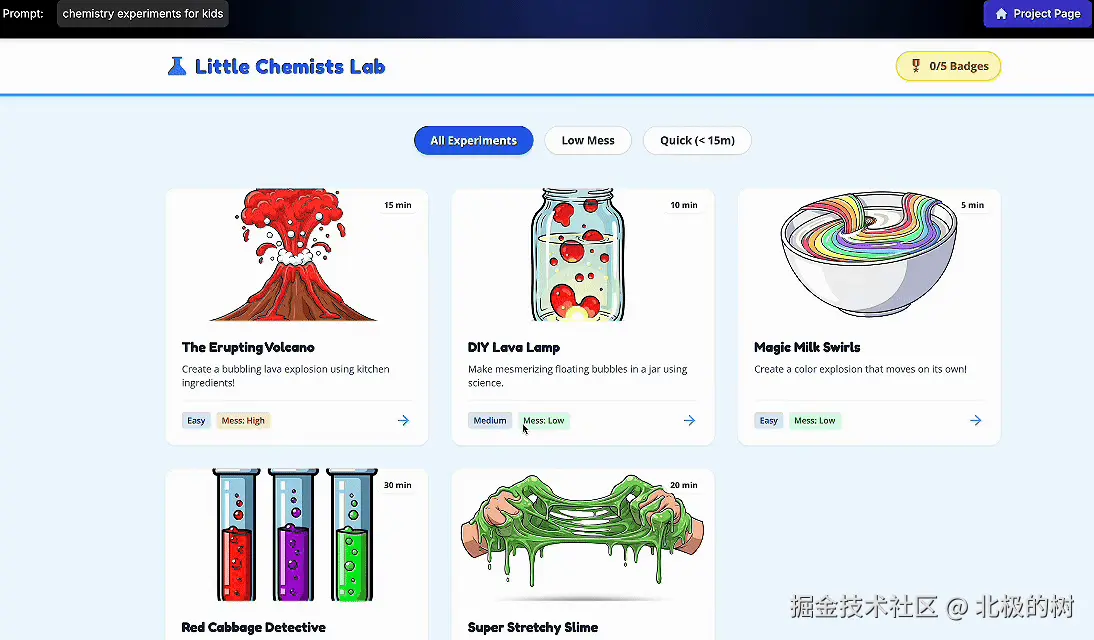
而对于化学系学生,系统生成的是:
- 精确的分子结构图
- 化学方程式和计量计算
- 实验数据表格
- 安全注意事项清单
关键是,这些都不需要教师手动准备多个版本。学生输入自己的学习目标和背景,系统可以自动生成最适合的学习界面。
更厉害的是实时调整能力。如果学生在某个概念上卡住了(通过交互数据判断,比如反复点击同一个区域),系统会自动简化那部分的界面,增加提示和辅助说明。
论文中还展示了一个"斜率和切线"的教学案例。系统检测到学生喜欢篮球,就把抽象的数学概念转化成"投篮轨迹"来讲解,学生的理解速度明显提升。
这种个性化不是简单的"换个背景图",而是认知层面的结构性适配。同样是讲分形,成年人看到的是数学公式和递归算法,小学生看到的是"树枝怎么长出来"的动画故事。界面的信息密度、交互复杂度、语言风格,都是动态调整的。
场景三:电商的意图驱动购物
查阅了相关资料,在电商领域,Generative UI应该也能在一定程度上改变购物体验。
现在的电商搜索,用户要把模糊的购物意图("我想买一套适合海滩婚礼的衣服")翻译成一系列筛选操作:男装 → 西装 → 亚麻 → 米色 → 尺码。这个过程很繁琐,而且容易漏掉重要选项。
Generative UI的做法:直接理解这一意图,生成一个临时的精品店界面。
系统生成的不是一个标准列表,而是一个杂志风格的"Lookbook"布局:
- 将西装、衬衫、乐福鞋搭配展示
- 用轻松的海滩氛围照片做背景
- 标注每件单品的透气性和舒适度
- 还有一个"比这个更休闲"的滑块
如果用户反馈"太正式了",界面会瞬间重排,替换为更休闲的Polo衫和卡其裤组合。
这种交互方式,将购物从"搜索商品"变成了"与导购对话",界面本身即是推荐引擎的具象化。
以上只是我个人体会、以及从网上看到的可能发挥巨大价值的应用场景。实际上,Generative UI的潜力可能远不止于此。
我觉得,每个行业、每个场景,只要涉及"信息呈现"和"交互",都有机会被Generative UI重新定义。 这不是一个单一的产品功能,而是一种新的人机交互范式。
技术原理:从Prompt到交互界面
讨论完应用场景,接着咱们通过论文详细了解它是如何做到的。论文中披露了详细的技术架构,我用通俗的方式解释一下核心原理。
整体架构:四层技术栈
根据论文,Generative UI的实现依赖于四个核心层:
1. 组件库
系统预先定义了一套标准化的UI组件,包括按钮、卡片、图表、表单、地图等基础组件,以及一些复合组件(比如商品卡片、用户评价模块)。这些组件都是经过设计系统规范的,确保生成的界面有统一的视觉风格。
2. 系统指令
这是告诉模型"怎么生成UI"的规则。包括:何时使用哪种组件、如何布局、什么样的交互符合用户预期。论文中称之为"元提示"(meta-prompt),它相当于给模型注入了设计原则和前端开发的最佳实践
3. 大语言模型
Gemini 3.0是核心引擎。它负责理解用户的自然语言输入,分析意图,然后从组件库中选择合适的组件,生成最终的UI代码(通常是HTML/CSS/JavaScript)
4. 后处理层
生成的代码会经过静态分析,检查语法错误、安全漏洞、性能问题。如果发现问题,系统会自动修正或重新生成。
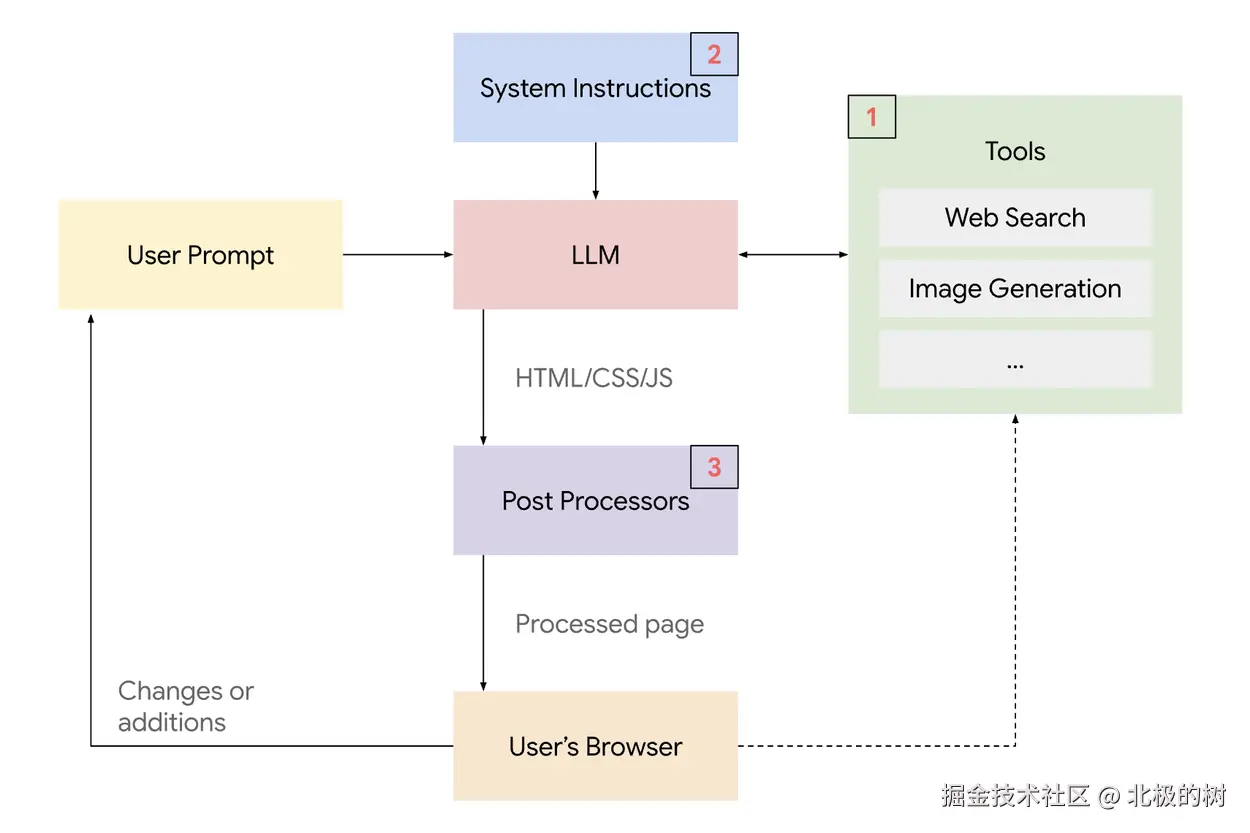
论文中特别强调,这四层缺一不可。早期的GPT-3.5尝试过类似任务,但由于模型能力不足,经常生成错误的代码或不符合设计规范的界面。接下来,分别探讨一下每一层的细节。
核心技术点一:组件库与工具调用
Generative UI的第一个关键,是把UI组件当作"工具"提供给模型。
传统的LLM只能输出文本。Generative UI的做法是,给模型一个"工具箱",里面有各种UI组件的接口,例如:
css
工具:生成图表
参数:
- 类型:柱状图/折线图/饼图
- 数据:[数组]
- 标题:字符串
- 配色方案:主题名称这段代码会被前端引擎解析,直接渲染成一个交互式图表。
可以用乐高来类比:组件库提供的是标准化的积木块,模型的任务不是制造积木,而是根据需求来组装积木。这样既保证了UI的质量和一致性,又给了模型足够的灵活性。
论文数据显示,当组件库有50+种组件时,模型能覆盖95%以上的常见UI需求。
核心技术点二:意图理解与布局生成
第二个关键是,模型要理解用户意图,并转化成合理的UI布局。
这里涉及一个隐式的推理过程,论文中称为"Planning(规划)"。
当用户说"规划一次去巴黎的旅行"时,模型会进行类似这样的思维链:
- 需求分析:旅行需要交通、住宿、景点、预算
- 组件选择:需要地图组件(地理位置)、列表组件(酒店选项)、天气卡片、计算器组件(预算)
- 布局决策:桌面端把地图放右侧、列表放左侧;移动端用标签页切换
模型输出的不是HTML代码,而是一个结构化的UI描述(通常是JSON格式):
css
{
"layout": "two-column",
"left": {
"component": "hotel-list",
"data": [...],
"sortBy": "price"
},
"right": {
"component": "interactive-map",
"markers": [...]
},
"bottom": {
"component": "budget-calculator"
}
}前端引擎拿到这个描述,用本地的UI组件库渲染出实际界面。
核心技术点三:上下文管理与迭代优化
第三个关键是处理用户的连续修改请求。
传统的LLM是无状态的,每次对话都是独立的。Generative UI需要记住之前的界面状态,才能实现增量修改。
论文中采用的方案是状态管理:
-
用户首次输入,生成界面A
-
用户说"把地图放大一点",系统不是重新生成整个界面,而是:
- 从上下文中取出界面A的描述
- 定位到"地图"组件
- 只修改地图的"size"参数
- 输出界面B(
其他部分保持不变)
系统会记住你们聊过的所有内容,包括之前生成的界面、你的修改请求、甚至你的交互行为(比如哪些按钮点得多,说明那部分用户感兴趣)。
论文数据显示,在3轮修改内,模型能保持状态一致性的准确率达到92%。
核心技术点四:安全性与一致性保障
最后一个关键是确保生成的界面安全、可用。
AI生成的代码可能有Bug,也可能包含不安全的内容。论文中的解决方案是后处理层,其中的工作包括:
语法修复:自动检测和修复常见错误,比如括号不匹配、标签没闭合。
安全过滤:禁止生成执行任意JavaScript的代码,只允许调用预定义的组件和API。
设计一致性检查:确保生成的界面符合设计系统规范,比如颜色、字体、间距都在允许范围内。
性能优化 :如果生成的界面有性能问题(比如一次渲染1000个组件),自动优化成分页或虚拟滚动。
论文数据显示,经过后处理的界面,运行时错误率从18%降到了不到2%。
技术挑战:不是完美的
虽然Generative UI很强大,但论文也指出了当前的局限性。
最明显的问题是速度。生成一个复杂界面可能需要10-30秒,这包括模型推理、工具调用、后处理等多个环节。对于习惯了"即时响应"的用户来说,这个等待时间还是有点长。论文中提到,团队正在优化流式生成技术,先显示骨架屏,再逐步渲染完整组件,让等待过程不那么焦虑。
另一个问题是模型偶尔会"幻觉"。它可能会"编造"一个根本不存在的组件,比如试图调用一个名为SuperFancyChart的组件,但组件库里根本没有。结果就是界面渲染失败。目前的解决办法是在系统指令中明确列出所有可用组件,并在后处理层做兜底检查,发现不存在的组件就替换成最接近的替代品。
对于非常复杂的交互,比如多步表单、拖拽排序这类需要精细状态管理的场景,模型的成功率还不够高,论文给出的数据是大约70%。这意味着10次里有3次可能需要人工介入调整。
还有一个有意思的悖论:为了让AI生成高质量的UI,你反而需要一个非常严格、标准化的组件库。这意味着UI设计师的角色正在发生转变,从"画页面"变成了"设计原子组件"和"制定组装规则"。某种程度上,设计师的工作从具体变抽象了。
写在最后
相比Gemini 3.0在参数和评测指标上的巨大提升,我觉得Generative UI更是让我眼前一亮。
它的核心突破在于:界面不再是预先设计好的静态模板,而是根据你的需求即时生成、动态适配的交互体验。对于产品经理、创业者、教育工作者来说,这意味着从想法到可演示原型的时间,从几天缩短到几分钟。
目前,Generative UI已经在谷歌搜索的AI模式(AI Mode)和Gemini应用中上线,但仅限美区的Pro/Ultra订阅用户使用。国内用户暂时只能等待全量开放。
不过论文和演示已经足够说明方向:从"人适应界面"到"界面适应人",这不仅是技术进步,更是交互范式的转变。期待它正式开放后,能为我们的工作带来实实在在的效率提升。