在近日举办的2025第八届智能辅助驾驶大会上,火山引擎数据产品解决方案专家分享了由多模态数据湖解决方案构成的数据基座,致力于解决智能网联汽车行业面临的海量多模态数据处理难题。该方案通过存储与计算架构的深度优化,助力企业将百PB级异构数据从"隐性负债"转化为驱动算法迭代与业务增长的核心资产。
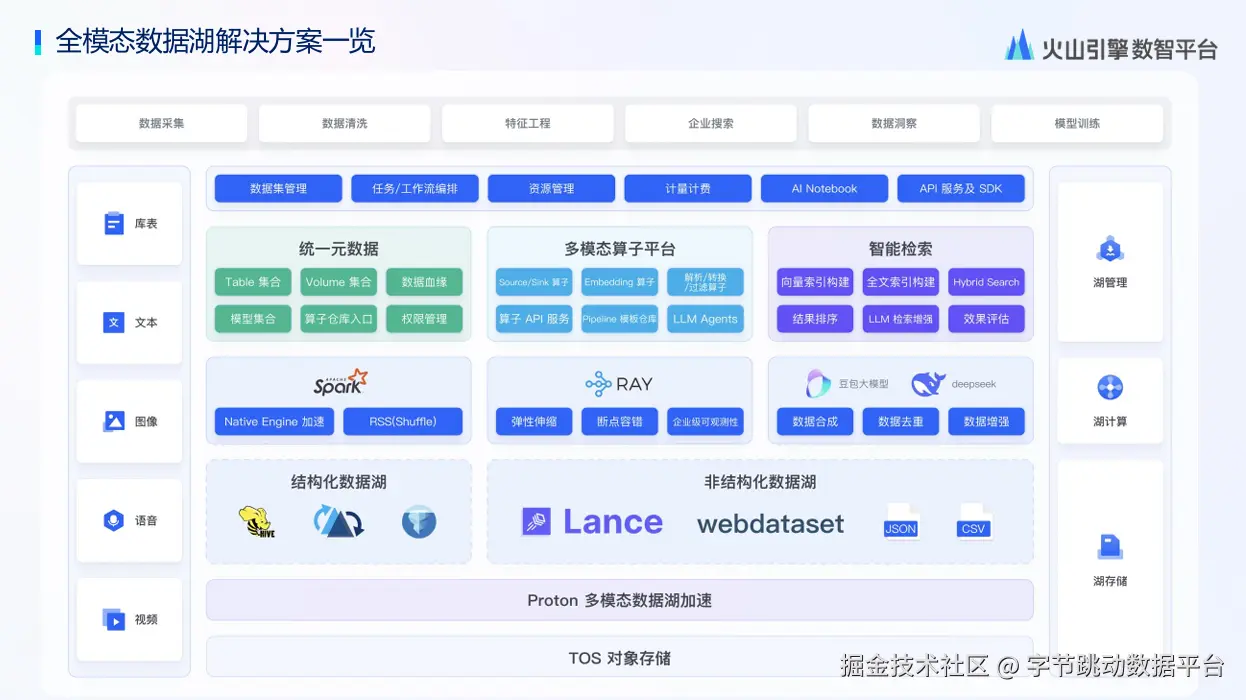
随着智能网联车迈入1Hz数据采集时代,部分信号频率甚至达到100Hz,云端架构面临数据量激增、schema弱化及车云一致性等多重挑战。同时,高级辅助驾驶规模化量产带来动辄百PB级的多模态数据处理需求,传统技术栈在效率、成本和协同性上存在明显瓶颈。火山引擎数据产品解决方案专家指出:"数据飞轮理念虽受认可,但实际应用常受限于高工程协同复杂度与极致处理效率要求。我们的基座设计以开源兼容与AI原生为核心,确保数据高效流转,让其真正成为资产而非负担。"
该能力基座采用开放性架构,聚焦六大关键维度:开箱即用特性、开源兼容性、轻量运维、成本优化、极致性能和AI原生设计。在存储层,方案引入Lance数据湖格式替代传统Parquet,通过列式压缩技术降低30%存储空间,并借助强化元数据描述与高级索引实现多模态数据秒级检索,内置版本管理功能显著提升非结构化数据管理效率。计算层深度整合Spark/Flink大数据栈与Ray/Daft等Python生态框架,通过EMR Ray的分布式并行化能力将算法团队改造成本最小化,在自动化标注场景中已验证可提升GPU利用率20%以上。
实践案例证明该方案具备显著效益。在某主机厂辅助驾驶项目中,火山引擎通过Remote Dataloader解决方案将数据预处理模块与训练集群解耦,使H20训练卡利用率从40%稳定提升至85%以上,单次训练迭代周期缩短50%,云端存储成本降低20%,整体技术降本达20%。另一量产分析项目采用Serverless Flink实时链路与Paimon+ByteHouse湖仓架构,成功将数据新鲜度压缩至分钟级,支撑高频实时决策需求。
展望未来,火山引擎将持续强化智驾与网联场景的多模态湖仓基座性能,推进Ray+Lance技术在量产分析中的落地。随着大模型与数据应用的深度融合,方案将进一步优化数据新鲜度、响应度与AI原生能力,为行业构建以数据消费为导向的要素化治理体系,推动智能驾驶技术向更高阶演进。