楔子:当开发者的"痛点"遇上 AI 的"甜点"
作为一名开发者,我们每天都在与复杂性作斗争。在代码的海洋中,我们渴望拥有一位真正懂我们的"副驾驶":它不仅能快速写出我们想要的模板代码,更能在我们深入一个庞大的遗留项目时,记住各个模块的关联;在我们调试一个棘手的 Bug 时,提供跨文件的洞察。
近年来,AI 编程助手层出不穷,它们确实在一定程度上提升了我们的生产力。但我们或多或少都经历过那些"哭笑不得"的瞬间:聊着聊着,AI 就忘记了我们最初的需求;让它重构一段代码,它却只给出了零碎的、无法直接运行的片段;或者,一个看似强大的新工具,却需要我们抛弃早已顺手的整个工具链去重新适应。这些体验,让 AI 时而像"神器",时而又像"人工智障"。
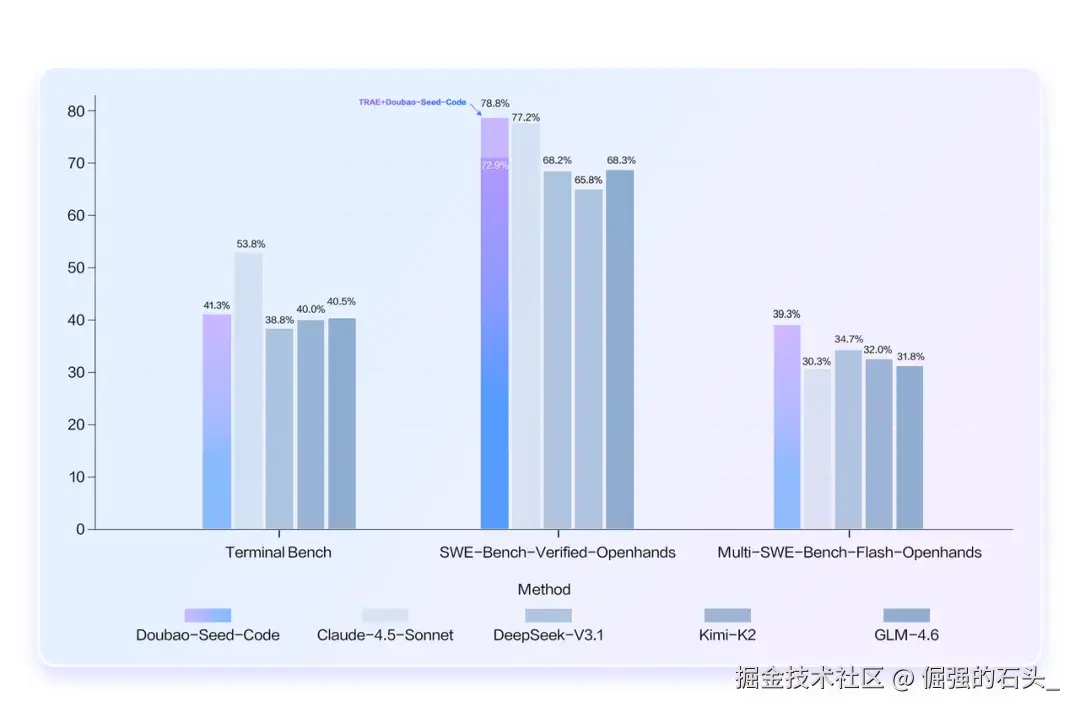
就在我逐渐习惯于这种"时好时坏"的 AI 协作模式时,一款名为 Doubao-Seed-Code 的国产编程大模型进入了我的视野。它并非又一个普通的语言模型,其官方介绍中提到的几个特性,仿佛是精准地瞄准了我们开发者日常工作中的核心痛点:
-
惊人的 256K 长上下文窗口 :这不只是一个数字上的提升。它意味着 AI 的"记忆力"从只能记住几页纸,跃升到能读完一整本厚书。在实践中,这意味着它有潜力理解一个小型项目的完整架构,而不是仅仅聚焦于单个文件,从而在进行重构、添加新功能或修复复杂 Bug 时,提供更具全局观的建议。
-
与主流生态的无缝兼容 :官方明确指出它同时兼容 Anthropic 和 OpenAI 的 API 格式。这对我这种深度
claude-code用户来说,无异于一个巨大的"甜点"。它意味着我不需要改变任何已经形成肌肉记忆的工作流,不需要更换工具,就能"无痛"地将引擎切换到一个可能更强大的核心上。这关乎效率,更关乎宝贵的"心流"不被打断。 -
为真实场景优化的代码能力:除了在各大评测基准上"刷分",它还特别强调了对代码补全、代码解释、跨文件操作等真实开发场景的优化。这表明它的设计目标,是成为一个能干活的"工程师",而不仅仅是一个会考试的"学生"。
-
面向未来的多模态视觉理解 :-Doubao-Seed-Code 自带视觉理解能力,非工具调用实现,这在国内编程模型中为"首发"。VLM训练需要专业团队和数据积累,有一定技术壁垒,doubao 系列模型一直以来视觉理解能力非常强,Seed-Code 模型保持了这个优势 国内市场:DeepSeek V3.1、Kimi K2、GLM 4.6、MiniMax M2 等 Coding 模型均不具备视觉理解能力,或需要依赖MCP实现,将图片转化成语义描述供模型理解,过程中信息折损会很大,效果远不及原生VLM能力;
这些特性组合在一起,描绘了一个极具吸引力的前景:一个记忆力超群、能融入我现有工作流、并且真正理解"写代码"这件事的编程伙伴。
然而,宣传和现实之间往往隔着一条鸿沟。这些诱人的特性,在真实的项目压力下,能发挥出几成功力?它究竟是又一个"PPT 明星",还是一个能真正并肩作战的"战友"?
为了找到答案,我决定亲自上手,为它设计一个"考验"。这个考验并非简单的算法题或代码片段生成,而是两个从零到一、从后端到前端、从开发到部署的完整实战项目。我希望通过这个过程,来检验 Doubao-Seed-Code 在端到端工作流中的真实表现。
这篇文章,便是我这次探索之旅的完整记录。
通过这篇文章,你将收获:
- 一个免登录的实用技巧 :掌握通过环境变量,让你本地的
claude-code工具直接调用豆包 API 的方法。 - 两个开箱即用的实战项目 :
- 一个功能完整的
FastAPITodo 后端服务(附带单元测试)。 - 一个已部署、可通过浏览器公开访问的
Web贪吃蛇小游戏。
- 一个功能完整的
- 一套可复用的行动指南:涵盖了从环境配置、API 接入,到 Prompt 编写和部署上线的全套代码与脚本。
那么,让我们正式开始这次 AI 编程的探索之旅。
第一步:环境搭建与 API 无缝接入
环境搭建
我的开发环境是一台 Ubuntu 22.04 服务器。为了确保后续实验的顺利进行,首先需要搭建好基础的开发环境。
我的环境清单:
- Node.js (18+) :作为
claude-code的运行环境。 - Python (3.10+):作为本次实践项目的编程语言。
- 基础开发工具 :
git、curl、pip、venv等。
你可以通过以下脚本快速完成环境的搭建:
bash
# 更新系统软件包列表
sudo apt update
# 安装 Python, pip, venv, Git 等基础工具
sudo apt install -y curl git python3 python3-venv python3-pip
# 安装 Node.js (推荐使用 nvm 进行版本管理)
# 国内用户如果遇到 Github 连接超时问题,建议使用以下 Gitee 镜像进行安装
export NVM_SOURCE="https://gitee.com/mirrors/nvm.git"
curl -fsSL https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.7/install.sh | bash
source ~/.bashrc
nvm install 18
nvm use 18
# 全局安装 claude-code 工具
npm install -g @anthropic-ai/claude-code
# 验证安装是否成功
claude --version当 claude --version 命令成功返回版本号时,说明我们的工作台已经准备就绪。 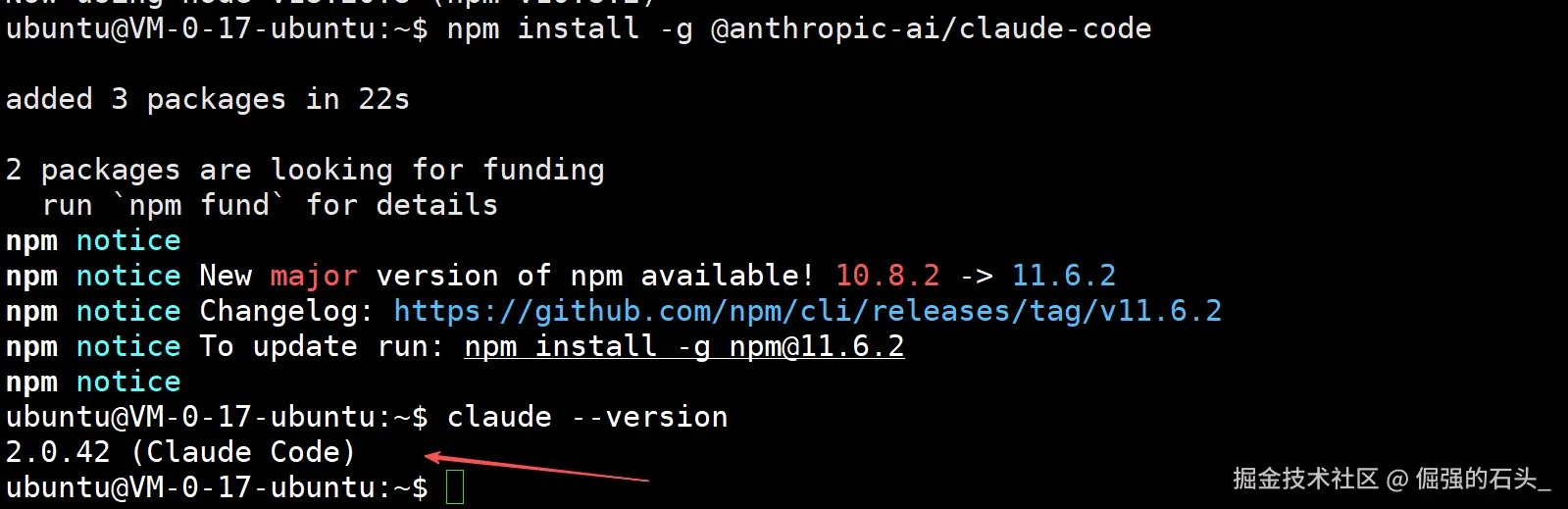
API 接入------实现与豆包模型的无缝连接
这是整个流程中最核心的一步。
Coding Plan:为个人开发者释放成本红利
火山方舟为个人开发者量身打造了"Coding Plan"优惠计划,进一步释放成本红利,最低首月 9.9 元即可畅享豆包编程模型。该套餐支持 Claude Code,以及 veCLI、Cursor、Cline、Codex CLI 等主流工具环境,更借助火山方舟超大资源池,为开发者提供稳定算力保障,获得畅快和稳定的编码体验。 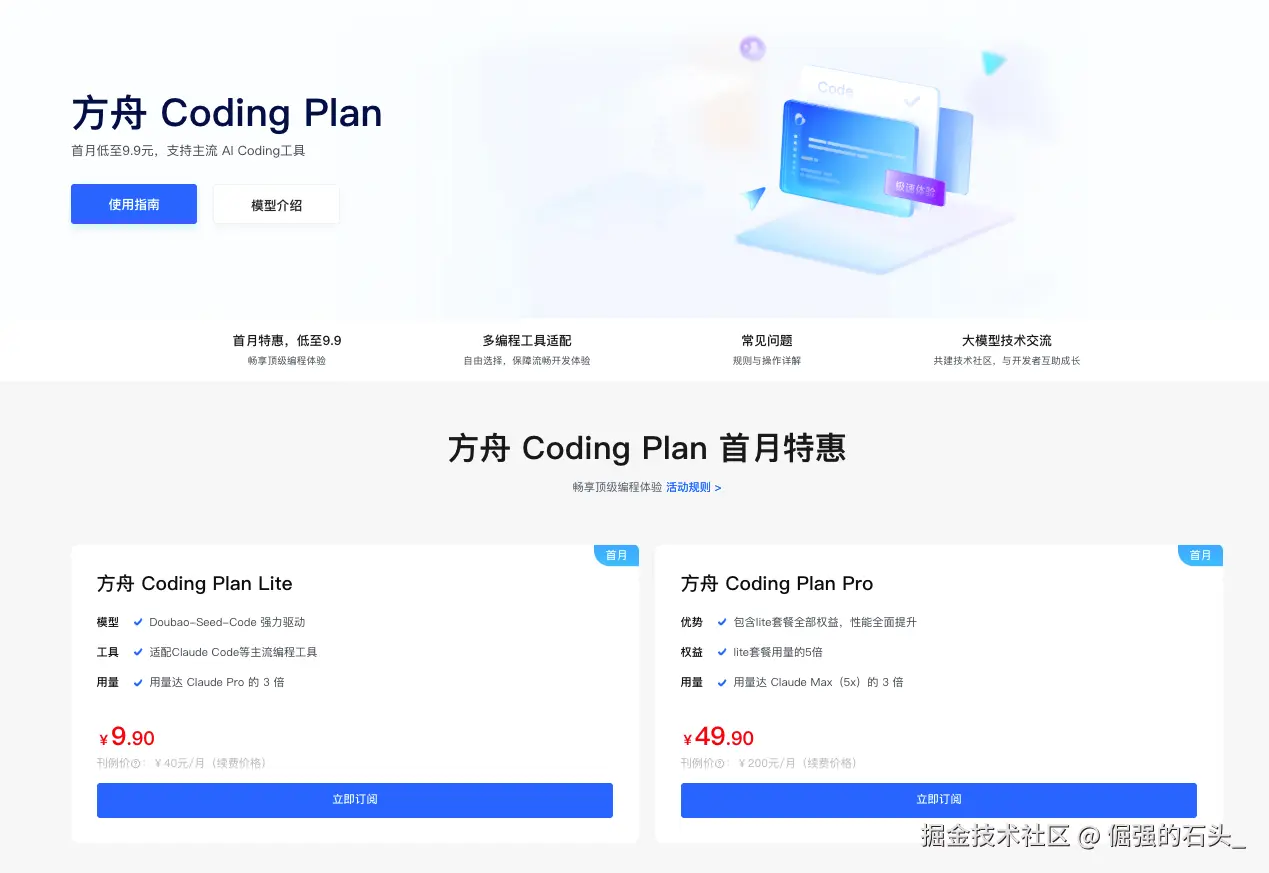 推荐您购买Lite版本的Coding Plan,将有足量tokens支撑测试
推荐您购买Lite版本的Coding Plan,将有足量tokens支撑测试
我们需要从火山方舟(Ark)控制台获取关键信息:
API Key:用于服务认证的密钥。
获取之后,我们就可以利用 claude-code 的环境变量覆盖机制。通过在执行命令时指定特定的环境变量,我们可以将 claude-code 的请求重定向到豆包模型的 API 端点。
我总结了三种不同的配置方式:
方式一:全局配置文件(官方推荐)
根据官方文档的指引,这是最推荐的持久化配置方式。claude-code 安装后,会在你的用户主目录下(~/)自动创建一个配置文件,我们只需要编辑它即可。
-
打开全局配置文件 : 在终端执行以下命令,使用
vim或你喜欢的文本编辑器打开它。如果文件不存在,此命令会自动创建。bashvim ~/.claude/settings.json -
填入配置信息 : 将以下内容粘贴到
settings.json文件中,并确保将YOUR_ARK_API_KEY替换为你自己的火山方舟 API Key。json{ "env": { "ANTHROPIC_AUTH_TOKEN": "YOUR_ARK_API_KEY", "ANTHROPIC_BASE_URL": "https://ark.cn-beijing.volces.com/api/coding", "ANTHROPIC_MODEL": "doubao-seed-code-preview-latest", "API_TIMEOUT_MS": "3000000", "CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC": "1" } }API_TIMEOUT_MS: 延长 API 请求超时时间至 50 分钟,防止因网络波动或模型生成时间长导致中断。CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC: 禁用一些非必要的遥测数据网络请求,优化体验。
保存文件后,你系统中的
claude命令就会默认使用豆包模型,一劳永逸。

方式二:一次性命令行注入(适合快速测试)
如果你只是想临时测试一下,或者在不同的模型间快速切换,可以在执行命令时直接注入环境变量。
bash
ANTHROPIC_BASE_URL="https://ark.cn-beijing.volces.com/api/coding" \
ANTHROPIC_AUTH_TOKEN="\u003c你的方舟API_KEY\u003e" \
ANTHROPIC_MODEL="doubao-seed-code-preview-latest" \
claude这个方法的好处是即用即走,不会影响全局配置。
方式三:项目级配置文件(针对特定项目)
在某些场景下,你可能希望某个特定项目使用不同的模型或 API Key。此时,可以在该项目的根目录下创建独立的配置文件。claude-code 会优先读取项目内的配置。
操作步骤与全局配置类似,只是路径位于项目内部:
- 进入项目目录:
cd /path/to/your/project - 创建并编辑配置文件:
vim .claude/settings.json - 填入该项目专属的配置。
第二步:初试身手------快速生成一个后端 API
API 连接成功后,我进行了第一个实战测试:让豆包模型生成一个带单元测试的 Todo API。
这是一个经典的编程任务,很适合用来检验模型的基础代码生成能力。
步骤1:创建项目结构与环境
-
创建项目目录:首先,我们为项目创建一个文件夹,并进入该目录。
bashmkdir -p ~/projects/doubao-todo cd ~/projects/doubao-todo -
初始化 Python 虚拟环境:为了保持项目依赖的隔离,我们创建一个虚拟环境并激活它。
bashpython3 -m venv .venv source .venv/bin/activate -
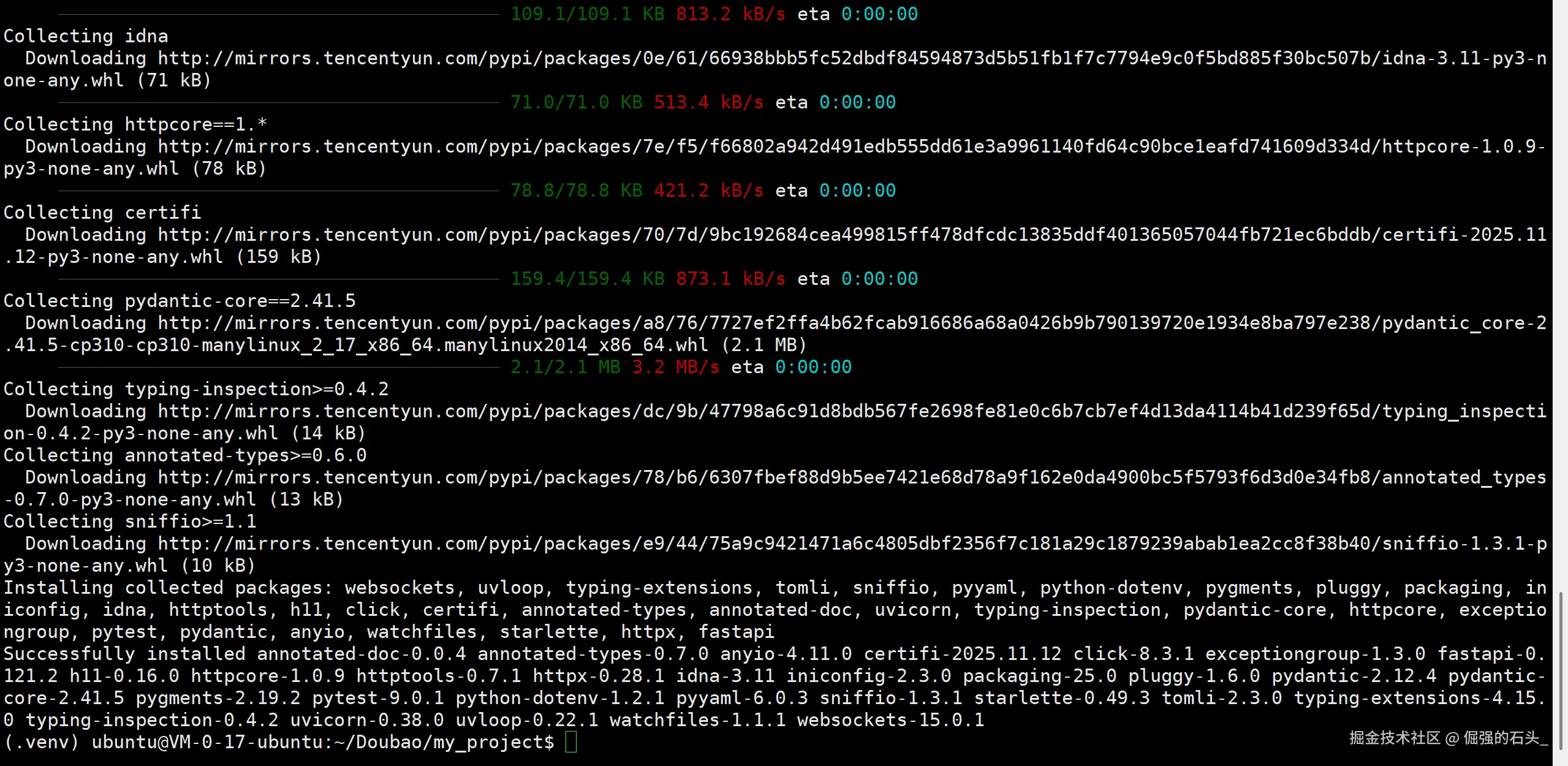
安装依赖库:安装本次项目所需的核心库。
bashpip install fastapi uvicorn[standard] pytest httpx
步骤2:与 AI 协作生成代码
我启动了配置好的 claude,并向其提交了我的详细需求:
\u003e \u003e 我需要一个最小可用的 Todo API,请使用 FastAPI 和 SQLite 实现。 \u003e \u003e 具体要求如下: \u003e - 路由需覆盖 CRUD 操作:`GET/POST/PUT/DELETE /todos` \u003e - 数据模型应包含 `id`, `title`, `done` 三个字段 \u003e - 项目结构应清晰,拆分为 `main.py`, `models.py`, `db.py` 等文件 \u003e - 请为 API 生成完整的 `pytest` 单元测试,并使用 `httpx` 库 \u003e - 最终生成的代码必须能够直接运行,且所有测试需一次性通过。 \u003e
模型会生成 main.py, models.py, db.py, test_main.py 等文件。请根据模型的输出,在项目中创建并填充这些文件。
步骤3:启动服务并执行测试
看到所有测试通过的提示,证明我们的 API 功能已经完美达成。 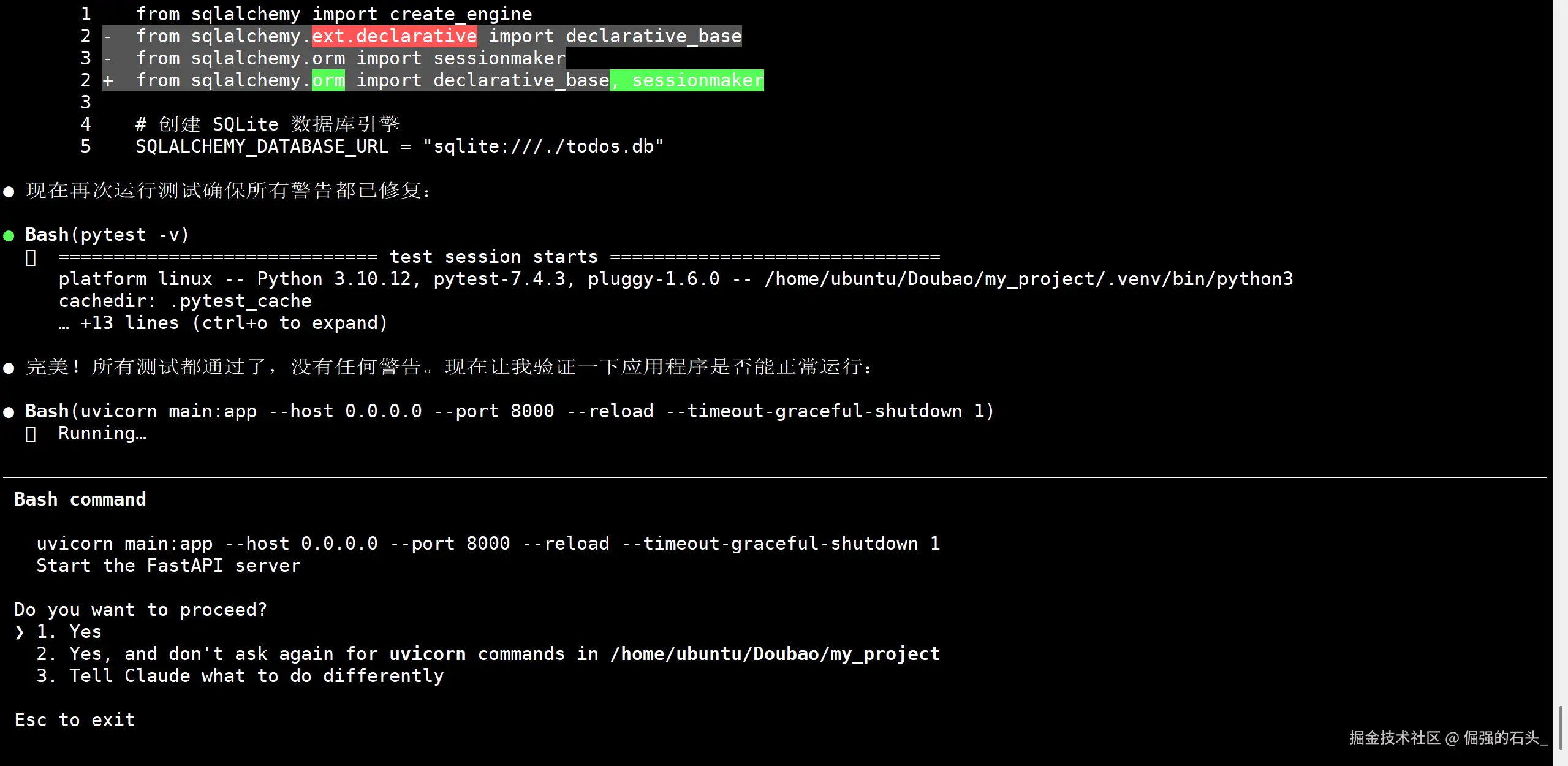
整个过程非常顺畅,模型准确地理解了我的需求,并生成了高质量、结构化的代码。在不到五分钟的时间里,一个经过完整测试的后端服务就成功搭建起来了并主动进行了测试。

第三步:进阶实践------部署一个在线 Web 小游戏
为了进一步检验模型的综合能力,我设定了第二个目标:创建一个贪吃蛇小游戏,并将其部署到 Ubuntu 服务器上,使其能够通过公网访问。
这个任务不仅考验代码生成能力,还涉及到了前端、后端服务以及服务器部署等全流程知识。
步骤1:提交更复杂的指令
我继续在 claude 中向豆包模型描述了我的新需求:
\u003e \u003e 接下来,我们来创建一个 Web 版的贪吃蛇游戏。 \u003e \u003e 前端需求: \u003e - 使用原生的 `HTML/CSS/JS` 实现,不依赖任何第三方框架。 \u003e - 游戏需包含计分板、暂停/继续功能,并且游戏速度应随分数提升而加快。 \u003e - 界面设计应简洁,并能同时适配桌面和移动端设备。 \u003e \u003e 后端需求: \u003e - 使用 `Flask` 编写一个简单的静态文件服务器 `server.py`。 \u003e - 请明确告知项目的文件目录结构(例如 `static` 和 `templates` 文件夹的用途)。 \u003e \u003e 最后,请提供在 Ubuntu 服务器上部署该项目所需的所有命令行脚本。 \u003e 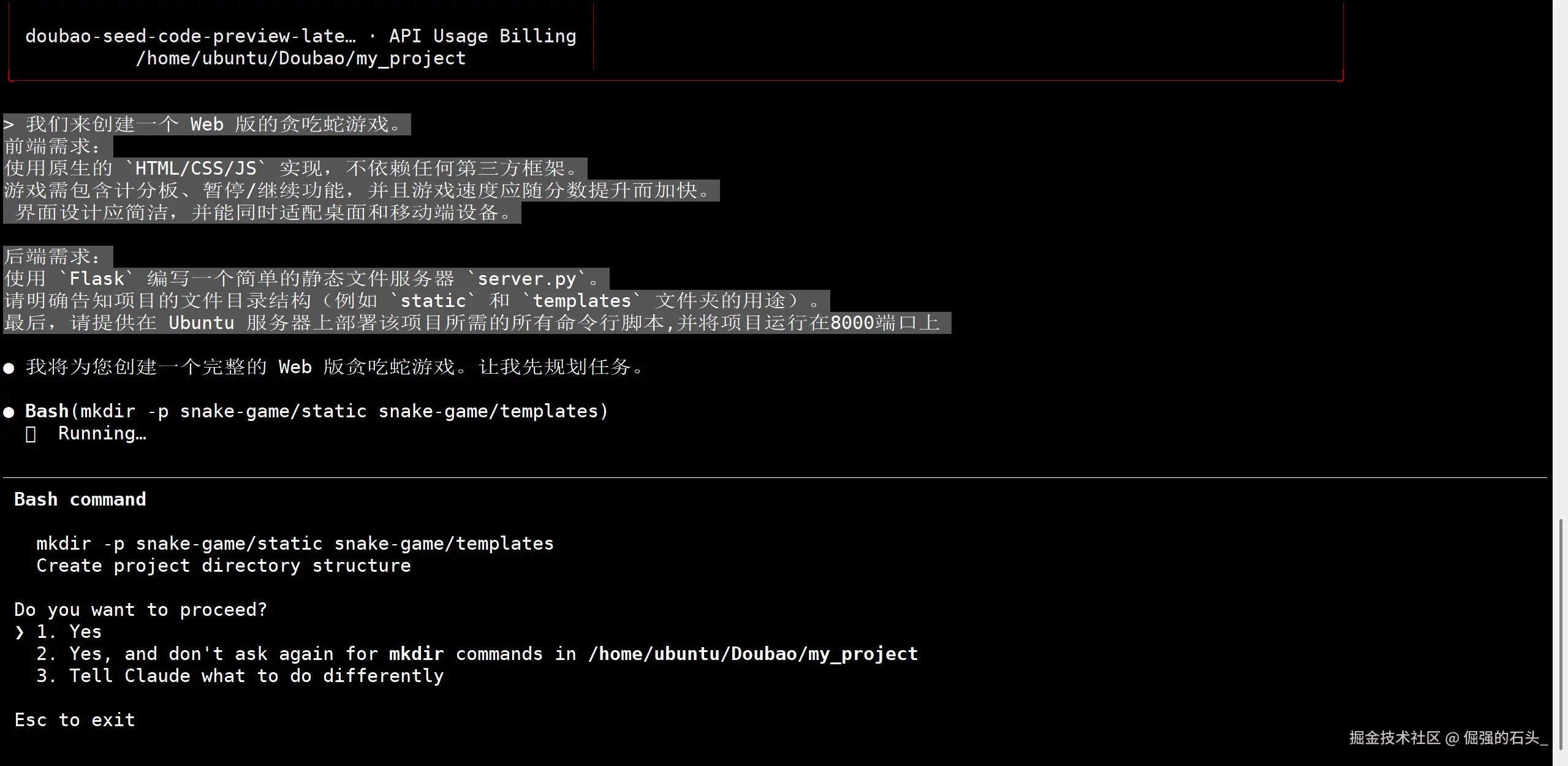
步骤2:创建项目文件结构
模型会生成 server.py, templates/index.html, static/style.css, static/game.js 等文件。并帮我们在服务器上创建对应的目录和文件。 index.html
步骤3:部署与初步验证
-
创建部署脚本
-
启动应用进行测试 :
此时,你可以通过浏览器访问 http://\u003c你的服务器IP\u003e:8000 来确认游戏是否可以正常运行。
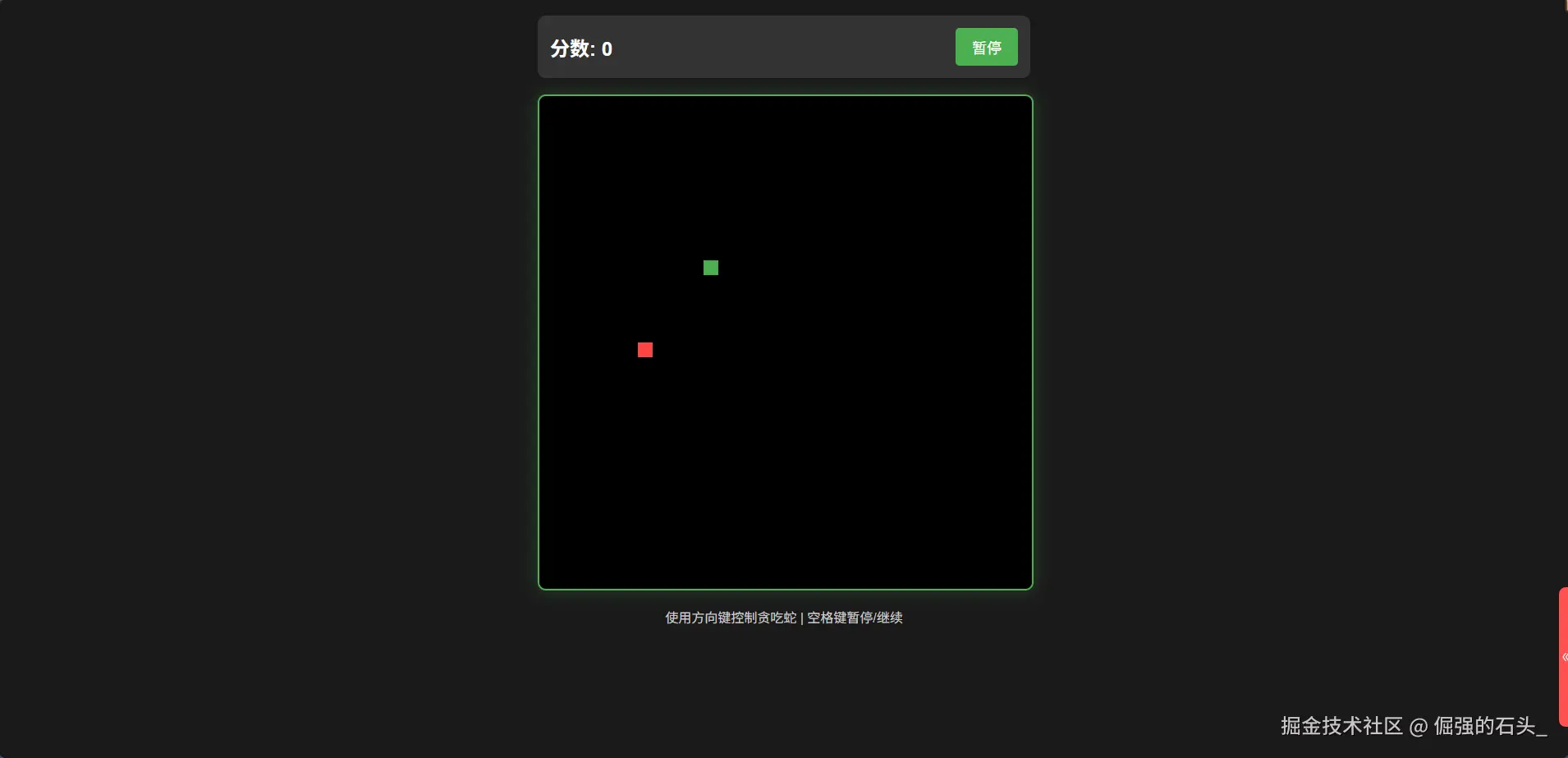
嗯emmm......好像有点过于简洁了,接下来再让他优化一下 
重新测试运行 
现在界面看起来美观多了,不满意还可以让他继续修改,说清楚具体的需求就好 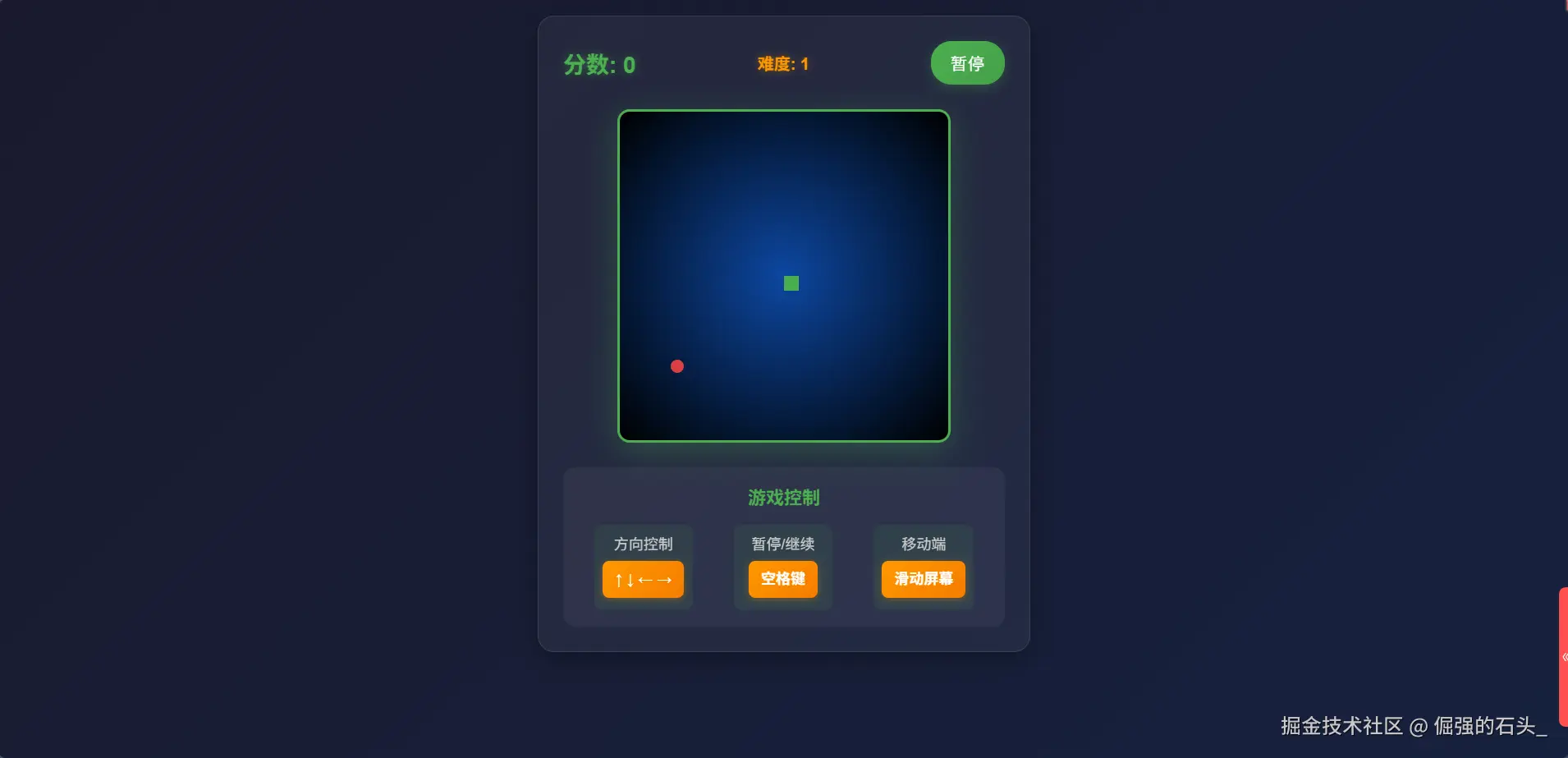
整个流程一气呵成,模型不仅生成了可运行的程序,还提供了详细的部署方案,其表现超出了我的预期。
总结:一次"物超所值"的实践
当我完成这两个实战项目并回顾整个过程时,这次通过 claude-code 结合 Doubao-Seed-Code 的实践,给我留下了深刻的印象。
文章开头提到的那些吸引我的特性,在实践中都得到了不同程度的印证:
- API 的高兼容性是本次能"免登录"平滑体验的基石,它让整个流程的准备工作变得异常简单,真正做到了"即插即用"。
- 强大的代码生成与理解能力在两个项目中体现得淋漓尽致。无论是需要遵循特定结构和规范的后端 API,还是涉及多文件、多语言(HTML/CSS/JS)的前端小游戏,模型都能准确理解我的意图,并给出高质量、可执行的完整方案,甚至连部署脚本都考虑周全。
- 长上下文的优势虽然在这样的小项目中不足以完全展现,但从模型能够一次性处理"前端+后端+部署"的复杂指令来看,其在维持对话连贯性、处理长任务链上的潜力已初见端倪。
总的来说,claude-code + Doubao-Seed-Code 这一组合在使用体验上的表现非常出色,它展示了当前大语言模型在"易用性"和"实用性"上的长足进步。它不仅是一个能写代码片段的工具,更像一个能理解项目全貌、并提供端到端解决方案的初级"虚拟开发者"。
如果你也对 AI 编程抱有兴趣,希望找到一个强大、易用且成本可控的编程伙伴,那么,不妨亲自动手,复刻这趟探索之旅。我相信,你也会有所收获。