作为NLP领域的经典任务,文本分类是入门Transformer模型微调的绝佳实践。本文将以二分类任务为例,详细记录基于BERT预训练模型的微调全流程,从环境配置、数据准备到模型训练、显存优化,带你踩平所有坑点,最终实现一个高性能的文本分类模型。
一、任务背景与技术选型
本次任务聚焦文本二分类 (例如情感分析、垃圾邮件识别等),选择BERT预训练模型进行微调------这是NLP领域"预训练+微调"范式的典型应用,既能复用BERT在大规模语料上学到的语言知识,又能快速适配特定任务。
技术栈:
- 框架:PyTorch + Hugging Face Transformers/Datasets
- 模型:BERT-base(或自定义预训练模型)
- 优化:AdamW优化器 + 混合精度训练 + 显存碎片优化
二、环境搭建与依赖安装
首先搭建稳定的训练环境,推荐使用conda管理环境:
bash
# 创建并激活虚拟环境
conda create -n torch_env python=3.10
conda activate torch_env
# 安装核心依赖
pip install torch transformers datasets pandas若需使用GPU加速,需额外安装对应版本的CUDA和cuDNN(可参考PyTorch官方安装指南)。
三、数据准备:Hugging Face Dataset格式解析
本次实验使用本地自定义数据集 ,需遵循Hugging Face datasets的格式规范:
- 数据集包含
train/test/validation拆分 - 每个样本需包含
text(输入文本)和label(0/1标签)字段
将数据按如下结构存放(与项目路径保持一致):
Remote/
├── data/
│ ├── train-00000-of-00001-xxx.parquet # 训练集
│ ├── test-00000-of-00001-xxx.parquet # 测试集
│ └── validation-00000-of-00001-xxx.parquet # 验证集
├── mode/ # BERT预训练模型文件(config.json、pytorch_model.bin等)
└── train.py # 训练脚本
通过datasets.load_dataset加载本地数据:
python
from datasets import load_dataset
# 加载本地数据集
hf_train_dataset = load_dataset("./Remote/data", split="train")
print(f"数据集规模:{len(hf_train_dataset)}条样本")四、模型构建:BERT + 分类头的经典架构
我们基于Hugging Face的BertModel构建自定义分类模型,核心逻辑是复用BERT的预训练特征,添加单层全连接层做二分类。
python
import torch
from transformers import BertModel, AutoTokenizer
class BertClassifier(torch.nn.Module):
def __init__(self, model_name="./Remote/mode"):
super().__init__()
# 加载预训练BERT模型
self.bert = BertModel.from_pretrained(model_name)
# 分类头:将BERT的768维输出映射到2个类别
self.classifier = torch.nn.Linear(self.bert.config.hidden_size, 2)
def forward(self, **kwargs):
# BERT前向传播,获取[CLS] token的池化输出
outputs = self.bert(**kwargs)
pooled_output = outputs.pooler_output
# 分类头输出logits
logits = self.classifier(pooled_output)
return logits
# 初始化Tokenizer和模型
tokenizer = AutoTokenizer.from_pretrained("./Remote/mode")
model = BertClassifier().to(device)五、训练全流程:从数据加载到模型收敛
训练流程的核心是数据批量处理、设备一致性保证、梯度更新三个环节,以下是关键步骤的代码与解析。
5.1 数据集封装与批量编码
为适配PyTorch的DataLoader,需自定义数据集类,并在collate_fn中完成文本编码和设备迁移:
python
from torch.utils.data import Dataset, DataLoader
class TextDataset(Dataset):
def __init__(self, raw_dataset):
self.raw_dataset = raw_dataset
def __len__(self):
return len(self.raw_dataset)
def __getitem__(self, idx):
return {
"text": self.raw_dataset[idx]["text"],
"label": self.raw_dataset[idx]["label"]
}
# 构建DataLoader,关键在于collate_fn中完成编码和设备迁移
train_loader = DataLoader(
TextDataset(hf_train_dataset),
batch_size=16,
shuffle=True,
collate_fn=lambda batch: (
{k: v.to(device) for k, v in tokenizer.batch_encode_plus(
[item["text"] for item in batch],
padding="longest",
truncation=True,
return_tensors="pt"
).items()},
torch.tensor([item["label"] for item in batch], dtype=torch.long).to(device)
)
)5.2 训练循环与梯度更新
使用AdamW优化器(Transformer微调的首选),结合混合精度训练提升效率:
python
from torch.cuda.amp import autocast, GradScaler
# 初始化损失函数、优化器、梯度缩放器
criterion = torch.nn.CrossEntropyLoss().to(device)
optimizer = torch.optim.AdamW(model.parameters(), lr=2e-5, weight_decay=1e-5)
scaler = GradScaler() # 混合精度训练用
# 训练循环
num_epochs = 3
for epoch in range(num_epochs):
model.train()
total_loss = 0.0
for batch_idx, (encoding, labels) in enumerate(train_loader, 1):
with autocast(): # 启用混合精度
logits = model(**encoding)
loss = criterion(logits, labels)
# 梯度更新(混合精度版本)
optimizer.zero_grad()
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
total_loss += loss.item()
if batch_idx % 10 == 0:
avg_loss = total_loss / batch_idx
print(f"Epoch {epoch+1}/{num_epochs} | Batch {batch_idx} | Avg Loss: {avg_loss:.4f}")
# 每个Epoch后清理显存,防止碎片累积
torch.cuda.empty_cache()
# 保存模型
torch.save({
"model_state_dict": model.state_dict(),
"optimizer_state_dict": optimizer.state_dict(),
"epoch": num_epochs
}, "Remote/qing_model.pth")六、踩坑实录:显存不足与设备不一致的解决方案
训练过程中最常见的两类问题及解决方案如下:
6.1 显存不足(CUDA out of memory)
- 直接方案 :减小
batch_size(如从16改为8)。 - 进阶方案 :
-
启用混合精度训练(如上述代码中的
autocast和GradScaler),显存占用直接减半。 -
梯度累积:通过
accumulation_steps模拟大batch,代码示例:pythonaccumulation_steps = 2 for batch_idx, (encoding, labels) in enumerate(train_loader, 1): with autocast(): logits = model(**encoding) loss = criterion(logits, labels) / accumulation_steps loss.backward() if batch_idx % accumulation_steps == 0: optimizer.step() optimizer.zero_grad()
-
6.2 设备不一致(Expected all tensors to be on the same device)
错误根源是模型、数据、标签不在同一设备 ,解决方案是在collate_fn中显式将所有张量移至目标设备:
python
collate_fn=lambda batch: (
{k: v.to(device) for k, v in tokenizer.batch_encode_plus(...).items()},
torch.tensor(...).to(device)
)七、优化技巧:让训练更高效、更稳定
除了上述问题解决,这些优化技巧能进一步提升训练体验:
-
提前加载Tokenizer :避免在
collate_fn中重复加载,减少IO开销:pythontokenizer = AutoTokenizer.from_pretrained(model_name) # 全局提前加载 -
梯度裁剪 :防止梯度爆炸,在
loss.backward()后添加:pythontorch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0) -
学习率调度 :使用
ReduceLROnPlateau根据损失自动调整学习率:pythonscheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.5, patience=2) # 训练循环中调用 scheduler.step(avg_loss)
八、总结与延伸
本次基于BERT的文本分类训练实战,覆盖了从环境搭建、数据处理、模型构建到训练优化的全流程,核心收获包括:
- 掌握Transformer模型微调的经典范式:
预训练模型 + 分类头。 - 解决NLP训练中最常见的"显存不足"和"设备不一致"问题。
- 学会混合精度训练、梯度累积等高级优化技巧,提升训练效率。
若需进一步提升模型性能,可尝试:
- 更换更大的预训练模型(如
bert-large)或领域适配的预训练模型(如医疗领域的BioBERT)。 - 引入数据增强技术(如回译、同义词替换),提升模型泛化能力。
- 尝试知识蒸馏,将大模型的知识迁移到小模型,平衡性能与效率。
核心代码如下:
python
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from transformers import BertModel, AutoTokenizer
from datasets import load_dataset
import os
# -------------------------- 全局配置 --------------------------
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}") # 新增:打印当前使用的设备
# 动态路径拼接(确保与项目根目录一致)
current_script_dir = os.path.dirname(os.path.abspath(__file__))
project_root = os.path.dirname(current_script_dir)
model_name = os.path.join(project_root, "Remote", "mode")
hf_dataset_dir = os.path.join(project_root, "Remote", "data")
batch_size = 8
num_epochs = 3
learning_rate = 2e-5
# 提前加载Tokenizer(避免每次batch重复加载,提升效率)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# -------------------------- 自定义数据集 --------------------------
class MineDataset(Dataset):
def __init__(self, raw_dataset):
self.raw_dataset = raw_dataset
def __len__(self):
return len(self.raw_dataset)
def __getitem__(self, idx):
return {
"text": self.raw_dataset[idx]["text"],
"label": self.raw_dataset[idx]["label"]
}
# -------------------------- 模型定义 --------------------------
class MineModel(nn.Module):
def __init__(self, model_name=model_name):
super().__init__()
self.bert = BertModel.from_pretrained(model_name)
self.classifier = nn.Linear(self.bert.config.hidden_size, 2) # 二分类任务
def forward(self, **kwargs):
# 简化:直接传递所有编码后的参数(input_ids/attention_mask/token_type_ids)
# BertModel原生支持这些参数,无需过滤
outputs = self.bert(**kwargs)
pooled_output = outputs.pooler_output # 使用BERT的池化输出
logits = self.classifier(pooled_output)
return logits
# -------------------------- 数据加载 --------------------------
print("Starting training preparation...")
print(f"Model path: {model_name}")
print(f"Dataset directory: {hf_dataset_dir}")
# 1. 加载本地数据集(确保数据集格式符合Hugging Face datasets规范)
hf_train_dataset = load_dataset(hf_dataset_dir, split="train")
print(f"Loaded {len(hf_train_dataset)} training samples.")
# 2. 封装自定义数据集
train_dataset = MineDataset(hf_train_dataset)
# 3. 构建DataLoader(核心修复:collate_fn中统一设备)
train_loader = DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True,
collate_fn=lambda batch: (
# 编码文本并将所有张量移到目标设备
{k: v.to(device) for k, v in tokenizer.batch_encode_plus(
[item["text"] for item in batch],
padding="longest", # 按批次最长文本填充
truncation=True, # 截断超过模型最大长度的文本
return_tensors="pt" # 返回PyTorch张量
).items()},
# 标签张量移到目标设备
torch.tensor([item["label"] for item in batch], dtype=torch.long).to(device)
)
)
# -------------------------- 初始化组件 --------------------------
# 模型移到目标设备
model = MineModel().to(device)
# 损失函数(二分类交叉熵)
criterion = nn.CrossEntropyLoss().to(device) # 移到设备(非必须,但统一更稳妥)
# 优化器(AdamW是Transformer模型常用优化器)
optimizer = optim.AdamW(model.parameters(), lr=learning_rate, weight_decay=1e-5) # 新增权重衰减,防止过拟合
# -------------------------- 训练循环 --------------------------
print("\nStarting training...")
for epoch in range(num_epochs):
model.train() # 开启训练模式(启用Dropout等)
total_loss = 0.0
total_steps = len(train_loader)
for batch_idx, (encoding, labels) in enumerate(train_loader, 1):
# 验证设备(可选,用于调试)
# print(f"Batch {batch_idx}: Input device={encoding['input_ids'].device}, Labels device={labels.device}")
# 前向传播
logits = model(**encoding) # 直接传递编码后的所有参数
loss = criterion(logits, labels) # 计算损失
# 反向传播+参数更新
optimizer.zero_grad() # 清空梯度
loss.backward() # 计算梯度
optimizer.step() # 更新参数
# 累计损失
total_loss += loss.item()
# 打印批次信息(每10个批次打印一次,避免输出过多)
if batch_idx % 10 == 0 or batch_idx == total_steps:
avg_loss = total_loss / batch_idx
print(f"Epoch [{epoch+1}/{num_epochs}] | Batch [{batch_idx}/{total_steps}] | Loss: {loss.item():.4f} | Avg Loss: {avg_loss:.4f}")
# -------------------------- 保存模型 --------------------------
# 保存模型状态字典(推荐,占用空间小,灵活度高)
save_path = "qing_model.pth"
torch.save({
"model_state_dict": model.state_dict(),
"optimizer_state_dict": optimizer.state_dict(),
"epoch": num_epochs,
"total_loss": total_loss
}, save_path)
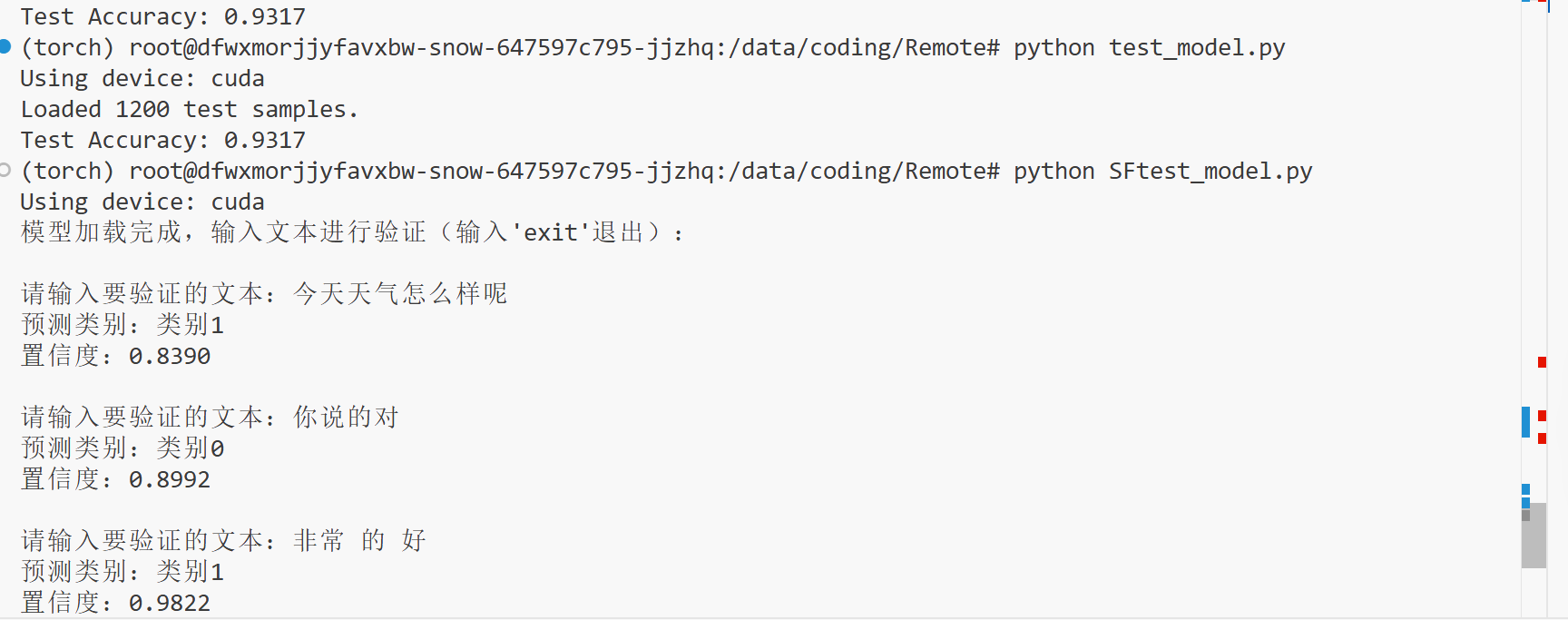
print(f"\nTraining completed! Model saved to: {save_path}")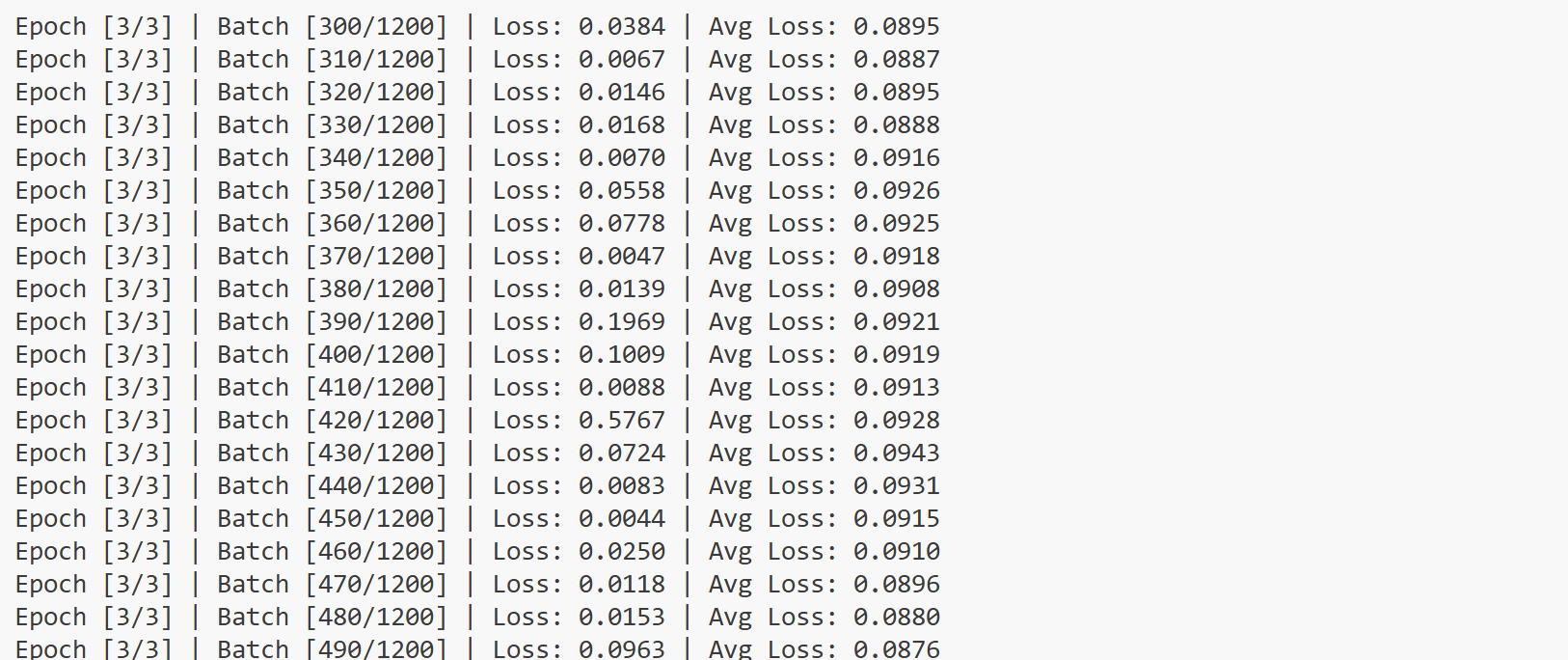
test_model.py
python
import torch
from torch.utils.data import DataLoader, Dataset
from transformers import AutoTokenizer, BertModel
from datasets import load_dataset
import os
# -------------------------- 全局配置 --------------------------
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
# 项目路径配置(与训练代码保持一致)
current_script_dir = os.path.dirname(os.path.abspath(__file__))
project_root = os.path.dirname(current_script_dir)
model_path = os.path.join(project_root, "Remote","qing_model.pth") # 训练好的模型路径
model_name = os.path.join(project_root, "Remote", "mode") # BERT模型路径
hf_dataset_dir = os.path.join(project_root, "Remote", "data") # 数据集路径
# 提前加载Tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)
# -------------------------- 模型定义(与训练代码完全一致) --------------------------
class MineModel(torch.nn.Module):
def __init__(self, model_name=model_name):
super().__init__()
self.bert = BertModel.from_pretrained(model_name)
self.classifier = torch.nn.Linear(self.bert.config.hidden_size, 2) # 二分类
def forward(self, **kwargs):
outputs = self.bert(**kwargs)
pooled_output = outputs.pooler_output
logits = self.classifier(pooled_output)
return logits
# -------------------------- 自定义测试数据集(与训练代码逻辑一致) --------------------------
class TestDataset(Dataset):
def __init__(self, raw_dataset):
self.raw_dataset = raw_dataset
def __len__(self):
return len(self.raw_dataset)
def __getitem__(self, idx):
return {
"text": self.raw_dataset[idx]["text"],
"label": self.raw_dataset[idx]["label"]
}
# -------------------------- 数据加载与预处理 --------------------------
def load_test_data():
# 加载测试数据集
hf_test_dataset = load_dataset(hf_dataset_dir, split="test")
print(f"Loaded {len(hf_test_dataset)} test samples.")
# 封装为自定义Dataset
test_dataset = TestDataset(hf_test_dataset)
# 构建DataLoader(与训练时的collate_fn逻辑一致,确保设备一致)
test_loader = DataLoader(
test_dataset,
batch_size=8, # 测试时batch_size可适当减小,降低显存压力
shuffle=False, # 测试时无需打乱
collate_fn=lambda batch: (
{k: v.to(device) for k, v in tokenizer.batch_encode_plus(
[item["text"] for item in batch],
padding="longest",
truncation=True,
return_tensors="pt"
).items()},
torch.tensor([item["label"] for item in batch], dtype=torch.long).to(device)
)
)
return test_loader
# -------------------------- 模型测试与评估 --------------------------
def test_model():
# 初始化模型并加载权重
model = MineModel().to(device)
model.load_state_dict(torch.load(model_path)["model_state_dict"])
model.eval() # 切换为评估模式(禁用Dropout)
# 加载测试数据
test_loader = load_test_data()
# 推理与评估
total = 0
correct = 0
with torch.no_grad(): # 测试时禁用梯度计算,节省显存
for encoding, labels in test_loader:
logits = model(**encoding)
predictions = torch.argmax(logits, dim=1) # 取概率最大的类别
correct += (predictions == labels).sum().item()
total += labels.size(0)
# 计算准确率
accuracy = correct / total
print(f"Test Accuracy: {accuracy:.4f}")
# -------------------------- 主函数 --------------------------
if __name__ == "__main__":
test_model() 
SFtest_modle.py
python
import torch
from transformers import AutoTokenizer, BertModel
import os
# -------------------------- 全局配置 --------------------------
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
# 项目路径配置
current_script_dir = os.path.dirname(os.path.abspath(__file__))
project_root = os.path.dirname(current_script_dir)
model_path = os.path.join(project_root, "Remote", "qing_model.pth") # 训练好的模型路径
model_name = os.path.join(project_root, "Remote", "mode") # BERT模型路径
# 类别映射(根据你的任务修改,如0-负类,1-正类)
label_map = {0: "类别0", 1: "类别1"}
# 提前加载Tokenizer和模型
tokenizer = AutoTokenizer.from_pretrained(model_name)
# -------------------------- 模型定义 --------------------------
class MineModel(torch.nn.Module):
def __init__(self, model_name=model_name):
super().__init__()
self.bert = BertModel.from_pretrained(model_name)
self.classifier = torch.nn.Linear(self.bert.config.hidden_size, 2) # 二分类
def forward(self, **kwargs):
outputs = self.bert(**kwargs)
pooled_output = outputs.pooler_output
logits = self.classifier(pooled_output)
return logits
# -------------------------- 加载模型 --------------------------
def load_model():
model = MineModel().to(device)
model.load_state_dict(torch.load(model_path, map_location=device)["model_state_dict"])
model.eval() # 切换为评估模式
return model
# -------------------------- 文本推理函数 --------------------------
def predict_text(text, model):
# 文本编码
encoding = tokenizer(
text,
padding="longest",
truncation=True,
return_tensors="pt"
).to(device) # 确保张量在目标设备上
# 模型推理
with torch.no_grad():
logits = model(**encoding)
probs = torch.nn.functional.softmax(logits, dim=1) # 转换为概率
pred_label = torch.argmax(probs, dim=1).item() # 预测类别
confidence = probs[0, pred_label].item() # 置信度
return pred_label, confidence
# -------------------------- 主函数 --------------------------
if __name__ == "__main__":
model = load_model()
print("模型加载完成,输入文本进行验证(输入'exit'退出):")
while True:
text = input("\n请输入要验证的文本:")
if text.lower() == "exit":
break
if not text.strip():
print("文本不能为空,请重新输入!")
continue
pred_label, confidence = predict_text(text, model)
print(f"预测类别:{label_map[pred_label]}")
print(f"置信度:{confidence:.4f}")