序章:HTTP的百年孤独
HTTP(HyperText Transfer Protocol)协议的诞生,标志着万维网(World Wide Web)的开端。他有着漫长的进化史,集中体现了人类与延迟 和阻塞 的血泪抗争。每一次版本升级,都是为了解决上一个版本留下的世纪难题。
让我们从头开始,看看这些老古董们是如何一步步被逼疯,最终不断进化的。
零、HTTP/0.9
在那个单纯到令人发指的年代,在1991年,Tim Berners-Lee发明了万维网,HTTP/0.9随之诞生。这个协议简单到让你想哭:
html
客户端:GET /index.html
服务器:<html>...</html>你的内心:就这? 对,就这!

特点:
-
只有GET方法
-
没有头部、没有状态码、没有错误处理
-
服务器响应完就关闭连接
现实比喻: 就像你走进一家餐厅,喊一声"来份炒饭",厨师直接把饭扔给你,然后关门大吉。
一、HTTP/1.0
HTTP/1.0 (1996) 的出现,是互联网文明的曙光。它解决了 0.9 时代的"裸奔"问题。
新特性
| 特性 | 描述 | 解决的问题 |
|---|---|---|
| 引入请求头和响应头 | 允许携带元数据,如 Content-Type、User-Agent。 |
实现了协议的可扩展性,不再局限于传输纯文本HTML。 |
| 引入状态码 | 200 OK 、404 Not Found 等。 |
请求的处理结果清晰化,便于错误处理和逻辑判断。 |
| 支持多种方法 | POST、HEAD 等。 |
实现了客户端向服务器提交数据(如表单)的能力。 |
| 支持多文档类型 | 支持图片、视频、应用数据等 | 使得Web不再是纯文本的世界,成为富媒体平台。 |
遗留问题
HTTP/1.0 最大的问题,在于它默认采用短连接(Short-lived Connection)。
想象一下这个场景:
你打开一个网页,里面有 1 个 HTML 文件、5 个 CSS 文件、10 张图片。
-
请求 HTML: 建立 TCP 连接 (三次握手) -> 发送请求 -> 接收响应 -> 断开连接 (四次挥手)。
-
请求 CSS 1: 建立 TCP 连接 -> 发送请求 -> 接收响应 -> 断开连接。
-
请求 CSS 2: 建立 TCP 连接 -> 发送请求 -> 接收响应 -> 断开连接。
-
... 重复 16 次!
这简直就Timi扯淡! 每次请求资源,都要经历一次三次握手、四次挥手的完整流程。大量的网络时间都浪费在了建立和断开连接 的路上
TCP:浏览器,我想要问候你母亲!你渲染一个网页,我手都握出老茧了,嘴皮都磨破了!

结论: HTTP/1.0 是个暴躁老哥,效率低下,网络延迟高得让人想 砸电脑。
二、HTTP/1.1
1997 年诞生的HTTP/1.1 学会了长情,解决了1.0 时代频繁握手挥手的延迟地狱,成为使用时间最长、影响最深远的HTTP版本。
持久连接(Keep-Alive)
HTTP/1.1 默认开启 了持久连接 Connection: keep-alive
bash
# 新的工作方式
客户端:你好,我要A文件 → 收到A → 我还要B → 收到B → 我还要C → 收到C → 这次真再见了| 其他重要优化 | 解决的问题 |
|---|---|
| Host 字段 | 解决了虚拟主机 问题。服务器可以根据 Host 头知道你要访问哪个网站,一台服务器可以托管成千上万个域名。 |
| 管道化(Pipelining) | 客户端可以一股脑地发送多个请求,而无需等待前一个响应。 |
| 分块传输编码 | 解决了动态内容生成时,服务器必须等所有内容生成完才能发送 Content-Length 的问题。 |
致命缺陷
HTTP/1.1 最大的贡献是引入了管道化,但管道化也暴露了它的致命伤 :应用层队头阻塞 。HTTP/1.1 的管道化有一个铁律 :请求可以乱序发,但响应必须按顺序回!
想象你在一个TCP 连接上点了三道菜:
-
请求 A: 一份沙拉(5分钟做好)
-
请求 B: 一份佛跳墙(巨慢,需要 30年)
-
请求 C: 一份米饭(15分钟做好)
你一股脑把 A、B、C 的订单都给了服务员(管道化)。服务器很快做好了沙拉(A)和米饭(C) 但是,由于 HTTP/1.1 的 按序返回 铁律,服务器必须:
-
等待佛跳墙(B)做好。
-
即使 A 和 C 已经好了,也必须在 B 后面排队!
结果: 佛跳墙堵住了整个队伍的头,导致后面的沙拉和米饭无法交付,你终于饿死在了这条TCP连接上。这就是应用层队头阻塞。
彩蛋环节🎊
(1)为什么要有这个铁律?
因为 HTTP/1.1 的报文是纯文本 的,浏览器无法仅凭报文内容判断哪个响应对应哪个请求。它只能通过发送顺序 来匹配。一旦乱序,浏览器就懵了,不知道哪个响应是哪个请求的。
结论: HTTP/1.1 就像一个有强迫症的处女座 ,虽然解决了连接开销,但却被自己设定的"顺序"规则给活活卡死了。管道化在实际应用中几乎被禁用,浏览器默认只使用 6 个 TCP 连接来并发请求,这又回到了"多连接"的老路,治标不治本。
(2)管道化
虽然管道化在理论上很美好,但在实际应用中却是个巨大的失败,几乎所有主流浏览器都默认禁用或从未完全实现它。管道化的三宗罪:
-
队头阻塞(HOL Blocking): 这是最致命的,如上所述,一个慢响应会阻塞所有后续响应。
-
幂等性问题: 管道化允许客户端在收到响应前发送下一个请求。如果发送了非幂等请求(如
POST),而第一个请求在服务器端处理到一半时连接断开,客户端会重发所有请求。这可能导致POST请求被重复执行 ,造成不可预知的后果(比如重复下单、重复扣款,这简直是灾难!)。 -
实现复杂性: 服务器端和中间代理对管道化的支持不一致,导致兼容性问题严重。
三、HTTP/2.0
为了彻底解决应用层队头阻塞这个世纪难题 ,在2015年 HTTP/2.0 带着多路复用的王牌登场了。
核心变化
HTTP/2 的核心思想是:在一个 TCP 连接上,实现真正的并发传输 。HTTP/2 在应用层和传输层之间增加了一个二进制分帧层。
-
报文格式革命: HTTP/1.1 的纯文本报文被拆解成一个个小的、带有唯一标识符 的二进制帧(Frame)。
-
流(Stream): 一个请求或响应的所有帧组成一个流(Stream) ,每个流都有一个唯一的 Stream ID 。
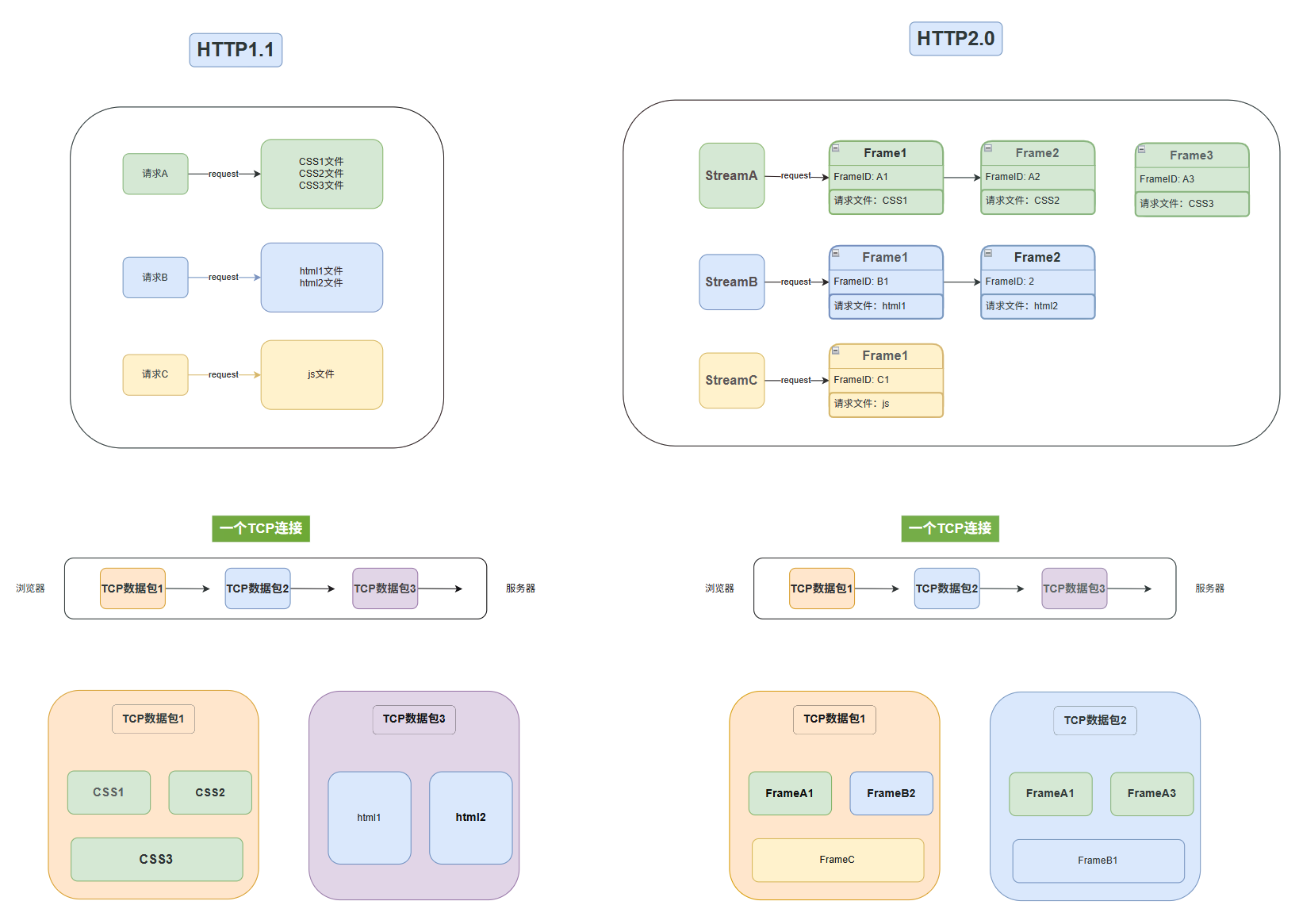
多路复用
有了 Stream ID,服务器就可以:
-
乱序发送帧: 服务器不再需要等待慢请求的响应,它可以把所有流的帧一股脑地塞进一个 TCP 连接里,乱序发送。
-
客户端重组: 客户端收到这些乱序的帧后,根据帧上的 Stream ID ,把属于同一个流的帧重新组装成完整的结果: 那个慢吞吞的"佛跳墙"流(Stream B)的帧,不会再阻塞"沙拉"流(Stream A)和"米饭"流(Stream C)的帧。应用层队头阻塞,卒!
| 其他重要优化 | 解决的问题 |
|---|---|
| 头部压缩(HPACK) | 静态字典(method: GET、status: 200直接用一个索引号表示)、动态字典、霍夫曼编码(对字符串值进行压缩) |
| 流优先级(Stream Priority) | 客户端给每个流设置一个 31 位的优先级值,服务器根据这个优先级,决定资源的分配和帧的发送顺序 |
| 服务器推送(Server Push) | 服务器可以"预测"客户端需要什么资源,并主动推过去。 |
致命缺陷
HTTP/2 解决了应用层的问题,但它依然基于 TCP,传输层队头阻塞 这个老六还在!。TCP 协议的核心设计 是:保证字节流的有序、可靠交付 。它把整个 TCP 连接看作一个单一的、有序的数据流。
想象一下,你点了三个菜:
-
A菜:大份水煮鱼(流1)
-
B菜:小份拍黄瓜(流2)
-
C菜:米饭(流3)
外卖小哥第一个包丢了(里面有鱼、黄瓜、米饭),即使第二个包(剩下的鱼和黄瓜)和第三个包(最后的鱼)到了,你也拿不到!必须等第一个包重做送来。

这就是HTTP/2的TCP层队头阻塞 解决方案: 既然 TCP 这个猪队友改不了,那就换掉它!
四、HTTP/3.0
既然 TCP 的祖传老毛病无法根治,HTTP/3 (2022) 做出了一个惊天动地的决定:抛弃 TCP,拥抱 UDP!
QUIC协议
UDP是不可靠、无序 的。它就像一个"甩手掌柜",只管把数据包扔出去,至于能不能到、到没到,它一概不管 。QUIC (Quick UDP Internet Connections) 协议,就是基于UDP ,重新实现了 TCP 的所有优点,并解决了它的所有缺点。 QUIC 的核心思想: 把 TCP 的可靠性、HTTP/2 的多路复用、TLS 的安全性 全部搬到应用层自己实现!
彻底解决传输层队头阻塞
QUIC 协议的核心在于其流(Stream) 机制的独立性。
-
流是独立的: QUIC 的流是互相独立的。一个流的丢失,只会影响该流的数据交付。
-
流内有序: 在每个流内部 ,QUIC 依然通过包序号 和偏移量来保证数据的有序交付。
-
流间无序: 不同的流之间,数据包可以乱序到达,乱序交付。
QUIC 如何处理丢包?
我们用一个实施级的例子来彻底掰开揉碎 QUIC 的独立流机制。假设我们有三个流:流 A、流 B、流 C。
| QUIC 包 | 内容 | 状态 | 影响 |
|---|---|---|---|
| 包 1 | A 数据帧 1 B 数据1 | 丢包! | 包含 A 和 B 的初始数据,需要重传。 |
| 包 2 | C 数据帧 1 A 数据帧 2 | 正常到达 | C 的数据可以立即交付 。A 的数据帧 2 虽然先到,但它知道 A 数据帧 1 还没到,所以只阻塞 A 流。 |
| 包 3 | B 数据帧 2 A 数据帧 3 | 正常到达 | B 的数据帧 2 虽然先到,但它知道 B 数据帧 1 还没到,所以只阻塞 B 流。 |
流 C :数据帧 1 立即交付,完全不受 QUIC 包 1 丢失的影响。
流 A 和 流 B :它们各自的数据帧 2 和 3 已经到达,但被 QUIC 协议在流内部按序缓存,等待丢失的帧 1 重传。
结论: 丢包的影响被完美地隔离 在了各自的流内部。这就是 QUIC 彻底解决传输层队头阻塞的秘密武器!
想象一下,这次外卖用了独立保温袋:
-
袋1:鱼+黄瓜 ← 丢了
-
袋2:米饭+剩下的鱼 ← 到了,你先吃米饭和这部分鱼
-
袋3:剩下的黄瓜+最后的鱼 ← 到了,继续吃
结果: 每个菜(流)的交付完全独立 , 传输层队头阻塞彻底死亡!
UDP 如何实现可靠传输?
(面试必考题)既然 UDP 不可靠,QUIC 是如何实现比 TCP 更高效的可靠性的?
| 可靠性机制 | QUIC 的实现(基于 UDP) | 相比 TCP 的优势 |
|---|---|---|
| 连接建立 | 1-RTT/0-RTT 握手。将 TCP 三次握手和 TLS1.3 握手合并。 | TCP 需要 3 次握手 + TLS 2-3 次握手。QUIC 只需要 1 次往返(甚至 0 次),连接速度快到爆炸! |
| 包序号与确认 | 使用包序号(Packet Number) ,但不依赖 于字节偏移量。使用ACK 帧 进行确认,支持选择性确认(SACK)。 | TCP 的序号是基于字节的,重传复杂。QUIC 的序号是基于包的,更简单高效。 |
| 重传机制 | 丢失的包重传时,会使用新的包序号。 | 避免了 TCP 中重传包和原始包的序号冲突问题,简化了接收端的处理逻辑。 |
| 拥塞控制 | 拥塞控制算法在应用层实现。 | 可以根据网络环境灵活更换拥塞控制算法(如 BBR),无需等待操作系统内核更新。 |
| 连接迁移 | 使用**连接 ID(Connection ID)**来标识连接,而不是 IP 地址和端口号。 | 解决了用户从 Wi-Fi 切换到 4G 时,TCP必须断开重连导致连接抖动。QUIC 可以无缝切换,用户毫无感知! |
五、总结
HTTP 的进化史,就是一部不断将"队头阻塞"从应用层 推向传输层 ,最终在传输层彻底解决的历史。
| 版本 | 队头阻塞位置 | 核心解决手段 | 遗留的"世纪难题" |
|---|---|---|---|
| HTTP/1.1 | 应用层 | 持久连接、管道化(失败) | 响应必须按序返回,导致慢请求阻塞所有请求。 |
| HTTP/2 | 传输层 | 二进制分帧、多路复用 | 基于 TCP,一个数据包丢失,阻塞整个连接上的所有流。 |
| HTTP/3 | 无 | 基于 UDP 的 QUIC 协议 | QUIC 流独立多路复用,一个流的丢失不影响其他流。彻底解决! |
如果您在面试中能把这些掰开揉碎的细节讲清楚,面试官不给你 Offer,那他就是瞎了眼!
六、面试官:请开始你的表演!
为了让您在面试中能够一击毙命,我们用最清晰的表格,归纳了 HTTP/1.1、HTTP/2 和 HTTP/3 的核心对比点

| 特性 | HTTP/1.1 | HTTP/2 | HTTP/3 (QUIC) |
|---|---|---|---|
| 传输协议 | TCP | TCP | UDP (基于 QUIC) |
| 连接建立 | 3 次握手 + TLS 握手 | 3 次握手 + TLS 握手 | 1-RTT/0-RTT 握手 (TLS 1.3 集成) |
| 报文格式 | 纯文本 (可读性高,但冗余) | 二进制帧 (不可读,但高效) | 二进制帧 (QUIC 帧) |
| 多路复用 | 无 (通过多连接或管道化实现伪并发) | 有 (应用层流独立,但共享 TCP 连接) | 有 (QUIC 流独立,基于 UDP) |
| 队头阻塞 | 应用层 HOL (响应必须按序) | 传输层 HOL (TCP 丢包阻塞所有流) | 无 (流独立,丢包只影响单个流) |
| 头部压缩 | 无 (每次重复发送) | HPACK (静态表+动态表) | QPACK (更安全、更高效的动态表) |
| 流优先级 | 无 | 有 (客户端可设置) | 有 (流独立,优先级控制更精细) |
| 连接迁移 | 无 (切换网络必须断开重连) | 无 | 有 (基于 Connection ID,无缝切换) |
| 性能瓶颈 | 频繁握手、应用层阻塞 | TCP 丢包阻塞 | 部署环境对 UDP 的限制 |
面试官最爱问的三个问题
-
Q: HTTP/2 解决了 HTTP/1.1 的队头阻塞吗?
- 部分解决。 它解决了应用层 的队头阻塞(通过多路复用),但由于它依然基于 TCP,所以它继承了 TCP 的传输层队头阻塞。一个 TCP 包丢失,会阻塞所有 HTTP/2 流。
-
Q: HTTP/3 为什么选择 UDP?
- 因为 TCP 的传输层队头阻塞 是其基因缺陷,无法通过上层协议解决。UDP 是一个无序、不可靠 的协议,QUIC 可以在其之上重新实现 一套更先进、更灵活的可靠传输机制,从而彻底消除队头阻塞。
-
Q: QUIC 如何实现可靠传输?
- QUIC 在 UDP 上实现了自己的可靠性机制 :它使用独立的流 ID 和包序号 来保证流内有序和流间独立;它使用ACK 帧 和新的重传机制 来保证可靠交付;它将 TLS 1.3 集成到握手过程中,实现了 1-RTT/0-RTT 快速连接。
每个版本都在突破前代的局限,恰如人生成长。我们总在既有框架内优化,却鲜有勇气如HTTP/3般彻底重构底层协议。真正的突破不在于做得更好,而在于重新定义"好"------打破思维里的TCP,在UDP般不确定的世界里,构建属于自己的可靠传输。
参考文献
1 MDN Web Docs. HTTP 的发展.
2 知乎. 关于队头阻塞(Head-of-Line blocking),看这一篇就足够了.
3 CSDN. 为什么HTTP/3要引入UDP?(快速了解QUIC).
4 The Byte. QUIC 设计原理与实践.
5 InfoQ. 一文读懂QUIC协议:更快、更稳、更高效的网络通信.
6 CSDN. HTTP1.1 对头阻塞和HTTP2 中对其的解决措施.