本文是对"云计算"课程学习中"MapReduce编程实现计算一个大文本文件中所有单词出现的个数"的实验步骤记录。若有错误,欢迎交流指正。
实验环境:3台CentOS 7虚拟机,均已配置Java1.8、zookeeper、hadoop;Eclipse和JDK
目录
- [1 前置准备](#1 前置准备)
- [2 修改hadoop配置文件](#2 修改hadoop配置文件)
-
- [2.1 mapred-site.xml](#2.1 mapred-site.xml)
- [2.2 yarn-site.xml](#2.2 yarn-site.xml)
- [3 分发配置](#3 分发配置)
- [4 启动集群](#4 启动集群)
- [5 新建Java工程](#5 新建Java工程)
-
- [5.1 新建项目](#5.1 新建项目)
- [5.2 代码编写](#5.2 代码编写)
- [5.3 配置jar包](#5.3 配置jar包)
- [5.4 导出可执行jar](#5.4 导出可执行jar)
- [6 新建测试用文件](#6 新建测试用文件)
- [7 运行代码](#7 运行代码)
-
- [7.1 Java版本报错的解决方法](#7.1 Java版本报错的解决方法)
- [8 运行结果](#8 运行结果)
-
- [8.1 再次运行的一个注意事项](#8.1 再次运行的一个注意事项)
1 前置准备
要想在windows中的浏览器以主机名访问虚拟机(包括ping命令等),需要配置windows的hosts文件。打开以下路径,找到hosts文件
C:\Windows\System32\drivers\etc
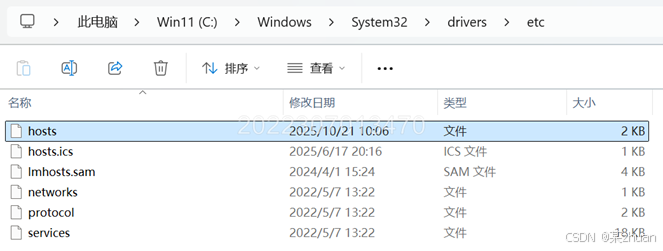
添加node1 node2 node3 的主机名到IP地址的映射
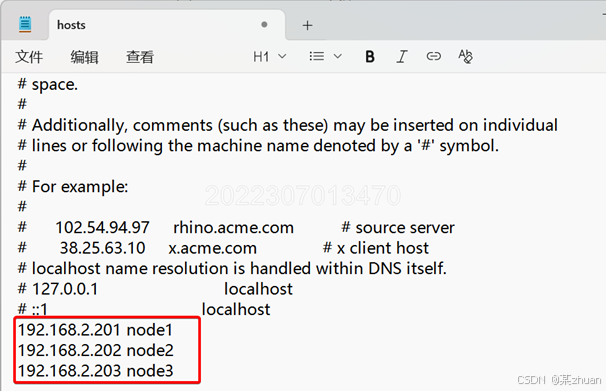
直接保存,会提示没有权限,所以先保存到其他位置
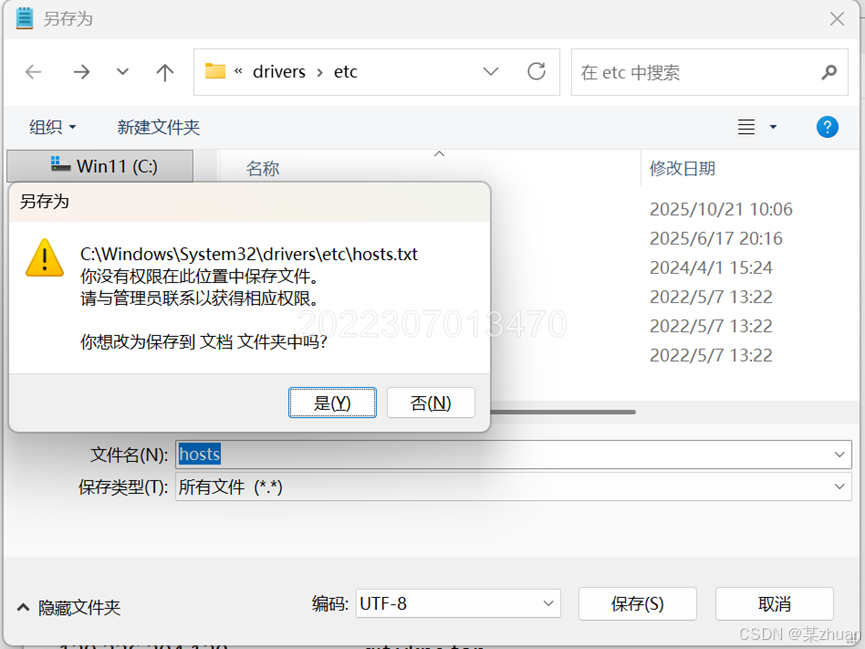
然后将修改后的hosts文件复制回刚才的目录,管理员授权,然后覆盖文件。
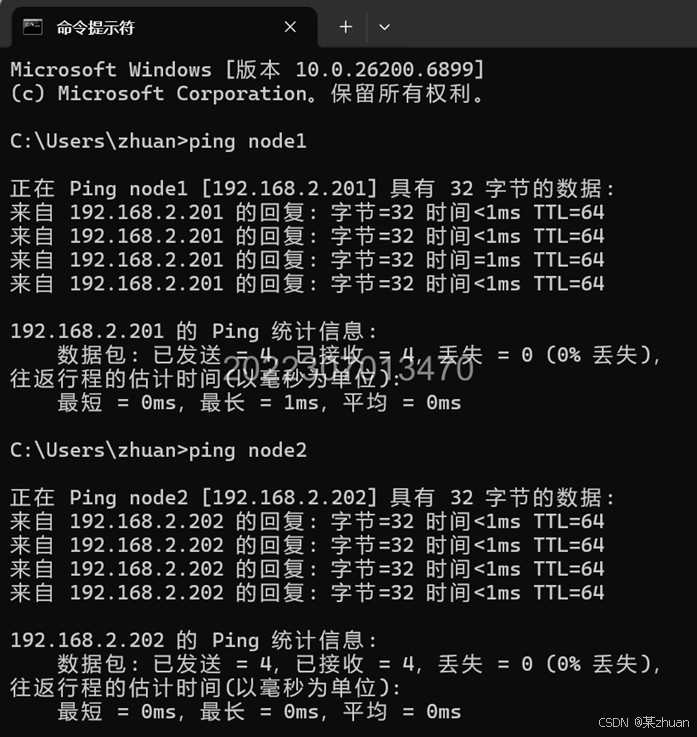
测试方法:
在cmd中ping node1,可以ping通,说明hosts配置完成。
2 修改hadoop配置文件
2.1 mapred-site.xml
bash
cd /usr/hadoop/etc/hadoop/
mv mapred-site.xml.template mapred-site.xml
vi mapred-site.xml添加以下内容,如下图所示
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
2.2 yarn-site.xml
bash
vi yarn-site.xml添加以下内容
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>rm_cluster</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node2</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node1:2181,node2:2181,node3:2181</value>
</property>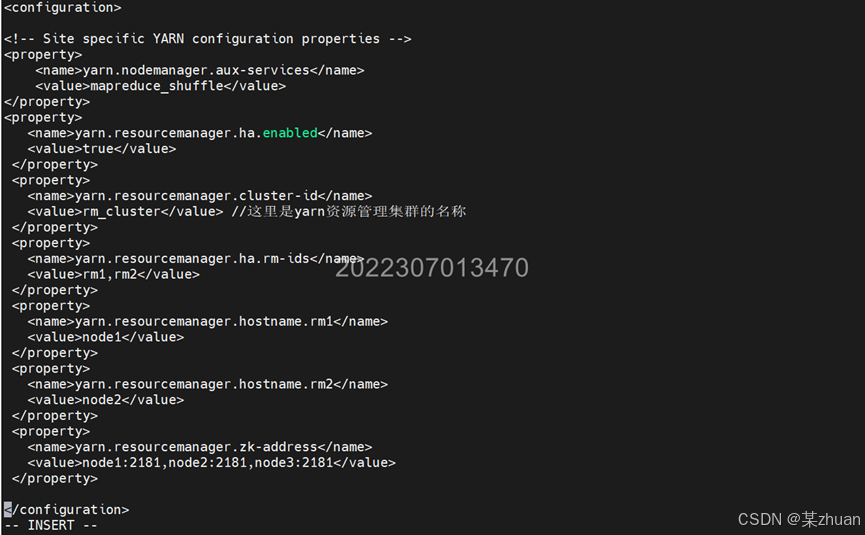
3 分发配置
拷贝mapred-site.xml、yarn-site.xml至node2、node3节点
bash
cd /usr/hadoop/etc/hadoop/
scp mapred-site.xml root@node2:/usr/hadoop/etc/hadoop/
scp mapred-site.xml root@node3:/usr/hadoop/etc/hadoop/
scp yarn-site.xml root@node2:/usr/hadoop/etc/hadoop/
scp yarn-site.xml root@node3:/usr/hadoop/etc/hadoop/4 启动集群
三个节点中,均需要执行以下命令启动zookeeper
bash
zkServer.sh startnode1启动dfs和yarn,执行以下命令
bash
start-dfs.sh
start-yarn.sh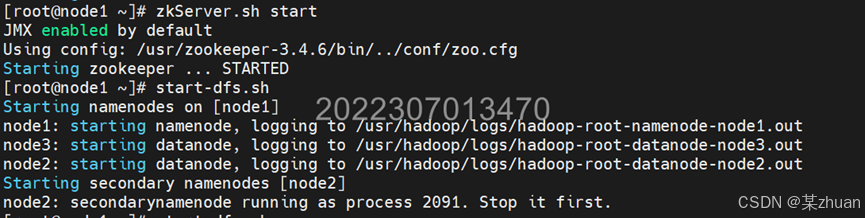

node2中需要启动ResourceManager,使用以下命令
bash
yarn-daemon.sh start resourcemanager
启动完成,使用jps查看个节点的进程,如下表所示则正常:
| 节点 | 进程 |
|---|---|
| node1 | Jps, QuorumPeerMain, ResourcesManager, Namenode |
| node2 | Jps, NodeManager, DataNode, QuorumPeerMain, ResourcesManager |
| node3 | Jps, QuorumPeerMain, DataNode |
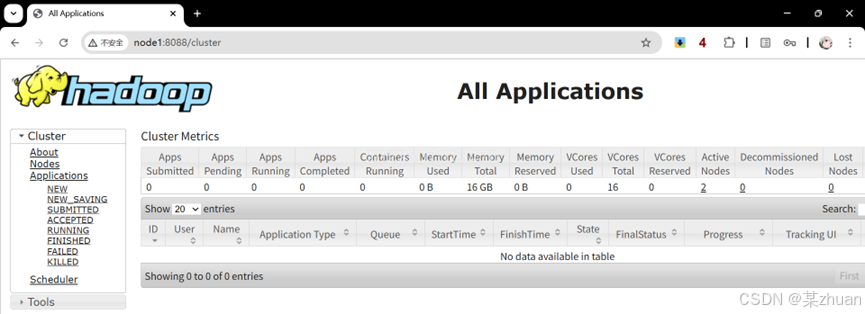
测试启动状态:
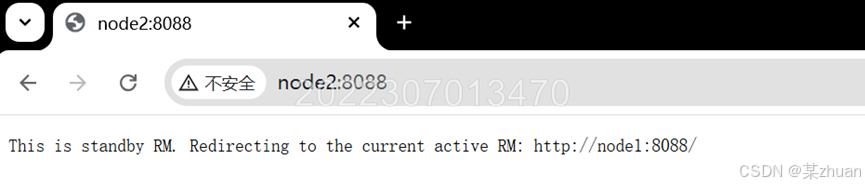
通过浏览器访问http://node1:8088 和 http://node2:8088 ,能看到下图所示的内容
如果windows中配置了hosts,网页可以在windows的浏览器中打开,否则需要在虚拟机的浏览器中打开。
5 新建Java工程
5.1 新建项目
启动eclipse软件,选择工作区路径
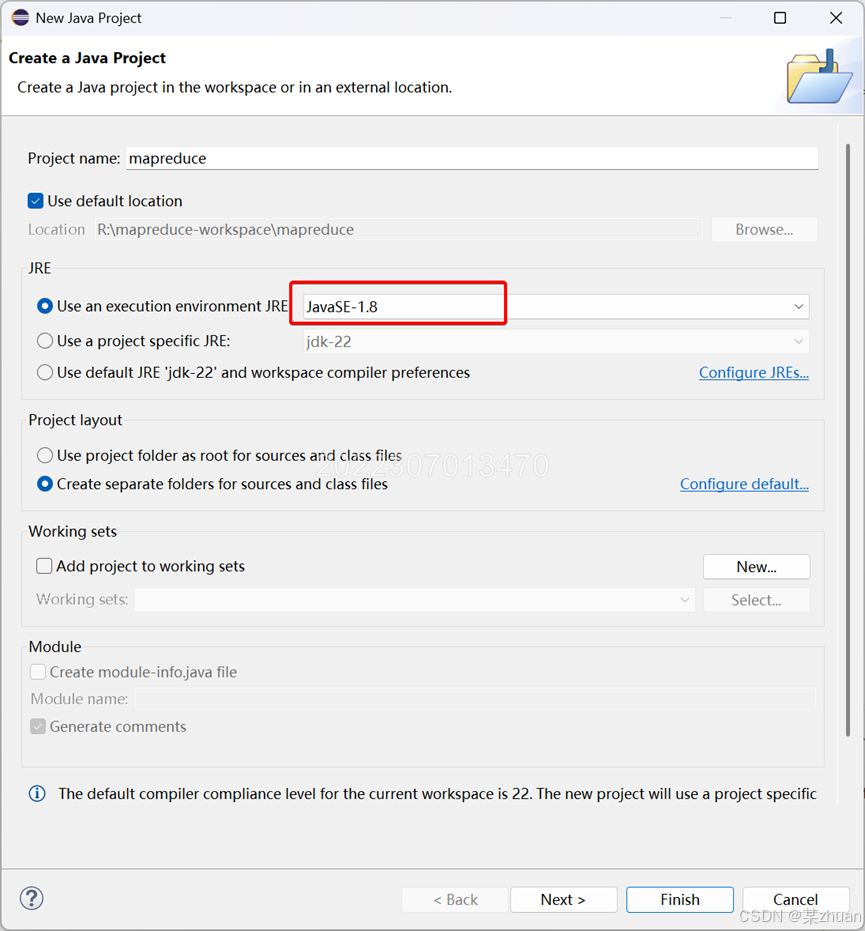
新建java工程,设置java环境,我这里能够设置的最低版本就是java 1.8。工程名字可以自己设置,此处置的名字是mapreduce。其他选项保持默认即可。
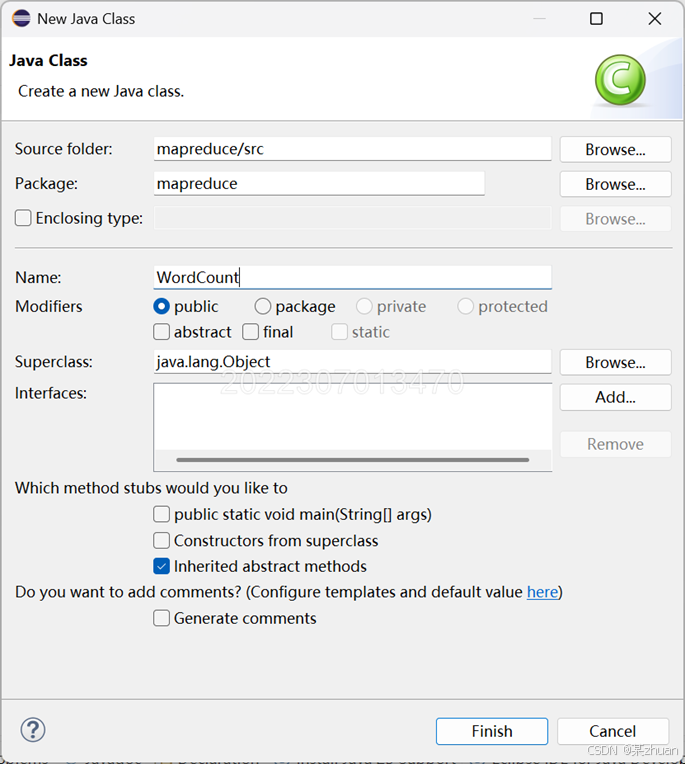
然后新建一个java类,将类名起名为WordCount。如果命名和这里不一样,后面代码需要对应修改
5.2 代码编写
WordCount.java中,填写以下代码。
java
package xxx; // 保持此行不要更改,和自己项目原版的一样
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
import java.io.IOException;
import java.util.StringTokenizer;
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
// map方法,划分一行文本,读一个单词写出一个<单词,1>
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);// 写出<单词,1>
}
}
}
// 定义reduce类,对相同的单词,把它们<K,VList>中的VList值全部相加
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();// 相当于<Hello,1><Hello,1>,将两个1相加
}
result.set(sum);
context.write(key, result);// 写出这个单词,和这个单词出现次数<单词,单词出现次数>
}
}
public static void main(String[] args) throws Exception { // 主方法,函数入口
// TODO Auto-generated method stub
Configuration conf = new Configuration(); // 实例化配置文件类
Job job = new Job(conf, "WordCount"); // 实例化Job类
job.setInputFormatClass(TextInputFormat.class); // 指定使用默认输入格式类
TextInputFormat.setInputPaths(job, args[0]); // 设置待处理文件的位置
job.setJarByClass(WordCount.class); // 设置主类名
job.setMapperClass(TokenizerMapper.class); // 指定使用上述自定义Map类
job.setCombinerClass(IntSumReducer.class); // 指定开启Combiner函数
job.setMapOutputKeyClass(Text.class); // 指定Map类输出的<K,V>,K类型
job.setMapOutputValueClass(IntWritable.class); // 指定Map类输出的<K,V>,V类型
job.setPartitionerClass(HashPartitioner.class); // 指定使用默认的HashPartitioner类
job.setReducerClass(IntSumReducer.class); // 指定使用上述自定义Reduce类
job.setNumReduceTasks(Integer.parseInt(args[2])); // 指定Reduce个数
job.setOutputKeyClass(Text.class); // 指定Reduce类输出的<K,V>,K类型
job.setOutputValueClass(Text.class); // 指定Reduce类输出的<K,V>,V类型
job.setOutputFormatClass(TextOutputFormat.class); // 指定使用默认输出格式类
TextOutputFormat.setOutputPath(job, new Path(args[1])); // 设置输出结果文件位置
System.exit(job.waitForCompletion(true) ? 0 : 1); // 提交任务并监控任务状态
}
}5.3 配置jar包
粘贴上述代码后,编辑器会出现很多红色波浪线报错,这是因为没有包含相应的库导致的。右键点击,选择Build Path->configure build path
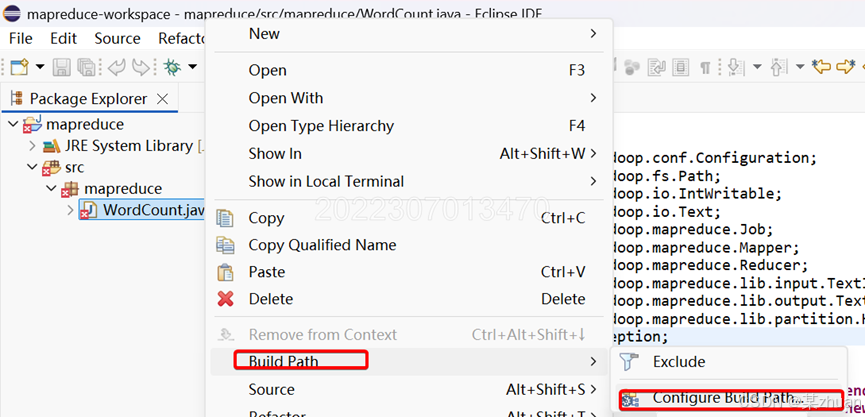
新建一个用户库,添加外部jar
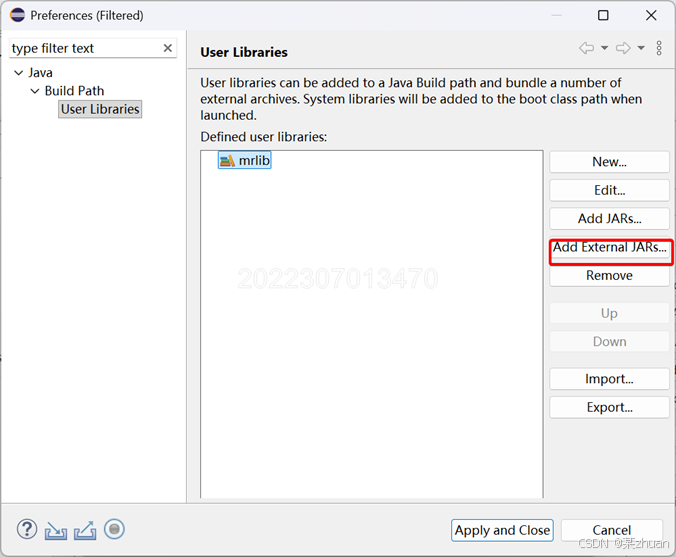
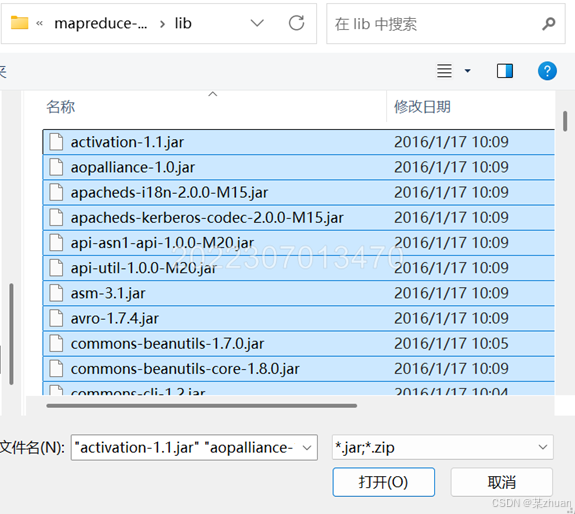
导入必要的库文件
配置库后,编辑器不再出现报错提示。
5.4 导出可执行jar
右键点击,选择export
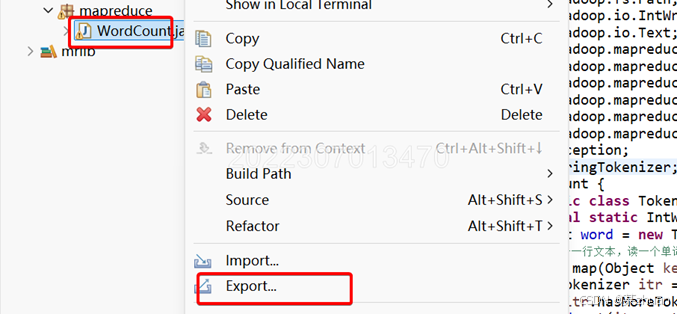
选择java下的jar file
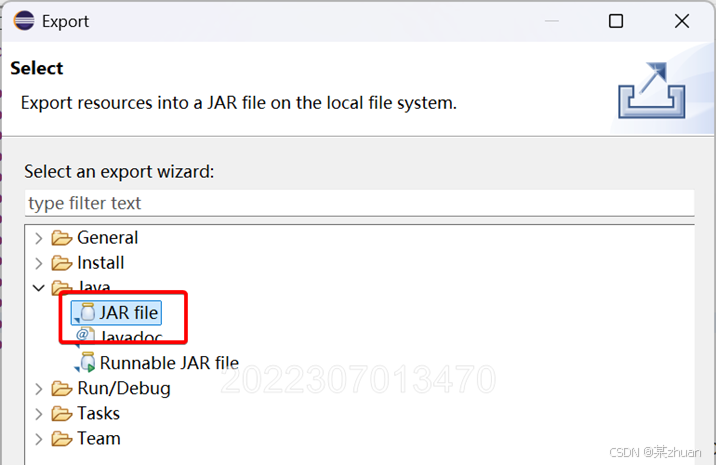
选择保存路径和输出文件名
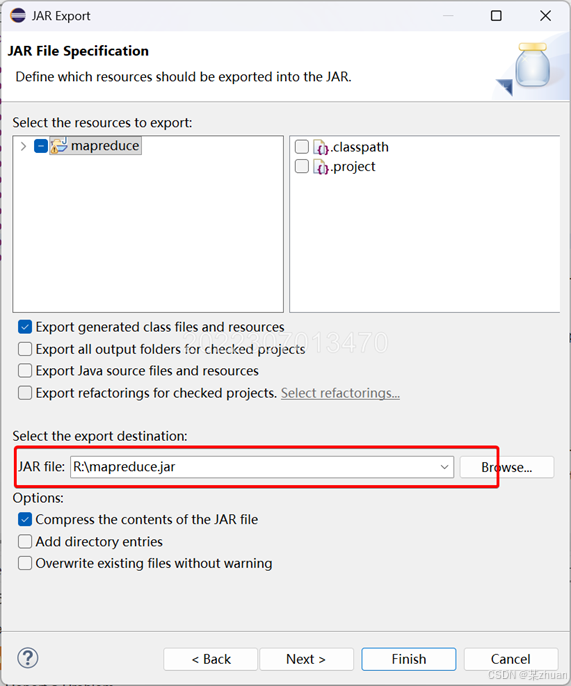
至此MapReduce代码编写完成。需要将导出的jar文件拷贝到虚拟机中。
6 新建测试用文件
在虚拟机中新建一个文件,写入一些测试的单词,或者粘贴一个英语文章进来。
执行以下命令将文件上传到hdfs中,并查看hdfs中是否已有相关文件
java
hadoop fs -put word.txt /
hadoop fs -ls /
7 运行代码
注意自己工程的结构和包名,对应修改启动命令
这里使用的启动命令为:
java
yarn jar mapreduce.jar mapreduce.WordCount /word.txt /wc_output 1在虚拟机中执行上述命令,即可运行程序。
若未出现报错,可跳至步骤8查看结果。
7.1 Java版本报错的解决方法
若出现下图报错,说明hadoop的Java版本和Eclipse中导出Jar时使用的不一样。
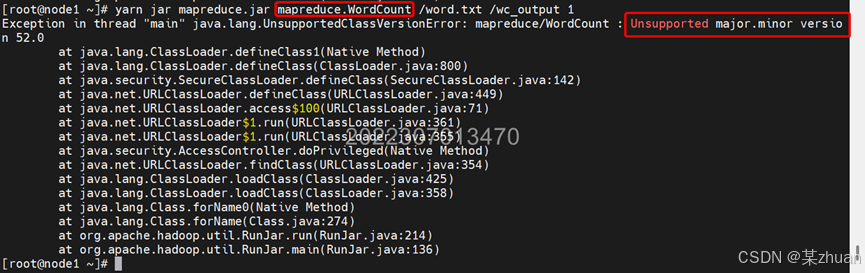
导出Jar使用的Java 1.8,而Hadoop配置的是Java 1.7。可以使用以下命令确认Hadoop的Java版本:
java
cat /usr/hadoop/etc/hadoop/hadoop-env.sh | grep java
所以需要修改hadoop使用的java版本
java
vi /usr/hadoop/etc/hadoop/hadoop-env.sh根据自己的安装路径修改为有效的java1.8版本
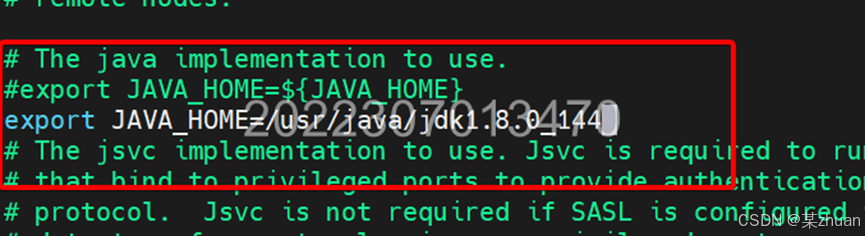
修改后,务必将修改后的文件分发到其他节点
java
scp /usr/hadoop/etc/hadoop/hadoop-env.sh root@node2:/usr/hadoop/etc/hadoop/
scp /usr/hadoop/etc/hadoop/hadoop-env.sh root@node3:/usr/hadoop/etc/hadoop/保险起见重启系统,然后参考步骤4重新启动集群。
8 运行结果
正常运行时,终端输出如下
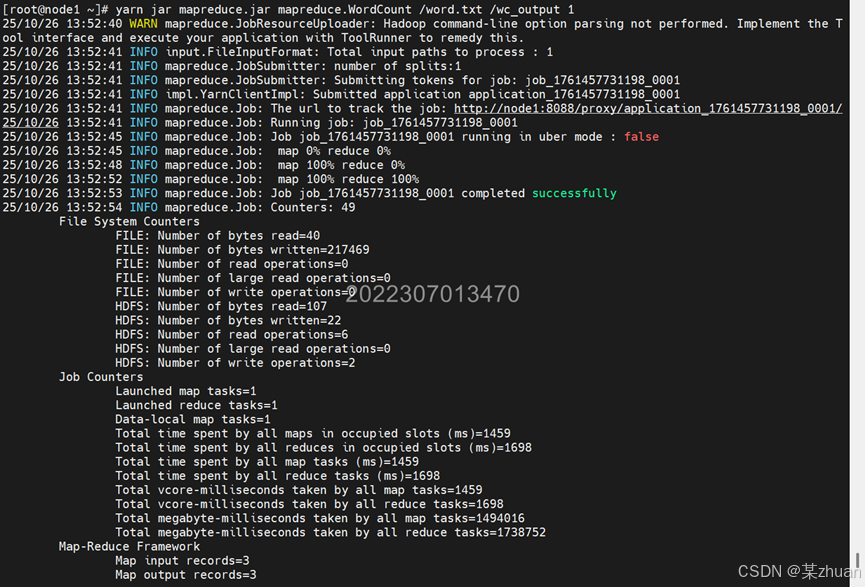
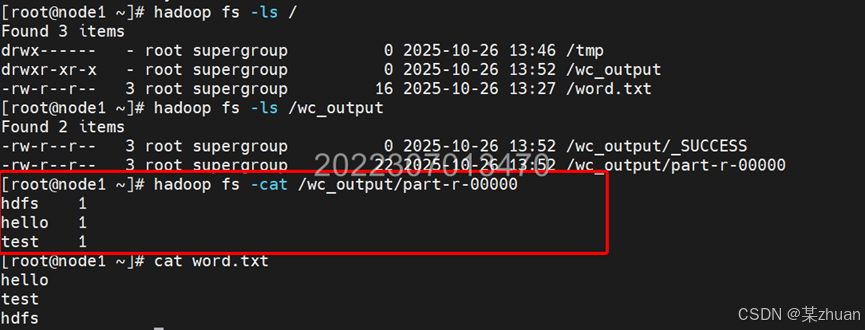
查看输出文件的内容,执行命令
java
hadoop fs -cat /wc_output/part-r-00000可以看到成功统计了文件中每个单词出现的次数
8.1 再次运行的一个注意事项
如果更换输入文件,再次运行启动命令时,会出现报错,输出路径已经存在
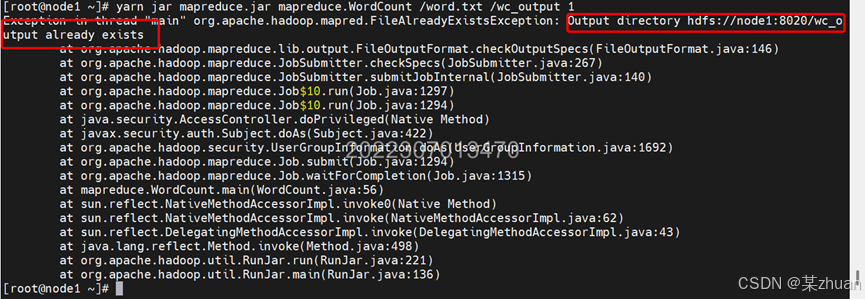
删除输出目录即可,执行命令:
java
hadoop fs -rm -r /wc_output之后正常运行启动命令。
文章记录的是笔者学习云计算课程中的一个实验过程,部分内容和步骤参考自教师提供的资料。若有错漏,还原交流指出。
实验至此结束,感谢阅读本文。
文中所有图片均添加水印,严禁任何方式盗用或转载本文及文中图片