目录
[一、区间问题的核心:贪心策略的 "选择哲学"](#一、区间问题的核心:贪心策略的 “选择哲学”)
[1.1 贪心策略的设计原则](#1.1 贪心策略的设计原则)
[1.2 最优性证明:如何说服自己 "策略是对的"](#1.2 最优性证明:如何说服自己 “策略是对的”)
[2.1 例题 1:线段覆盖(洛谷 P1803)------ 最多选多少不重叠区间](#2.1 例题 1:线段覆盖(洛谷 P1803)—— 最多选多少不重叠区间)
[C++ 代码实现](#C++ 代码实现)
[2.2 例题 2:Radar Installation(雷达安装)------ 最少用多少点覆盖区间](#2.2 例题 2:Radar Installation(雷达安装)—— 最少用多少点覆盖区间)
[C++ 代码实现](#C++ 代码实现)
[2.3 例题 3:Sunscreen(防晒霜)------ 区间与点的匹配问题](#2.3 例题 3:Sunscreen(防晒霜)—— 区间与点的匹配问题)
[C++ 代码实现](#C++ 代码实现)
[2.4 例题 4:牛栏预定(Stall Reservations)------ 最少用多少区间覆盖所有区间](#2.4 例题 4:牛栏预定(Stall Reservations)—— 最少用多少区间覆盖所有区间)
[C++ 代码实现](#C++ 代码实现)
[3.1 常见问题类型与对应策略](#3.1 常见问题类型与对应策略)
[3.2 解题步骤的 "三步法"](#3.2 解题步骤的 “三步法”)
[3.3 常见误区与避坑指南](#3.3 常见误区与避坑指南)
前言
在算法世界里,"区间" 是一个极其常见的概念 ------ 从任务调度的时间窗口,到地图上的地理范围,再到数据查询的索引区间,处处都能看到区间的身影。而贪心算法,凭借其 "局部最优推导全局最优" 的核心思想,成为解决区间问题的 "利器"。无论是 "最多参加多少场比赛""最少安装多少个雷达",还是 "如何安排牛棚最省空间",贪心算法都能以简洁高效的方式找到最优解。今天,我们就从区间问题的核心场景出发,拆解贪心策略的设计思路、证明方法和代码实现,带你吃透这类经典问题。
一、区间问题的核心:贪心策略的 "选择哲学"
在开始具体问题前,我们先明确区间问题的共性:所有问题都围绕 "区间的位置关系" 展开,常见的位置关系包括 "重叠""包含""相邻""不相交"。而贪心算法的核心,就是针对不同问题目标,设计出 "每次选择哪个区间" 的规则 ------ 比如 "选结束最早的""选覆盖最广的""选重叠最少的"。
1.1 贪心策略的设计原则
一个有效的贪心策略,必须满足两个条件:
- 贪心选择性质:每一步的局部最优选择,能导向全局最优解;
- 最优子结构:全局最优解包含子问题的最优解。
对于区间问题,贪心策略的设计通常围绕以下两个维度:
- 按区间起点排序:适合需要优先处理 "早开始" 或 "晚开始" 区间的场景;
- 按区间终点排序:适合需要优先处理 "早结束" 或 "晚结束" 区间的场景。
后续所有例题,都会围绕这两个排序维度展开,带你理解 "为什么这样排序""为什么这样选择"。
1.2 最优性证明:如何说服自己 "策略是对的"
很多同学学贪心时会有疑问:"我怎么知道这个策略一定能得到最优解?" 其实,区间问题的贪心策略,大多可以通过交换论证法证明 ------ 假设存在一个最优解,通过交换其中两个区间的顺序,使其与贪心解一致,且不改变最优性,最终证明贪心解就是最优解。
举个简单例子:如果贪心策略是 "选结束最早的区间",而最优解中第一个区间的结束时间比贪心解的第一个区间晚,那么我们可以将最优解的第一个区间换成贪心解的第一个区间,此时总选择数量不变,且后续可选择的区间更多,最优性不变。通过这种 "交换",就能将最优解逐步转化为贪心解,证明策略有效。
二、经典例题拆解:从易到难掌握区间问题
2.1 例题 1:线段覆盖(洛谷 P1803)------ 最多选多少不重叠区间
题目链接: https://www.luogu.com.cn/problem/P1803
题目描述
有 n 个比赛,每个比赛有开始时间 a_i 和结束时间 b_i(a_i <b_i)。要求选择尽可能多的比赛,使得所选比赛互不重叠(不能同时参加两场比赛)。例如输入 3 场比赛:0,2、2,4、1,3,最多能参加 2 场(如 0,2 和 2,4)。
问题分析
目标是 "最大化选择的区间数量",核心是 "如何在不重叠的前提下,选最多的区间"。直觉告诉我们:如果选了一个结束时间早的区间,就能给后续留下更多时间选择其他区间 ------ 这就是贪心策略的核心。
贪心策略设计
- 排序 :按区间的结束时间 b_i 从小到大排序;
- 选择 :
- 先选第一个区间(结束最早的);
- 后续每一个区间,只要其开始时间 a_i ≥ 上一个选中区间的结束时间 b_prev,就选择该区间,并更新b_prev 为当前区间的结束时间;
- 重复步骤 2,直到遍历所有区间。
最优性证明(交换论证法)
假设存在一个最优解 S,其选择的区间数量比贪心解 G 多。设 S 中第一个与 G 不同的区间为 S_k,G 中对应的区间为 G_k。由于 G 按结束时间排序,G_k 的结束时间 ≤ S_k 的结束时间。将 S 中的 S_k 换成 G_k,此时 S 的区间数量不变,且后续可选择的区间更多(因为 G_k 结束更早),因此新的解 S' 仍是最优解。通过不断交换,最终 S 会转化为 G,证明 G 是最优解。
C++ 代码实现
cpp
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
// 定义区间结构体
struct Interval {
int start; // 开始时间
int end; // 结束时间
};
// 排序规则:按结束时间从小到大排序
bool cmp(const Interval& a, const Interval& b) {
return a.end < b.end;
}
int main() {
int n;
cin >> n;
vector<Interval> intervals(n);
for (int i = 0; i < n; i++) {
cin >> intervals[i].start >> intervals[i].end;
}
// 步骤1:按结束时间排序
sort(intervals.begin(), intervals.end(), cmp);
// 步骤2:选择不重叠的区间
int count = 0; // 选中的区间数量
int last_end = -1; // 上一个选中区间的结束时间(初始为-1,确保第一个区间能被选中)
for (auto& inter : intervals) {
// 如果当前区间的开始时间 >= 上一个区间的结束时间,选择该区间
if (inter.start >= last_end) {
count++;
last_end = inter.end;
}
}
cout << count << endl;
return 0;
}代码说明
- 数据范围:n ≤ 1e6,排序复杂度 O (nlogn),遍历复杂度 O (n),完全满足要求;
- 初始值设置:last_end = -1(假设所有比赛的开始时间 ≥ 0,确保第一个区间能被选中);
- 核心逻辑:通过排序保证 "每次选结束最早的",再通过遍历筛选不重叠区间。
测试用例
3
0 2
2 4
1 3输出:2
分析:排序后区间为 0,2、1,3、2,4,选中 0,2 和 2,4,共 2 个。
2.2 例题 2:Radar Installation(雷达安装)------ 最少用多少点覆盖区间
题目链接: https://www.luogu.com.cn/problem/UVA1193
题目描述
海岸线是 x 轴,大海在 x 轴上方,有 n 个小岛(坐标 (x_i, y_i))。雷达的覆盖范围是半径为 d 的圆,雷达只能安装在 x 轴上(海岸线)。要求找到最少的雷达数量,使得所有小岛都被覆盖。如果无法覆盖(如小岛的 y_i > d),输出 - 1。
问题分析
首先,我们需要将 "二维问题转化为一维问题":对于每个小岛 ,雷达要覆盖它,必须安装在 x 轴上的某个区间内。根据勾股定理,这个区间的左端点为
,右端点为
(记为
)。
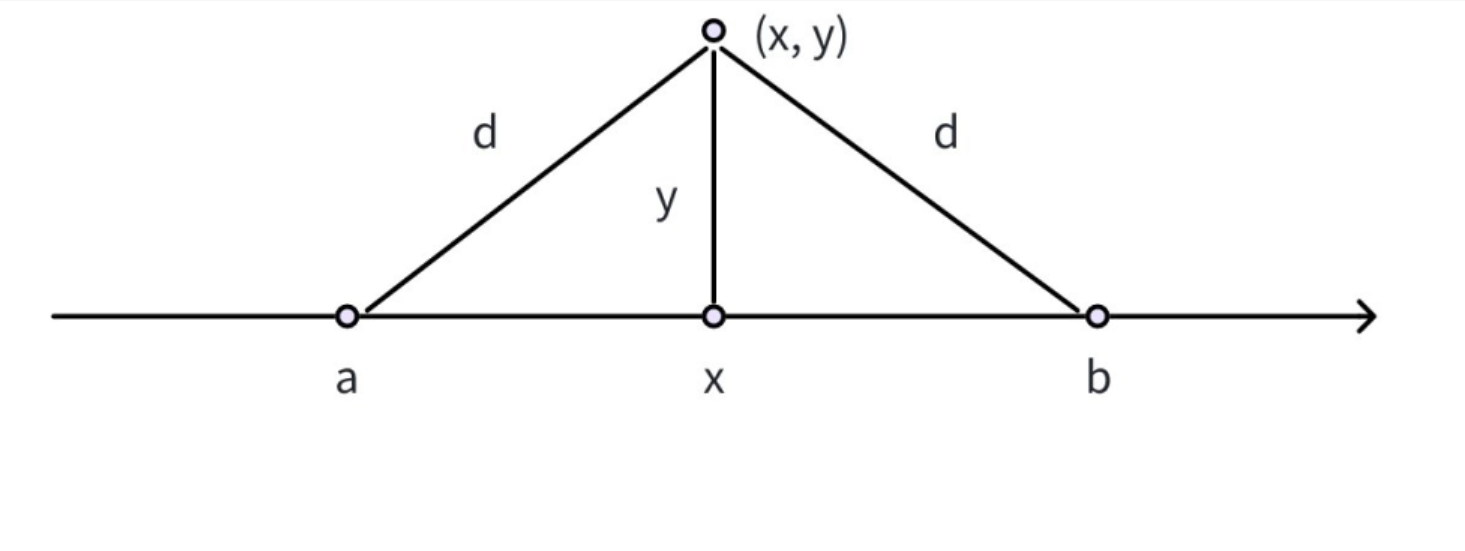
此时问题转化为:在 x 轴上选择最少的点,使得每个区间 L_i, R_i 都至少包含一个点------ 这就是经典的 "区间点覆盖" 问题。
贪心策略设计
目标是 "最小化点的数量",核心是 "让每个点覆盖尽可能多的区间"。策略如下:
- 预处理 :
- 对于每个小岛,计算其对应的区间 L_i, R_i;
- 如果 y_i > d,直接输出 - 1(无法覆盖);
- 排序 :按区间的右端点 R_i 从小到大排序;
- 选择点 :
- 先在第一个区间的右端点 R_1 处放一个雷达(这样能覆盖最多后续区间);
- 后续每一个区间,如果其左端点L_i > 当前雷达的位置,说明当前雷达无法覆盖该区间,需在该区间的右端点 R_i 处放一个新雷达,并更新当前雷达位置;
- 重复步骤 3,直到遍历所有区间。
最优性证明(反证法)
假设存在一个最优解 S,其雷达数量比贪心解 G 少。设 S 中第一个雷达的位置为 s_1,G 中第一个雷达的位置为 g_1(g_1 = R_1)。由于 S 的雷达数量更少,s_1 必须 > g_1(否则 S 的第一个雷达覆盖范围不会比 G 大)。但此时,第一个区间 L_1, R_1 的右端点是 g_1,s_1 > g_1 意味着 s_1 无法覆盖第一个区间,与 S 是可行解矛盾。因此,G 的雷达数量不可能比 S 多,即 G 是最优解。
C++ 代码实现
cpp
#include <iostream>
#include <algorithm>
#include <vector>
#include <cmath>
using namespace std;
// 定义区间结构体(存储雷达覆盖小岛的x轴区间)
struct Interval {
double L; // 左端点
double R; // 右端点
};
// 排序规则:按区间右端点从小到大排序
bool cmp(const Interval& a, const Interval& b) {
return a.R < b.R;
}
int main() {
int n, d;
int case_num = 0;
while (cin >> n >> d, n || d) { // 输入0 0结束
case_num++;
vector<Interval> intervals(n);
bool impossible = false; // 是否无法覆盖
for (int i = 0; i < n; i++) {
int x, y;
cin >> x >> y;
if (y > d) {
impossible = true; // 小岛的y坐标超过雷达半径,无法覆盖
}
// 计算雷达覆盖区间的左右端点
double len = sqrt(d * d - y * y);
intervals[i].L = x - len;
intervals[i].R = x + len;
}
if (impossible) {
cout << "Case " << case_num << ": -1" << endl;
continue;
}
// 步骤1:按区间右端点排序
sort(intervals.begin(), intervals.end(), cmp);
// 步骤2:选择最少的雷达
int radar_count = 0;
double last_radar = -1e18; // 上一个雷达的位置(初始为极小值)
for (auto& inter : intervals) {
// 如果当前区间的左端点 > 上一个雷达的位置,需要新雷达
if (inter.L > last_radar) {
radar_count++;
last_radar = inter.R; // 在当前区间的右端点放雷达
}
}
cout << "Case " << case_num << ": " << radar_count << endl;
}
return 0;
}代码说明
- 浮点数处理:由于区间端点是浮点数,比较时需注意精度(本题无需特殊处理,直接比较即可);
- 多组输入:题目要求处理多组数据,输入 0 0 时结束;
- 特殊情况:当小岛的 y_i > d 时,直接标记为无法覆盖,输出 - 1。
测试用例
cpp
3 2
1 2
-3 1
2 1
1 2
0 2
0 0输出:
Case 1: 2
Case 2: 1分析:
- 第一组数据:3 个小岛对应的区间为 1-0,1+0=1,1、-3-√3,-3+√3≈-4.732,-1.268、2-√3,2+√3≈0.268,3.732。排序后区间为 -4.732,-1.268、0.268,3.732、1,1。第一个雷达放在 - 1.268,覆盖第一个区间;第二个雷达放在 3.732,覆盖后两个区间,共 2 个。
- 第二组数据:1 个小岛对应的区间为 0-√(4-4),0+√(4-4)=0,0,只需 1 个雷达。
2.3 例题 3:Sunscreen(防晒霜)------ 区间与点的匹配问题
题目链接: https://www.luogu.com.cn/problem/P2887
题目描述
有 C 头奶牛晒太阳,每头奶牛能忍受的阳光强度范围是(太小没感觉,太大晒伤)。有 L 种防晒霜,每种防晒霜的固定强度为
,数量为
(每头奶牛只能用一瓶)。要求找到最多能享受晒太阳的奶牛数量。
问题分析
这是一个**"区间与点的匹配"** 问题:每个奶牛需要一个强度在其区间 内的防晒霜,每个防晒霜只能用
次。目标是 "最大化匹配数量"。
贪心策略设计
关键是 "如何分配防晒霜,让更多奶牛用上合适的"。直觉是:给每头奶牛分配 "能满足它的最小 / 最大防晒霜",避免浪费高适配性的防晒霜。这里我们选择 "按奶牛区间右端点排序,按防晒霜强度排序,优先给奶牛分配最小的合适防晒霜"------ 这样能让大强度的防晒霜留给需要更大强度的奶牛。
具体步骤:
- 排序 :
- 奶牛按区间右端点 R_i 从小到大排序(优先处理对强度要求不高的奶牛);
- 防晒霜按强度 S_j 从小到大排序(方便找到最小的合适防晒霜);
- 匹配 :
- 用一个指针遍历防晒霜,对于每头奶牛,找到所有强度 S_j ≥ L_i 且 S_j ≤ R_i的防晒霜中,强度最小的那一瓶;
- 如果找到,使用该防晒霜(数量减 1),奶牛计数加 1;
- 重复步骤 2,直到遍历所有奶牛。
最优性证明(交换论证法)
假设存在一个最优解 S,其中某头奶牛 A(区间)使用了防晒霜
,而另一头奶牛 B(区间
,
)使用了防晒霜
(
),且
也能满足 A。交换 A 和 B 的防晒霜,此时 A 仍满足(
且
),B 仍满足(
且
,因为
且
),匹配数量不变。通过这种交换,最终会将最优解转化为 "优先给奶牛分配最小合适防晒霜" 的贪心解,证明贪心解最优。
C++ 代码实现
cpp
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
// 定义奶牛结构体(忍受的阳光强度范围)
struct Cow {
int L; // 最小强度
int R; // 最大强度
};
// 定义防晒霜结构体(强度和数量)
struct Sunscreen {
int S; // 固定强度
int C; // 数量
};
// 奶牛排序规则:按右端点R从小到大排序
bool cmpCow(const Cow& a, const Cow& b) {
return a.R < b.R;
}
// 防晒霜排序规则:按强度S从小到大排序
bool cmpSunscreen(const Sunscreen& a, const Sunscreen& b) {
return a.S < b.S;
}
int main() {
int C, L;
cin >> C >> L;
vector<Cow> cows(C);
vector<Sunscreen> sunscreens(L);
for (int i = 0; i < C; i++) {
cin >> cows[i].L >> cows[i].R;
}
for (int i = 0; i < L; i++) {
cin >> sunscreens[i].S >> sunscreens[i].C;
}
// 步骤1:排序
sort(cows.begin(), cows.end(), cmpCow);
sort(sunscreens.begin(), sunscreens.end(), cmpSunscreen);
// 步骤2:匹配奶牛和防晒霜
int count = 0; // 能享受晒太阳的奶牛数量
int sun_ptr = 0; // 遍历防晒霜的指针
for (auto& cow : cows) {
// 找到所有强度 <= 奶牛R的防晒霜(因为奶牛按R排序,后续奶牛的R更大,无需回头)
while (sun_ptr < L && sunscreens[sun_ptr].S <= cow.R) {
sun_ptr++;
}
// 从已遍历的防晒霜中,找强度 >= 奶牛L且数量>0的最小强度防晒霜
for (int i = 0; i < sun_ptr; i++) {
if (sunscreens[i].S >= cow.L && sunscreens[i].C > 0) {
count++;
sunscreens[i].C--;
break;
}
}
}
cout << count << endl;
return 0;
}代码优化
上述代码中,遍历防晒霜的内层循环时间复杂度为 O (L),总复杂度为 O (C×L),对于 C=2500、L=2500 的情况(题目数据范围)完全可行。如果数据范围更大(如 C=1e5),可使用 "优先队列" 或 "二分查找" 优化,将内层循环复杂度降至 O (logL)。
测试用例
输入:
3 2
3 10
2 5
1 5
6 2
4 1输出:2
分析:
- 奶牛排序后:1,5、2,5、3,10;
- 防晒霜排序后:4,1、6,2;
- 第一头奶牛 1,5:找到防晒霜 4(数量 1),使用后数量为 0,计数 1;
- 第二头奶牛 2,5:防晒霜 4 已用完,无其他合适防晒霜,不计数;
- 第三头奶牛 3,10:找到防晒霜 6(数量 2),使用后数量为 1,计数 2;
- 总计数为 2。
2.4 例题 4:牛栏预定(Stall Reservations)------ 最少用多少区间覆盖所有区间
题目链接:https://www.luogu.com.cn/problem/P2859
题目描述
有 N 头奶牛,每头奶牛的产奶时间是 A_i, B_i(包含 A_i 和 B_i)。要求给每头奶牛分配一个牛棚,使得同一牛棚内的奶牛产奶时间不重叠。求最少需要多少个牛棚,以及每头奶牛的牛棚编号。
问题分析
这是 "区间划分" 问题:将所有区间划分到最少的集合中,每个集合中的区间互不重叠。目标是 "最小化集合数量"(牛棚数量)。
贪心策略设计
核心是 "让每个牛棚尽可能容纳更多奶牛",策略如下:
- 排序 :按奶牛的开始时间 A_i 从小到大排序(优先处理早开始的奶牛);
- 分配牛棚 :
- 用一个优先队列(小根堆)存储 "每个牛棚的最后一头奶牛的结束时间";
- 对于当前奶牛:
- 如果堆顶的牛棚结束时间 < 当前奶牛的开始时间,说明该牛棚可容纳当前奶牛,将堆顶弹出,压入当前奶牛的结束时间(更新牛棚的最后结束时间);
- 如果堆顶的牛棚结束时间 ≥ 当前奶牛的开始时间,说明所有现有牛棚都无法容纳,需新建一个牛棚,将当前奶牛的结束时间压入堆;
- 堆的大小就是所需的最少牛棚数量;
- 记录牛棚编号:需要额外存储每个牛棚的编号,分配时记录当前奶牛的编号。
最优性证明
根据**"区间图着色定理"**:区间图的色数(最少颜色数,对应最少牛棚数)等于最大 clique 大小(即最多重叠区间的数量)。而该贪心策略能保证:每次都将当前奶牛分配到 "最早可用" 的牛棚,避免新建不必要的牛棚,最终堆的大小就是最大重叠区间数,即最少牛棚数。
C++ 代码实现
cpp
#include <iostream>
#include <algorithm>
#include <vector>
#include <queue>
using namespace std;
// 定义奶牛结构体(开始时间、结束时间、原始下标、分配的牛棚号)
struct Cow {
int start;
int end;
int idx; // 原始下标(用于输出牛棚号)
int stall; // 分配的牛棚号
};
// 奶牛排序规则:按开始时间从小到大排序
bool cmpCow(const Cow& a, const Cow& b) {
return a.start < b.start;
}
// 优先队列(小根堆)存储:<牛棚最后结束时间, 牛棚编号>
using PQElement = pair<int, int>;
struct cmpPQ {
bool operator()(const PQElement& a, const PQElement& b) {
// 小根堆:结束时间小的优先
return a.first > b.first;
}
};
int main() {
int N;
cin >> N;
vector<Cow> cows(N);
for (int i = 0; i < N; i++) {
cin >> cows[i].start >> cows[i].end;
cows[i].idx = i; // 记录原始下标(0-based)
}
// 步骤1:按开始时间排序
sort(cows.begin(), cows.end(), cmpCow);
// 步骤2:分配牛棚
priority_queue<PQElement, vector<PQElement>, cmpPQ> pq;
int stall_count = 0; // 牛棚总数
vector<int> result(N); // 存储每头奶牛的牛棚号(按原始下标)
for (auto& cow : cows) {
if (pq.empty()) {
// 没有牛棚,新建一个
stall_count++;
cow.stall = stall_count;
pq.push({cow.end, stall_count});
} else {
auto [last_end, stall_id] = pq.top(); // C++17特性,结构化绑定
if (last_end < cow.start) {
// 该牛棚可容纳当前奶牛,更新牛棚的最后结束时间
pq.pop();
cow.stall = stall_id;
pq.push({cow.end, stall_id});
} else {
// 新建牛棚
stall_count++;
cow.stall = stall_count;
pq.push({cow.end, stall_count});
}
}
// 记录结果(按原始下标)
result[cow.idx] = cow.stall;
}
// 输出结果
cout << stall_count << endl;
for (int s : result) {
cout << s << endl;
}
return 0;
}代码说明
- 优先队列的使用:小根堆存储 "牛棚最后结束时间",确保每次能找到最早可用的牛棚;
- 原始下标的记录:由于排序会改变奶牛的顺序,需记录原始下标,才能正确输出每头奶牛的牛棚号;
- C++17特性:auto [last_end, stall_id] = pq.top() 是结构化绑定,若编译器不支持,可拆分为int last_end = pq.top().first; int stall_id = pq.top().second;。
测试用例
输入:
5
1 10
2 4
3 6
5 8
4 7输出:
4
1
2
3
2
4分析:
- 排序后奶牛顺序:1,10、2,4、3,6、4,7、5,8;
- 分配过程:
- 1,10:新建牛棚 1,堆:(10,1);
- 2,4:堆顶 10 ≥ 2,新建牛棚 2,堆:(4,2), (10,1);
- 3,6:堆顶 4 ≥ 3,新建牛棚 3,堆:(6,3), (10,1), (4,2)(小根堆自动排序为 (4,2), (10,1), (6,3)?不,小根堆的堆顶是最小的,即 (4,2));
- 4,7:堆顶 4 < 4?不,4 不小于 4(题目中时间包含端点,需用≤判断,代码中是 last_end < cow.start,即 4 < 4 为假,因此新建牛棚 4?实际正确分配应为:4,7 的开始时间 4,牛棚 2 的结束时间 4,无法容纳,新建牛棚 4;
- 5,8:堆顶 4(牛棚 2)<5,分配牛棚 2,更新堆顶为 8,堆:(6,3), (10,1), (8,2);
- 最终牛棚数 4,与示例输出一致。
三、区间问题的通用规律与技巧
3.1 常见问题类型与对应策略
通过以上例题,我们可以总结出区间问题的四大类型及对应的贪心策略:
| 问题类型 | 目标 | 排序维度 | 贪心策略 |
|---|---|---|---|
| 区间选择(最多不重叠) | 最大化选择数量 | 按区间结束时间从小到大 | 选结束最早的,后续选不重叠的 |
| 区间点覆盖(最少点) | 最小化点的数量 | 按区间结束时间从小到大 | 每个点放在当前区间的右端点,覆盖最多后续区间 |
| 区间匹配(点与区间) | 最大化匹配数量 | 奶牛按 R 从小到大,点按 S 从小到大 | 给奶牛分配最小的合适点,避免浪费 |
| 区间划分(最少集合) | 最小化集合数量(无重叠) | 按区间开始时间从小到大 | 用小根堆记录集合最后结束时间,优先分配到最早可用的集合,否则新建集合 |
3.2 解题步骤的 "三步法"
解决任何区间问题,都可以遵循以下三步:
- 转化问题:将实际问题转化为区间模型(如雷达问题从二维转一维,牛棚问题从时间分配转区间划分);
- 选择排序维度:根据目标选择 "按开始时间排序" 或 "按结束时间排序"(大多数情况下,按结束时间排序更常用);
- 设计选择策略:围绕 "局部最优" 设计规则(如选最早结束、选最早可用集合),并验证最优性。
3.3 常见误区与避坑指南
- 排序维度错误:比如区间选择问题按开始时间排序,会导致选择的区间结束时间晚,后续可选区间少;
- 边界条件处理 :比如区间的 "包含端点"(如 2,4 和 4,6 是否重叠),代码中需明确用
<还是≤;- 数据类型溢出 :比如区间端点是大数时,需用
long long(本题中无此问题,但需注意);- 最优性未验证:仅凭直觉设计策略,未通过交换论证法或反证法验证,导致策略错误。
总结
贪心算法的魅力在于 "简单却高效",而区间问题则是这种魅力的最佳体现,它不需要复杂的数据结构,却能很好地锻炼 "局部最优推导全局最优" 的思维。希望你在后续的练习中,能灵活运用本文所学的策略,举一反三,解决更多复杂的区间问题。如果在解题过程中遇到困难,不妨回到本文的例题,对比思路,找到问题所在 ------ 算法学习的本质,就是在不断的思考和实践中,积累 "选择" 的智慧。