Spring AI Vector Store 分析
请关注微信公众号:阿呆-bot
1. 工程结构概览
spring-ai-vector-store 是 Spring AI 的向量存储抽象层,它提供了统一的接口来操作各种向量数据库。Spring AI 支持 20+ 种向量数据库实现,包括 Neo4j、Elasticsearch、Milvus、PGVector、Pinecone 等。
spring-ai-vector-store/ # 核心抽象层
├── VectorStore.java # 向量存储接口
├── SearchRequest.java # 搜索请求
├── filter/ # 过滤表达式
│ └── Filter.java
└── observation/ # 观察性支持
vector-stores/ # 具体实现
├── spring-ai-neo4j-store/ # Neo4j 实现
├── spring-ai-elasticsearch-store/ # Elasticsearch 实现
├── spring-ai-milvus-store/ # Milvus 实现
├── spring-ai-pgvector-store/ # PostgreSQL/PGVector 实现
└── ... (20+ 种实现)2. 技术体系与模块关系
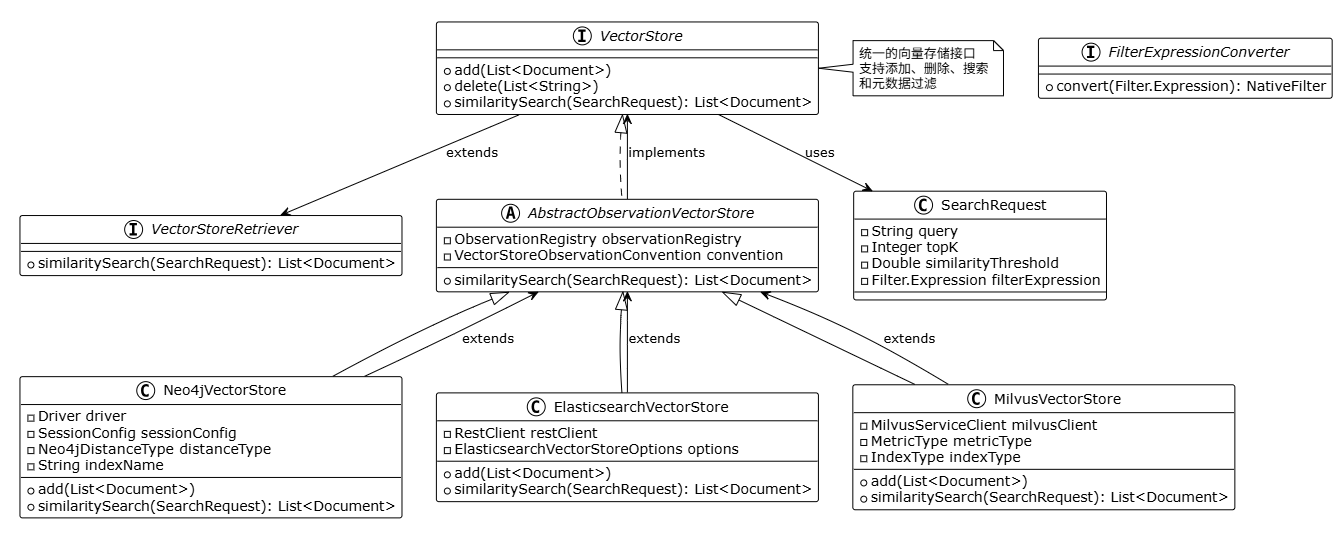
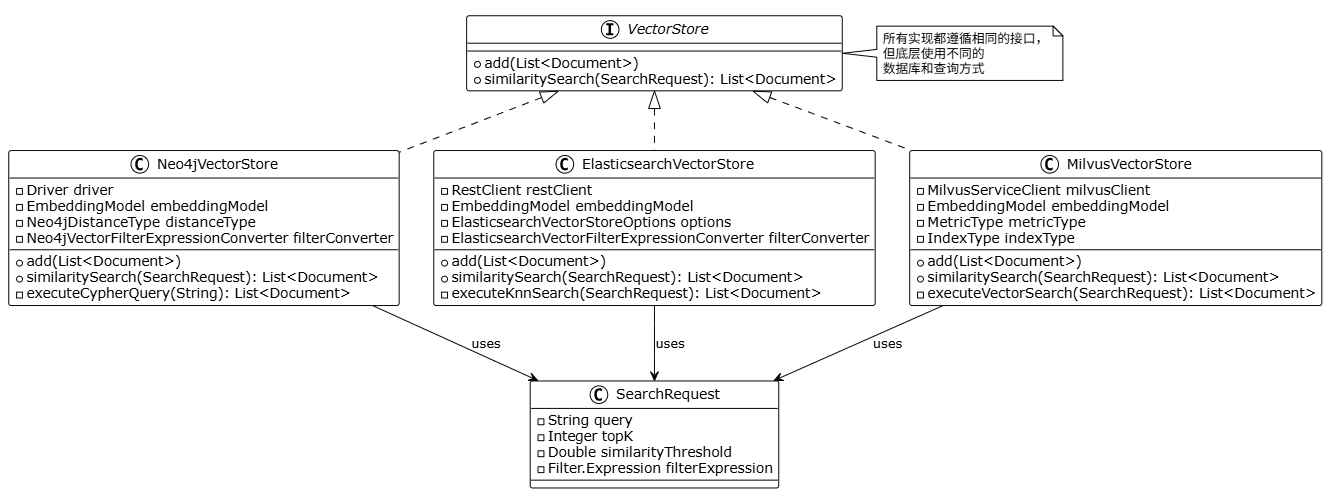
向量存储采用统一的抽象接口,所有实现都遵循相同的模式:
3. 关键场景示例代码
3.1 基础使用
所有向量存储都使用相同的 API:
java
@Autowired
private EmbeddingModel embeddingModel;
// Neo4j
Neo4jVectorStore vectorStore = Neo4jVectorStore.builder(driver, embeddingModel)
.initializeSchema(true)
.build();
// Elasticsearch
ElasticsearchVectorStore vectorStore = ElasticsearchVectorStore.builder(restClient, embeddingModel)
.initializeSchema(true)
.build();
// Milvus
MilvusVectorStore vectorStore = MilvusVectorStore.builder(milvusClient, embeddingModel)
.initializeSchema(true)
.build();
// 添加文档
vectorStore.add(List.of(
new Document("Spring AI 是一个 AI 应用开发框架"),
new Document("支持多种 AI 模型和向量数据库")
));
// 相似度搜索
List<Document> results = vectorStore.similaritySearch(
SearchRequest.query("AI 框架")
.withTopK(5)
.withSimilarityThreshold(0.7)
);3.2 元数据过滤
所有实现都支持元数据过滤:
java
// 使用过滤表达式
List<Document> results = vectorStore.similaritySearch(
SearchRequest.query("查询内容")
.withTopK(10)
.withFilterExpression("category == '技术' AND year > 2023")
);3.3 批量处理
支持批量添加和批处理策略:
java
// 使用批处理策略
vectorStore = MilvusVectorStore.builder(milvusClient, embeddingModel)
.batchingStrategy(new TokenCountBatchingStrategy(1000))
.build();
// 批量添加
List<Document> documents = loadDocuments(); // 大量文档
vectorStore.add(documents); // 自动批处理4. 核心实现图
4.1 统一抽象设计
5. 入口类与关键类关系
6. 关键实现逻辑分析
6.1 统一接口设计
VectorStore 接口提供了统一的向量存储抽象:
java
public interface VectorStore extends DocumentWriter, VectorStoreRetriever {
void add(List<Document> documents);
void delete(List<String> idList);
void delete(Filter.Expression filterExpression);
List<Document> similaritySearch(SearchRequest request);
}这种设计让所有向量数据库都使用相同的 API,用户可以轻松切换不同的实现。
6.2 Neo4j 实现
Neo4j 使用 Cypher 查询和 HNSW 索引:
java
public class Neo4jVectorStore extends AbstractObservationVectorStore {
@Override
public void add(List<Document> documents) {
// 1. 生成嵌入向量
List<float[]> embeddings = embeddingModel.embed(documents);
// 2. 构建 Cypher 查询
String cypher = """
UNWIND $rows AS row
MERGE (n:Document {id: row.id})
SET n.text = row.properties.text,
n.embedding = row.embedding,
n.metadata = row.properties.metadata
""";
// 3. 执行批量插入
try (var session = driver.session(sessionConfig)) {
session.executeWrite(tx -> {
tx.run(cypher, Map.of("rows", documentRows));
});
}
}
@Override
public List<Document> similaritySearch(SearchRequest request) {
// 1. 生成查询向量
float[] queryEmbedding = embeddingModel.embed(request.getQuery());
// 2. 转换过滤表达式
String whereClause = filterConverter.convert(request.getFilterExpression());
// 3. 构建向量搜索查询
String cypher = """
CALL db.index.vector.queryNodes(
'%s',
%d,
$queryVector
)
YIELD node, score
WHERE %s
RETURN node, score
ORDER BY score DESC
LIMIT %d
""".formatted(indexName, topK, whereClause, request.getTopK());
// 4. 执行查询并转换结果
return executeCypherQuery(cypher, queryEmbedding);
}
}特点:
- 使用 Neo4j 的向量索引(HNSW)
- 支持 Cypher 查询的元数据过滤
- 支持 Cosine 和 Euclidean 距离
6.3 Elasticsearch 实现
Elasticsearch 使用 k-NN 搜索:
java
public class ElasticsearchVectorStore extends AbstractObservationVectorStore {
@Override
public void add(List<Document> documents) {
// 1. 生成嵌入向量
List<float[]> embeddings = embeddingModel.embed(documents);
// 2. 构建批量索引请求
BulkRequest bulkRequest = new BulkRequest();
for (int i = 0; i < documents.size(); i++) {
IndexRequest request = new IndexRequest(indexName)
.id(documents.get(i).getId())
.source(Map.of(
"content", documents.get(i).getText(),
"embedding", embeddings.get(i),
"metadata", documents.get(i).getMetadata()
));
bulkRequest.add(request);
}
// 3. 执行批量索引
restClient.bulk(bulkRequest);
}
@Override
public List<Document> similaritySearch(SearchRequest request) {
// 1. 生成查询向量
float[] queryVector = embeddingModel.embed(request.getQuery());
// 2. 构建 k-NN 搜索请求
KnnVectorQueryBuilder knnQuery = new KnnVectorQueryBuilder("embedding", queryVector, request.getTopK());
// 3. 添加元数据过滤
if (request.getFilterExpression() != null) {
QueryBuilder filterQuery = filterConverter.convert(request.getFilterExpression());
knnQuery.addFilterQuery(filterQuery);
}
// 4. 执行搜索
SearchRequest searchRequest = new SearchRequest(indexName)
.source(new SearchSourceBuilder().query(knnQuery));
SearchResponse response = restClient.search(searchRequest);
return convertToDocuments(response);
}
}特点:
- 使用 Elasticsearch 的
dense_vector字段类型 - 支持 k-NN 搜索和元数据过滤
- 支持 Cosine、L2、Dot Product 相似度
6.4 Milvus 实现
Milvus 是专门的向量数据库:
java
public class MilvusVectorStore extends AbstractObservationVectorStore {
@Override
public void add(List<Document> documents) {
// 1. 生成嵌入向量
List<List<Float>> embeddings = embeddingModel.embed(documents)
.stream()
.map(embedding -> Arrays.stream(embedding).boxed().collect(toList()))
.collect(toList());
// 2. 构建插入数据
List<InsertParam.Field> fields = List.of(
new InsertParam.Field("id", documents.stream().map(Document::getId).collect(toList())),
new InsertParam.Field("content", documents.stream().map(Document::getText).collect(toList())),
new InsertParam.Field("embedding", embeddings),
new InsertParam.Field("metadata", documents.stream().map(Document::getMetadata).collect(toList()))
);
// 3. 执行插入
InsertParam insertParam = InsertParam.newBuilder()
.withCollectionName(collectionName)
.withFields(fields)
.build();
milvusClient.insert(insertParam);
}
@Override
public List<Document> similaritySearch(SearchRequest request) {
// 1. 生成查询向量
float[] queryVector = embeddingModel.embed(request.getQuery());
// 2. 构建搜索参数
SearchParam searchParam = SearchParam.newBuilder()
.withCollectionName(collectionName)
.withVectorFieldName("embedding")
.withVectors(List.of(Arrays.stream(queryVector).boxed().collect(toList())))
.withTopK(request.getTopK())
.withMetricType(metricType)
.withParams(Map.of("nprobe", 10))
.build();
// 3. 添加过滤表达式
if (request.getFilterExpression() != null) {
String filterExpr = filterConverter.convert(request.getFilterExpression());
searchParam.withExpr(filterExpr);
}
// 4. 执行搜索
R<SearchResults> response = milvusClient.search(searchParam);
return convertToDocuments(response.getData());
}
}特点:
- 专门的向量数据库,性能优异
- 支持多种索引类型(IVF_FLAT、HNSW 等)
- 支持多种相似度度量(Cosine、L2、IP)
7. 实现对比分析
| 特性 | Neo4j | Elasticsearch | Milvus |
|---|---|---|---|
| 数据库类型 | 图数据库 | 搜索引擎 | 向量数据库 |
| 索引算法 | HNSW | k-NN | HNSW/IVF_FLAT |
| 相似度度量 | Cosine, Euclidean | Cosine, L2, Dot Product | Cosine, L2, IP |
| 元数据过滤 | Cypher WHERE | Query DSL | 表达式字符串 |
| 适用场景 | 图+向量混合查询 | 全文+向量搜索 | 纯向量搜索 |
| 性能 | 中等 | 高 | 极高 |
| 扩展性 | 好 | 很好 | 优秀 |
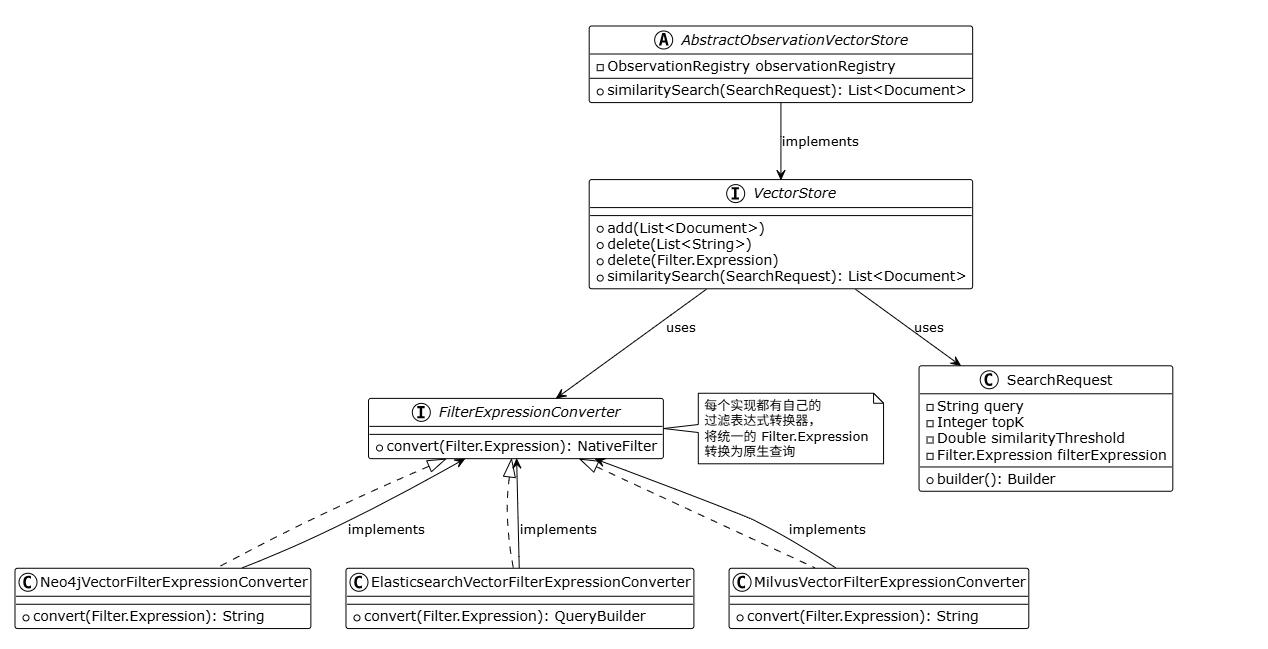
8. 过滤表达式转换
每个实现都有自己的 FilterExpressionConverter,将统一的 Filter.Expression 转换为原生查询:
java
// Neo4j: 转换为 Cypher WHERE 子句
"n.metadata.category = '技术' AND n.metadata.year > 2023"
// Elasticsearch: 转换为 Query DSL
{
"bool": {
"must": [
{"term": {"metadata.category": "技术"}},
{"range": {"metadata.year": {"gt": 2023}}}
]
}
}
// Milvus: 转换为表达式字符串
"metadata['category'] == '技术' && metadata['year'] > 2023"9. 外部依赖
不同实现的依赖:
9.1 Neo4j
- Neo4j Java Driver:Neo4j 官方驱动
- Neo4j 5.15+:支持向量索引
9.2 Elasticsearch
- Elasticsearch Java Client:官方 Java 客户端
- Elasticsearch 8.0+:支持 k-NN 搜索
9.3 Milvus
- Milvus Java SDK:Milvus 官方 SDK
- Milvus 2.0+:向量数据库
10. 工程总结
Spring AI 向量存储的设计有几个值得学习的地方:
统一抽象 。所有向量数据库都实现相同的 VectorStore 接口,这让用户可以轻松切换不同的实现,而不需要改业务代码。今天用 Neo4j,明天想换 Milvus?改个配置就行。
灵活的过滤机制 。通过 Filter.Expression 和 FilterExpressionConverter,实现了统一的过滤表达式,但每个实现可以转换为自己的原生查询。写一次过滤表达式,所有数据库都能用。
观察性内置 。所有实现都继承 AbstractObservationVectorStore,提供了统一的指标和追踪能力。可以监控搜索次数、延迟、错误率等,对生产环境很有用。
批处理支持 。通过 BatchingStrategy,可以灵活配置批量操作的策略,提高性能。想一次插入 1000 条数据?配置个批处理策略就行。
自动模式初始化 。大多数实现都支持 initializeSchema(true),自动创建必要的索引和表结构。不用手动建表,启动时自动搞定。
总的来说,Spring AI 向量存储抽象层设计既统一又灵活。统一的接口让代码简洁,灵活的实现让每个数据库都能发挥自己的优势。这种设计让 Spring AI 能够支持 20+ 种不同的向量数据库,同时保持代码的可维护性。