https://mp.weixin.qq.com/s/4n0Cl4xEMVoFCulTORPJWg
是什么
GraphQL是由Facebook开发的API查询语言,通过客户端定义数据结构提升数据传输效率,广泛应用于复杂数据交互场景。于2012年开发,2015年开源。
它是数据库无关的,而且可以在使用API的任何环境中有效使用,我们可以理解为GraphQL是基于API之上的一层封装,目的是为了更好,更灵活的适用于业务的需求变化。
为什么
传统开发(比如restful)的不足
REST作为一种现代网络应用非常流行的软件架构风格,自从Roy Fielding博士在2000年他的博士论文中提出来到现在已经有了20年的历史。它的简单易用性,可扩展性,伸缩性受到广大Web开发者的喜爱。
REST 的 API 配合JSON格式的数据交换,使得前后端分离、数据交互变得非常容易,而且也已经成为了目前Web领域最受欢迎的软件架构设计模式。
但随着REST API的流行和发展,它的缺点也暴露了出来:
- 滥用REST接口,导致大量相似度很高(具有重复性)的API越来越冗余。
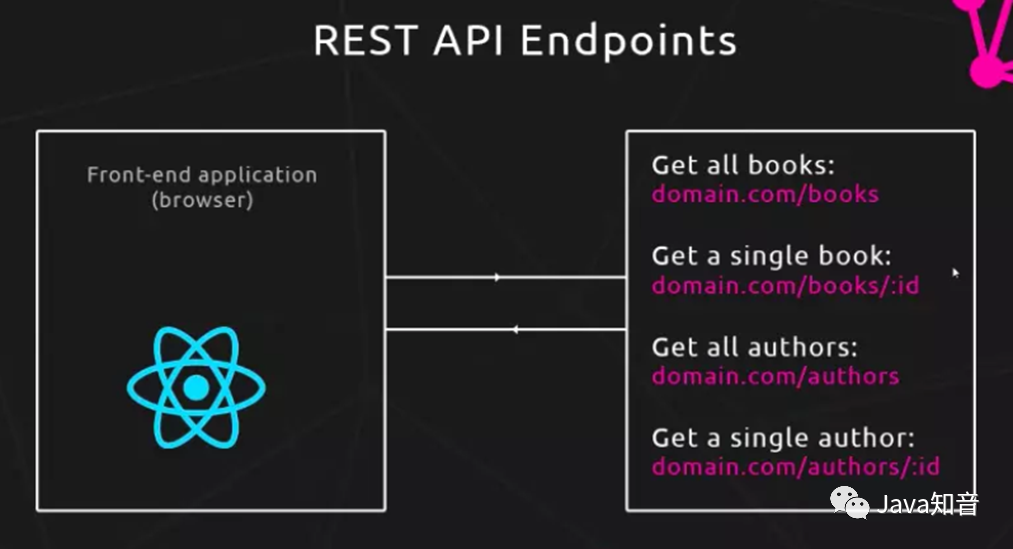
- 对于前端而言:REST API粒度较粗,难以一次性符合前端的数据要求,前端需要分多次请求接口数据。增加了前端人员的工作量。而且多次http请求会增加服务器负担。
- 对于后端而言:前端需要的数据往往在不同的地方具有相似性,但却又不同,比如针对同样的用户信息,有的地方只需要用户简要信息(比如头像、昵称),有些地方需要详细的信息,这就需要开发不同的接口来满足这些需求。当这样的相似但又不同的地方多的时候,就需要开发更多的接口来满足前端的需要。增加了后端开发人员的工作量和重复度。
那我们来分析一下,当前端需求变化,涉及到改动旧需求时,会有以下这些情况:
- 「做加法:」产品需求增加,页面需要增加功能,数据也就相应的要增加显示,那么REST接口也需要做增加,这种无可厚非。
- 「做减法:」产品需求减少,页面需要减少功能,或者减少某些信息显示,那么数据就要做减法。
- 「同时做加减法:」既有加法,又有减法,其实这种就跟新需求没啥区别,前端需要重做页面,后端需要新写接口满足前端需要,但是旧接口还是不能轻举妄动(除非确定只有这一处调用才可以删除)。
针对做减法,一种通常懒惰的做法是,前端不与后端沟通,仅在前端对数据选择性显示。
因为后端接口能够满足数据需要,仅仅是在做显示的时候对数据进行了选择性显示,但接口的数据是存在冗余的,这种情况一个是存在数据泄露风险,另外就是数据量过大时造成网络流量过大,页面加载缓慢,用户流量费白白消耗,用户体验就会下降。
另外一种做法就是告知后端,要么开发新的接口,要么,修改旧接口,删掉冗余字段。
但一般来说,开发新接口往往是后端开发人员会选择的方案,因为这个方案对现有系统的影响最低,不会有额外的风险。
修改旧接口删除冗余数据的方案往往开发人员不会选择,这是为什么呢?
这就涉及到了系统的稳定性问题了,旧接口往往不止是一个地方在用,很有可能很多页面、设置不同客户端、不同服务都调用了这个接口获取数据,不做详细的调查,是不可能知道到底旧接口被调用了多少次,一旦改动旧接口,涉及范围可能非常大,往往会引起其他地方出现崩溃。改动旧接口成本太高,所以往往不会被采取。
针对做加法或者同时加减法:
往往这个时候,其实用到的数据大多都是来自于同一个DO或者DTO,不过是在REST接口组装数据时,用不同的VO来封装不同字段,或者,使用同样的VO,组装数据时做删减。
看到这些问题是不是觉得令人头大?
所以需求频繁改动是万恶之源,当产品小哥哥改动需求时,程序员小哥哥可能正提着铁锹赶来...
那么有没有一种方案或者框架,可以使得在用到同一个领域模型(DO或者DTO)的数据时,前端对于这个模型的数据字段需求的改动,后端可以根据前端的改动和需要,自动适配,自动组装需要的字段,返回给前端呢?如果能这样做的话,那么后端程序猿小哥可能要开心死了,前端妹子也不用那么苦口婆心地劝说后端小哥哥了。
所以GraphQL隆重出世了!那么问题来了,graphql怎么解决上面问题的呢?
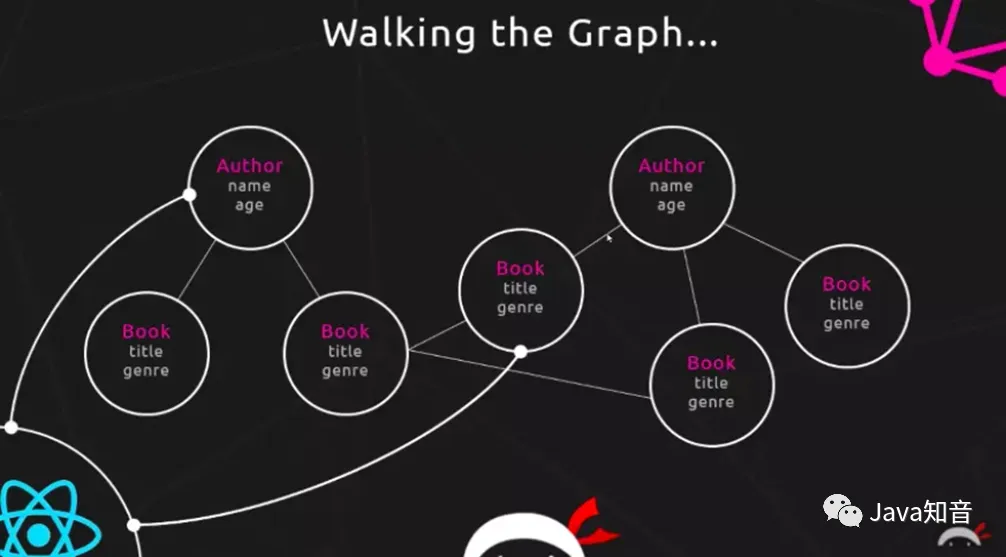
GraphQL 实际上将多个 HTTP 请求聚合成了一个请求,将多个 restful 请求的资源变成了一个从根资源 POST 访问其他资源的 Comment 和 Author 的图,多个请求变成了一个请求的不同字段,从原有的分散式请求变成了集中式的请求,因此GraphQL又可以被看成是图数据库的形式。
REST 痛点
传统写法:/api/user/basic、/api/user/withProfile、/api/user/withOrder... 每换个页面就加路由,后端跟着写一堆重复代码。
GraphQL 做法
前端只发一次请求,把字段写进 query 就行:
go
query { user(id:1){ name age avatar } } # 个人中心只要 3 个字段
query { user(id:1){ name vipLevel orderList{price} } } # 管理后台多拿订单自动生成"解析函数"骨架,CRUD 只剩一行数据库调用
g generate dao 自动把表结构翻译成 CRUD 方法;
gqlgen generate 自动把 GraphQL 字段翻译成 Go 接口;
开发者要做的只是"把两者粘起来"------代码量比手写 REST 少一半以上。
文档、Mock、SDK 零成本自带
GraphQL 的 schema 就是活的接口文档,打开 Playground 就能点点查;
前端可以直接用 graphql-code-generator 一键生成 TypeScript SDK,再也不用等后端给 Swagger;
测试同学用 graphql-faker 基于 schema 就能造 Mock 数据,前后端并行开发。
聚合查询一次网络往返,性能反而更高
传统场景:打开订单页→先查用户→再查订单→再查商品,三次 HTTP。
GraphQL 场景:一次请求,后端用 GoFrame 的 Join 或 Scan 一次性把三张表捞回来,减少网络 RTT,前端白屏时间更短。
升级、换库、分库分表对前端透明
哪天把 MySQL 换成 TiDB,或者把字段下划线改成驼峰,只要改 resolver 里的那一行 Scan,schema 不变前端就无感;
如果走 REST,路由、DTO、Swagger、前端 SDK 全得同步改一遍。
统一网关/限流/监控,GoFrame 原生能力直接复用
鉴权、日志、限流、Prometheus 指标,全部用 GoFrame 的中间件写一次即可;
GraphQL 只有一个 /query 入口,nginx 网关配一条规则就能限流,比 REST 动辄几十条路由好维护得多。
简单示例,怎么用------以golang为例
下面以goframe v2框架举例
我们假设目录结构是这样,具体可以再调整
一、目录结构
gframe-graphql/
├── api/ # GraphQL 相关文件
│ ├── generated/ # gqlgen 自动生成
│ ├── model/ # 业务模型(与数据库表对应)
│ ├── resolver.go # 把"GraphQL 语句"翻译成"GoFrame 数据库调用"
│ └── schema.graphqls # 纯文本的 GraphQL 接口描述
├── internal/
│ ├── cmd/
│ │ └── main.go # 项目入口,启动 HTTP + GraphQL
│ └── dao/ # GoFrame dao(自动生成的表操作)
├── hack/ # gqlgen 代码生成脚本
│ └── gqlgen.go
├── go.mod
└── config.yaml # GoFrame 数据库配置二、准备动作(一次性)
安装工具
go install github.com/99designs/gqlgen@latest拉依赖
go get github.com/gogf/gf/v2
go get github.com/99designs/gqlgen建数据库(MySQL 示例)
CREATE TABLE `user` (
`id int PRIMARY KEY AUTO_INCREMENT,
`name` varchar(32) NOT NULL,
`age int NOT NULL
);
INSERT INTO user(name,age) VALUES('Tom',18),('Jerry',19);在config文件中写好数据库连接配置,然后使用自带的gf gen工具生成dao层
三、代码编写
1、api/model/user.go // 与表字段一一对应
go
package model
// User 对应数据库表 user(字段名必须导出, gqlgen 才能用)
type User struct {
ID int `json:"id" orm:"id" `
Name string `json:"name" orm:"name"`
Age int `json:"age" orm:"age" `
}2、api/schema.graphqls // 纯文本,描述"前端能查什么"
graphql
type User {
id : Int! # ! 表示非空
name: String!
age : Int!
}
type Query {
userList: [User!]! # 返回一批用户 userList对应后面4中的函数
}3、hack/gqlgen.go // 生成代码的脚本
go
//go:build ignore
// +build ignore
package main
import (
"github.com/99designs/gqlgen/api"
"github.com/99designs/gqlgen/codegen/config"
"log"
)
func main() {
cfg, err := config.LoadConfigFromDefaultLocations()
if err != nil {
log.Fatalln(err)
}
if err = api.Generate(cfg, api.AddPlugin()); err != nil {
log.Fatalln(err)
}
}执行
go
go run hack/gqlgen.go会在 api/generated/ 里生成所有骨架,包括 resolver 接口。
4、api/resolver.go // 把"GraphQL 调用"翻译成"GoFrame 查库" 这个是关键 注意看好
go
package api
import (
"context"
"gql-demo/api/generated" // gqlgen 生成的接口包
"gql-demo/api/model"
"github.com/gogf/gf/v2/frame/g"
)
// Resolver 必须实现 generated.ResolverRoot 接口(生成器已帮你定义好)
type Resolver struct{}
// ------------------ Query 重点-------------------------
// UserList 对应 schema.graphqls 里的 userList 查询
func (r *Resolver) UserList(ctx context.Context) ([]*model.User, error) {
var users []*model.User
// 用 GoFrame 链式 ORM 查全表
err := g.DB().Model("user").Scan(&users)
if err != nil {
return nil, err
}
return users, nil
}
// 下面三个函数用于把 Resolver 嵌套到 gqlgen 运行时
func (r *Resolver) Query() generated.QueryResolver { return &queryResolver{r} }
type queryResolver struct{ *Resolver }5、internal/cmd/main.go // 入口:启动 HTTP + GraphQL Playground
go
package main
import (
"gql-demo/api"
"gql-demo/api/generated"
"github.com/99designs/gqlgen/graphql/handler"
"github.com/99designs/gqlgen/graphql/playground"
"github.com/gogf/gf/v2/frame/g"
"github.com/gogf/gf/v2/net/ghttp"
)
func main() {
// 1. 拿到 gqlgen 的解析器
srv := handler.NewDefaultServer(generated.NewExecutableSchema(generated.Config{Resolvers: &api.Resolver{}}))
// 2. 用 GoFrame 的 ghttp 注册路由
s := g.Server()
s.Group("/", func(group *ghttp.RouterGroup) {
group.GET("/") // 首页提示
group.GET("/graphql", playground.Handler("GraphQL playground", "/query")) // 可视化界面
group.POST("/query", srv.ServeHTTP) // 真正的 GraphQL 查询入口
})
// 3. 启动
s.Run()
}四、跑起来验证
go
go mod tidy
go run internal/cmd/main.go浏览器打开 http://localhost:8000/graphql,输入:
go
query {
userList {
id
name
age
}
}立刻返回:
go
{
"data": {
"userList": [
{ "id": 1, "name": "Tom", "age": 18 },
{ "id": 2, "name": "Jerry", "age": 19 }
]
}
}至此,GoFrame v2 负责数据库 CRUD,gqlgen 负责 GraphQL 协议,两者无缝拼接完成。
五、更加具体一点的使用
加where条件
加参数过滤:
在schema.graphqls的query里面,修改为
go
query { userList(age: Int): [User!]! }在 resolver 里判断 age != nil 再 .Where("age", age)
连表查询
一、数据库(MySQL)
go
CREATE TABLE `user` (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(32) NOT NULL
);
CREATE TABLE `product` (
id INT PRIMARY KEY AUTO_INCREMENT,
title VARCHAR(64) NOT NULL,
price DECIMAL(10,2) NOT NULL
);
CREATE TABLE `order` (
id INT PRIMARY KEY AUTO_INCREMENT,
user_id INT NOT NULL,
product_id INT NOT NULL,
num INT NOT NULL,
CONSTRAINT fk_user FOREIGN KEY (user_id) REFERENCES user(id),
CONSTRAINT fk_product FOREIGN KEY (product_id) REFERENCES product(id)
);
go
-- 造点数据
INSERT INTO user(name) VALUES ('Tom'),('Jerry');
INSERT INTO product(title,price) VALUES ('iPhone',5999),('MacBook',9999);
INSERT INTO `order`(user_id,product_id,num) VALUES (1,1,2),(2,2,1);二、GraphQL schema(api/schema.graphqls)
go
type User {
id : Int!
name: String!
}
type Product {
id : Int!
title: String!
price: Float!
}
type Order {
id : Int!
user : User! # 连表对象
product: Product! # 连表对象
num : Int!
}
type Query {
orderList: [Order!]! # 一次返回订单+用户+商品
}三、Go 代码(只贴关键 diff,其余沿用上一篇骨架)
api/model/entity.go // 三张表的实体(GoFrame 命令 gf gen dao 会帮你生成,这里手写简版方便阅读)
go
package model
type User struct {
Id int `json:"id" orm:"id"`
Name string `json:"name" orm:"name"`
}
type Product struct {
Id int `json:"id" orm:"id"`
Title string `json:"title" orm:"title"`
Price float64 `json:"price" orm:"price"`
}
type Order struct {
Id int `json:"id" orm:"id"`
UserId int `json:"user_id" orm:"user_id"`
ProductId int `json:"product_id" orm:"product_id"`
Num int `json:"num" orm:"num"`
// 连表对象(数据库不存在,仅用于返回)
User *User `json:"user" orm:"with:uid=id"` // 语义标签,非 ORM 约束
Product *Product `json:"product" orm:"with:pid=id"`
}api/resolver.go // 核心:一条 SQL 连三表,一次性 Scan 进结构体
go
package api
import (
"context"
"gql-demo/api/generated"
"gql-demo/api/model"
"github.com/gogf/gf/v2/frame/g"
)
type Resolver struct{}
// OrderList 是实现 schema.graphqls 里 orderList 查询的函数
func (r *Resolver) OrderList(ctx context.Context) ([]*model.Order, error) {
// 写一条连表 SQL,用别名让结果和 Go 结构体字段一一对应
sql := `
SELECT
o.id AS id,
o.num AS num,
u.id AS uid,
u.name AS uname,
p.id AS pid,
p.title AS ptitle,
p.price AS pprice
FROM ` + "`order` o " + `
JOIN user u ON o.user_id = u.id
JOIN product p ON o.product_id = p.id
`
var list []*model.Order
// ScanList 自动把多行结果映射到切片
err := g.DB().Ctx(ctx).Raw(sql).ScanList(&list, "Order")
if err != nil {
return nil, err
}
// 二次循环把平铺结果挂到嵌套对象,方便 gqlgen 直接返回
for _, o := range list {
o.User = &model.User{
Id: o.UserId,
Name: o.User.Name, // 这里已从 SQL 别名 uname 映射好
}
o.Product = &model.Product{
Id: o.ProductId,
Title: o.Product.Title,
Price: o.Product.Price,
}
}
return list, nil
}
// 下面三行把 Resolver 注册到 gqlgen
func (r *Resolver) Query() generated.QueryResolver { return &queryResolver{r} }
type queryResolver struct{ *Resolver }其余文件(main.go、schema、初始化)沿用上一篇即可,无需改动。
跑起来验证
go
go run internal/cmd/main.go浏览器打开 http://localhost:8000/graphql,输入:
bash
query {
orderList {
id
num
user { id name }
product { id title price }
}
}返回:
bash
{
"data": {
"orderList": [
{
"id": 1,
"num": 2,
"user": { "id": 1, "name": "Tom" },
"product": { "id": 1, "title": "iPhone", "price": 5999 }
},
{
"id": 2,
"num": 1,
"user": { "id": 2, "name": "Jerry" },
"product": { "id": 2, "title": "MacBook", "price": 9999 }
}
]
}
}复杂聚合查询(max、count等)与分页
在 GraphQL 里用 COUNT、SUM、MAX 等聚合函数 一样能玩,思路只有两步:
在 schema 里把"聚合结果"当成一个普通对象暴露出去;
在 resolver 里写 GoFrame 链式 SQL(或 Raw),把 SELECT COUNT(*) ... GROUP BY ... 的结果 Scan 进结构体,再返回。
下面给你一个「完整可跑」的例子:
需求:前端要看到 每个商品被下单多少次、卖出去多少件、总销售额。
一、数据库(沿用之前 order/user/product)
go
-- 已有数据
INSERT INTO `order`(user_id,product_id,num) VALUES (1,1,2),(2,1,3),(2,2,1);
-- 需要算:
-- 商品1 2+3=5件 销售额 5*5999
-- 商品2 1件 销售额 1*9999二、GraphQL schema(api/schema.graphqls)
graphql
复制
go
type ProductStat {
productId : Int! # 商品主键
title : String! # 商品名称(连表取)
orderCount : Int! # 订单笔数 COUNT(*)
totalNum : Int! # 卖出件数 SUM(num)
totalAmount : Float! # 总销售额 SUM(num*price)
}
type Query {
productStatList: [ProductStat!]! # 聚合列表
}三、Go 代码(关键 resolver)
模型(api/model/stat.go)
go
package model
type ProductStat struct {
ProductId int `json:"productId"` // 商品主键
Title string `json:"title"` // 商品标题
OrderCount int `json:"orderCount"` // 订单笔数
TotalNum int `json:"totalNum"` // 卖出件数
TotalAmount float64 `json:"totalAmount"` // 总销售额
}resolver(api/resolver.go)
go
func (r *Resolver) ProductStatList(ctx context.Context) ([]*model.ProductStat, error) {
// 写法1:GoFrame 链式 + Raw,直接一条 SQL 解决
sql := `
SELECT
p.id AS product_id,
p.title,
COUNT(*) AS order_count,
SUM(o.num) AS total_num,
SUM(o.num * p.price) AS total_amount
FROM product p
JOIN ` + "`order` o " + `ON o.product_id = p.id
GROUP BY p.id, p.title
`
var list []*model.ProductStat
if err := g.DB().Ctx(ctx).Raw(sql).Scan(&list); err != nil {
return nil, err
}
return list, nil
}
go
// 注册到 gqlgen
func (r *Resolver) Query() generated.QueryResolver { return &queryResolver{r} }
type queryResolver struct{ *Resolver }四、跑起来
go
go run internal/cmd/main.goPlayground 里输入:
go
query {
productStatList {
productId
title
orderCount
totalNum
totalAmount
}
}返回:
go
{
"data": {
"productStatList": [
{
"productId": 1,
"title": "iPhone",
"orderCount": 2,
"totalNum": 5,
"totalAmount": 29995
},
{
"productId": 2,
"title": "MacBook",
"orderCount": 1,
"totalNum": 1,
"totalAmount": 9999
}
]
}
}五、如果你更喜欢"纯链式 ORM"而不写 Raw
GoFrame 也支持链式调法:
go
复制
go
db := g.DB().Model("order o").
Fields("o.product_id", "p.title", "COUNT(*) order_count", "SUM(o.num) total_num", "SUM(o.num*p.price) total_amount").
LeftJoin("product p", "p.id=o.product_id").
Group("o.product_id, p.title")
var list []*model.ProductStat
err := db.Scan(&list)等价效果,不想手写 SQL 也能拼出来。
分页
把 schema 改成:
go
type ProductStatPage {
list : [ProductStat!]!
totalCount : Int! # 总商品数
}
type Query {
productStatPage(page: Int = 1, size: Int = 10): ProductStatPage!
}resolver 里用 GoFrame 分页语法:
go
page, size := g.RequestFromCtx(ctx).GetPage(size, page)
db := g.DB().Model(...).Page(page, size)
total, _ := db.Count()
list := make([]*model.ProductStat, 0)
db.Scan(&list)
return &model.ProductStatPage{List: list, TotalCount: total}, nil前端拿到 totalCount 可直接渲染分页条。
结论
GraphQL 不排斥聚合函数,把 COUNT/SUM 的结果当成普通对象返回即可;
写一条带 GROUP BY 的 SQL(或链式 ORM),Scan 进结构体,resolver 原样抛出;
再套个 Page() 就能支持分页,复杂度跟写 REST 完全一样,却保留了"前端要多少字段拿多少"的灵活性。
增删改
加 Mutation:在 schema.graphqls 里写
go
mutation { createUser(name:String!,age:Int!):User! }然后实现 func (r *mutationResolver) CreateUser(...),内部用
g.DB().Model("user").Data(g.Map{...}).Insert() 即可。
如果需要更新与删除
go
type Mutation {
# 1. 插入
createOrder(userId: Int!, productId: Int!, num: Int!): Order!
# 2. 更新
updateOrderNum(id: Int!, num: Int!): Order!
# 3. 删除
deleteOrder(id: Int!): Boolean! # 返回 true 表示成功
}使用graphql一定要做好数据隔离
比如 举个例子 本来用户只能查自己的订单 但是上面的方式 用户能够直接调用代码 查到别人的订单 通过订单id号为别人
后面会讲怎么处理这种情况
简单验权
用户 A 发一条 query { order(id: 1234) { user { name } } }
而订单 1234 其实是用户 B 的 → 直接越权暴露隐私。
下面把「为什么会出现」「怎么修」「代码怎么改」一步步拆开给你看,并给出可直接落地的 最小权限样板。
一、复现越权场景(用我们前面的例子)
resolver 里现在是这样:
go
func (r *Resolver) Order(ctx context.Context, id int) (*model.Order, error) {
var o model.Order
// 没有任何身份判断,直接按主键查
err := g.DB().Model("order").Where("id", id).Scan(&o)
return &o, err
}请求:
go
query { order(id: 1) { id user { name } } }只要知道订单号就能拿到别人的订单 → 水平权限漏洞(IDOR)。
二、修复思路:在 resolver 里加「数据归属」校验
登录时把用户 ID 写进 JWT(或 Session)。
每次查询都拿"当前用户 ID"和"要查数据的所属用户 ID"比对,不等就直接返回错误。
不要信任前端传的"用户 ID",只认后端从 token 里解析出来的。
三、代码改造(最小侵入版)
登录成功时签发 JWT(只贴关键片段)
go
// internal/logic/user.go
import "github.com/golang-jwt/jwt/v4"
func Login(ctx context.Context, name string) (string, error) {
var u model.User
if err := g.DB().Model("user").Where("name", name).Scan(&u); err != nil {
return "", err
}
token := jwt.NewWithClaims(jwt.SigningMethodHS256, jwt.MapClaims{
"uid": u.Id, // 把用户主键写进去
"exp": time.Now().Add(24 * time.Hour).Unix(),
})
return token.SignedString([]byte("your-secret"))
}写一个中间件,把 uid 塞进 context
go
复制
go
// internal/middleware/auth.go
func Auth(r *ghttp.Request) {
tokenStr := r.Header.Get("Authorization")
claims := jwt.MapClaims{}
if _, err := jwt.ParseWithClaims(tokenStr, &claims, func(t *jwt.Token) (interface{}, error) {
return []byte("your-secret"), nil
}); err != nil {
r.Response.WriteStatusExit(401, "Unauthorized")
}
uid := int(claims["uid"].(float64))
// 把当前用户 ID 塞进后续能拿到的 context
ctx := context.WithValue(r.Context(), "uid", uid)
r.SetCtx(ctx)
r.Middleware.Next()
}在 resolver 里做"订单归属"判断
go
func (r *Resolver) Order(ctx context.Context, id int) (*model.Order, error) {
// 1. 取当前登录用户
uid, ok := ctx.Value("uid").(int)
if !ok {
return nil, fmt.Errorf("未登录")
}
// 2. 先查订单
var o model.Order
if err := g.DB().Model("order").Where("id", id).Scan(&o); err != nil {
return nil, err
}
// 3. 关键:订单不属于当前用户 → 直接拒绝
if o.UserId != uid {
return nil, fmt.Errorf("无权查看他人订单")
}
// 4. 再补连用户、商品(同之前)
_ = g.DB().Model("user").Where("id", o.UserId).Scan(&o.User)
_ = g.DB().Model("product").Where("id", o.ProductId).Scan(&o.Product)
return &o, nil
}路由层挂中间件(main.go)
go
s := g.Server()
s.Group("/query", func(g *ghttp.RouterGroup) {
g.Middleware(middleware.Auth) // 所有 GraphQL 请求先过鉴权
g.ALL("", graphqlHandler)
})四、效果验证
用户 A 的 uid=1,JWT 里也是 1
请求 order(id:1) → 订单.user_id=1 → 正常返回
用户 A 改 id 为 2
订单.user_id=2 ≠ 1 → 直接报错
{"errors":{"message":"无权查看他人订单"}}
五、再上层保险(可选)
数据库层加 row-level security(MySQL 8.0 支持 RLS,Pg 更成熟),SQL 里自带 WHERE user_id = current_uid(),即使代码漏判也查不到。
把"用户 ID"作为 强制参数 放进 GraphQL 查询,例如:
graphql
复制
query { myOrderList { id product { title } } } # 后端永远只返回当前用户
不提供按订单号单查的入口,彻底杜绝越权。
网关层统一做 字段级授权(graphql-shield 规则),resolver 只写业务,不用重复写 if uid!=xxx。
结论
GraphQL 不会自动帮你做"只能看自己的"这种业务级隔离;
"谁能看哪条数据"必须自己在 resolver(或服务层)里显式判断,判断依据只能来自后端可信的登录态(JWT/session),绝不能信任前端传的任何"用户 ID"。
只要加上"数据归属"这一行 if,就能把前面说的"订单 ID 遍历"漏洞彻底堵死。
直接拖库
会------但只要按规范部署,GraphQL 并不比 REST 更"危险"。
把"整个库被拉走"通常不是 GraphQL 本身的问题,而是缺了必要的安全治理。下面把常见风险点、攻击场景和对应的"加固措施"逐条列给你,所有结论都基于 2024-2025 年社区与厂商的公开复盘 。
一、GraphQL 独有的"可被直接拖库"风险场景
无限嵌套 + 缺少深度限制
典型 payload:
graphql
复制
query { user(id: 1) {
friends { # 第 1 层
friends { # 第 2 层
friends { # ...
friends { id name email }
}
}
}
} }
如果好友关系双向,一条查询就能指数级膨胀,把全站用户刷出来 。
→ 缓解:给 gqlgen 加 FixedComplexityLimit 或 depthLimit 中间件,推荐深度 ≤ 8。
缺少分页 / 数量限制
graphql
复制
query { users { id name email phone } } # 一次 SELECT * FROM user
十万用户直接打满内存。
→ 缓解:
全部列表型字段强制加 first/last/max=50 参数;
在数据库层用 游标分页(WHERE id > cursor LIMIT 50),而不是 OFFSET。
内省(Introspection)把整张"数据地图"暴露给陌生人
默认 /graphql?query={__schema{types{name fields{name}}}} 就能拿到所有字段、关系、枚举值 。
→ 生产环境务必关闭内省(gqlgen 的 introspection: false),或者只在调试白名单 IP 开启。
未做字段级授权------"查得到对象就能看到所有列"
例如 User 类型里把 email、idCard、salary 全部暴露,普通用户也能顺手带走别人的敏感列。
→ 缓解:
在 resolver 里做 列白名单(row-level + column-level);
或者使用 GraphQL 网关(Apollo Router / graphql-shield)统一加权限注解。
二、"老熟人"漏洞在 GraphQL 里一样会出现
SQL 注入
直接把参数拼进 SQL:
go
复制
db.Raw("SELECT * FROM user WHERE name = '" + name + "'") // ❌
社区案例里被 sqlmap 一把拖走 。
→ 始终用参数化查询 / GoFrame ORM 链式条件,不要手写拼接。
CSRF / Clickjacking
如果 GraphQL 端点接受 application/x-www-form-urlencoded,攻击者可以构造隐藏表单把恶意 mutation 塞进去 。
→ 只接受 application/json;启用 CSRF Token 或 SameSite=Strict。
批量查询(Batching)轰炸
HTTP/2 下一次发 1000 条 {users{...}} 请求体,服务器照样会执行 1000 次 SQL。
→ 在网关层限制 单 HTTP 请求只含单一 GraphQL 查询;或者给 Batching 总量设上限(Apollo 默认 10)。
三、业界落地的"最小安全基线"清单
表格
复制
防护措施 推荐值 / 工具 作用
查询深度限制 ≤ 8 层 防无限嵌套
查询复杂度上限 5000 点(gqlgen FixedComplexityLimit) 防 DoS
分页大小上限 50 条 / 次 防一次性拖全表
关闭内省 introspection: false 隐藏数据地图
字段级授权 graphql-shield / 手写 if 防越权
参数化 SQL GoFrame .Where("id", uid) 防 SQL 注入
关闭 GraphiQL 生产环境不挂载 playground 减少调试入口
速率限制 100 req/min / IP 防爆破
结论
GraphQL 确实比 REST 多一个"可被任意字段查询"的入口,但只要在网关 / resolver 里把"深度、数量、权限、速率"四件事管住,它就不会比传统接口更容易被拖库。相反,schema 驱动的强类型反而让"字段级审计"更容易自动化。
一句话:安全不是 GraphQL 的锅,缺安全策略才是。
知识讲解
GraphQL的核心概念:图表模式(Schema)
要想要设计GraphQL的数据模型,用来描述你的业务数据,那么就必须要有一套Schema语法来做支撑。
数据类型
想要描述数据,就必须离不开数据类型的定义。所以GraphQL设计了一套Schema模式(可以理解为语法),其中最重要的就是数据类型的定义和支持。
那么类型(Type)就是模式(Schema)最核心的东西了。
什么是类型?
对于数据模型的抽象是通过类型(Type)来描述的,每一个类型有若干字段(Field)组成,每个字段又分别指向某个类型(Type)。这很像Java、C#中的类(Class)。
GraphQL的Type简单可以分为两种,一种叫做Scalar Type(标量类型),另一种叫做Object Type(对象类型)。
那么就分别来介绍下两种类型。
标量类型(Scalar Type)
标量是GraphQL类型系统中最小的颗粒。类似于Java、C#中的基本类型。
其中内建标量主要有:
String
Int
Float
Boolean
Enum
ID
上面的类型仅仅是GraphQL默认内置的类型,当然,为了保证最大的灵活性,GraphQL还可以很灵活的自行创建标量类型。
对象类型(Object Type)
仅有标量类型是不能满足复杂抽象数据模型的需要,这时候我们可以使用对象类型。
通过对象模型来构建GraphQL中关于一个数据模型的形状,同时还可以声明各个模型之间的内在关联(一对多、一对一或多对多)。
对象类型的定义可以参考下图:
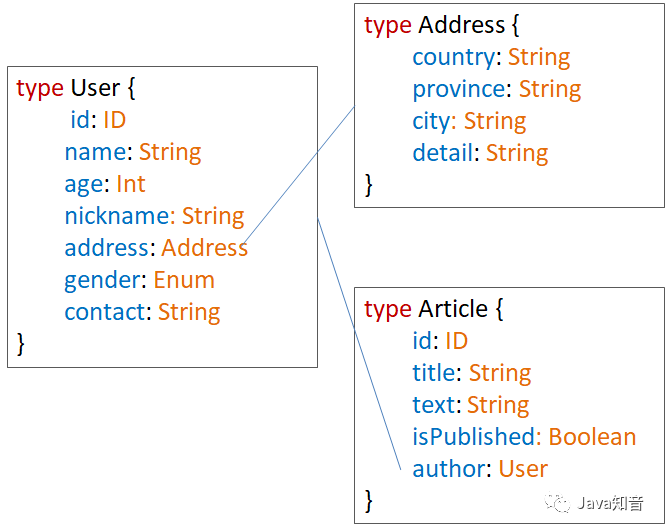
是不是很方便呢?我们可以像设计类图一样来设计GraphQL的对象模型。
类型修饰符(Type Modifier)
那么,类型系统仅仅只有类型定义是不够的,我们还需要对类型进行更广泛性的描述。
类型修饰符就是用来修饰类型,以达到额外的数据类型要求控制。
比如:
列表:Type
非空:Type!
列表非空:Type!
非空列表,列表内容类型非空:Type!!
在描述数据模型(模式Schema)时,就可以对字段施加限制条件。
例如定义了一个名为User的对象类型,并对其字段进行定义和施加限制条件:

那么,返回数据时,像下面这种情况就是不允许的:

Graphql会根据Schema Type来自动返回正确的数据:

其他类型
除了上面的,Graphql还有一些其他类型来更好的引入面向对象的设计思想:
接口类型(Interfaces):
其他对象类型实现接口必须包含接口所有的字段,并具有相同的类型修饰符,才算实现接口。
比如定义了一个接口类型:

那么就可以实现该接口:
联合类型(Union Types):
联合类型和接口十分相似,但是它并不指定类型之间的任何共同字段。几个对象类型共用一个联合类型。

输入类型(Input Types):
更新数据时有用,与常规对象只有关键字修饰不一样,常规对象时 type 修饰,输入类型是 input 修饰。
比如定义了一个输入类型:

前端发送变更请求时就可以使用(通过参数来指定输入的类型):

所以,这样面向对象的设计方式,真的对后端开发人员特别友好!而且前端MVVM框架流行以来,面向对象的设计思想也越来越流行,前端使用Graphql也会得心应手。
Graphql 技术接入架构
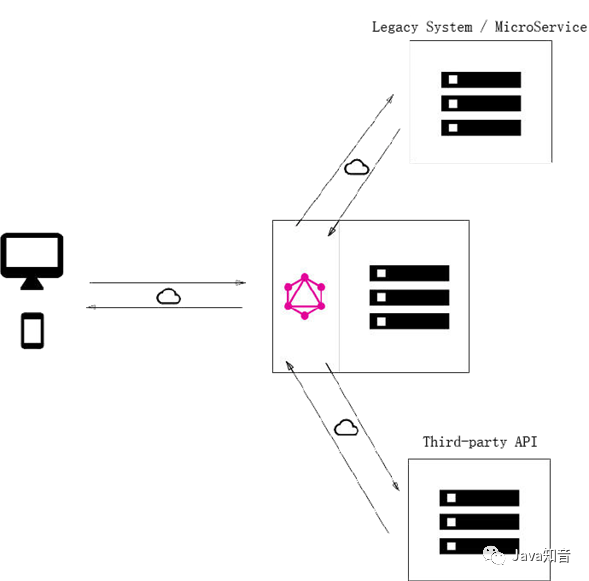
那么,该怎么设计来接入我们现有的系统中呢?
将Graphql服务直连数据库的方式:最简洁的配置,直接操作数据库能减少中间环节的性能消耗。

集成现有服务的GraphQL层:这种配置适合于旧服务的改造,尤其是在涉及第三方服务时、依然可以通过原有接口进行交互。

直连数据库和集成服务的混合模式:前两种方式的混合。
这种模式 其实更像graphql实现了传统api定义层或者controller层需要的东西,自定义传哪些字段
需要对后台服务大改么?
使用了GraphQL就要完全抛弃REST了吗?
GraphQL需要直接对接数据库吗?
使用GraphQL需要对现有的后端服务进行大刀阔斧的修改吗?
答案是:NO!不需要!(即使不采用下面的部署模式也不用这么大的修改)
它完全可以以一种不侵入的方式来部署,将它作为前后端的中间服务,也就是,现在开始逐渐流行的 前端 ------ 中端 ------ 后端 的三层结构模式来部署!
那就来看一下这样的部署模式图:
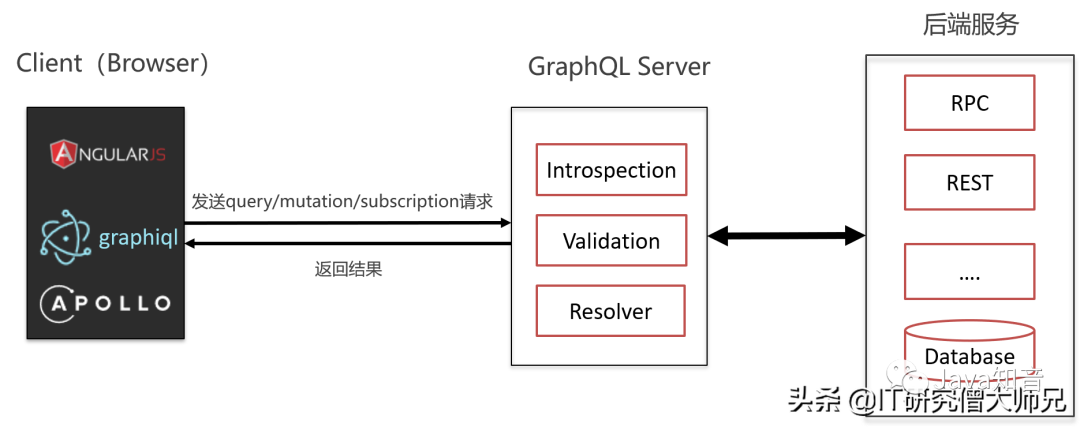
GraphQL应用的基本架构
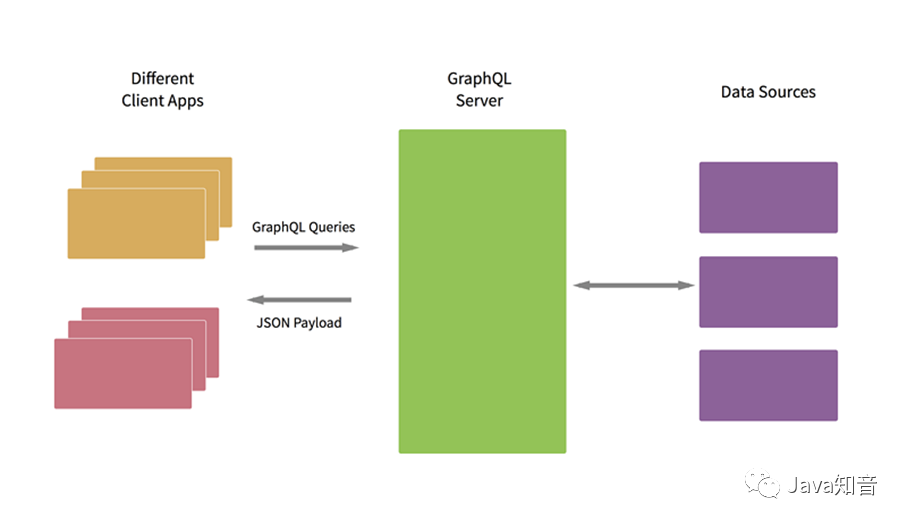
下图是一个 GraphQL 应用的基本架构,其中客户端只和 GraphQL 层进行 API 交互,而 GraphQL 层再往后接入各种数据源。这样一来,只要是数据源有的数据, GraphQL 层都可以让客户端按需获取,不必专门再去定接口了。
一个GraphQL服务仅暴露一个 GraphQL Endpoint,可以按照业务来进行区分,部署多个GraphQL服务,分管不同的业务数据,这样就可以避免单服务器压力过大的问题了。
Graphql的一些工具
graphiql (npm): 一个交互式的运行于浏览器中的 GraphQL IDE。
Graphql Language Service: 一个用于构建 IDE 的 GraphQL 语言服务(诊断、自动完成等) 的接口。
quicktype (github): 在 TypeScript、Swift、golang、C#、C++ 等语言中为 GraphQL 查 询生成类型。
想要获取更多关于Graphql的一些框架、工具,可以去awesome-graphql:一个神奇的社区,维护一系列库、资源等,地址是
https://github.com/chentsulin/awesome-graphql。
想要学习更多Graphql的知识,可以去GraphQL.cn。
other
我能这样理解么 实际上就是 后端把所有数据都查出来,然后前端根据需要 自己选择需要展示哪些字段?
不是"后端把所有数据都查出来",而是:
后端只查前端"请求里要的那些字段"(GraphQL 的按需查询)。
举个例子:
schema 里即使暴露了 20 个字段,前端只写 3 个 → resolver 里只会 SELECT id, name, price(gqlgen 会自动帮你投影),不会把另外 17 个字段捞回来。
数据库层面也是按需的(不会 SELECT *)。
下面给你一段实测代码,同一接口,两次请求,SQL 语句字段数完全不同。
实测对比(gqlgen + GoFrame)
schema:
go
type Product {
id : Int!
title : String!
price : Float!
stock : Int!
description : String!
}resolver 里打印实际 SQL:
go
func (r *Resolver) Product(ctx context.Context, id int) (*model.Product, error) {
// 这里故意不写具体字段,用 gqlgen 的自动投影
var p model.Product
err := g.DB().Model("product").Where("id", id).Scan(&p)
g.Log().Debug(ctx, g.DB().GetLastSql()) // 打印 SQL
return &p, err
}① 前端只要标题:
go
query { product(id:1){ title } }实际 SQL(日志):
go
SELECT `title` FROM `product` WHERE `id` = 1② 前端多要两个字段:
go
query { product(id:1){ title price stock } }实际 SQL:
go
SELECT `title`, `price`, `stock` FROM `product` WHERE `id` = 1看到区别了吗?gqlgen 会根据 selection set 自动帮你拼接要查询的字段,不会 SELECT * 回来再过滤。
例外情况
你在 resolver 里手写 Raw SQL 并且写了 SELECT *,那就真的会全表拖;
→ 解决:用链式 ORM 或者手写字段列表,保持与前端 selection 一一对应。
嵌套子对象(friends{...})默认会再发一次 SQL;
→ 可用 DataLoader 或提前 JOIN 批量解决,但依旧只选要用的列。
一句话总结
GraphQL 的"按需"是全程按需:
前端只问 3 个字段 → resolver 只解析 3 个字段 → SQL 只查 3 个字段 → 网络只回 3 个字段。
不是"全查回来再挑",而是"没点的分支连数据库都不碰"。