查看GaussDB集群状态:
sql
[Ruby@gs01 ~]$ cm_ctl query -Cvdip
[ CMServer State ]
node node_ip instance state
---------------------------------------------------------------------
1 gs01 192.168.3.60 1 /data/cluster/cmserver/cm_server Primary
[ Cluster State ]
cluster_state : Normal
redistributing : No
balanced : Yes
current_az : AZ_ALL
[ Datanode State ]
node node_ip instance state
--------------------------------------------------------------------------------------
1 gs01 192.168.3.60 6001 8000 /data/cluster/master/datanode1 P Primary Normal
[Ruby@gs01 ~]$ 1.模拟注入故障,修改数据库参数。
sql
[Ruby@gs01 ~]$ gs_guc reload -Z datanode -N all -I all -c "thread_pool_attr = '32,2,(cpubind:0-1,10-16)'"
The gs_guc run with the following arguments: [gs_guc -Z datanode -N all -I all -c thread_pool_attr = '32,2,(cpubind:0-1,10-16)' reload ].
Begin to perform the total nodes: 1.
Popen count is 1, Popen success count is 1, Popen failure count is 0.
Begin to perform gs_guc for datanodes.
Command count is 1, Command success count is 1, Command failure count is 0.
Total instances: 1. Failed instances: 0.
ALL: Success to perform gs_guc!2.停止数据库,停止成功。
sql
[Ruby@gs01 datanode1]$ cm_ctl stop
cm_ctl: stop cluster.
cm_ctl: stop nodeid: 1
cm_ctl: check node status take 0 seconds.
.
cm_ctl: check node status take 0 seconds.
.
cm_ctl: check node status take 0 seconds.
.
cm_ctl: check node status take 0 seconds.
.
cm_ctl: check node status take 0 seconds.
.
cm_ctl: check node status take 0 seconds.
.
cm_ctl: check node status take 1 seconds.
.
cm_ctl: check node status take 0 seconds.
.
cm_ctl: check node status take 0 seconds.
.
cm_ctl: check node status take 0 seconds.
.
cm_ctl: check node status take 0 seconds.
.
cm_ctl: check node status take 0 seconds.
.
cm_ctl: check node status take 0 seconds.
.
cm_ctl: stop cluster successfully.
[Ruby@gs01 datanode1]$ 3.切换到root用户,执行iptables命令,注入网络故障。
sql
[root@gs01 ~]# iptables -I OUTPUT -p tcp --dport 25000 -j REJECT
[root@gs01 ~]# iptables-save
# Generated by iptables-save v1.8.5 on Sat Nov 22 15:42:35 2025
*filter
:INPUT ACCEPT [5:324]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [5:356]
-A OUTPUT -p tcp -m tcp --dport 25000 -j REJECT --reject-with icmp-port-unreachable
COMMIT
# Completed on Sat Nov 22 15:42:35 2025
[root@gs01 ~]# 4.切换到Ruby用户,重启数据库。发现启动失败。
sql
[root@gs01 ~]# su - Ruby
Last login: Sat Nov 22 15:01:36 CST 2025 on pts/2
Last failed login: Sat Nov 22 15:26:33 CST 2025 from fe80::42af:caf5:3ad:be36%ens33 on ssh:notty
There was 1 failed login attempt since the last successful login.
[Ruby@gs01 ~]$
[Ruby@gs01 ~]$ cm_ctl start
cm_ctl: checking cluster status.
cm_ctl: check node status take 0 seconds.
cm_ctl: start cluster.
cm_ctl: start nodeid: 1
...................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................
cm_ctl: start cluster failed in (600)s.
[Ruby@gs01 ~]$ 5.查看集群状态,CMServer 状态为Down,为CMServer 组件启动失败。
sql
[Ruby@gs01 ~]$ cm_ctl query -Cvid
[ CMServer State ]
node node_ip instance state
---------------------------------------------------------------------
1 gs01 192.168.3.60 1 /data/cluster/cmserver/cm_server Down
cm_ctl: can't connect to cm_server.
Maybe cm_server is not running, or timeout expired. Please try again.
[Ruby@gs01 ~]$ 6.查看CMServer 进程状态,当前进程已启动。
sql
[Ruby@gs01 ~]$ ps -ef | grep cm_server | grep -v grep
Ruby 43849 1 0 15:44 ? 00:00:01 /data/cluster/omm/gaussdbapp/bin/cm_server
[Ruby@gs01 ~]$ 7.根据集群启动时间和日志文件修改时间,查看数据库启动时间点CMAgent日志。
sql
[Ruby@gs01 ~]$ cd $GAUSSLOG/cm/cm_agent
[Ruby@gs01 cm_agent]$ ls -lrt | grep cm_agent
-rw------- 1 Ruby Ruby 575185 Nov 22 16:00 cm_agent-2025-11-22_144034-current.log
[Ruby@gs01 cm_agent]$ 8.查看对应日志,搜索ERROR。

9.切换到root用户,查看iptables防火墙规则。

10.主机iptables规则禁用5000端口,删除相应iptables规则。
sql
[root@gs01 ~]# iptables -D OUTPUT 1
[root@gs01 ~]# iptables-save
# Generated by iptables-save v1.8.5 on Sat Nov 22 16:07:31 2025
*filter
:INPUT ACCEPT [619:179271]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [619:179303]
COMMIT
# Completed on Sat Nov 22 16:07:31 2025
[root@gs01 ~]# iptables -L -n --line-number
Chain INPUT (policy ACCEPT)
num target prot opt source destination
Chain FORWARD (policy ACCEPT)
num target prot opt source destination
Chain OUTPUT (policy ACCEPT)
num target prot opt source destination
[root@gs01 ~]# 11.切换到Ruby用户,重启GaussDB集群。
sql
[Ruby@gs01 ~]$ cm_ctl start
cm_ctl: checking cluster status.
cm_ctl: check node status take 0 seconds.
cm_ctl: start cluster.
cm_ctl: start nodeid: 1
.................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................
cm_ctl: start cluster failed in (600)s.
[Ruby@gs01 ~]$ 12.查看集群状态。
sql
[Ruby@gs01 ~]$ cm_ctl query -Cvid
[ CMServer State ]
node node_ip instance state
---------------------------------------------------------------------
1 gs01 192.168.3.60 1 /data/cluster/cmserver/cm_server Primary
[ Cluster State ]
cluster_state : Unavailable
redistributing : No
balanced : No
current_az : AZ_ALL
[ Datanode State ]
node node_ip instance state
-------------------------------------------------------------------------------
1 gs01 192.168.3.60 6001 /data/cluster/master/datanode1 P Down Unknown
[Ruby@gs01 ~]$ 13.查看Datanode状态为Down所在节点的dn进程。
sql
[Ruby@gs01 ~]$ ps -ef | grep dn
Ruby 71445 53361 0 16:24 pts/2 00:00:00 grep dn
[Ruby@gs01 ~]$ 14.根据集群启动时间和日志文件修改时间,查看数据库启动时间点CMAgent组件的system_call日志。
sql
[Ruby@gs01 ~]$ cd $GAUSSLOG/cm/cm_agent
[Ruby@gs01 cm_agent]$ ls -lrt | grep system_call
-rw------- 1 Ruby Ruby 1463956 Nov 22 16:25 system_call-current.log
[Ruby@gs01 cm_agent]$ 15.查看集群启动对应时间点日志,查看报错如下。
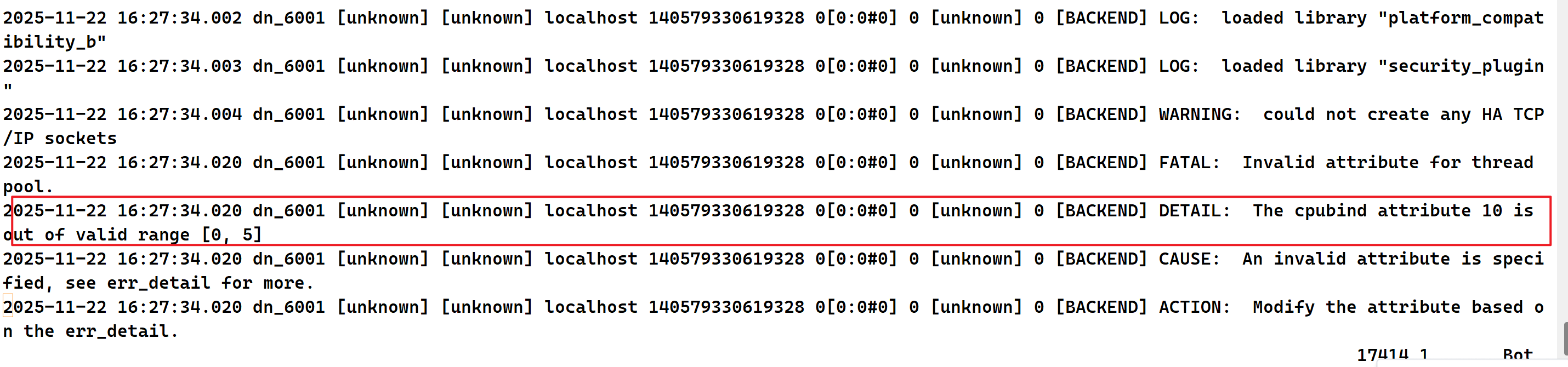
集群启动失败是由于参数设置不合理或设置错误,当每个节点的参数配置错误,则会导致集群不可启动。
16.登录Datanode状态异常节点,排查日志中参数文件路径,打开日志中报错的配置文件,查找对应报错参数,将错误配置行修正。
sql
vim /data/cluster/master/datanode1/gaussdb.conf参数thread_pool_attr配置如下:
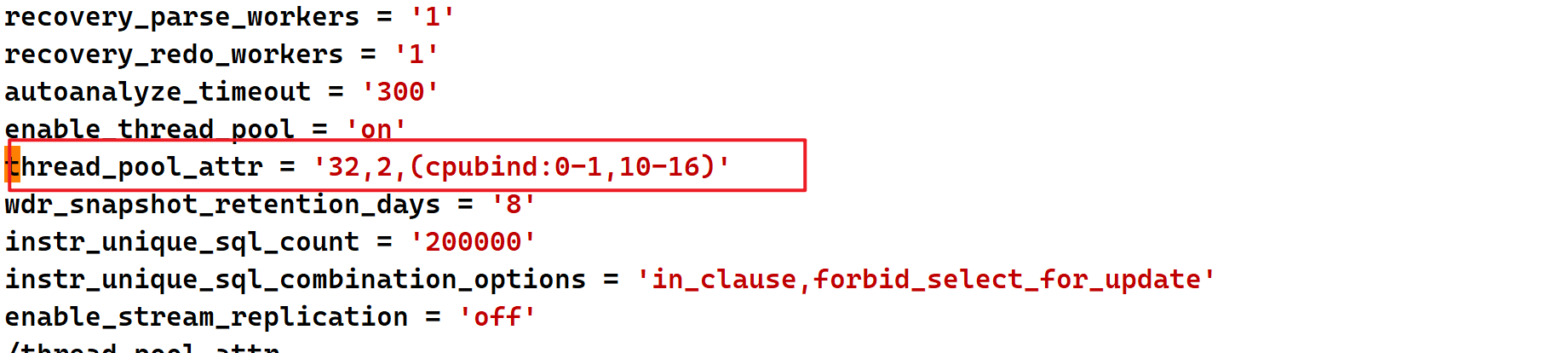
更正对应的参数配置,保存退出:

17.重启GaussDB集群,这次可以启动成功。
sql
[Ruby@gs01 cm_agent]$ cm_ctl start
cm_ctl: checking cluster status.
cm_ctl: check node status take 0 seconds.
cm_ctl: start cluster.
cm_ctl: start nodeid: 1
.
cm_ctl: start cluster successfully.
[Ruby@gs01 cm_agent]$ 18.查看集群状态,发现全部正常。
sql
[Ruby@gs01 cm_agent]$ cm_ctl query -Cvid
[ CMServer State ]
node node_ip instance state
---------------------------------------------------------------------
1 gs01 192.168.3.60 1 /data/cluster/cmserver/cm_server Primary
[ Cluster State ]
cluster_state : Normal
redistributing : No
balanced : Yes
current_az : AZ_ALL
[ Datanode State ]
node node_ip instance state
-------------------------------------------------------------------------------
1 gs01 192.168.3.60 6001 /data/cluster/master/datanode1 P Primary Normal
[Ruby@gs01 cm_agent]$