Apache SeaTunnel(原名 Waterdrop)是一款高性能、分布式的开源数据集成平台,主打海量数据的同步、ETL 处理等场景,能解决多数据源兼容、同步场景复杂等行业痛点,目前已成为 Apache 顶级项目,被近百家企业应用于生产环境。以下从核心能力、集成相关特性、典型集成场景等方面详细介绍。
官网:https://seatunnel.incubator.apache.org/

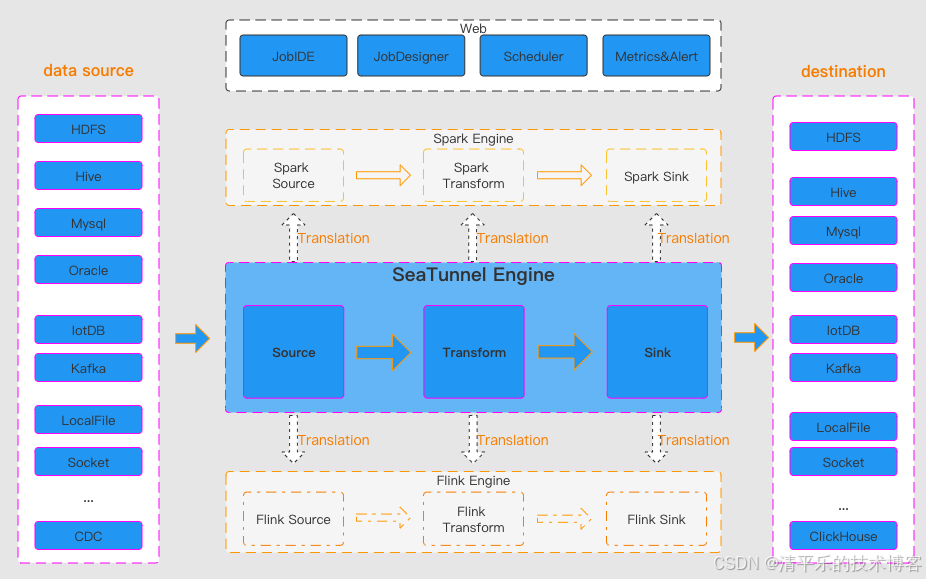
一、核心集成基础能力
1、超丰富连接器,覆盖多类数据源
这是其核心集成优势,目前支持超 100 个连接器且数量持续增加,能对接各类主流数据存储和中间件。包括关系型数据库(MySQL、PostgreSQL、Oracle 等)、非关系型数据库(Elasticsearch、MongoDB 等)、分布式文件系统(HDFS、S3、OSS 等)、消息队列(Kafka、Pulsar 等),还支持常见 SaaS 服务的数据读写,可满足绝大多数企业的跨存储数据集成需求。
2、多引擎适配,兼容现有技术栈
默认使用自研的 SeaTunnel Zeta 引擎,同时还支持 Flink、Spark 等主流大数据计算引擎作为执行引擎。企业无需重构现有技术架构,可直接将 SeaTunnel 集成到已有的 Flink 或 Spark 集群中,降低集成落地成本。且它对这些引擎的多个版本都提供兼容,避免版本适配问题。
3、批流一体集成,适配多同步场景、
打破了离线与实时同步的开发壁垒,基于其 Connector API 开发的组件可同时兼容离线全量、离线增量、CDC(变更数据捕获)、实时同步、全库同步等多种场景。比如既能完成每日凌晨的 MySQL 全量数据向 Hive 数据仓库的同步,也能实现 Kafka 实时日志向 Elasticsearch 的流式写入,无需为不同场景单独开发集成方案。
二、助力集成落地的关键特性
1、轻量化集成,降低运维成本
无需复杂的集群部署,支持单机和集群两种部署模式,若选择 Zeta 引擎部署,无需依赖 Spark、Flink 等额外大数据组件,大幅减少服务器资源占用。同时提供 YAML 格式的配置文件定义集成任务,无需编写复杂代码,搭配 SeaTunnel Web 的可视化画布,可实现任务的拖拽式开发,运维人员也能快速上手。
2、高适配性与扩展性,应对特殊需求
采用插件化架构,用户可基于其 Connector API 自定义开发 Source(数据源)、Transform(数据转换)、Sink(数据目的地)插件,轻松集成到项目中。比如面对企业内部自研的数据库,可开发专属连接器实现数据集成。此外还支持 JDBC 复用、数据库日志多表解析,解决了多表同步时 JDBC 连接过多、CDC 场景日志重复解析等集成痛点。
3、数据一致性与监控,保障集成可靠
支持分布式快照算法,能实现断点续传,避免数据同步过程中因故障导致的数据丢失或重复,保障集成过程的数据一致性。同时提供完善的实时监控能力,可直观查看同步任务的读写数据量、数据大小、QPS 等指标,便于运维人员及时掌握集成任务状态,排查异常问题。
三、几个典型应用场景
1、数据仓库 / 数据湖集成
将分散在各个业务系统的 MySQL、Oracle 等数据库中的数据,通过 SeaTunnel 抽取、清洗、转换后,统一集成到 Hive、ClickHouse 等数据仓库,或 Iceberg、Hudi 等数据湖,为企业的数据分析和决策提供统一的数据基础。
2、系统迁移中的数据集成
企业进行数据库升级(如 MySQL 升级到 PostgreSQL)、架构调整或云迁移(本地数据迁移到云存储 OSS)时,可通过 SeaTunnel 实现数据的平滑迁移,支持增量同步避免业务中断,保障迁移过程中数据的完整性。
3、实时数据分析链路集成
将业务系统实时产生的订单数据、用户行为日志,经 Kafka 采集后,通过 SeaTunnel 实时同步并转换,写入 Elasticsearch 或 ClickHouse,支撑实时数据看板、用户行为监控等场景的数据分析需求,且高吞吐、低延迟的特性可满足海量实时数据的集成效率要求。