7 Classification
7.1 Motivation
线性回归不适用于分类任务
7.2 逻辑回归 Logistic Regression
先介绍Sigmoid函数:
g(z)=11+e−z,0<g(z)<1g(z)=\frac{1}{1+e^{-z}}, 0<g(z)<1g(z)=1+e−z1,0<g(z)<1
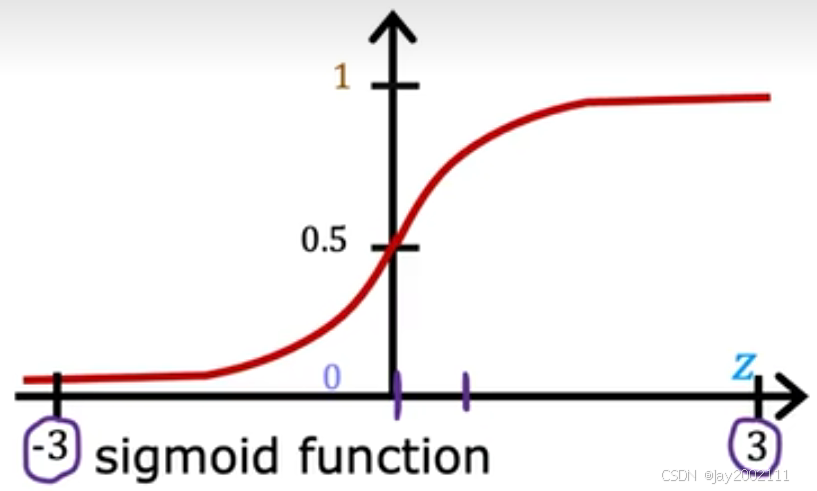
逻辑回归模型公式:
fw⃗,b(x⃗)=g(z⃗)=g(w⃗⋅x⃗+b)=11+e−(w⃗⋅x⃗+b)f_{\vec w, b}(\vec x)=g(\vec z)=g(\vec w \cdot \vec x + b)=\frac {1}{1+e^{-(\vec w \cdot \vec x + b)}}fw ,b(x )=g(z )=g(w ⋅x +b)=1+e−(w ⋅x +b)1
可以将其看做是给定 x⃗\vec xx 的情况下预测值为 1 的概率:
fw⃗,b(x⃗)=P(y=1∣x⃗;w⃗,b)f_{\vec w, b}(\vec x)=P(y=1|\vec x; \vec w, b)fw ,b(x )=P(y=1∣x ;w ,b)
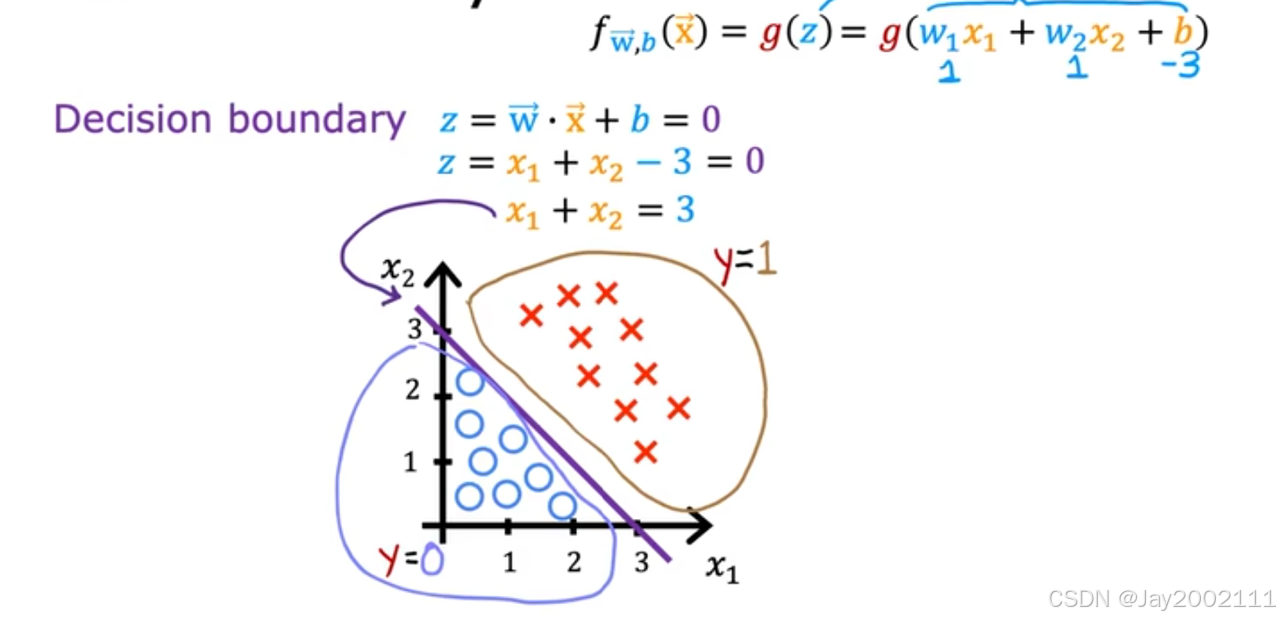
7.3 决策边界 Decision Boundary
直观感受,例如常见把决策边界值设为0.5,即z=0时
线性决策边界:
非线性决策边界,例如多项式:

8 Cost Function
8.1 Cost Function for Logistic Regression
平方误差函数不适用于逻辑回归,成本函数J是非凸函数
定义:
Loss=L(fw⃗,b(x⃗(i)),y(i))J(w⃗,b)=1m∑i=1mLoss=1m∑i=1m12(fw⃗,b(x⃗(i))−y)2,(平方误差)\begin{equation} \begin{split} Loss &= L(f_{\vec w, b}{(\vec x^{(i)})},y^{(i)}) \\ J(\vec w, b) &= \frac{1}{m} \sum_{i=1}^{m}Loss \\ &=\frac{1}{m} \sum_{i=1}^{m}\frac{1}{2}(f_{\vec w, b}{(\vec x^{(i)})}-y)^2, (平方误差) \end{split} \end{equation}LossJ(w ,b)=L(fw ,b(x (i)),y(i))=m1i=1∑mLoss=m1i=1∑m21(fw ,b(x (i))−y)2,(平方误差)
由于fw⃗,b(x⃗)f_{\vec w, b}(\vec x)fw ,b(x )取值范围在0-1之间,那么可以构造另一种Loss函数,使得横轴取值范围在0-1之间时,Loss的变化很大,且当y的正确值为1时,横轴从0到1时Loss递减至0,反之亦然。
考虑取对数:
L(fw⃗,b(x⃗(i)),y(i))={−log(fw⃗,b(x⃗(i)))if y(i)=1−log(1−fw⃗,b(x⃗(i)))if y(i)=0L(f_{\vec w, b}{(\vec x^{(i)})},y^{(i)}) = \begin{cases} -log(f_{\vec w, b}{(\vec x^{(i)})}) &\text{if }y^{(i)}=1 \\ -log(1-f_{\vec w, b}{(\vec x^{(i)})}) &\text{if }y^{(i)}=0 \end{cases}L(fw ,b(x (i)),y(i))={−log(fw ,b(x (i)))−log(1−fw ,b(x (i)))if y(i)=1if y(i)=0
8.2 Simplified Cost Function
将上述Loss转化为统一的形式:
L(fw⃗,b(x⃗(i)),y(i))=−y(i)log(fw⃗,b(x⃗(i)))−(1−y(i))log(1−fw⃗,b(x⃗(i)))L(f_{\vec w, b}{(\vec x^{(i)})},y^{(i)}) = -y^{(i)}log(f_{\vec w, b}{(\vec x^{(i)})})-(1-y^{(i)})log(1-f_{\vec w, b}{(\vec x^{(i)})}) L(fw ,b(x (i)),y(i))=−y(i)log(fw ,b(x (i)))−(1−y(i))log(1−fw ,b(x (i)))
那么成本函数则为:
J(w⃗,b)=1m∑i=1mL(fw⃗,b(x⃗(i)),y(i))=−1m∑i=1my(i)log(fw⃗,b(x⃗(i)))+(1−y(i))log(1−fw⃗,b(x⃗(i)))\begin{equation} \begin{split} J(\vec w, b)&=\frac{1}{m}\sum_{i=1}^{m}L(f_{\vec w, b}{(\vec x^{(i)})},y^{(i)}) \\ &=-\frac{1}{m}\sum_{i=1}^{m}y\^{(i)}log(f_{\\vec w, b}{(\\vec x\^{(i)})})+(1-y\^{(i)})log(1-f_{\\vec w, b}{(\\vec x\^{(i)})}) \end{split} \end{equation}J(w ,b)=m1i=1∑mL(fw ,b(x (i)),y(i))=−m1i=1∑my(i)log(fw ,b(x (i)))+(1−y(i))log(1−fw ,b(x (i)))这个代价函数是通过 最大似然估计 (Maximum Likelihood Estimate, MLE) 得出的
9 Gradient Descent
9.1 Gradient Descent Implementation
前面推算的逻辑回归的成本函数:
J(w⃗,b)=−1m∑i=1my(i)log(fw⃗,b(x⃗(i)))+(1−y(i))log(1−fw⃗,b(x⃗(i)))J(\vec w, b)=-\frac{1}{m}\sum_{i=1}^{m}y\^{(i)}log(f_{\\vec w, b}{(\\vec x\^{(i)})})+(1-y\^{(i)})log(1-f_{\\vec w, b}{(\\vec x\^{(i)})})J(w ,b)=−m1i=1∑my(i)log(fw ,b(x (i)))+(1−y(i))log(1−fw ,b(x (i)))
开始推算梯度下降,一样的公式:
wj=wj−α∂∂wjJ(w⃗,b),(j=1,2,...,n,即n个特征)b=b−α∂∂bJ(w⃗,b)w_j = w_j - \alpha \frac{\partial}{\partial w_j}J(\vec w, b) , (j=1, 2, ...,n,即n个特征)\\ b = b - \alpha \frac{\partial}{\partial b}J(\vec w, b)wj=wj−α∂wj∂J(w ,b),(j=1,2,...,n,即n个特征)b=b−α∂b∂J(w ,b)
有:
∂∂wjJ(w⃗,b)=1m∑i=1mxj(i)(fw⃗,b(x⃗(i))−y(i))∂∂bJ(w⃗,b)=1m∑i=1m(fw⃗,b(x⃗(i))−y(i))\frac{\partial}{\partial w_j}J(\vec w, b) = \frac{1}{m}\sum_{i=1}^{m}x_j\^{(i)}(f_{\\vec w,b}(\\vec x\^{(i)})-y\^{(i)}) \\ \frac{\partial}{\partial b}J(\vec w, b) = \frac{1}{m}\sum_{i=1}^{m}(f_{\vec w,b}(\vec x^{(i)})-y^{(i)})∂wj∂J(w ,b)=m1i=1∑mxj(i)(fw ,b(x (i))−y(i))∂b∂J(w ,b)=m1i=1∑m(fw ,b(x (i))−y(i))
b的没有乘x,看似两个公式和线性回归一样,实则不一样,因为f变了