TL;DR
- 场景:维度多导致 Cuboid 爆炸、构建慢、存储膨胀率飙升。
- 结论:用 Cuboid 剪枝 + Derived 维度;用 CubeStatsReader/GUI核查体积与命中,优先删"永不命中/近似冗余"的 Cuboid。
- 产出:可执行命令、判定阈值与优化思路、版本适配矩阵、常见错误速查卡。

版本矩阵
| 项 | 已验证说明 |
|---|---|
| Apache Kylin 3.x(MR 引擎) | 与示例命令 kylin.sh org.apache.kylin.engine.mr.common.CubeStatsReader <cube> 一致,统计输出含行数/体积/Shrink。 |
| Apache Kylin 4.x(Spark 引擎) | 建议复核统计能力与 GUI 指标一致;类路径/实现可能不同,按官方文档与发行包校对工具入口。 |
| CubeStatsReader 统计 | 是构建后执行,基于抽样/NDV 估算;用于识别"大体积/低 Shrink/少命中"的剪枝对象。 |
| GUI:Cube Size/Expansion Rate | 是Model 页面悬停可见体积与膨胀率;>1000% 优先排查高基数维度、Count Distinct、剪枝缺失。 |
| Derived 维度 | 是用维表主键替代非主键参与预计算,显著减少 Cuboid 数;查询期做一次映射聚合。 |

Cuboid剪枝优化
Cuboid 特指 Kylin 中在某一种维度组合下所计算的所有数据,以减少Cuboid数量为目的的优化统称为Cuboid剪枝。 在没有采取任何优化措施的情况下,Kylin会对每一种维度的组合进行预计算。
- 如果有4个维度,可能最终会有 2^4 = 16个 Cuboid需要计算
- 如果有10个维度,那么没有经过任何优化的Cube就存在2^10 = 1024个Cuboid
- 如果有20个维度,那么Cube中总共会存在2^20 = 1048576个Cuboid 过多的Cuboid数量对构建引擎、存储引擎压力是非常巨大的,因此,在构建维度数量较多的Cube时候,尤其要注意Cube的剪枝优化。
Cube的剪枝优化是一种试图减少额外空间占用的方法,这种方法的前提是不会明显影响查询时间,在做剪枝优化的时候:
- 需要选择跳过那些多余的Cuboid
- 有的Cuboid因为查询样式的原因永远不会被查询到,因此显得多余
- 有的Cuboid的能力和其他Cuboid接近,因此显得多余
Kylin提供了一系列简单的工具来帮助他们完成Cube的剪枝优化。
检查Cuboid数量
ApacheKylin 提供了一个简单的工具,检查Cube中哪些Cuboid最终被预计算了,称这些Cuboid被物化的Cuboid,该工具还能给出每个Cuboid所占空间的估计值。由于该工具需要在对数据进行一定阶段的处理之后才能估算Cuboid的大小,一般来说在Cube构建完毕之后再使用该工具。
使用如下的命令行工具去检查这个Cube中的Cuboid状态:
shell
# 我要查看 wzk_kylin_test_cube_4
kylin.sh org.apache.kylin.engine.mr.common.CubeStatsReader wzk_kylin_test_cube_4执行之后的结果如下图所示: 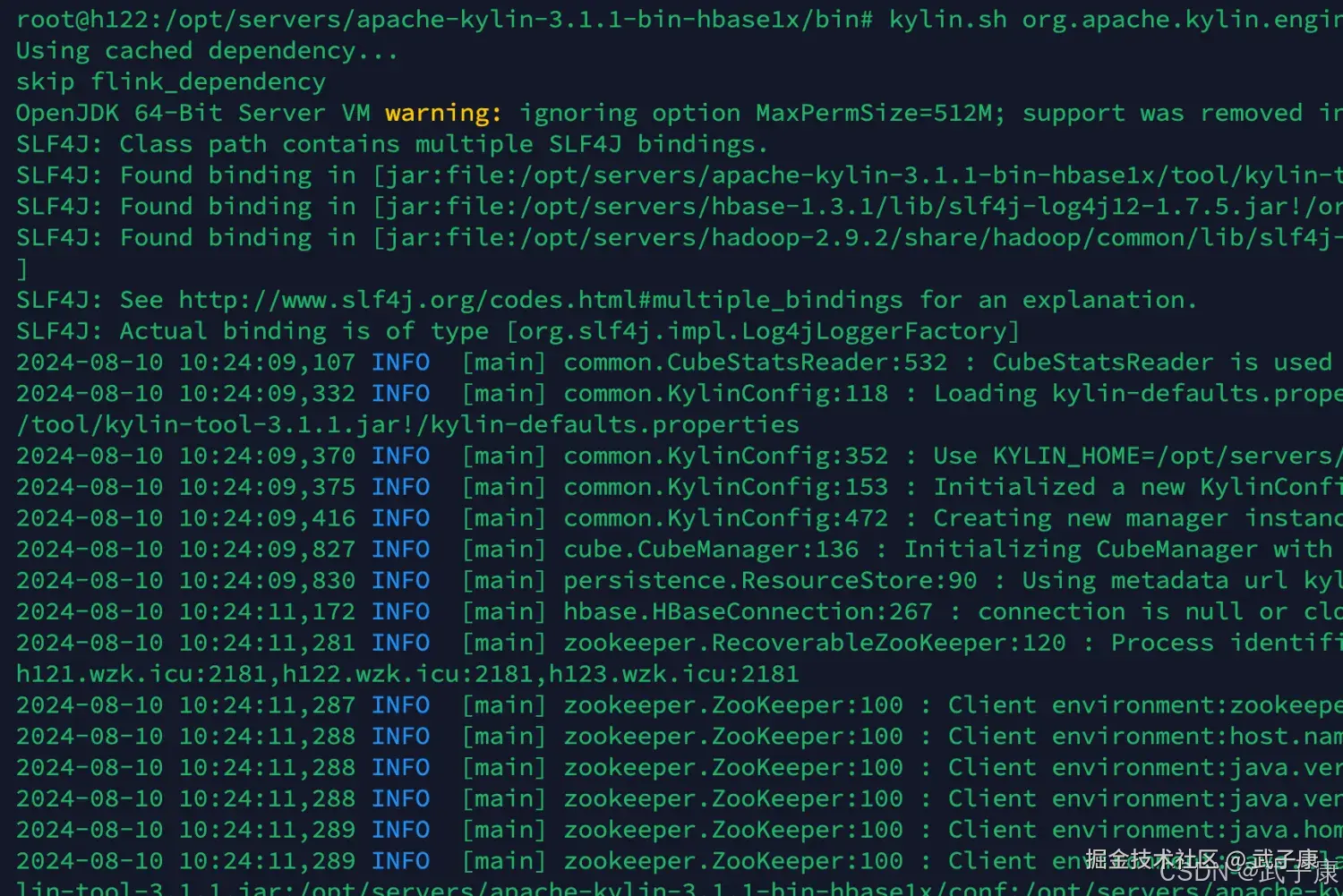
对应的截图如下图: 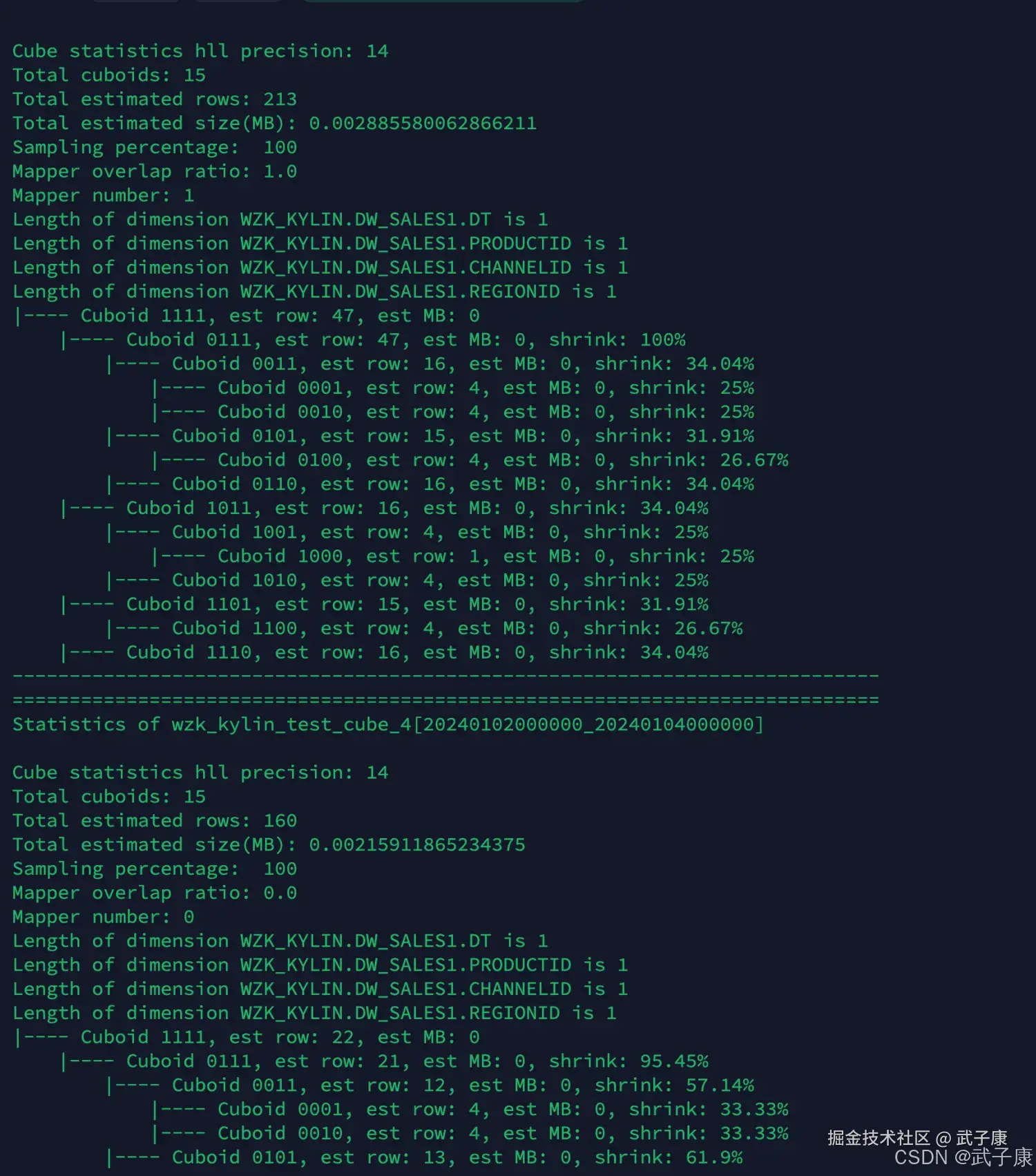
- 估计Cuboid大小的精度(HII Precision)
- 总共的Cuboid数量
- Segment 的总行数估计
- Segment的大小估计,Segment的大小决定Mapper、Reducer的数量、数据分片数量等
- 所有的Cuboid及它的分析结果都以树状的形式打印了出来
- 在这颗树上,每个节点代表一个Cuboid,每个Cuboid都由一连串1和0的数字组成
- 数字串的长度等于有效维护度的数量,从左到右每个数字依次代表RowKeys设置中的各个维度,如果数字为0,则代表这个Cuboid中不存在相应的维度,如果数字为1,则代表这个Cuboid中存在相应的维度
- 除了最顶端的Cuboid之外,每个Cuboid都有一个父亲Cuboid,且都比父亲Cuboid少了一个"1",其意义是这个Cuboid就是由它的父亲节点减少一个维度聚合而来的(上卷)
- 最顶端的Cuboid成为Base Cuboid,它直接由源数据计算而来,Base Cuboid的具体信息,包括该Cuboid的输出中除了0和1的数字串以外,后面还有每个Cuboid的具体信息,包括该Cuboid行数的估计值、该Cuboid大小的估计值,以及这个Cuboid的行数与父亲节点的对比(Shrink值)
- 所有Cuboid行数的估计值之和应该等于Segment的行数估计值,所有Cuboid的大小估计值应该等于该Segment的大小估计值,每个Cuboid都是在它的父亲节点的基础上进一步聚合而成的
检查Cube大小
在WebGUI的Model页面选择一个READ状态为Cube,光标移动到该Cube的CubeSize列时,WebGUI会提示Cube的源数据大小,以及当前Cube的大小除以数据源大小的比例,称为膨胀率(Expansion Rate)。
我们可以在页面上看到Cube的大小信息,如下图所示: 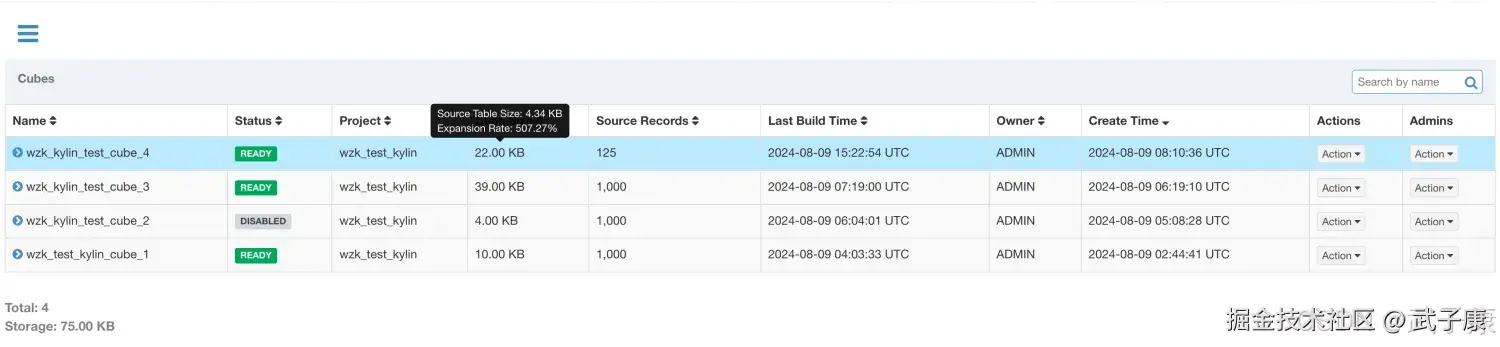 一般来说,Cube的膨胀率应该在0%-1000%之间,如果一个Cube的膨胀率超过1000%,那么应该查找当中的原因,膨胀率高可能有以下几个方面的原因:
一般来说,Cube的膨胀率应该在0%-1000%之间,如果一个Cube的膨胀率超过1000%,那么应该查找当中的原因,膨胀率高可能有以下几个方面的原因:
- Cube中的维度数量较多,且没有进行很好的Cuboid剪枝优化,导致Cuboid数量极多
- Cube中存在较高基数的维度(基数的维度是指维度中有多少个不同的值),导致包含这类维度的每个Cuboid占用的空间都很大,这些Cuboid累积造成整体Cube体积变大。
- 存在占用空间大的度量,例如Count Distinct,因此需要Cuboid的每一行中都为其保存了一个较大度量数据,最坏的情况会导致Cuboid中每一行都有数十KB,从而造成整个Cube的体积变大
对于Cube的膨胀率居高不下的情况,需要结合实际数据进行分析,优化。
使用衍生维度
一个维度可以是普通维度或者衍生维度(Derived) 将维度表的维度设置为衍生维度,这个维度不会参与计算,而是使用维度表的主键(或事实表的外键)来替代它。 Kylin会在底层记录维表主键与其他维度之间的映射关系,以便在查询时能够动态的将维度表的主键翻译成这些非主键维度,并进行实时聚合。 创建Cube的时候,这些维度如果指定为衍生维度,Kylin将会排除这些维度,而是使用维度表的主键来代替它们创建Cuboid,后续查询的时候,再基于主键的聚合结果,在进行一次聚合。 使用衍生角度会有效减少Cube中的Cuboid数量,但在查询的时候会增加聚合的时间。
不适合的场景:
- 如果从维度表主键到某个维度表所需要的聚合工作量非常大,此时作为一个普通的维度表聚合更合适,否则会影响Kylin的查询性能。
案例1-定义衍生维度及对比
基本介绍
有以下时间日期维表: 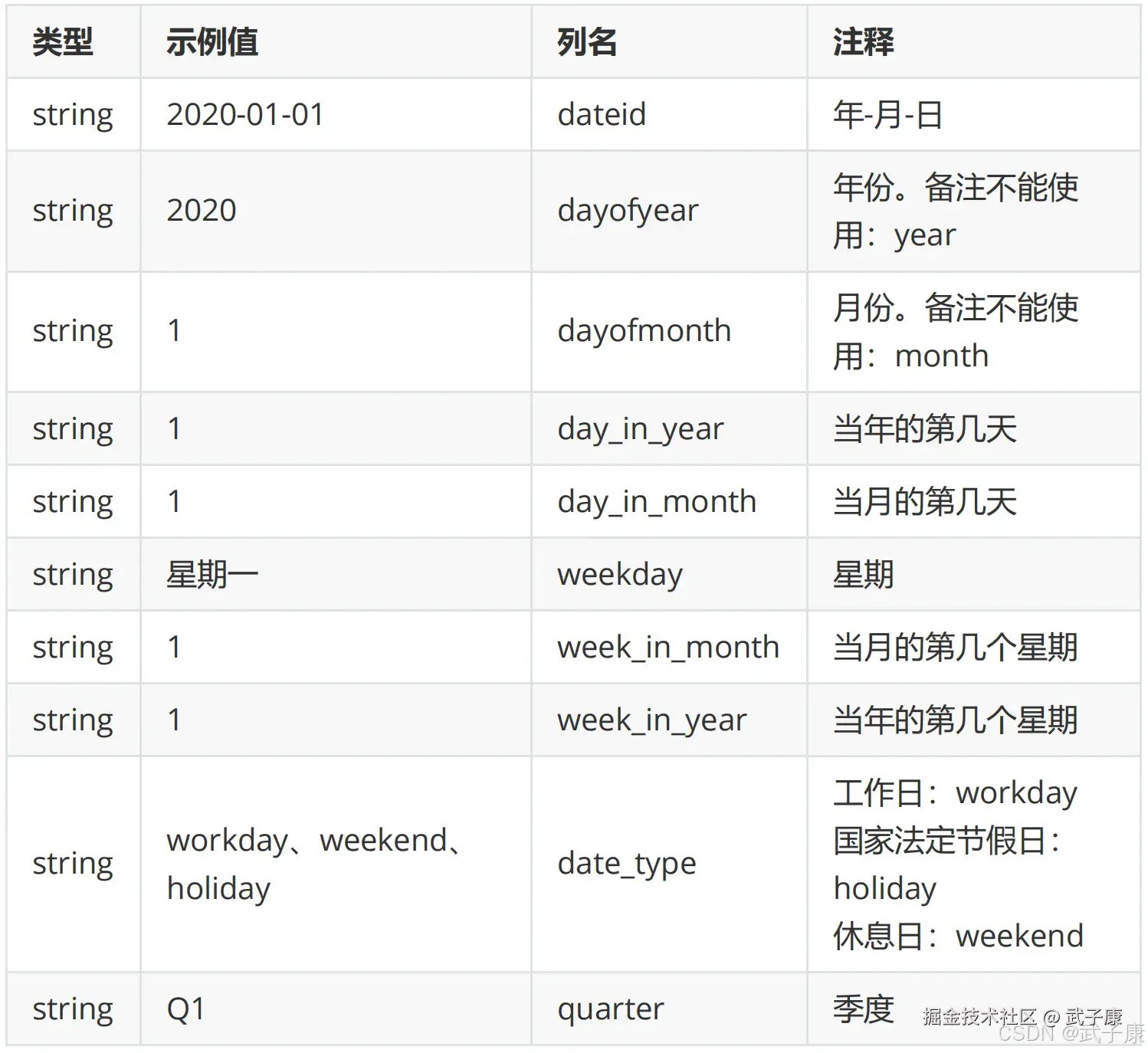
编写 SQL
sql
-- 建表
drop table wzk_kylin.dim_date;
create table wzk_kylin.dim_date(
dateid string,
dayofyear string,
dayofmonth string,
day_in_year string,
day_in_month string,
weekday string,
week_in_month string,
week_in_year string,
date_type string,
quarter string
)ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
-- 加载数据
LOAD DATA LOCAL INPATH 'dim_date.txt' OVERWRITE
INTO TABLE wzk_kylin.dim_date;备注信息: 日期维度代表 dim_date中两个字段,dayofyear、dayofmonth、不能是year、month。
测试数据
dim_date里,少放几条数据(机器太弱了跑不动):
shell
2024-01-01,2024,01,001,01,1,1,01,workday,Q1
2024-01-02,2024,01,002,02,2,1,01,workday,Q1
2024-01-03,2024,01,003,03,3,1,01,workday,Q1
2024-01-04,2024,01,004,04,4,1,01,workday,Q1上传数据
shell
cd /opt/wzk/kylin_test
vim dim_date.txt写入如下的数据: 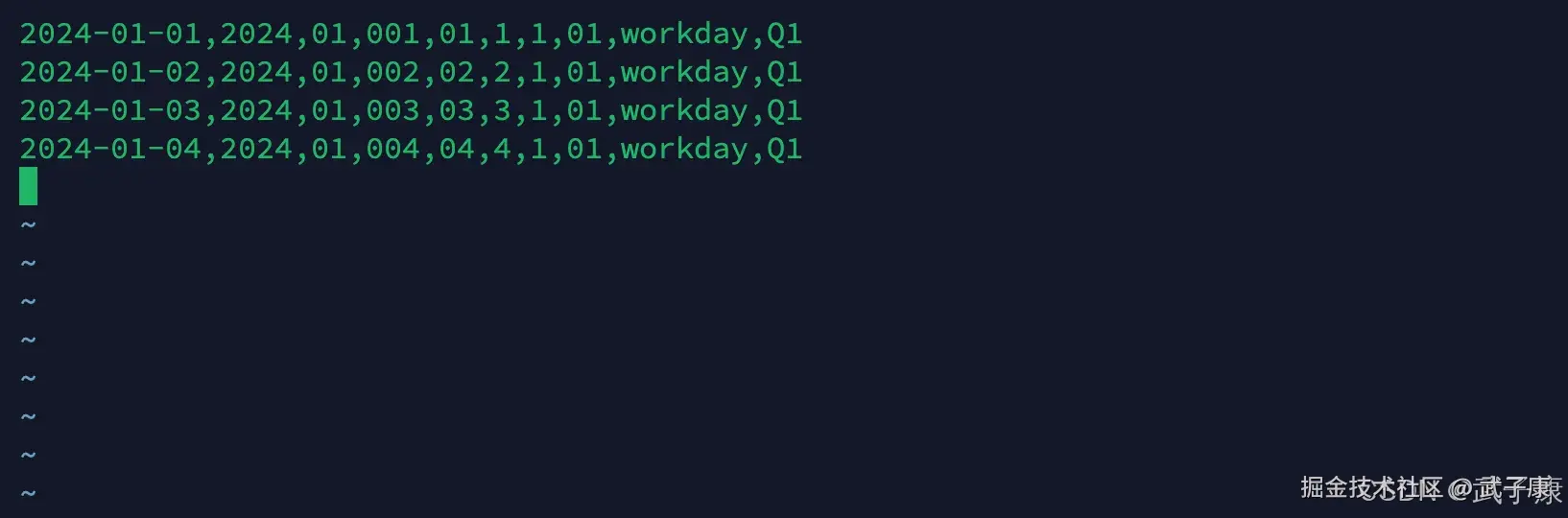
shell
cd /opt/wzk/kylin_test
vim dim_date.sql写入的数据如下图所示: 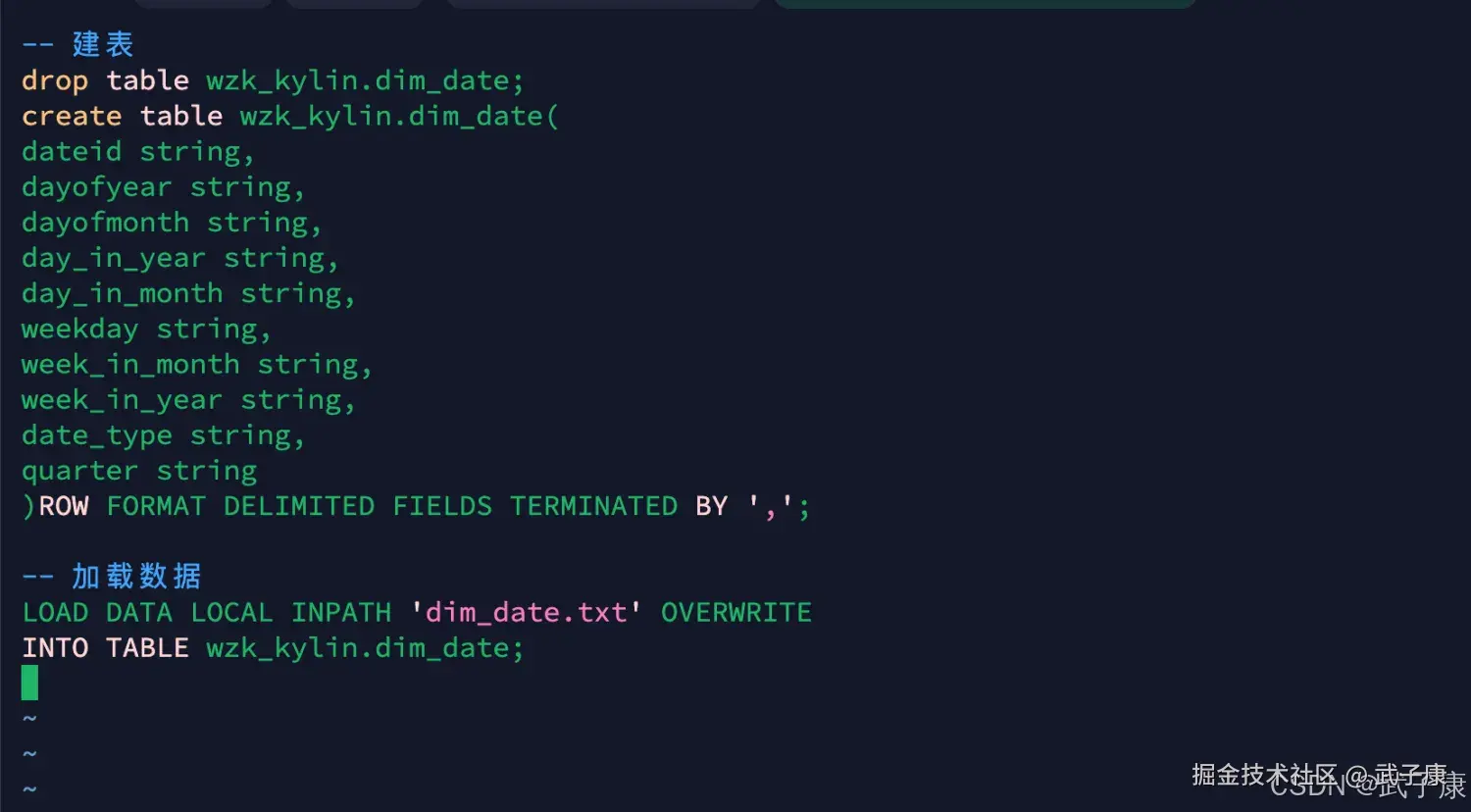 执行如下的脚本:
执行如下的脚本:
shell
cd /opt/wzk/kylin_test
hive -f dim_date.sql执行结果如下图所示: 
Cube设计
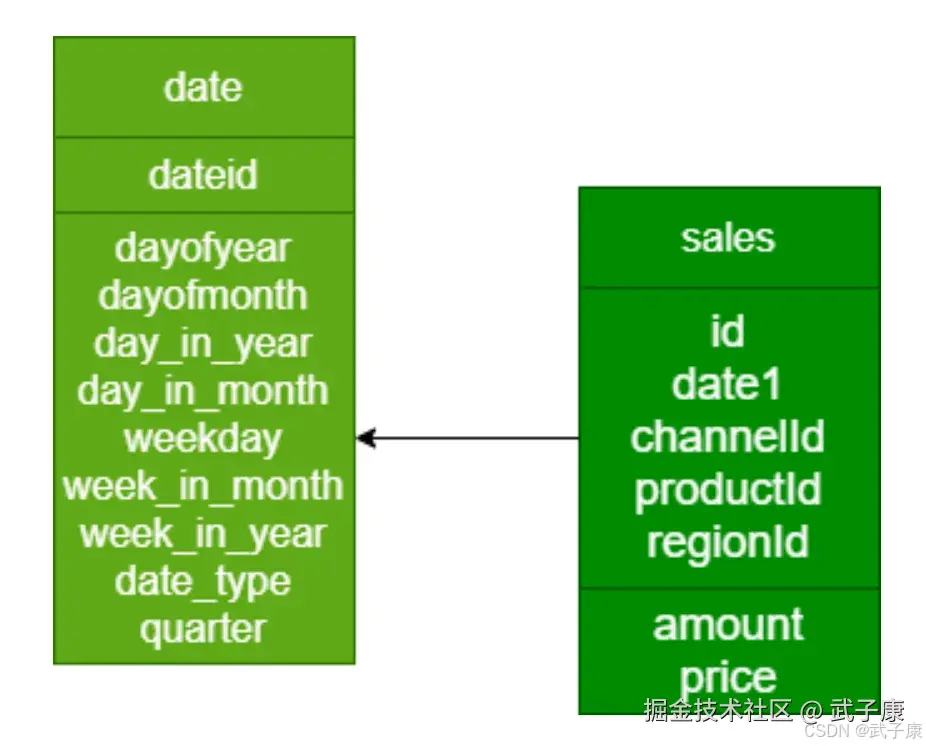 对应的SQL:
对应的SQL:
sql
select dim_date.dayofyear, sum(price)
from lagou_kylin.dw_sales join lagou_kylin.dim_date on
dw_sales.date1 = dim_date.dateid
group by dim_date.dayofyear;基本的执行流程如: 创建项目 - 指定数据源 - 定义Model- 定义Cube - 查询
加载数据源
之前已经操作过很多次了,这里就简单一些写了,添加日期维度表:  创建Model,wzk_test_model_5,选择如下的连表关系:
创建Model,wzk_test_model_5,选择如下的连表关系: 
维度按照按照如下图的配置进行:  度量还是按原来的:
度量还是按原来的:  剩下的部分默认即可。
剩下的部分默认即可。
构建Cube
我们分别构建刚才创建的两个Cube: 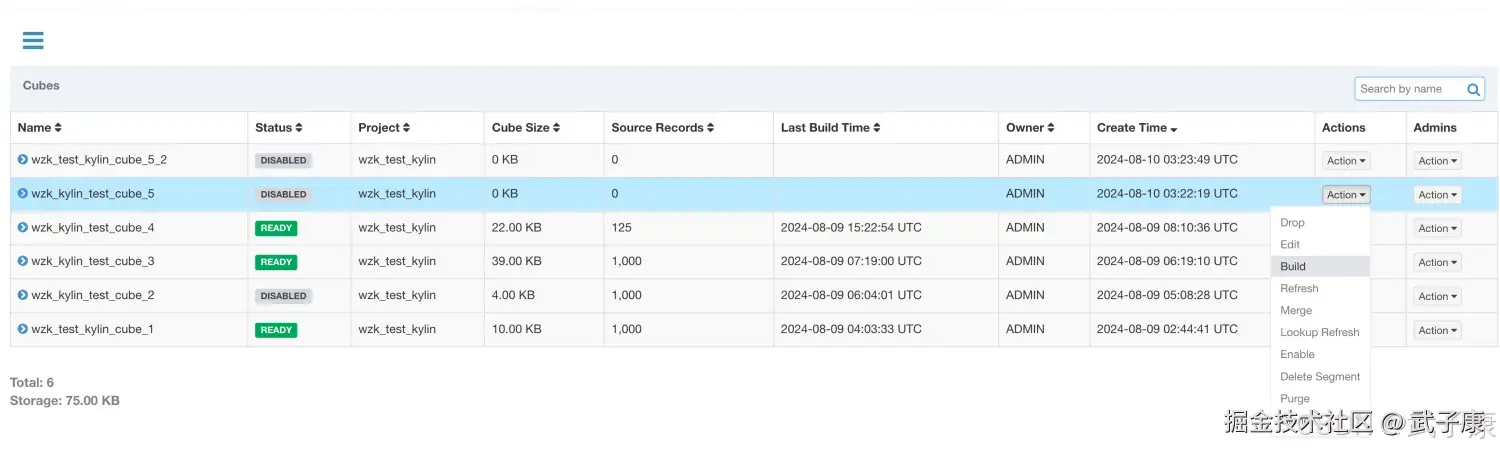
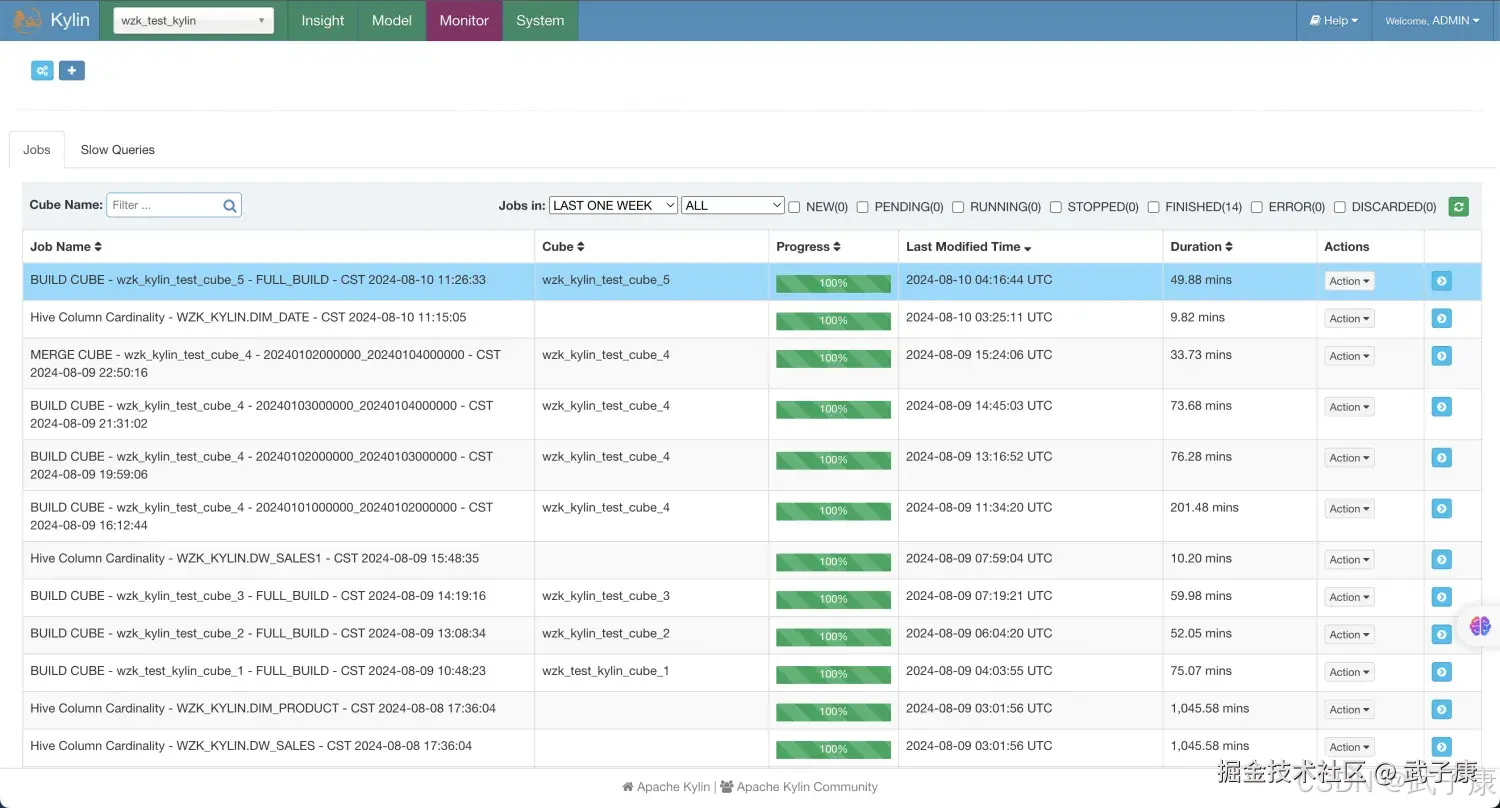
构建结果
构建的结果如下图所示:
wzk_test_kylin_cube_5
wzk_test_kylin_cube_5_2
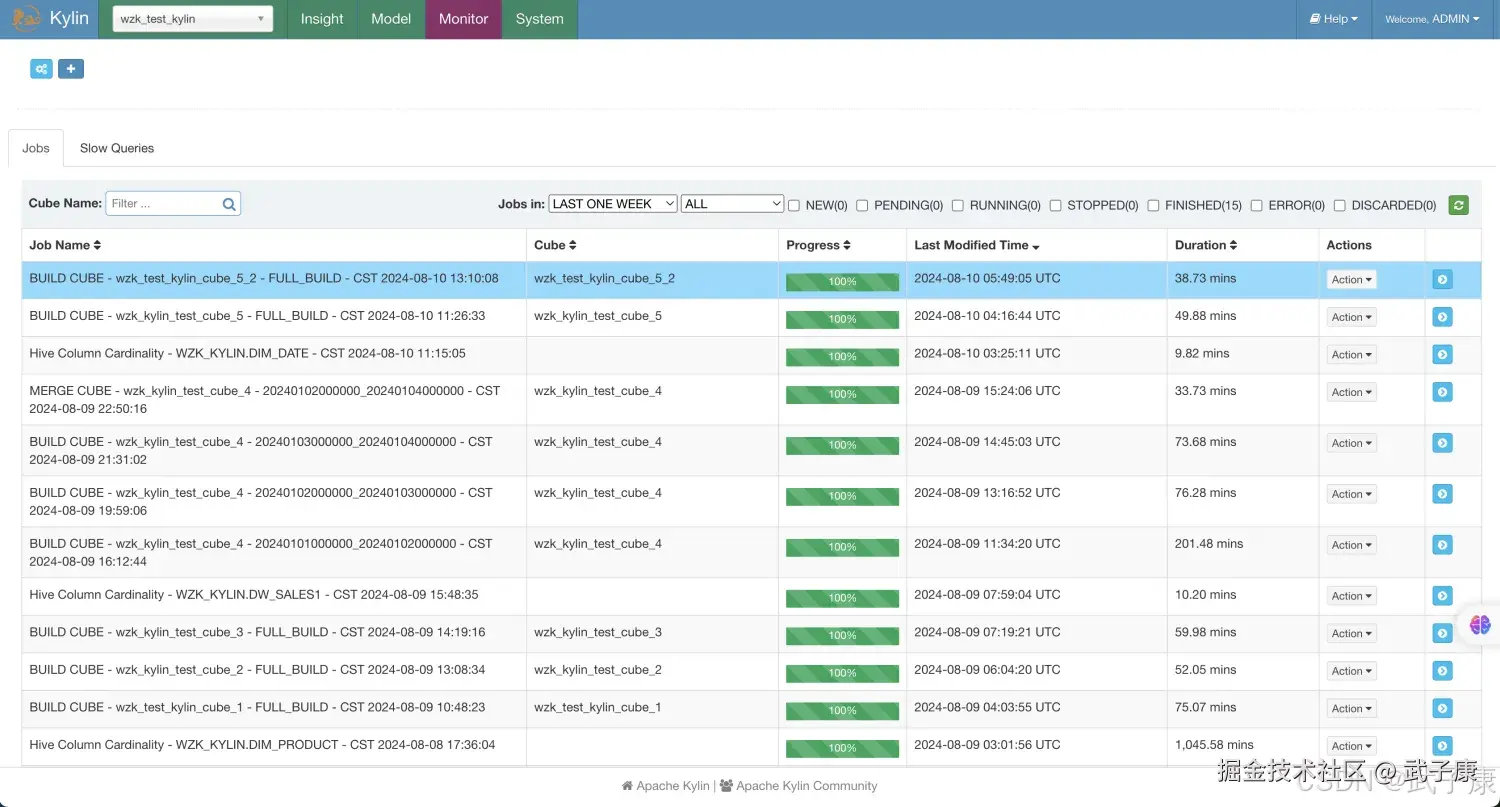
检查Cube的Cuboid数量
我们刚才创建了两个Cube如下图所示: 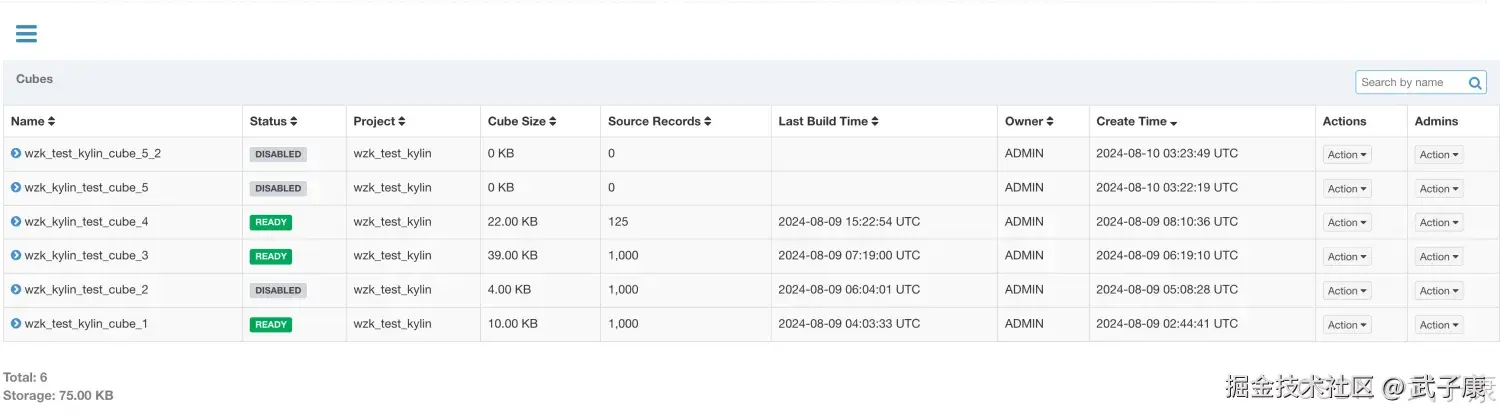
wzk_test_kylin_cube_5
查看 wzk_test_kylin_cube_5:
shell
kylin.sh org.apache.kylin.engine.mr.common.CubeStatsReader wzk_kylin_test_cube_5对应的截图如下所示: 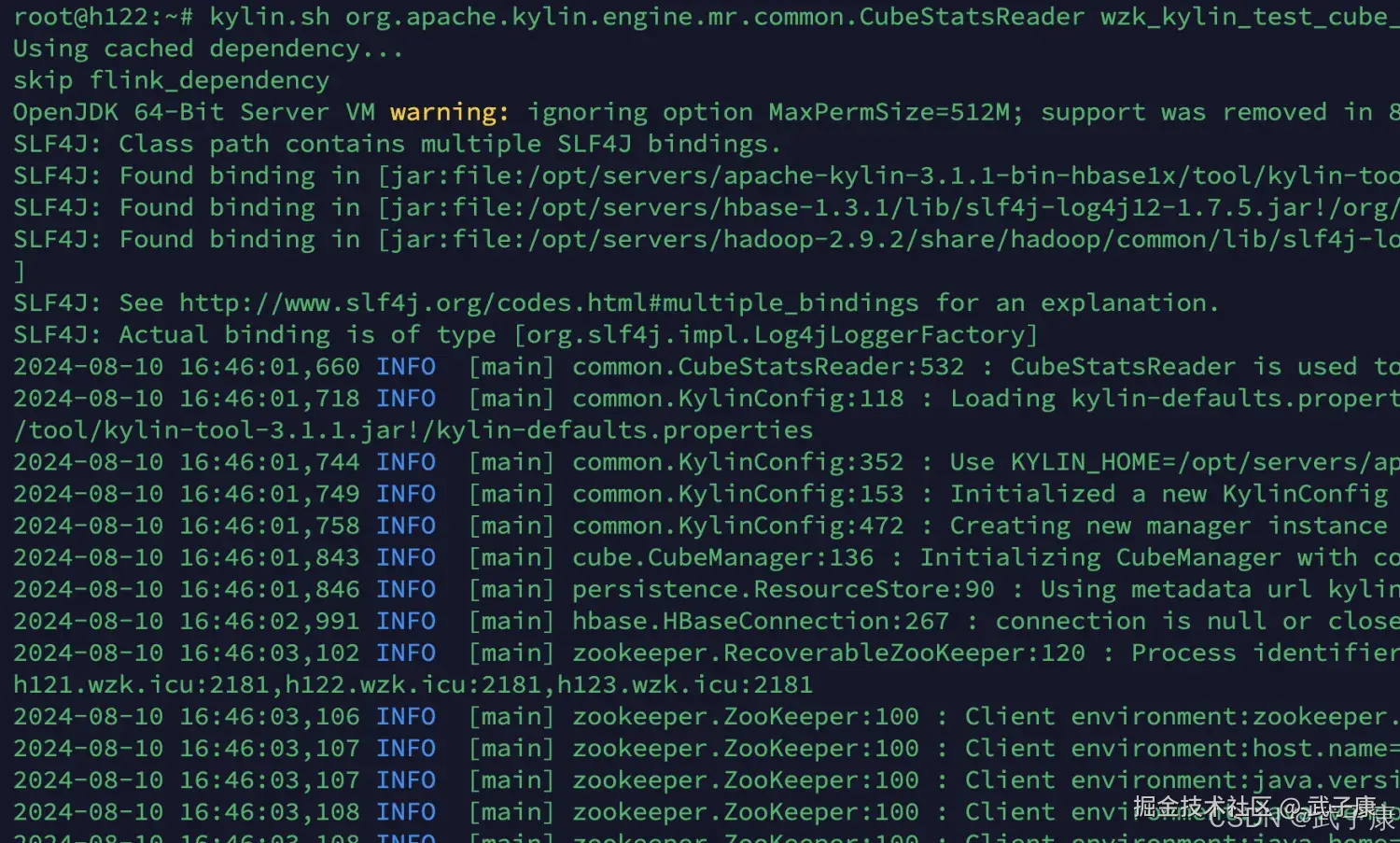
wzk_test_kylin_cube_5_2
查看 wzk_test_kylin_cube_5_2:
shell
kylin.sh org.apache.kylin.engine.mr.common.CubeStatsReader wzk_test_kylin_cube_5_2查询结果如下: 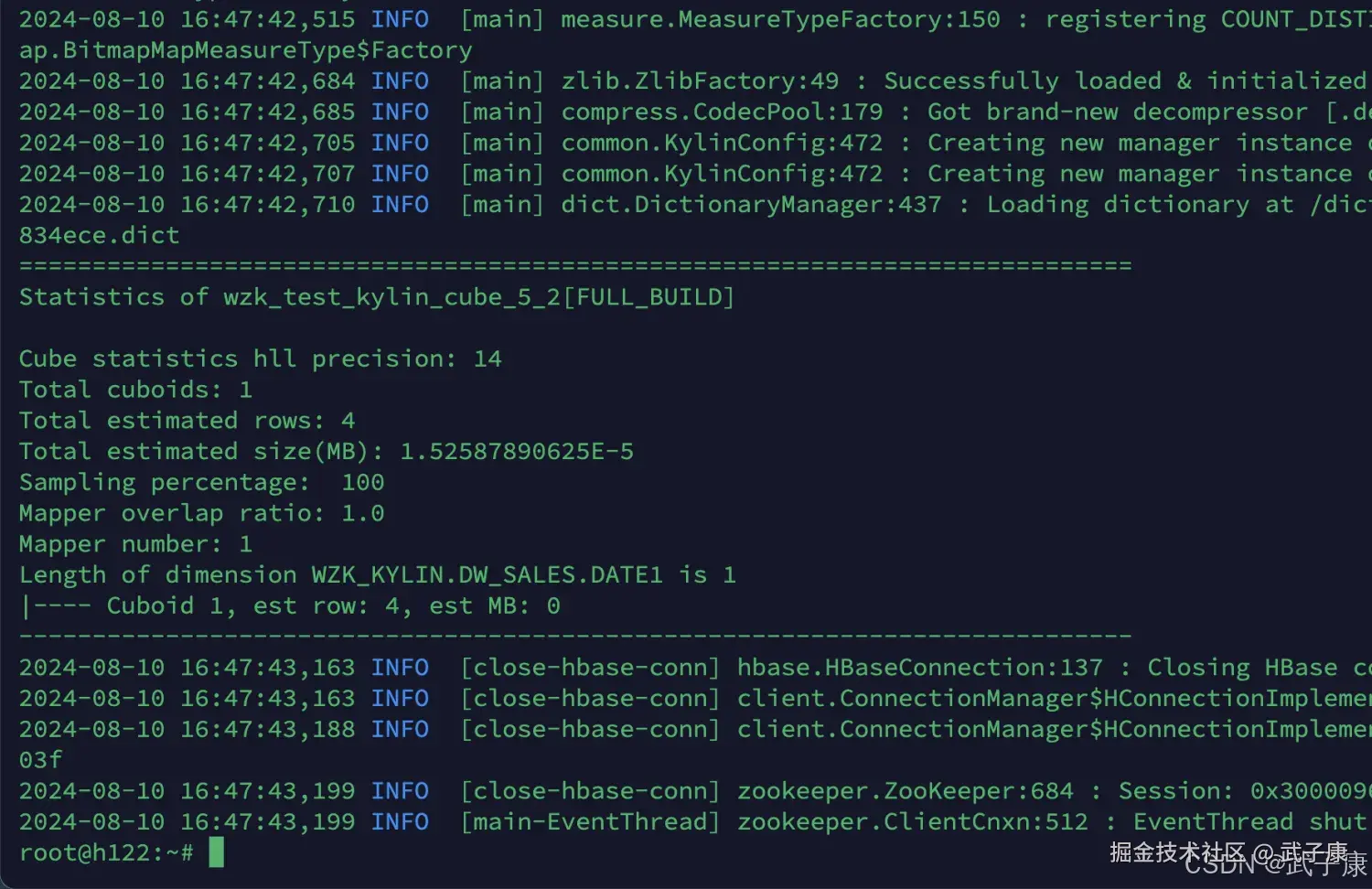
错误速查
| 症状 | 根因定位 | 修复 |
|---|---|---|
| 膨胀率 > 1000% | Cuboid 过多/高基数维度/重度 Count Distinct | GUI 体积与膨胀率;StatsReader 体积/行数分布禁用不命中/近似冗余 Cuboid;将高基数改为更高层聚合或 Bitmap/Dict 优化;评估度量替代方案 |
| 构建极慢/失败(超时或 OOM) | 维度组合爆炸、资源与切分不匹配 | 构建 Job 日志;Segment 大小与 Mapper/Reducer 数强剪枝;拆小 Segment;调优并行度与内存;增量构建 |
| StatsReader 无输出/类找不到 | 工具类路径与版本不匹配 | 在 $KYLIN_HOME 执行;校验发行包中的类名使用对应版本工具入口;确认 MR/Spark 引擎依赖齐全 |
| 查询变慢(启用 Derived 后) | 查询端二次聚合成本上升 | 查询计划/Profile;命中统计高频维度改回普通维度;仅对低命中维度用 Derived |
| 某些 Cuboid 从不命中 | 设计与查询模式不符 | 查询日志/命中统计在 Cube 设计中禁用该组合;保留少量关键下钻路径 |
| Segment 体积估算偏差大 | 抽样/NDV(HLL)精度不足 | StatsReader 精度字段与估算比对提高采样/精度;重跑统计;用实际查询反馈迭代剪枝 |
| 关联后结果异常/空 | 维表键未对齐/数据未加载全 | 核对 join key 与维表唯一性清洗维表主键;补齐字典/快照;重建 Segment |
| Count Distinct 体积畸大 | 度量实现占用高 | StatsReader 单 Cuboid 体积排行替换为近似去重或分层预聚合;限制参与的维度组合 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-127 Qwen2.5-Omni 深解:Thinker-Talker 双核、TMRoPE 与流式语音
💻 Java篇持续更新中(长期更新)
Java-174 FastFDS 从单机到分布式文件存储:实战与架构取舍 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 正在更新,深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解