开篇闲聊
大半夜的,刚处理完一个MySQL的慢查询,手里这杯速溶咖啡都凉透了。
我就在想,咱们做运维的,最怕的是什么?不是服务器宕机,宕机了反而干脆,直接重启或者切备机。最怕的是那种"慢"。业务说卡,老板说卡,你上去一看,CPU利用率像过山车一样,一会儿100%一会儿5%,内存波澜不惊,日志里也是静悄悄的。
这时候你用的如果是Zabbix,默认30秒或者1分钟抓一次数据,大概率你看到的都是"正常"。为啥?因为故障往往就发生在那个间隙里,那几秒钟的IO风暴,Zabbix这种"老实人"根本抓不住。
这时候你就需要Netdata了。这玩意儿默认1秒抓一次数据,就算是一闪而过的毛刺,在它眼里也跟慢动作回放似的。
但是!Netdata有个最大的毛病:单机版太爽,多机版头疼。
你装一台爽一台,装十台,你就得开十个浏览器标签页。要是五十台呢?你是不是得买个那啥,股票交易员用的六联屏显示器?
所以这篇咱们就聊透一件事:怎么把这一堆Netdata汇聚到一个界面上看,也就是所谓的Streaming(流式传输)模式。 别跟我提Netdata Cloud,那是SaaS服务,虽然好用,但咱们很多时候机器在内网,或者因为安全合规(其实就是抠门不想买商业版或者不想数据出境),还得是自己搭建中心节点最靠谱。
搞清楚谁是老大,谁是小弟
逻辑其实特别简单,别被官方文档里那一堆术语吓到了。
你就把这套架构想象成"包工头"和"搬砖工"。
- 搬砖工(Slave/Child):就是你那些干活的业务服务器。它们上面装Netdata,只负责玩命采集数据,采集完了自己不存(或者少存),直接打包扔给包工头。
- 包工头(Master/Parent):这是一台专门的监控服务器。它负责接收所有搬砖工扔过来的数据,存盘,展示,报警。
这样搞有个巨大的好处:业务服务器上不用消耗内存去存历史数据了,特别省资源。
第一步:先把地基打好(安装)
现在安装Netdata简直太无脑了。不管你是Master还是Slave,起手式都一样。我不建议你们去搞什么Docker安装,真的,物理机直接装最省事,能读到更多底层硬件信息。
随便找台CentOS或者Ubuntu,一行命令甩进去:
Bash
bash <(curl -Ss https://my-netdata.io/kickstart.sh)
这脚本虽然有点"暴力",但它会自动识别你的系统,把缺的依赖包给你补齐。等个几分钟,看到那个炫酷的ASCII艺术字出来,就是装好了。
记得把防火墙端口放开,默认是19999。要是这都忘了,后面你也别看了,洗洗睡吧。
第二步:搞定"包工头"(Master配置)
重点来了。这块经常有人掉坑里。
我们要生成一个API Key(其实就是个UUID),这玩意儿就像是接头暗号。小弟要给大哥交数据,得先对暗号。
在Master服务器上,用uuidgen命令生成一个:
Bash
uuidgen
e1540a6c-f179-476f-813d-d0c46000eb15假设你生成的是 e1540a6c-f179-476f-813d-d0c46000eb15(我也就随手一打,你自己生成个真的)。
然后去改配置文件。Netdata的配置文件逻辑稍微有点绕,它为了防止你改乱,搞了个edit-config脚本。
Bash
cd /etc/netdata
./edit-config stream.conf进去之后,把那些注释都还得差不多了,我们要加上这一段:
Ini, TOML
[e1540a6c-f179-476f-813d-d0c46000eb15]
enabled = yes
default history = 3600
default memory mode = dbengine
health enabled by default = auto
allow from = *解释两句:
[UUID]:就是刚才生成的那个。default memory mode = dbengine:这个很关键!以前Netdata存数据吃内存吃到你怀疑人生,现在用了dbengine,它是把数据压缩存硬盘里,内存只留索引,几百台机器的监控数据,几个G内存就能扛得住。allow from = *:允许所有IP推数据过来。如果你为了安全,可以写具体的IP段,比如192.168.1.*。
改完保存。顺手重启一下:systemctl restart netdata。
第三步:调教"搬砖工"(Slave配置)
现在回到你的业务服务器(Slave)上。
同样的,去改stream.conf:
Bash
cd /etc/netdata
./edit-config stream.conf这次我们要改的是 [stream] 部分:
Ini, TOML
[stream]
enabled = yes
destination = 192.168.198.133:19999
api key = e1540a6c-f179-476f-813d-d0c46000eb15
timeout seconds = 60
default port = 19999
send charts matching = *
buffer size bytes = 1048576
reconnect delay seconds = 5
initial clock resync iterations = 60这里有个坑要注意!
一定要把Slave本机的存储关掉,不然你这所谓的"流式传输"就没意义了,两头存数据不是浪费吗?
打开 netdata.conf:
Bash
./edit-config netdata.conf找到 [global] 区块,把 memory mode 改成 none:
Ini, TOML
[global]
memory mode = none
# 既然不存数据,web模式也可以根据情况关掉,或者留着看实时也行重启Slave上的Netdata。
见证奇迹的时刻
这时候,你打开浏览器,访问Master那台机器的IP http://192.168.198.133:19999/。
左上角,看到那个菜单了吗?点开它。
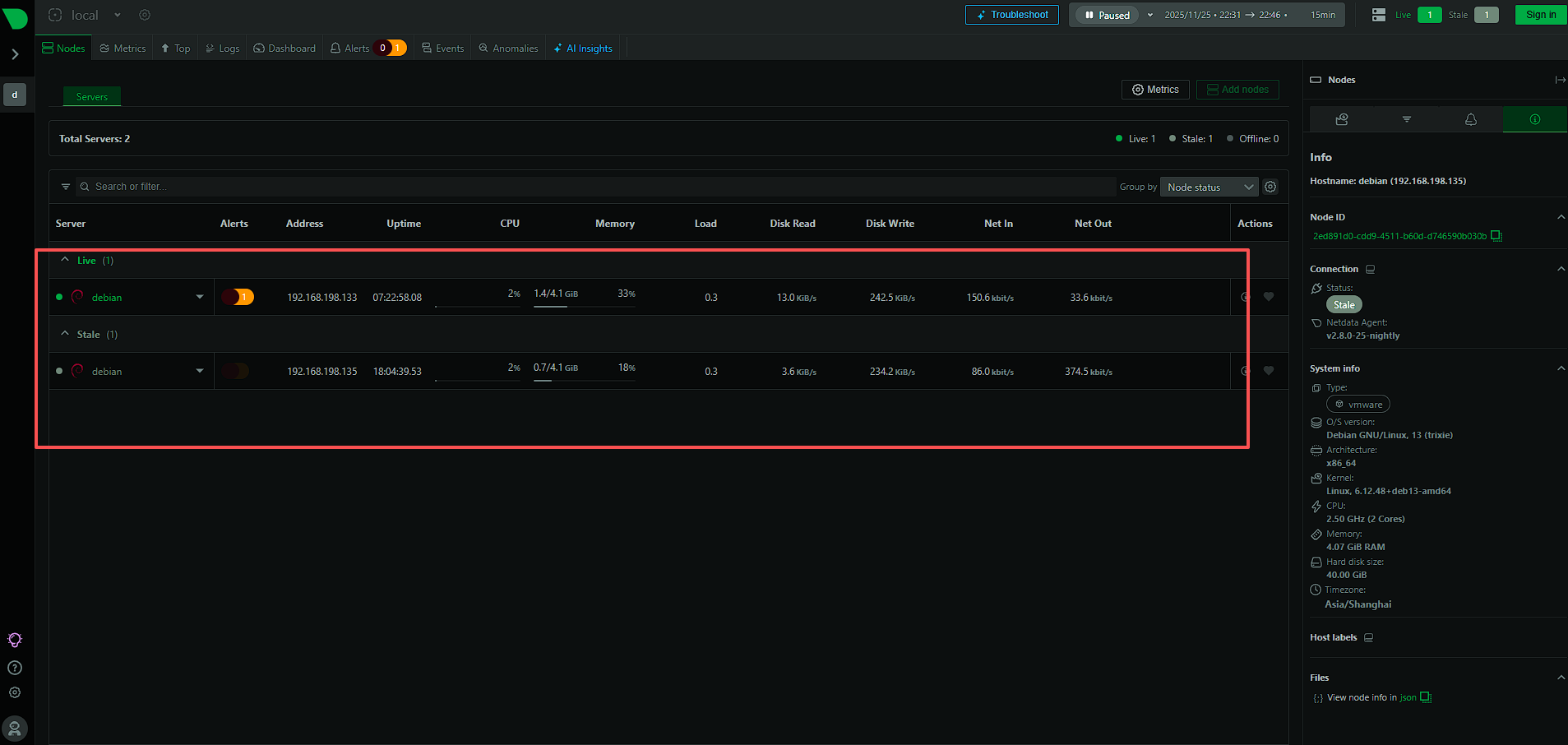
如果不出意外,你应该能看到一个下拉列表,里面除了Master自己,还多出来了你的Slave机器的主机名!
点哪台,界面就切到哪台。所有的数据都在这一个页面里,不用切浏览器标签了。
你要是配置了50台,这里就列50个。
而且,因为我们Master端用了 dbengine,你可以轻松回溯过去一周甚至一个月的数据(取决于你Master硬盘有多大),再也不是那个"重启之后啥都没了"的Netdata了。
登录后信息更全
进阶玩法:报警怎么搞?
光看着爽没用,咱们也不能24小时盯着屏幕看心电图啊。
Netdata的报警其实非常强大,自带了成吨的模板。什么MySQL连接数爆了,磁盘IO卡死了,它都知道。
但是默认它是发邮件,这年头谁还天天盯着邮件看报警啊?必须得对接钉钉、飞书或者企业微信。
这块得改 health_alarm_notify.conf。
Netdata自带了脚本支持很多国外工具(Slack, Discord),国内的稍微麻烦点,我一般的做法是写个简单的Python脚本或者Shell脚本,在这个配置文件里指定 custom_sender。
比如在 health_alarm_notify.conf 里:
Bash
SEND_DISCORD="NO"
SEND_SLACK="NO"
# ... 把没用的都关了
# 开启自定义
SEND_CUSTOM="YES"然后去修改 /usr/libexec/netdata/plugins.d/alarm-notify.sh 里面的 custom_sender() 函数。
这块稍微需要点代码底子。但我告诉你个偷懒的方法:直接把Master的数据推给Prometheus,用Alertmanager去报警。
哎?怎么又绕回Prometheus了?
别急,这是两码事。
Netdata做采集(秒级,精度高,无死角),Prometheus做存储和报警(生态好,现有工具链成熟)。
Netdata原生支持把数据 export 到Prometheus。这样你既有了Netdata那个无敌的实时Dashboard用来排查突发故障,又有了Prometheus的长久存储和成熟的报警机制。这就是所谓的"成年人我全都要"。
遇到过的那些坑
这几年用下来,也不是没栽过跟头。
-
时间不同步:
Slave和Master的时间如果差太多,数据会推不过去,或者看着像断了一样。一定要搞NTP同步,这是运维的基本修养,别问我怎么知道的,问就是都是泪。
-
UUID冲突:
别以为没人这么干。直接克隆虚拟机,把Netdata装好的镜像到处拷。结果几台机器公用一个Machine ID,Master端直接懵圈,数据在那左右互搏。克隆完了记得重置一下Netdata的ID。
-
资源消耗:
虽说Netdata轻量,但如果你开了几百个插件(什么Apache, Nginx, PHP-FPM, MySQL, Redis, MongoDB全开),在那种1核1G的"乞丐版"云主机上,还是稍微有点吃力的。
你可以去 edit-config 里把没用的插件给禁了。比如这台机器根本没装Postgres,你就把Postgres的采集插件关了,省点是点。
写在最后
其实没有什么工具是万能的。
Zabbix胜在稳定,老牌,适合看宏观的、天级别的趋势,适合做资产管理。
Prometheus胜在灵活性,云原生标配,K8s里离了它不行。
而Netdata,它就是那个拿着显微镜的特种兵。
当线上出现诡异的卡顿,所有常规监控都显示"正常"的时候,Netdata往往能救你一命。它能告诉你,刚才那1秒钟,硬盘的写入队列长度是不是突然飙到了1000,或者是不是有个进程偷偷吃光了SWAP。
把多台服务器聚合起来,只是第一步。当你真正看懂了Netdata图表里那些花花绿绿的线条代表的底层含义------比如软中断(softirq)突然变高意味着什么,Context Switches(上下文切换)暴涨又是谁的锅------那时候,你才算真正摸到了Linux内核的门槛。
监控这东西,配置好了只是开始,看懂数据才是核心竞争力。
行了,这杯咖啡彻底喝不出味了。
我也得去检查一下我那个Master节点的磁盘空间了,别回头日志存满了把监控服务器给搞挂了,那就真是"监控挂了没人报警,因为报警的那个也挂了",这就成笑话了。
如果觉得这篇实战对你有那么一点点启发,或者帮你省了几个切屏的时间,别忘了点赞、转发。我们一起在运维这条路上互相学习,共同进步!
公众号:运维躬行录
个人博客:躬行笔记