作者:尝君
背景
在云原生架构普及的背景下,容器化显著提升了应用交付效率和资源利用率,但也带来了运维挑战。由于容器对底层系统的抽象,内存可见性降低,导致高负载下出现的内存占用过高、抖动甚至服务退化等问题难以及时发现和定位。传统依赖人工、日志回溯和逐节点分析的排查方式效率低下,难以应对动态环境;而隐性内存泄漏等长期问题则持续影响稳定性并推高运维成本。
为此,云监控2.0 ** **1 全新打造底层操作系统诊断 ** **2 能力,可实现对主机、容器运行时及应用进程的全栈内存状态一键扫描与统一分析。该方案无需侵入业务,即可快速识别异常模式,显著提升问题发现与根因定位效率。
业务痛点解析
隐式内存占用指业务运行中间接产生的系统内存消耗,未体现在应用进程的常规指标(如 RSS/PSS)中,因而难以被监控或业务感知。尽管不表现为"显式"使用,却真实占用物理内存。由于缺乏有效暴露与归因机制,这类内存往往在系统层面持续累积,最终导致可用内存下降、频繁回收甚至 OOM。在高负载、高并发或复杂云原生架构中,该问题尤为突出,严重影响服务延迟、调度效率与系统稳定性。因此,亟需结合内核级追踪与全栈关联分析,实现从"看到内存用量"到"理解内存成因"的跃迁,提升可观测性与资源治理精度。
痛点 1:文件缓存(filecache)高
filecache 用来提升文件访问性能,并且理论上可以在内存不足时被回收,但高 filecache 在生产环境中也引发了诸多问题:
- filecache 回收时,直接影响业务响应时间(RT),在高并发环境中,这种延时尤为显著,可能导致用户体验急剧下降。例如,在电商网站的高峰购物时段,filecache 的回收延时可能会引起用户购物和付款卡顿,直接影响用户体验。
- 在 Kubernetes(k8s)环境中,workingset 包含活跃的文件缓存,如果这些活跃缓存过高,会直接影响 K8s 的调度决策,导致容器无法被高效调度到合适的节点,从而影响应用的可用性和整体的资源利用率。
痛点 2:SReclaimable 高
SReclaimable 是内核维护的可回收缓存,虽不计入用户进程内存统计,但受应用行为(如频繁文件操作、临时文件创建/删除)显著影响。尽管系统可在内存压力下回收它,但回收过程涉及复杂的锁竞争与同步,常引发较高的 CPU 开销和延迟抖动。SReclaimable 长期高位会占用大量物理内存,却因监控通常只关注进程 RSS 或容器内存而被忽视,造成内存压力误判。
因此,应将 SReclaimable 纳入关键内存指标,结合应用行为与内核观测,实现精准归因与动态管控,防范其对系统稳定性的潜在威胁。
痛点 3:memory group 残留
cgroup 与 namespace 是容器运行时的核心机制。在高频调度场景(如大规模微服务或批处理系统)中,若清理不及时或内核释放延迟,易引发 cgroup 泄漏------即无关联进程的 cgroup 目录未被回收。这不仅占用内核内存,还会引起内存统计误差,导致监控异常、延时抖动等问题。
因此,保障 cgroup 生命周期闭环,结合内核监控与主动巡检,及时清理残留实例,是高密度容器环境稳定性治理的关键。
痛点 4:内存不足,却找不到去哪儿了
当系统内存紧张时,常规工具(如 top)难以揭示真实内存去向------它们无法观测内核驱动(如 GPU、网卡、RDMA)直接分配的内存。在 AI 训练等高性能场景中,GPU 驱动会大量申请 memory、DMA buffer 等系统内存用于显存映射与通信,但这些关键开销对用户"不可见"。运维人员只能看到 MemAvailable 骤降甚至耗尽,却无法定位具体任务、机制或判断是否存在泄漏。
这种可观测性盲区严重拖慢排障效率,可能导致服务中断或训练失败。更糟的是,根因不明易使同类问题反复发生,引发故障蔓延,威胁系统稳定性。
解决方案:用 SysOM 诊断隐式内存
方案介绍
在四种隐式内存占用场景中,文件缓存(page cache)过高最为常见。以该场景为例,核心问题是:哪些进程在读写哪些文件,导致缓存堆积?
解答的关键在于实现从内存页(page)到具体文件路径的精准归因。这需深入内核,完成从物理内存到文件语义的映射,主要分两步:
- 由 page 定位 inode:通过 page->mapping 和 index 找到其所属的 address_space 和文件 inode;
- 由 inode 还原文件路径:遍历 dentry 缓存,在挂载命名空间中重建完整路径(如 /data/model/xxx.bin)。
要实现端到端追溯,系统需具备两大能力:全量扫描文件缓存页,以及根据 inode 高效解析对应路径。传统工具仅提供静态统计,缺乏进程-文件-页的动态关联。唯有构建细粒度、可追溯、低开销的全链路归因机制,才能回答"谁、读了什么、占了多少",实现高缓存场景下的精准诊断与快速响应。

我们也调研分析了多种方案的优缺点:
| 方案 | 优点 | 缺点 |
|---|---|---|
| 驱动模块(ko) | 实现简单 | 侵入性强,存在宕机风险,且内核版本繁多,适配难度大 |
| eBPF | 无宕机风险,兼容性好 | 循环能力不足 |
| mincore 系统调用 | 基于系统调用 | 关闭的文件无法扫描 |
| kcore | 具备全量扫描能力 | CPU 消耗大 |
最终我们选择基于 kcore 来解析系统 filecache 对应的文件,但也需要解决几个问题:
-
kcore 读的是 raw 内存,没有数据结构信息。
-
kcore 需要遍历全量内存,在大内存系统下,CPU 消耗大,时间长。
-
需要支持整机和容器级的文件缓存扫描。
方案实施
针对传统 kcore 方案在文件缓存分析中内存依赖强、兼容性差、开销高等问题,我们提出一种基于 eBPF BTF 协同的轻量级解析机制。
核心优势在于:利用内核自带的 BTF 信息,动态获取关键数据结构的字段偏移,实现跨版本、跨发行版的安全内存解析。针对 page cache 物理页离散分布、全量遍历成本高的挑战,使用采样策略------仅需捕获少量活跃的缓存页,即可回溯至对应 inode,解析出文件路径及所属 cgroup。结合 /proc/kpageflags 和 /proc/kpagecgroup 提供的页级属性(如是否为文件页、可回收性、cgroup 归属等),实现物理内存到容器和工作负载的精准归因。
该方案首次在生产环境中实现非侵入、低开销、高精度的文件缓存溯源,突破"看得见总量、看不见来源"的瓶颈,为缓存膨胀与隐性内存占用提供有效诊断手段。
教育行业某客户通过控制台解决内存高问题
K8s 是一个开源的容器编排平台,主要用于自动化部署、扩展和管理容器化应用。它提供一个强大的、灵活的架构来支持大规模的应用服务,从而简化了应用的运维管理,企业在享受 K8s 在容器编排和部署所带来的便利时,同时也面临新的问题。
案例 1:通过 SysOM 分析容器内存工作集高
Kubernetes 采用内存工作集(workingset)来监控和管理容器的内存使用,当容器内存使用量超过了设置的内存限制或者节点出现内存压力时,kubernetes 会根据 workingset 来决定是否驱逐或者杀死容器。
内存工作集计算公式: Workingset = 匿名内存 + active_file。匿名内存一般是程序通过 new/malloc/mmap 方式分配,而 active_file 是进程读写文件引入,程序一般对这类内存使用存在不透明情况,经常容易出问题。客户通过容器监控发现其 K8s 集群中某个 pod 的 Workingset 内存持续走高,无法进一步定位究竟是什么原因导致的 Workingset 内存使用高。
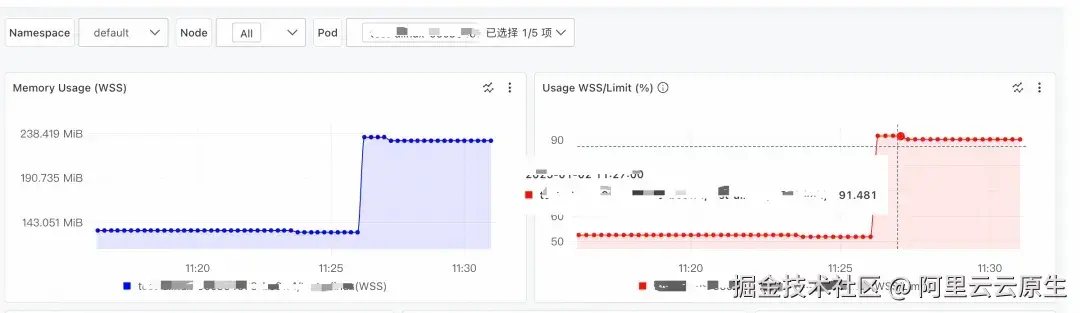
针对上述场景,先找到 Pod 所在的 ECS 节点,通过使用 SysOM 使用内存全景分析诊断,选择目标 ECS 节点后,再选择目标 Pod,发起诊断:
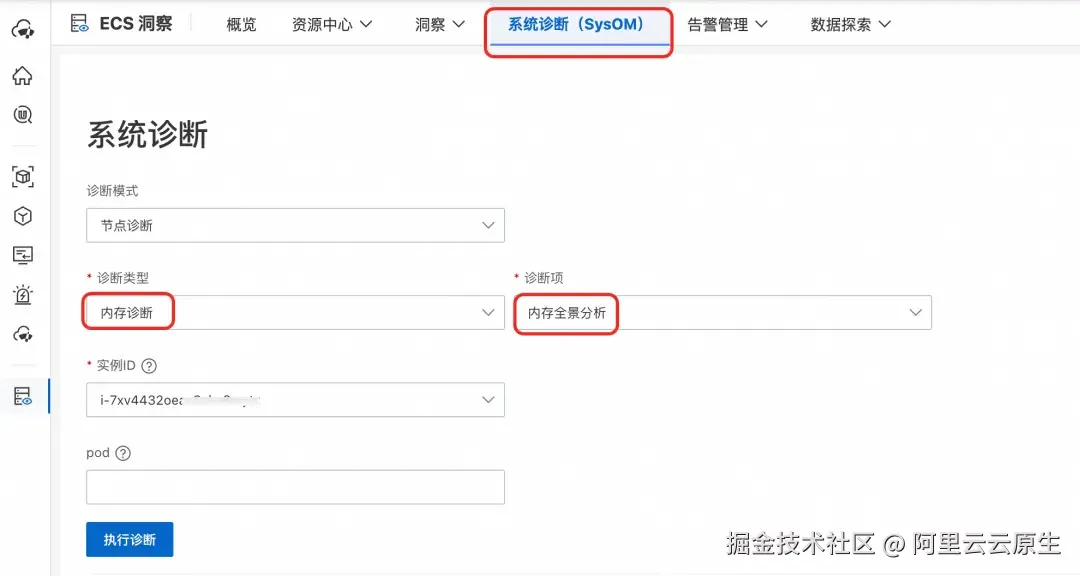
诊断结果如下:
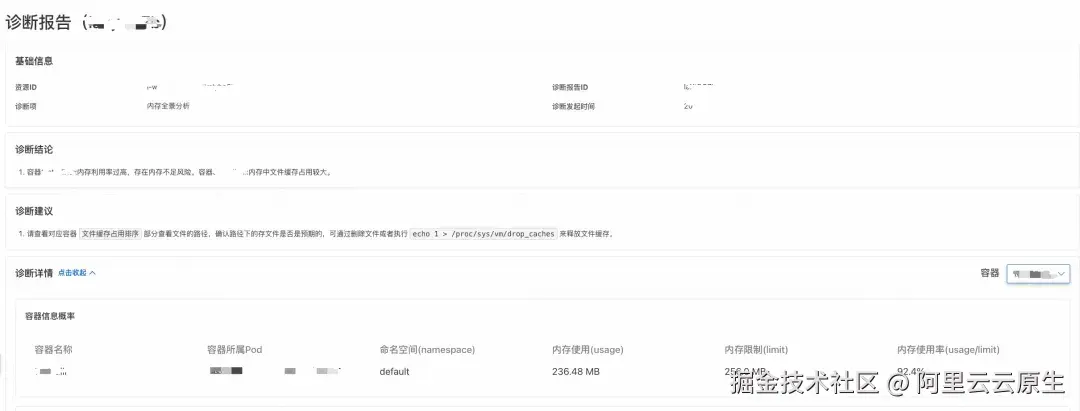
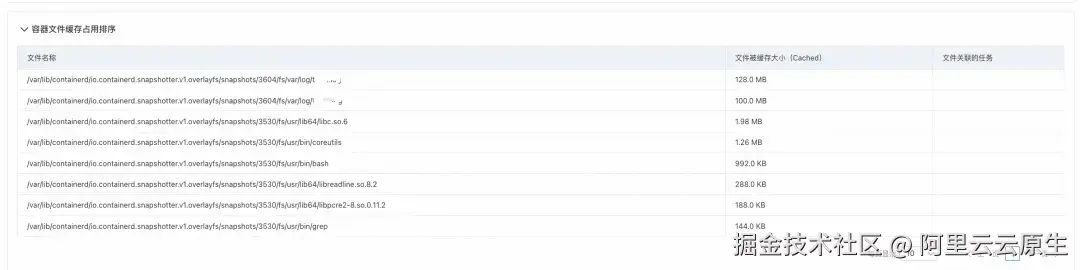
诊断结论明确指出:容器 xxx 内存使用率过高,存在内存不足风险,主要因文件缓存占用较大。
查看文件缓存排序表可见,前两个容器中的日志文件(路径为宿主机映射路径,容器内实际位于 /var/log)共占用约 228MB 缓存,系业务程序读写日志所致。
建议优化日志写入方式或限制缓存增长,避免 WorkingSet 内存过高触发 OOM 或直接内存回收,导致业务延迟。
修复建议:
-
通过手动执行 echo 1 > /proc/sys/vm/drop_caches 来主动释放缓存。
-
如产生文件缓存的文件是非必要文件,可以通过手动删除文件释放缓存。
-
使用 ack 集群的内存 QoS 功能(复制链接至浏览器打开):help.aliyun.com/zh/ack/ack-...
案例 2: 通过SysOM分析共享内存高
某行业客户发现,在运行较久的机器上,通过 free -h 看到的剩余内存较少,buff/cache 比较多,客户通过分析和查阅资料,通过执行 echo 3 > /proc/sys/vm/drop_caches 来主动释放缓存。客户发现,使用该方法可以回收部分缓存,但是仍然还有大量的 cache 占用没有释放:
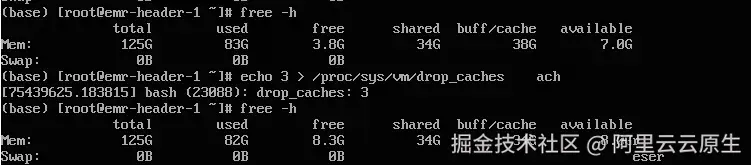
针对上述场景,通过使用 SysOM 对目标 ECS 进行内存全景分析诊断,诊断的结果如下:
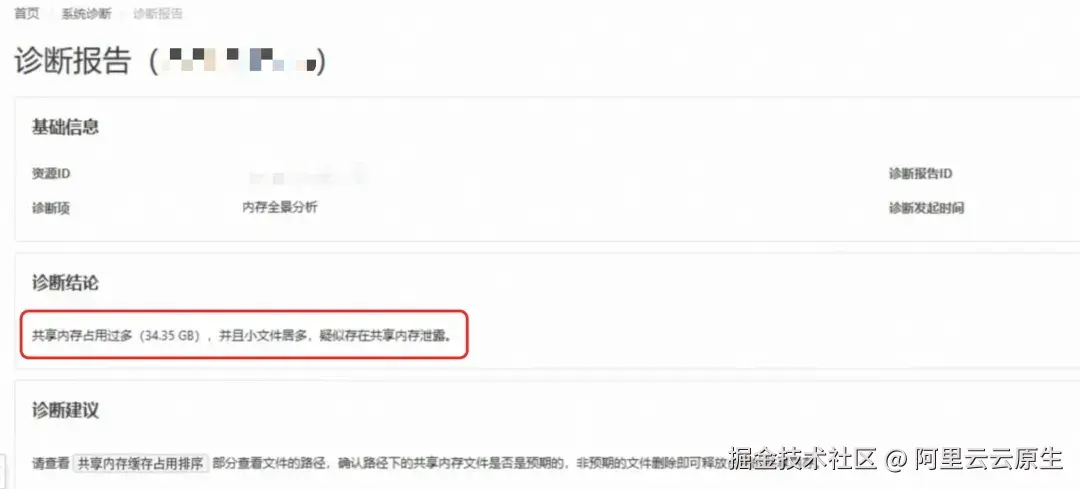

诊断结论明确指出:共享内存占用过高(34.35 GB),且以大量小文件(如 160 KB)为主,疑似存在泄露。从共享内存缓存占用排序表可见,占用最高的前 30 个文件均来自 /dev/shm/ganglia/*,证实了小文件泄漏问题。由此判断,客户业务程序在该目录下创建了共享内存文件但未及时释放。结合业务场景评估后,可直接删除这些文件以释放缓存内存。
内存全景诊断结果说明及详细使用教程可参考:help.aliyun.com/zh/alinux/u...
客户收益
目前操作系统诊断能力 ** **3 能够对高负载、网络延迟抖动、内存泄漏、内存溢出(OOM)、宕机、I/O 流量分析及性能抖动等各种复杂问题进行一键诊断,在保障稳定性的同时最大化资源效率,更重要的是,该能力有效缓解系统资源压力引发的性能抖动------如文件缓存膨胀或内核内存增长触发直接回收甚至 OOM Killer,造成延迟或服务中断。通过及时识别异常占用并释放非必要缓存,可避免 Pod 频繁进入内存回收路径,降低进程阻塞与响应延迟,保障关键业务服务质量。
下一步规划:
我们将持续演进 SysOM 的智能运维能力:融合大模型的泛化理解与小模型的实时推理,构建分层诊断体系,实现异常早期识别、根因推测与处置建议生成;支持跨平台、多环境统一管理,扩展主流 OS 发行版兼容性;深化内核级细粒度监控,填补观测盲区,并集成至告警框架,推动运维从"被动响应"转向"主动防控"。整体推动操作系统从资源管理者向智能运维中枢演进,为关键业务提供更强技术底座。
如果您想了解更多的诊断能力,可参考系统诊断文档。
相关链接:
1 云监控 2.0
account.aliyun.com/login/login...
2 系统诊断
account.aliyun.com/login/login...
3 操作系统诊断能力