SFT
先调 prompt,保证让模型可以按照你想输出的样式先输出。如果怎么调都不行建议换模型,说明能力不行。
正常来说,通过prompt至少有20%以上的答案是正确的,才有SFT成功的可能性。但是,如果prompt不太复杂就能够有不错的效果,prompt不用构造太复杂。模型就可以遵循指令。
可以通过更强大的模型造一些数据,然后,再多个模型对其进行打标,判断产生的QA对是否符合要求这样就可以构造一批高质量的样本。如果有人力的支持,可以进行人工检验,更加保险。
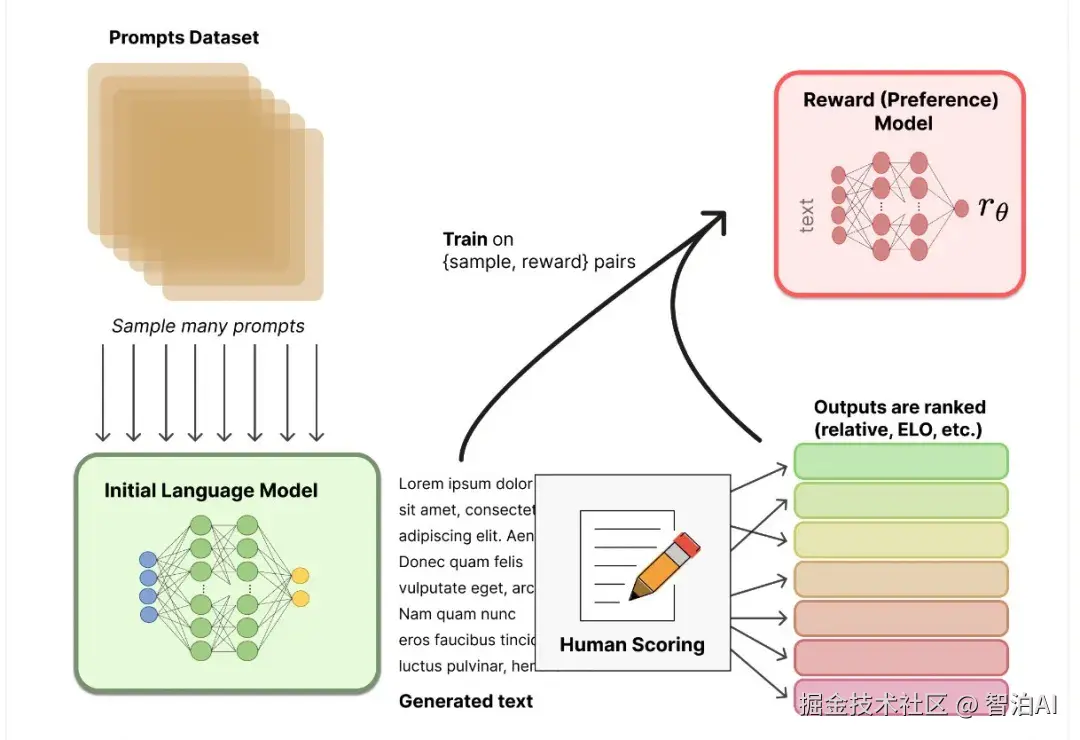
调参的时候,可以对learningrate,weight decay从大往小调,通常lr从1E-4开始,weight decay从0.25开始。
模型越大,肯定是效果越好,在模型很大情况下可以开 ds。
事实上loss,对于大模型训练仅能做一个基本的判断了,基本上,到了中后期,loss小,效果不一定好甚至还会出现loss先下降后上升的情况,即使是在训练集。
所以,正确的判断方法还是,从小步数的checkpoint,进行accuray或者其他业务指标的判断,正常情况,只要模型在正常训练,该指标通常也是下降逐渐到收敛的一个状态。
因此,不能太依赖loss指标,仅仅做初步参考。
数据的多样性非常重要,再三强调,训练集的数据分布一定要包括测试集的数据分布,这样测试集才会有好的效果,所以,当你的测试集效果不好,但是训练集数据还可以的时候,记得去检查测试集有没有类似的数据。
如果没有,ok,手动人工针对性添加数据吧,先5个,10个的先加,再看训练效果数据集的风格一定要统一,输出的答案风格一定要单一。
比如,每次答案都是以ison格式的,确保数据都是"js犢洧锹啇婚 xxx`这种格式。如果sql的答案都是select a,b,c,那么就不要出现select*。保证你数据的统一性,纯洁性是模型不学偏的根本。
思维链+fewshot肯定是可以提高原始模型能力的但是,SFT就不用加思维链和fewshot了,直接用样本堆死它。而且思维链+fewshot也超级耗时啊,标注也是一个超级麻烦的事情。
所以,还不如直接造大量高质量样本,直接让模型学习。暴力但是很有效对于多任务问题,可能有的同学会问到底多少条数据才合理,个人经验,每个垂域400条高质量数据足矣。
可以对数据集设置一个难易程度,让模型先学简单后学难的,有利于模型的加速收敛在小模型上面。
如果纯用某一类数据去SFT,效果可能还会下降,这是因为小模型能力差,泛化能力也差,一旦数据分布相差太大,模型基础能力都gameover了。
解决方式是要不换更大模型,要不增加一些base模型产生的数据。
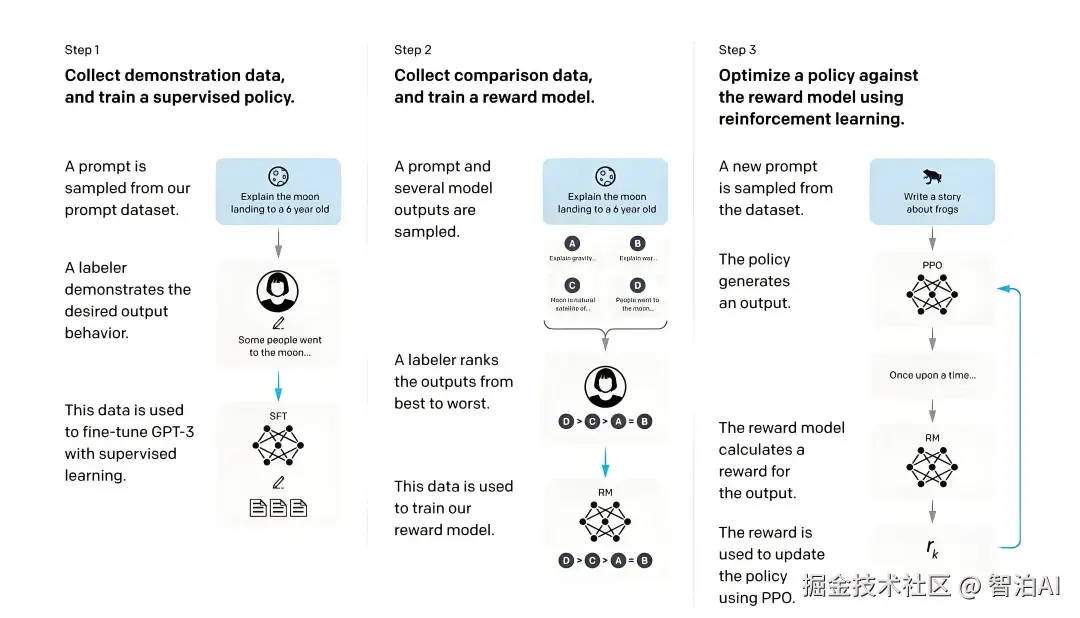
用GRPO训练过的模型去rollout,再选择高分的数据去SFT的效果比纯用原始数据SFT的效果可能会更好。
而且用这个SFT后的模型去再进行RL,效果更佳。但是这个过程不能够重复,因为越到后面,模型产生的答案越单一,其实效果没有那么好。
RL
和 SFT一样,做RL的模型本身就对数据集回答的超级差,可能20%都达不要,那就果断换模型吧。
这里着重说一下,SFT是为了让模型有能力去回答问题,而RL仅仅是将这个能力推到上限。
就和我们打篮球一样,一个经过训练的篮球运动员,在发挥好的时候,可以10中8,但是他可能平时就5中5,而RL做的就是让该运动员长期处在10中8等状态。
但是如果运动员只能10中2,且从来没有10中8,那么他怎么都到不了10中8。

对于reward的设计,对于有明显规则可以作为critic的问题,比如数学或者逻辑问题,RL是有效果的,但是如果没有明显规则,需要用大模型或者other模型打分的问题,可能RL就没有那么大的效果了。
特别是那些非常主观问题的,比如,C罗比梅西伟大吗?
reward的规则一定要考虑完整,且不能太多rewardrule,否则会让模型彻底偏向某个规则,或者直接reward hacking。
比如,对于仅有1个正例或者1个负例的数据集,如果完成正例的回答是很难的,而回答负例是很简单的,且正例数据比负例少,模型就倾向于全部数据都打负例,这样模型依然可以得到高分。
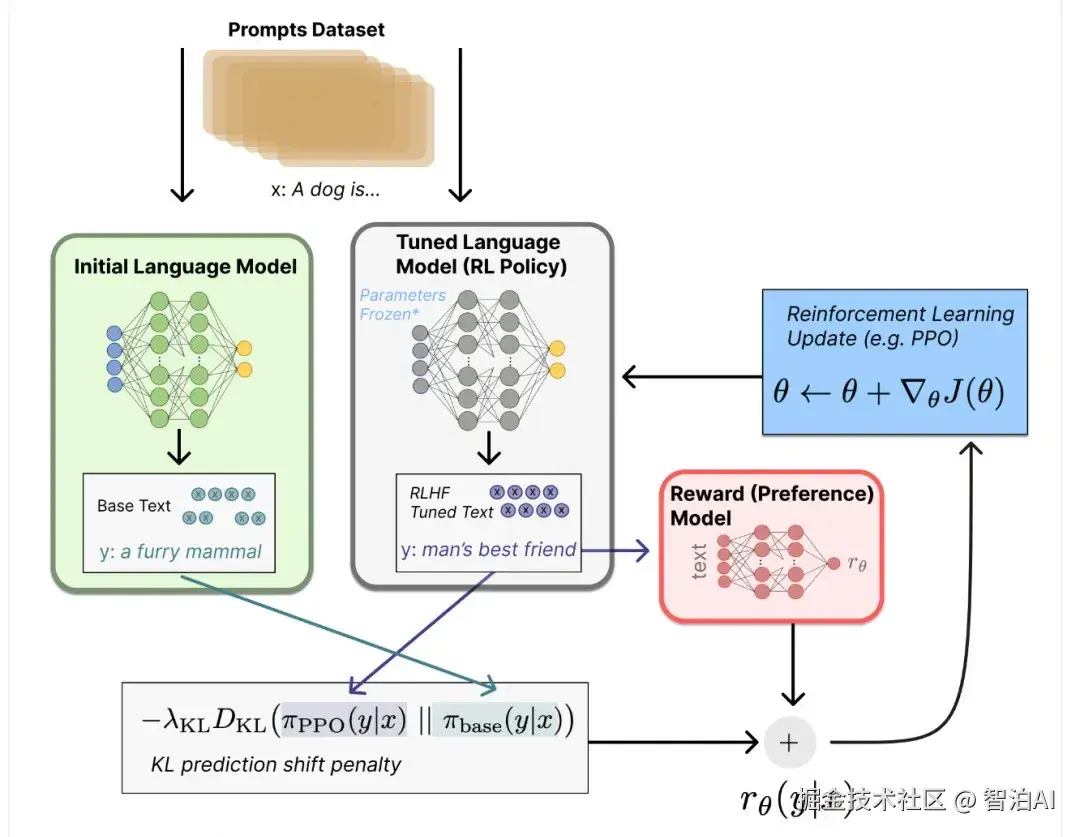
对于没有经过SFT的模型,kl散度可以不用开,因为没有经过SFT的模型产生的数据实际多样性还是有的,不会像SFT那么统一RL训练的模型更应该关注reward是否快速增长到收敛,而不是看loss。
对于有确定性rule reward的数据集,可能纯RL也能起到效果,不用再去SFT。反之,必须SFT,再RL。
如果SFT都没有效果,那么别指望RL了。一定记得取不同训练步骤的checkpoint针对某些问题进行检验,好记性不如烂笔头,看指标终究抵不过bad case的研究。
reward是基石,KL散度是尺度器,reward直接决定了RL能够达到的上限,KL是让模型的生成不要太单一或者太杂乱。通常KL是从小到大调,一般0.001足够了。
如果Base-RL的效果想要更进一步,可以试试用base-RL拒绝采样一批样本,然后对Base模型进行简单的冷启动微调,随后再继续RL。
这就是先挑出reward擒窮助高的样本先微调冷启动一把。
reward始终不上涨,在排除了一切可能的原因后建议用训练前的模型针对一些case rollout出多个回复(n可以大一点),看下这些回复的奖励是不是都特别低。
如果都特别低,那说明基模的能力上限就如此,想要通过探索来提升表现是行不通的,建议换模型或者对 SFT模型进行优化。
当出现训练不稳定(如损失值突然飙升),可启用梯度裁剪,裁剪值一般为 0.2。
PPO的学习率通常需要比SFT小一个数量级。例如,如果SFT阶段的学习率是2e-5,PPO阶段的初始学习率建议设置为1e-6到3e-6之间。
过高的学习率极易导致模式崩溃(Mode Collapse)为防止能力遗忘,可以在RL的prompt池中混入5%-10%的通用SFT数据。
这是一种简单有效的方法,可以在优化特定偏好的同时,通过让模型回顾通用任务来"锚定"其基础能力。
在PPO训练前,务必对RM的输出进行归一化处理。这可以防止因奖励模型打分范围不固定而导致的梯度爆炸或消失,极大提升训练稳定性。
RLHF阶段的batch size宁大勿小。更大的批次可以提供更稳定的梯度估计,尤其对于PPO。如果显存不足,应优先使用Gradient Accumulation来等效扩大批次大小。
在RLHF中可能经常碰到Reward Hacking,解决方案是在奖励函数中加入惩罚项,或者调低某个reward的权重系数,或者将这些作弊样本作为负例,重新训练奖励模型。
Reward持续上升,并且KL散度爆炸式增长,这需要增加KL惩罚项的权重,通常建议从一个较小的值(如0.001)开始,逐步增加。
KL散度很低,奖励几乎不增长或者增长缓慢,KL惩罚太过了,模型被过度束缚,调低系数,同时可以检查下学习率,如果学习率非常低,模型更新步子太小,可能也会导致reward增长缓慢。
模型训练初期就输出大量重复或者无意义的内容,习率过高。过大的学习率可能导致模型参数更新过于剧烈,跳出了有效的参数空间,导致mode collapse。这需要降低学习率。
对于大模型微调,学习率通常设置得非常小,例如 1e-6 到 1e-5 之间。可以从一个保守的值开始尝试。
同时,使用warmup和decay策略通常是个好主意,一般推荐cosine策略。
模型响应的长度变得非常短或非常长,这是因为奖励模型可能存在length bias,需要修正奖励模型:在RM训练数据中加入不同长度的优质样本,消除长度偏见。
或者在RL阶段加入长度惩罚/奖励。reward持续上涨,但人工评估发现生成内容存在事实错误或逻辑混乱,这是因为RM过拟合或偏好数据存在偏差,导致模型学习到"欺骗性策略"。

这时候需要根据你的具体任务,把奖励拆分多个独立维度,分别标注并加权融合。
Critic的 Value Loss波动剧烈,难以收敛,这是因为reward方差过大,导致Critic难以准确估计长期价值,这时候需要对reward或者advantage进行归一化。
策略熵快速下降,生成内容同质化严重,这是因为entropy_coef过低,导致策略过早收敛到局部最优,探索能力不足。
可以增大熵系数:或者采用DAPO的Clip-Higher策略:解耦PPO的clip上下界,放宽低概率token的提升空间,缓解熵崩溃DPO中,模型对 chosen和rejected 的概率差增长缓慢,这是因为 beta 值过高。
DPO中的 beta 参数扮演着类似PPO中KL散度惩罚的角色,它控制着隐式奖励模型的温度。beta 过高意味着策略更新过于保守。可以调低 beta。
降低 beta可以让模型更大胆地学习偏好,拉开 chosen 和 rejected 的差距。DPO中,DPO训练损失下降很快,但生成效果差甚至不如 SFT模型,这是因为beta 值过低 或 学习率过高。
beta 过低导致模型过于激进,偏离SFT模型太远,丢失了通用能力。学习率过高同样会破坏预训练模型的结构。
可以调高 beta:增加对SFT模型的约束。降低学习率:使用更小的学习率(如1e-7到 5e-6)进行微调。
GRPO训练,batch size越大,其实效果越稳定,尤其是模型能力没有那么好的情况下。
更多AI大模型学习视频及资源 ,都在智泊AI。