本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。
" 大模型应用开发,做出来只是开始,做好才是能力。 "
昨天在优化完智能体的记忆功能之后,今天做进一步的测试,然后就发现在多轮对话之后智能体好像变笨了;之前能够回答得很好的问题,现在有点失灵了。
因此,既然产生了问题,那么就要想办法解决问题;正如之前的一位同事的口头禅------需求是合理的,那么就可以做。
智能体优化
今天测试过程中遇到的问题主要有以下几种现象,随着对话轮数的增多,智能体无法准确识别工具并调用,甚至开始使用自身的知识和历史记录进行回答;并且,无法保证知识来源的准确性。
其次,模型调用工具开始变得不准确,无法准确生成调用参数,导致召回结果为空。
再有,随着对话轮数的增多,模型的回答质量越来越差,在你质问它的时候,它也无法解决问题,并且会持续性犯同样的错误。
比如说,在测试的过程中,模型会生成一个明显错误的调用参数,然后你质问它,它会告诉你参数是错的;然后你再问一个同样的问题,它还会用同样的参数。
所以,面对以上这些问题,我们需要想办法去进行优化;但到底应该怎么优化呢?
其实从理论上来说,智能体的优化方案就那几种,最重要的是我们需要找到一个最合适的值。
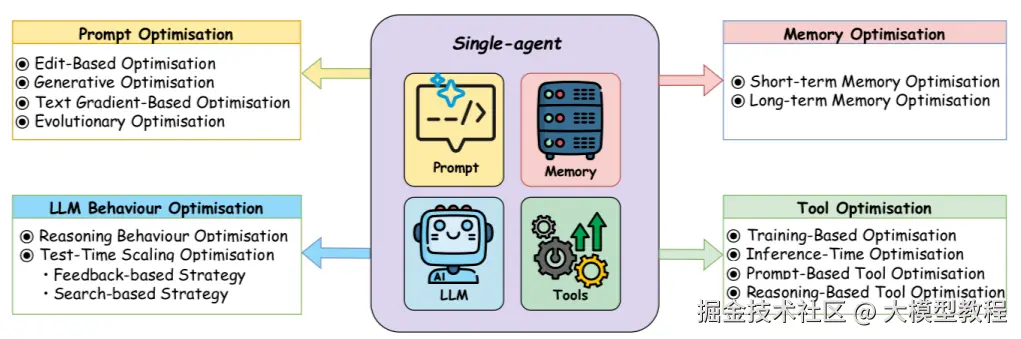
智能体的优化方向主要有以下几个环节:
- 上下文长度
- 历史记录管理
- 提示词的优化
- 工具的优化
上下文长度
上下文长度是影响大模型或者说智能体的稳定性的第一要素,针对不同的环境,不同的模型,不同的上下文窗口,我们需要测试出一个最优的上下文长度,这样才能让智能体尽可能的表现最好。
历史记录管理
历史记录管理是控制模型上下文长度的一个重要手段,而且历史记录的质量也会直接影响到智能体的质量。
在历史记录管理中,我们有两种方式控制历史记录的长度,一种是使用固定长度的token,另一种是使用固定的对话次数,一般情况下维持在六到十轮对话最好。
但历史记录会因为不同的问题,不同的回答,影响其长度和对话轮数;如使用订长的token,那么随着回答长度的增多,对话轮数会变少;而如果使用固定轮数的历史记录,那么随着回答的增多,其长度会变大。
提示词优化
在提示词中,我们不但要明确告诉模型它的工作职责,还要明确告诉模型有哪些工具,每个工具有什么用,在什么情况下需要调用工具,在什么情况下又可以不调用工具等等一系列问题。
工具优化
工具优化分为两个方面,其一是工具的描述,包括功能描述和参数描述;事实上,工具描述从本质上来说,也属于提示词的一部分,因为一个好的工具描述能够明确告诉模型,这个工具有什么用,以及应该怎么用。
其二,是工具中参数验证,比如有些参数可能是枚举类型,这时就需要在描述中把枚举值列举出来;并且对参数进行验证,因为模型虽然会尽可能的按照你的要求生成工具调用参数,但我们无法完全保证其调用参数的准确性。
其次,我们可以在工具中使用一些规则验证和转换,如根据地区查询时,当包含某个关键字或词时,就设置一个默认值;如只要包含浙江,浙江省等就默认是全省。
这样经过以上几种优化方式对智能体进行优化,就能大大提升智能体的质量和稳定性;但具体的效果还需要在不同的环境和业务场景中进行测试。
智能体开发就是一个反复测试,反复实验的过程,这个过程没有捷径。
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。