1、部署
拉取代码,自己编译(不用全量包,也不需要全量包)
github源码:
https://github.com/alibaba/DataX
打包好了的:
https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202309/datax.tar.gz需要的运行环境
Linux
JDK(1.8以上,推荐1.8)
Python(2或3都可以)
Apache Maven 3.x (Compile DataX)使用源码Maven打包
- 嫌麻烦的,可以直接下打包好了的
- 这一步,可以去除自己不要Reader和Writer,实际不需要的去除后,可以减小包的大小
- 步奏
1、datax-all的pom.xml中注释不要的Reader和Writer
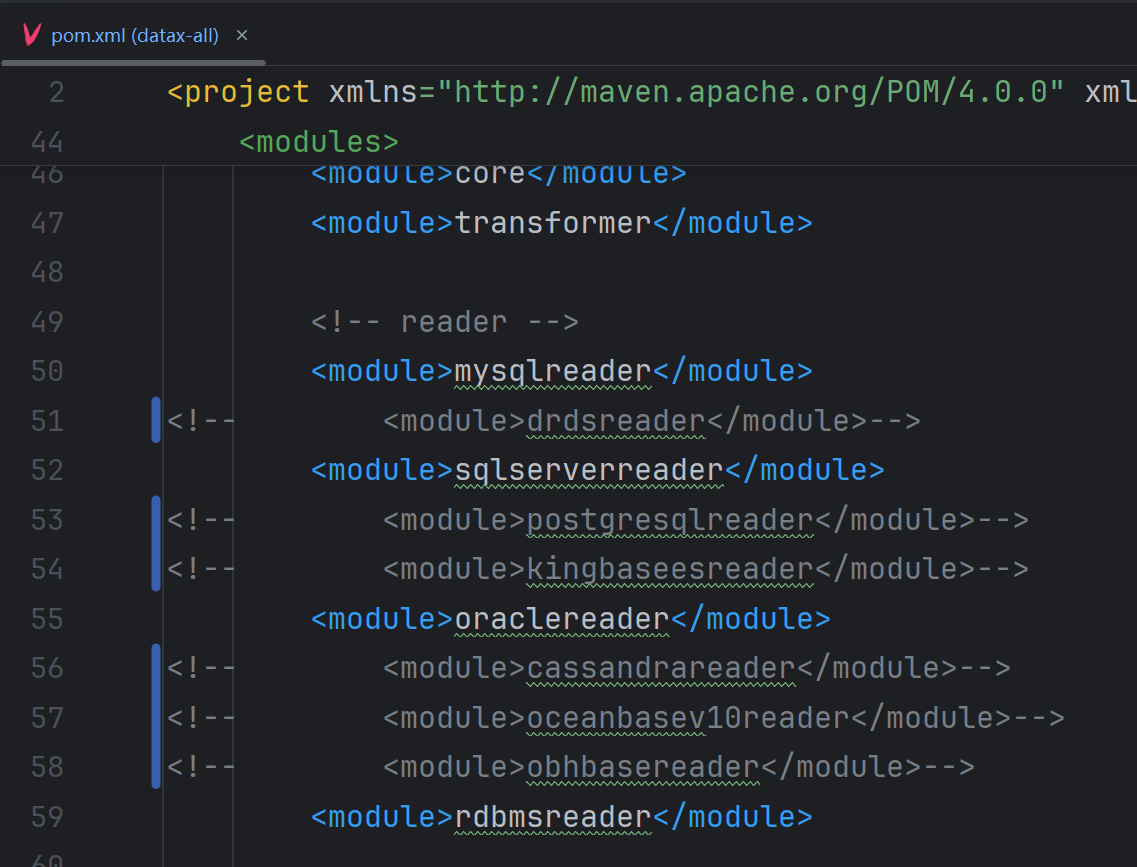
2、修改达梦数据库为达梦8(默认是7)
rdbmsreader、rdbmswriter的pom.xml修改
<!-- dm7 dm8 driver -->
<!-- <dependency>-->
<!-- <groupId>com.dameng</groupId>-->
<!-- <artifactId>Dm7JdbcDriver17</artifactId>-->
<!-- <version>7.6.0.142</version>-->
<!-- </dependency>-->
<dependency>
<groupId>com.dameng</groupId>
<artifactId>Dm8JdbcDriver18</artifactId>
<version>8.1.1.49</version>
</dependency>3、打包
-
可以在Linux服务器(需要安Maven)
cd {DataX_source_code_home}
//打包命令
mvn -U clean package assembly:assembly -Dmaven.test.skip=true -
也可以在本地idea中打包(我用的):
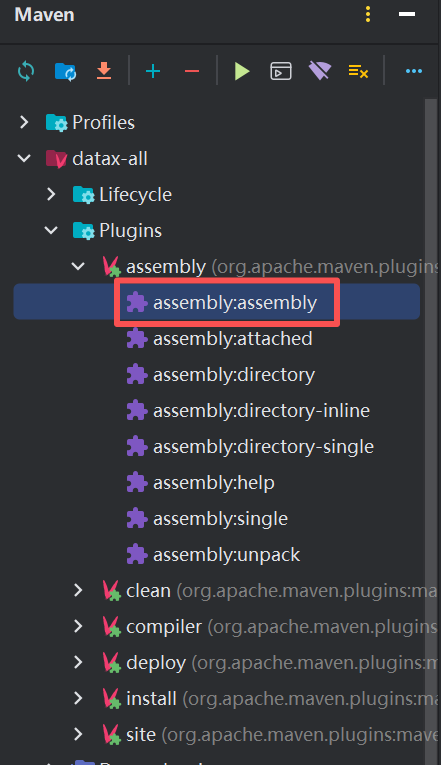
-
打包完成
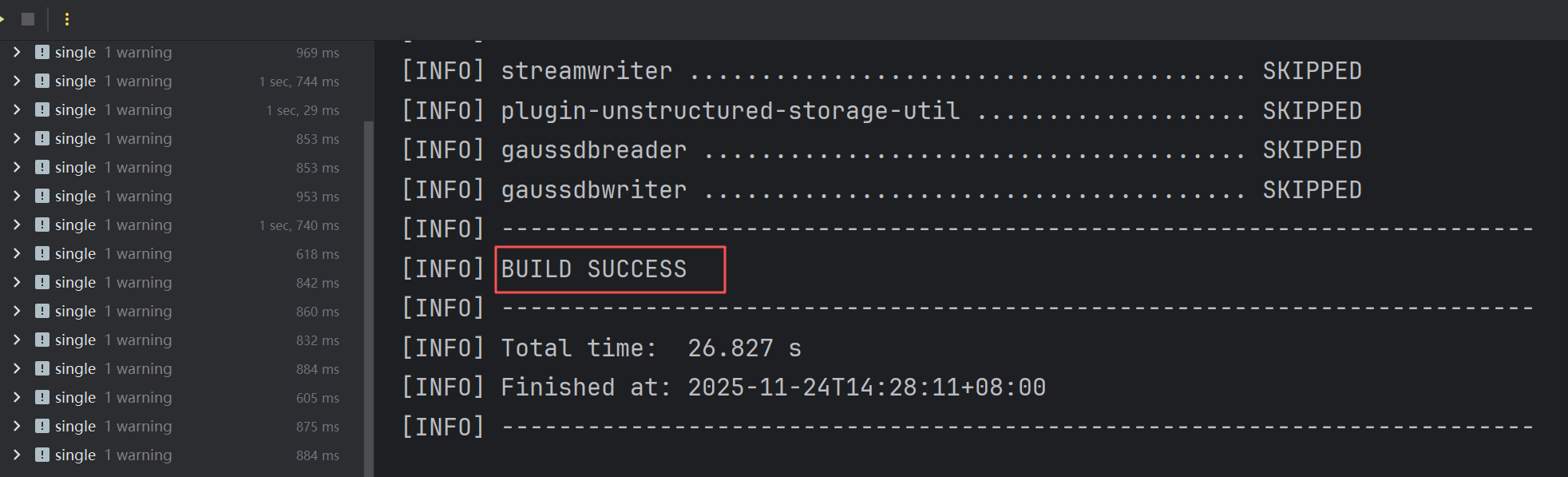
-
项目地址下:
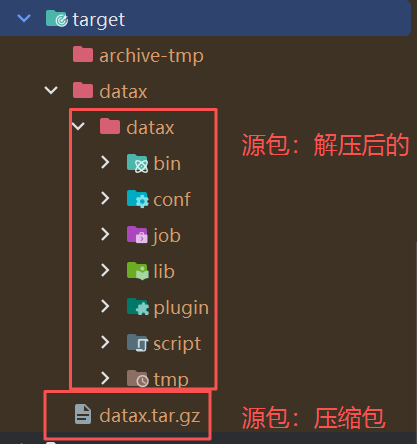
-
上传"解压后的"到服务器即可
2、演示Demo
数据准备(mysql)
-
建表
CREATE TABLE cs1.
t_8_100w(
idbigint NOT NULL COMMENT '主键',
namevarchar(2000) NULL COMMENT '名字',
sexint null COMMENT '性别:1男;2女',
decimal_fdecimal(32, 6) NULL COMMENT '大数字',
phone_numbervarchar(20) DEFAULT '13456780000' COMMENT '电话',
agevarchar(255) NULL COMMENT '字符串年龄转数字',
create_timetimestamp DEFAULT CURRENT_TIMESTAMP COMMENT '新增时间',
descriptionlongtext NULL COMMENT '大文本',
addressvarchar(2000) NULL COMMENT '空地址转默认值:未知',
PRIMARY KEY (id)
); -
数据准备1(存储过程)------会很卡(别用)
DELIMITER $$
CREATE PROCEDURE InsertMultipleRows2()
BEGIN
DECLARE i INT DEFAULT 0;
DECLARE batch_size INT DEFAULT 1000;
DECLARE description_text LONGTEXT;
DECLARE address_text VARCHAR(255);START TRANSACTION; WHILE i < 1000000 DO -- 生成10KB的大文本描述 SET description_text = REPEAT(CONCAT('DataX测试大文本字段_编号', i, '_重复内容_'), 400); -- 根据i%2生成地址:等于0生成"地址X",不等于0为NULL IF i % 2 = 0 THEN SET address_text = CONCAT('地址', i); ELSE SET address_text = NULL; END IF; INSERT INTO t_8_100w (`id`, `name`, `decimal_f`, `age`, `description`, `address`) VALUES ( i, CONCAT('名字', i), i + 0.000001, ROUND((RAND() * 12) + 18), description_text, address_text ); SET i = i + 1; -- 批量提交 IF i % batch_size = 0 THEN COMMIT; START TRANSACTION; SELECT CONCAT('已插入: ', i, ' 条记录') AS progress; END IF; END WHILE; COMMIT; SELECT '数据插入完成,总计100万条记录' AS final_result;END$$
DELIMITER ;CALL InsertMultipleRows2();
-
数据准备2(批量提交,减小文本大小)
-- 先生成存储过程
DELIMITER $$
CREATE PROCEDURE InsertMultipleRows_Batch(
IN start_id INT, -- 起始ID
IN end_id INT, -- 结束ID
IN batch_size INT -- 批次大小
)
BEGIN
DECLARE i INT DEFAULT start_id;
DECLARE description_text LONGTEXT;
DECLARE address_text VARCHAR(255);
DECLARE sex_text INT;
DECLARE total_to_insert INT;SET total_to_insert = end_id - start_id; -- 开始事务 START TRANSACTION; WHILE i < end_id DO -- 生成精确的1KB文本 SET description_text = REPEAT(CONCAT('DataX_Test_Text_', i, '_ABCDEFGHIJKLMN_'), 41); -- 根据i%2生成地址 IF i % 2 = 0 THEN SET address_text = CONCAT('地址', i); SET sex_text = 1; ELSE SET address_text = NULL; SET sex_text = 2; END IF; -- 插入数据 INSERT INTO t_8_100w (`id`, `name`, `sex`, `decimal_f`, `age`, `description`, `address`) VALUES ( i, CONCAT('名字', i), sex_text, i + 0.000001, ROUND((RAND() * 12) + 18), description_text, address_text ); SET i = i + 1; -- 每batch_size条提交一次 IF i % batch_size = 0 OR i = end_id THEN COMMIT; IF i < end_id THEN START TRANSACTION; END IF; -- 显示进度 IF i % 50000 = 0 OR i = end_id THEN SELECT CONCAT('批次 ', start_id, '-', end_id, ': 已插入 ', i - start_id, ' / ', total_to_insert, ' 条记录') AS progress; END IF; END IF; END WHILE; SELECT CONCAT('批次完成! ID范围: ', start_id, ' 到 ', end_id - 1, ' (共', total_to_insert, '条)') AS batch_complete;END$$
DELIMITER ;-- 再分批次执行
-- 测试1万条(如果能执行,再分批执行后面的)
CALL InsertMultipleRows_Batch(0, 10000, 500);
-- 每10万条创建一次,分批执行
CALL InsertMultipleRows_Batch(10000, 100000, 500);
CALL InsertMultipleRows_Batch(100000, 200000, 500);
CALL InsertMultipleRows_Batch(200000, 300000, 500);
CALL InsertMultipleRows_Batch(300000, 400000, 500);
CALL InsertMultipleRows_Batch(400000, 500000, 500);
CALL InsertMultipleRows_Batch(500000, 600000, 500);
CALL InsertMultipleRows_Batch(600000, 700000, 500);
CALL InsertMultipleRows_Batch(700000, 800000, 500);
CALL InsertMultipleRows_Batch(800000, 900000, 500);
CALL InsertMultipleRows_Batch(900000, 1000000, 500);
需要抽取的json的job准备
示例
json
{
"job": {
"content": [
{
"reader": {
"name": "oraclereader", # 读取端
"parameter": {
"column": [], # 需要同步的列 (* 表示所有的列)
"connection": [
{
"jdbcUrl": [], # 连接信息
"table": [] # 连接表
}
],
"password": "", # 连接用户
"username": "", # 连接密码
"where": "" # 描述筛选条件
}
},
"writer": {
"name": "mysqlwriter", # 写入端
"parameter": {
"column": [], # 需要同步的列
"connection": [
{
"jdbcUrl": "", # 连接信息
"table": [] # 连接表
}
],
"password": "", # 连接密码
"preSql": [], # 同步前. 要做的事
"session": [],
"username": "", # 连接用户
"writeMode": "" # 操作类型
}
},
"transformer":[]
}
],
"setting": {
"speed": {
"channel": "" # 指定并发数
}
}
}
}one.json
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["id","name"],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://ip:端口/数据库"],
"table": ["t_01"]
}
],
"password": "密码",
"username": "root",
"where": ""
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": ["id2","name2"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://ip:端口/数据库",
"table": ["t_02"]
}
],
"password": "密码",
"preSql": [],
"session": [],
"username": "root",
"writeMode": "insert"
}
},
"transformer":[] //值转换、清洗工具:用于在数据传输过程中对数据进行中间处理和转换
}
],
"setting": {
"speed": {
"channel": "6"
}
}
}
}执行job
-
python2:python。python3要加3:python3
python3 /data/datax/bin/datax.py /data/datax/job/one.json
Transformer介绍
-
用于在数据传输过程中对数据进行中间处理和转换
-
不同DataX版本的差异
DataX 3.0+
组件名称带dx_前缀:dx_filter、dx_replace、dx_groovy参数格式更加严格
DataX 2.0及以下
组件名称无前缀:filter、replace、groovy参数相对宽松
1. FilterTransformer (dx_filter) - 数据过滤器
作用:根据条件过滤数据记录
正确用法:
{
"name": "dx_filter",
"parameter": {
"columnIndex": 5, // 要过滤的字段索引
"paras": ["<=", "25"] // [操作符, 比较值]
}
}
支持的操作符:
>、>=、<、<=、==、!=
注意:符合条件的数据会被保留,不符合的被丢弃示例:
// 保留age>25的记录
{"name": "dx_filter", "parameter": {"columnIndex": 5, "paras": [">", "25"]}}
// 保留gender=="男"的记录
{"name": "dx_filter", "parameter": {"columnIndex": 2, "paras": ["==", "男"]}}2. ReplaceTransformer (dx_replace) - 字符串替换器
作用:按位置替换字符串内容
用法:
{
"name": "dx_replace",
"parameter": {
"columnIndex": 4, // 要替换的字段索引
"paras": ["3", "4", "****"] // [开始位置, 替换长度, 替换内容]
}
}
示例:
// 手机号脱敏:从第3位开始替换4个字符为****
{"name": "dx_replace", "parameter": {"columnIndex": 4, "paras": ["3", "4", "****"]}}
// 身份证号脱敏:保留前6后4
{"name": "dx_replace", "parameter": {"columnIndex": 3, "paras": ["6", "8", "********"]}}3. SubstrTransformer (dx_substr) - 字符串截取器
作用:截取字符串的指定部分
用法:
{
"name": "dx_substr",
"parameter": {
"columnIndex": 1,
"paras": ["0", "5"] // [开始位置, 截取长度]
}
}
示例:
// 截取前5个字符
{"name": "dx_substr", "parameter": {"columnIndex": 1, "paras": ["0", "5"]}}
// 截取第2到第6个字符
{"name": "dx_substr", "parameter": {"columnIndex": 1, "paras": ["1", "5"]}}4. PadTransformer (dx_pad) - 字符串填充器
作用:对字符串进行左填充或右填充
用法:
{
"name": "dx_pad",
"parameter": {
"columnIndex": 1,
"paras": ["0", "10", "l"] // [填充字符, 目标长度, 方向(l-左/r-右)]
}
}
示例:
// 左填充0到10位
{"name": "dx_pad", "parameter": {"columnIndex": 1, "paras": ["0", "10", "l"]}}
// 右填充空格到20位
{"name": "dx_pad", "parameter": {"columnIndex": 1, "paras": [" ", "20", "r"]}}5. GroovyTransformer (dx_groovy) - Groovy脚本处理器
作用:执行自定义Groovy脚本,功能最强大
用法:
{
"name": "dx_groovy",
"parameter": {
"code": "// Groovy脚本代码\nif (record.getColumn(2) != null) {\n String sex = record.getColumn(2).asString();\n if (\"1\".equals(sex)) {\n record.setColumn(2, new StringColumn(\"男\"));\n } else if (\"2\".equals(sex)) {\n record.setColumn(2, new StringColumn(\"女\"));\n }\n}\nreturn record;"
}
}常用场景:
复杂条件判断
多字段关联处理
数据类型转换
业务规则验证
6. DigestTransformer - 数据摘要生成器
作用:生成数据的摘要信息(如MD5、SHA等)
用法:
{
"name": "dx_digest",
"parameter": {
"columnIndex": 1,
"paras": ["MD5"] // 摘要算法:MD5, SHA-1, SHA-256等
}
}
示例:
// 对姓名字段生成MD5摘要
{"name": "dx_digest", "parameter": {"columnIndex": 1, "paras": ["MD5"]}}
// 对多个字段组合生成摘要
{
"name": "dx_groovy",
"parameter": {
"code": "String combined = record.getColumn(1).asString() + record.getColumn(2).asString();\nString md5 = org.apache.commons.codec.digest.DigestUtils.md5Hex(combined);\nrecord.setColumn(6, new StringColumn(md5));\nreturn record;"
}
}完整的transformer
"transformer": [
// 1. 数据过滤:只保留age>25的记录
{
"name": "dx_filter",
"parameter": {"columnIndex": 5, "paras": [">", "25"]}
},
// 2. 手机号脱敏
{
"name": "dx_replace",
"parameter": {"columnIndex": 4, "paras": ["3", "4", "****"]}
},
// 3. 姓名截取前10位
{
"name": "dx_substr",
"parameter": {"columnIndex": 1, "paras": ["0", "10"]}
},
// 4. 用户ID左补0到8位
{
"name": "dx_pad",
"parameter": {"columnIndex": 0, "paras": ["0", "8", "l"]}
},
// 5. 复杂业务逻辑:性别转换 + 地址默认值
{
"name": "dx_groovy",
"parameter": {
"code": "// 性别转换\nString sex = record.getColumn(2)?.asString();\nif (\"1\".equals(sex)) record.setColumn(2, new StringColumn(\"男\"));\nelse if (\"2\".equals(sex)) record.setColumn(2, new StringColumn(\"女\"));\n\n// 地址默认值\nif (record.getColumn(8) == null || record.getColumn(8).asString()?.trim()?.isEmpty()) {\n record.setColumn(8, new StringColumn(\"未知\"));\n}\nreturn record;"
}
},
// 6. 生成数据MD5指纹
{
"name": "dx_digest",
"parameter": {"columnIndex": 1, "paras": ["MD5"]}
}
]