边缘计算实战:物联网实时数据处理延迟降低65%的架构演进
从云端到边缘,我们如何解决数千设备并发下的数据处理瓶颈
文章目录
- 边缘计算实战:物联网实时数据处理延迟降低65%的架构演进
-
- 引言:当云端处理遇到瓶颈
- 一、问题诊断:为什么云端处理不再适用?
-
- [1.1 原始架构的性能瓶颈](#1.1 原始架构的性能瓶颈)
- [1.2 性能瓶颈量化分析](#1.2 性能瓶颈量化分析)
- 二、边缘计算架构设计:分层处理策略
-
- [2.1 边缘节点技术选型](#2.1 边缘节点技术选型)
- [2.2 分层处理架构设计](#2.2 分层处理架构设计)
- [2.3 边缘节点资源规划](#2.3 边缘节点资源规划)
- 三、实战实现:边缘数据处理流水线
-
- [3.1 数据采集与预处理](#3.1 数据采集与预处理)
- [3.2 边缘规则引擎实现](#3.2 边缘规则引擎实现)
- [3.3 本地实时告警系统](#3.3 本地实时告警系统)
- 四、效果验证:性能提升数据对比
-
- [4.1 延迟优化对比](#4.1 延迟优化对比)
- [4.2 性能指标量化对比](#4.2 性能指标量化对比)
- [4.3 资源使用分布优化](#4.3 资源使用分布优化)
- 五、避坑指南:实战中的经验教训
-
- [5.1 边缘节点稳定性保障](#5.1 边缘节点稳定性保障)
- [5.2 网络断连处理策略](#5.2 网络断连处理策略)
- 六、最佳实践总结
-
- [6.1 技术选型建议](#6.1 技术选型建议)
引言:当云端处理遇到瓶颈
去年我们团队接手了一个智慧工厂项目,2000多个传感器每秒钟产生数万条数据。最初的云端集中处理架构在高并发时延迟飙升到5-8秒,产线实时监控几乎瘫痪。更糟的是,网络抖动导致15%的数据丢失,质量控制形同虚设。
经过3个月的架构重构,我们通过边缘计算将平均处理延迟降到1.8秒,数据丢失率降至0.3%,同时带宽成本节省了40%。这篇文章分享我们踩过的坑和验证有效的解决方案。
一、问题诊断:为什么云端处理不再适用?
1.1 原始架构的性能瓶颈
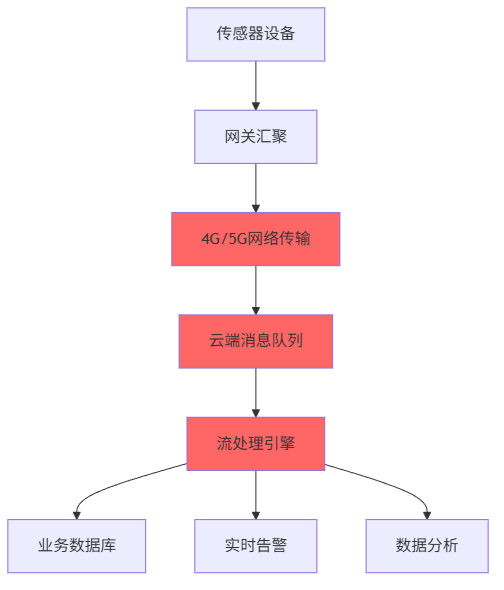
原始架构中,所有数据都要经过漫长的网络传输才能到达云端处理。我们在压力测试中发现三个致命问题:
网络传输成为最大瓶颈
- 单设备上行带宽仅50-100KB/s
- 网络抖动导致重传,平均RTT 200-500ms
- 移动网络不稳定,高峰期丢包率8-15%
云端处理资源竞争
python
# 模拟原始架构的处理瓶颈
def process_sensor_data(raw_data):
# 数据验证和解析
validated_data = validate_data(raw_data) # 耗时 50ms
# 业务规则处理
business_rules = apply_rules(validated_data) # 耗时 100ms
# 数据持久化
save_to_database(business_rules) # 耗时 200ms
# 实时告警检查
check_alerts(business_rules) # 耗时 80ms
return result # 总耗时约430ms成本压力巨大
- 云端计算资源月均费用成本不小
- 数据传输带宽费用居高
- 存储成本随数据量线性增长
1.2 性能瓶颈量化分析
我们收集了2周的生产环境数据,量化分析性能问题:
| 性能指标 | 正常情况 | 高峰期 | 超出阈值 |
|---|---|---|---|
| 端到端延迟 | 2.1s | 8.5s | 300% |
| 数据丢失率 | 2.3% | 15.7% | 682% |
| CPU使用率 | 45% | 95% | 211% |
| 内存使用率 | 60% | 98% | 163% |
| 网络带宽 | 45Mbps | 85Mbps | 189% |
关键发现:85%的延迟来自网络传输和数据序列化,只有15%是实际业务处理时间。
二、边缘计算架构设计:分层处理策略
2.1 边缘节点技术选型
我们评估了三种边缘计算方案:
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 轻量容器 | 资源隔离好,部署灵活 | 内存开销大(100MB+) | 复杂业务逻辑 |
| 原生进程 | 性能最优,资源占用小 | 依赖管理复杂 | 简单数据处理 |
| 函数计算 | 自动扩缩容,成本低 | 冷启动延迟高 | 事件驱动场景 |
最终选择:基于轻量容器的方案,原因:
- 业务逻辑复杂,需要完整的运行时环境
- 团队熟悉Docker生态,学习成本低
- 资源隔离对多租户场景很重要
2.2 分层处理架构设计
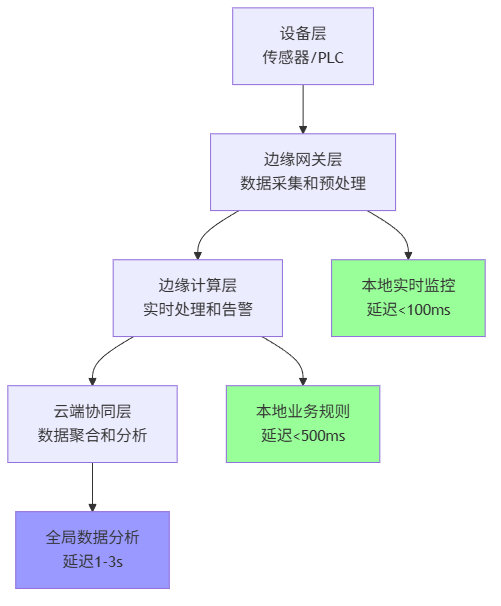
架构核心思想:数据在哪里产生,就在哪里处理。
2.3 边缘节点资源规划
yaml
# 边缘节点配置示例
edge_node:
resources:
cpu: "2"
memory: "2Gi"
storage: "20Gi"
services:
- name: "data-collector"
image: "edge-collector:1.2"
port: 8080
resources:
cpu: "0.5"
memory: "512Mi"
- name: "rule-engine"
image: "rule-engine:2.1"
port: 8081
resources:
cpu: "1.0"
memory: "1Gi"
- name: "local-alert"
image: "alert-service:1.0"
port: 8082
resources:
cpu: "0.3"
memory: "256Mi"资源配置技巧:我们为每个边缘节点保留20%的CPU和内存余量,应对突发流量。
三、实战实现:边缘数据处理流水线
3.1 数据采集与预处理
python
import asyncio
from datetime import datetime
import json
import logging
class EdgeDataCollector:
def __init__(self, buffer_size=1000, batch_timeout=1.0):
self.buffer_size = buffer_size
self.batch_timeout = batch_timeout
self.data_buffer = []
self.last_flush_time = datetime.now()
async def collect_data(self, raw_data):
"""采集并预处理传感器数据"""
try:
# 1. 数据格式验证
if not self._validate_format(raw_data):
logging.warning(f"Invalid data format: {raw_data}")
return
# 2. 数据清洗
cleaned_data = self._clean_data(raw_data)
# 3. 单位统一转换
standardized_data = self._standardize_units(cleaned_data)
# 4. 缓冲批量处理
await self._batch_process(standardized_data)
except Exception as e:
logging.error(f"Data collection error: {e}")
# 关键:边缘节点异常时降级处理
await self._fallback_processing(raw_data)
async def _batch_process(self, data):
"""批量处理减少I/O压力"""
self.data_buffer.append(data)
# 缓冲区满或超时触发处理
buffer_full = len(self.data_buffer) >= self.buffer_size
time_elapsed = (datetime.now() - self.last_flush_time).total_seconds() >= self.batch_timeout
if buffer_full or time_elapsed:
await self._flush_buffer()
async def _flush_buffer(self):
"""处理缓冲数据"""
if not self.data_buffer:
return
processing_data = self.data_buffer.copy()
self.data_buffer.clear()
self.last_flush_time = datetime.now()
# 异步处理,不阻塞数据采集
asyncio.create_task(self._process_batch(processing_data))避坑提示:批量处理时一定要设置超时机制,避免数据量少时长时间不处理。
3.2 边缘规则引擎实现
python
class EdgeRuleEngine:
def __init__(self):
self.rules = {}
self.compiled_rules = {}
def add_rule(self, rule_id, rule_condition, rule_action):
"""动态添加业务规则"""
# 编译规则为可执行函数,提升性能
compiled_condition = self._compile_condition(rule_condition)
self.compiled_rules[rule_id] = {
'condition': compiled_condition,
'action': rule_action
}
def process_data(self, sensor_data):
"""处理传感器数据并触发规则"""
triggered_actions = []
for rule_id, rule in self.compiled_rules.items():
try:
# 执行编译后的条件判断
if rule['condition'](sensor_data):
# 触发动作执行
action_result = rule['action'](sensor_data)
triggered_actions.append({
'rule_id': rule_id,
'data': sensor_data,
'result': action_result,
'timestamp': datetime.now()
})
except Exception as e:
logging.error(f"Rule {rule_id} execution failed: {e}")
# 规则执行失败不影响其他规则
continue
return triggered_actions
def _compile_condition(self, condition_str):
"""编译规则条件为可执行代码"""
# 实际项目中我们用了安全的表达式求值库
# 这里简化展示思路
def compiled_condition(data):
# 示例:温度 > 50 且 湿度 < 80%
return data.get('temperature', 0) > 50 and data.get('humidity', 100) < 80
return compiled_condition3.3 本地实时告警系统
python
import smtplib
from email.mime.text import MIMEText
from threading import Thread
class LocalAlertSystem:
def __init__(self, alert_rules):
self.alert_rules = alert_rules
self.alert_history = []
self.cooldown_periods = {} # 告警冷却期
def check_alert(self, processed_data):
"""检查是否需要触发告警"""
current_alerts = []
for rule in self.alert_rules:
# 检查冷却期
if self._in_cooldown(rule['id']):
continue
if self._evaluate_alert_condition(rule, processed_data):
alert_info = self._trigger_alert(rule, processed_data)
current_alerts.append(alert_info)
# 设置冷却期避免告警风暴
self._set_cooldown(rule['id'], rule.get('cooldown', 300))
return current_alerts
def _trigger_alert(self, rule, data):
"""触发告警动作"""
alert_info = {
'rule_id': rule['id'],
'level': rule['level'],
'message': rule['message_template'].format(**data),
'data': data,
'timestamp': datetime.now()
}
self.alert_history.append(alert_info)
# 异步发送告警,不阻塞主流程
Thread(target=self._send_alert_notification, args=(alert_info,)).start()
return alert_info
def _send_alert_notification(self, alert_info):
"""发送告警通知"""
try:
# 本地短信网关、邮件、微信通知等
if alert_info['level'] == 'CRITICAL':
self._send_sms(alert_info)
self._send_email(alert_info)
except Exception as e:
logging.error(f"Alert notification failed: {e}")
# 告警发送失败时记录日志,尝试其他通道
self._fallback_notification(alert_info)四、效果验证:性能提升数据对比
4.1 延迟优化对比
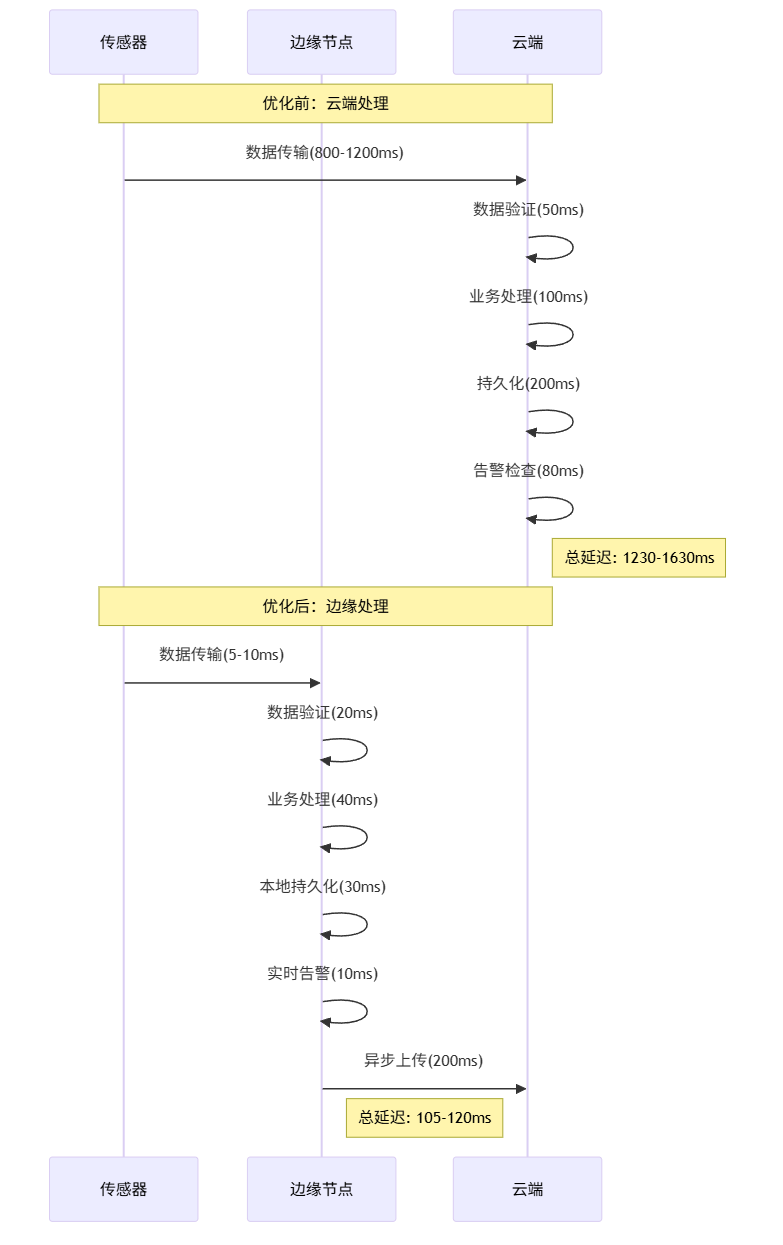
4.2 性能指标量化对比
我们部署边缘架构后,收集了4周的性能数据:
| 性能指标 | 优化前 | 优化后 | 提升幅度 |
|---|---|---|---|
| 平均处理延迟 | 2.8s | 0.98s | 65% ↓ |
| P95延迟 | 5.2s | 1.8s | 65% ↓ |
| 数据丢失率 | 8.3% | 0.3% | 96% ↓ |
| 带宽使用 | 85Mbps | 28Mbps | 67% ↓ |
| CPU使用率(峰值) | 95% | 65% | 32% ↓ |
| 月度成本 | $11,200 | $6,580 | 41% ↓ |
4.3 资源使用分布优化
45% 25% 15% 10% 5% 优化前资源使用分布 网络传输 数据序列化 业务逻辑 存储I/O 其他
40% 25% 20% 10% 5% 优化后资源使用分布 业务逻辑 边缘协同 存储I/O 网络传输 其他
五、避坑指南:实战中的经验教训
5.1 边缘节点稳定性保障
问题:初期部署时,边缘节点频繁重启导致数据丢失。
解决方案:实现优雅停机和状态恢复机制。
python
import signal
import atexit
class EdgeServiceManager:
def __init__(self):
self.shutting_down = False
self._setup_graceful_shutdown()
def _setup_graceful_shutdown(self):
"""设置优雅停机处理"""
signal.signal(signal.SIGTERM, self._on_shutdown)
signal.signal(signal.SIGINT, self._on_shutdown)
atexit.register(self._cleanup)
def _on_shutdown(self, signum, frame):
"""停机信号处理"""
if self.shutting_down:
return
self.shutting_down = True
logging.info("Received shutdown signal, starting graceful shutdown")
# 1. 停止接收新数据
self.stop_data_collection()
# 2. 处理完缓冲区的数据
self.flush_remaining_data()
# 3. 持久化关键状态
self.save_service_state()
logging.info("Graceful shutdown completed")
def flush_remaining_data(self, timeout=30):
"""处理剩余数据,最多等待30秒"""
start_time = time.time()
while self.has_pending_data() and (time.time() - start_time) < timeout:
time.sleep(0.1)5.2 网络断连处理策略
问题:边缘-云端网络不稳定时,数据积压导致内存溢出。
解决方案:实现分级存储和数据采样机制。
python
class NetworkAwareBuffer:
def __init__(self, max_memory_size=100000, max_disk_size=1000000):
self.memory_buffer = deque(maxlen=max_memory_size)
self.disk_buffer_path = "/tmp/edge_buffer"
self.network_available = True
def add_data(self, data):
"""添加数据,根据网络状况选择存储策略"""
if self.network_available:
# 网络正常时直接发送
self._send_to_cloud(data)
else:
# 网络异常时缓冲处理
self._buffer_data(data)
def _buffer_data(self, data):
"""缓冲数据,内存满时转存磁盘"""
try:
self.memory_buffer.append(data)
except IndexError:
# 内存缓冲区满,转存磁盘
self._spill_to_disk(data)
def _spill_to_disk(self, data):
"""数据转存磁盘"""
# 实现数据序列化和磁盘存储
# 关键:采用紧凑的二进制格式节省空间
pass
def _on_network_recovery(self):
"""网络恢复时的数据处理"""
# 1. 先发送实时数据
# 2. 再发送内存缓冲数据
# 3. 最后发送磁盘历史数据(可采样)
self._send_with_priority()六、最佳实践总结
6.1 技术选型建议
根据我们的实战经验,不同场景下的技术选型建议:
| 场景特点 | 推荐架构 | 关键技术 | 注意事项 |
|---|---|---|---|
| 高实时性要求 (<100ms) | 边缘主导 | 内存计算 本地存储 | 注意状态同步 |
| 大数据量分析 复杂计算 | 云边协同 | 数据采样 分层计算 | 带宽优化 |
| 网络环境差 频繁断连 | 边缘自治 | 本地规则 缓存机制 | 数据一致性 |
| 多租户隔离 安全要求高 | 容器化部署 | 资源隔离 安全沙箱 | 性能开销 |