前言
MySQL是互联网公司用得最多的数据库,而InnoDB则是MySQL生态中最常见的存储引擎。
它为什么能够在大数据量、高并发的互联网业务中稳定运行?
今天我们来聊聊InnoDB的并发控制、锁机制和MVCC------从基础概念到内核设计的完整逻辑。
这篇文章稍长一些,建议收藏后慢慢品读。
并发控制:为什么数据库需要它?
想象一个场景:
多个请求同时对同一条数据进行操作。如果没有任何保护措施,结果会是混乱的------某个线程还在修改数据,另一个线程已经开始读取,最后导致数据不一致。
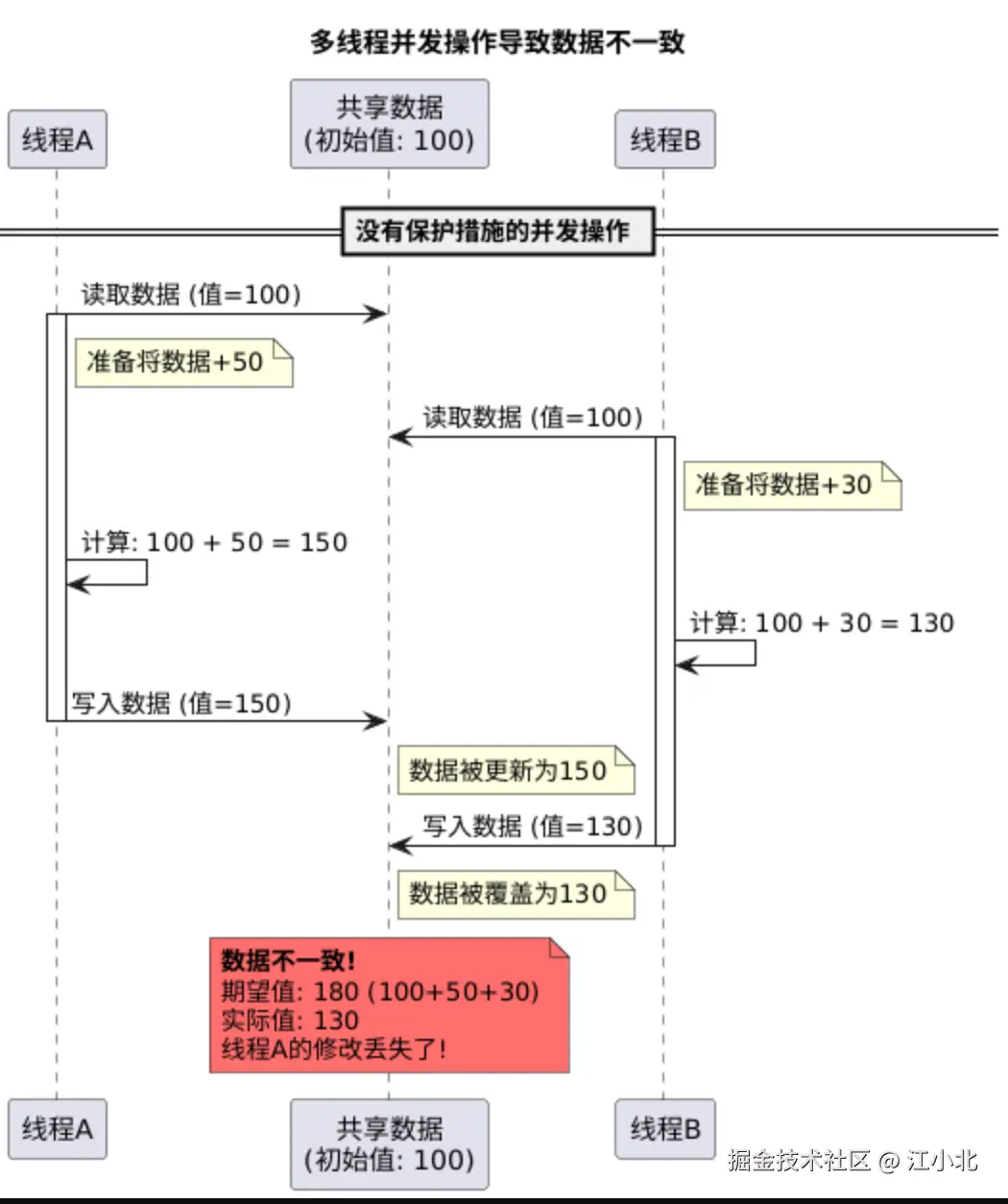
这就是为什么数据库必须有并发控制机制。
从技术角度看,保证数据一致性的方法通常有两类:
- 一是用锁来阻止冲突操作
- 二是用数据多版本来让不同操作并行进行。
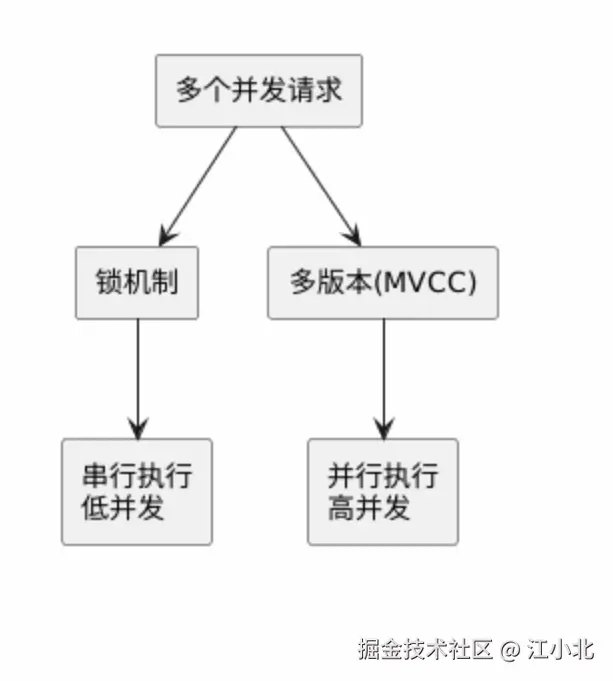
从普通锁到读写锁的进化
最朴素的想法就是用一把锁把临界区锁死:
操作数据前加锁,操作完后释放。
但这样做太粗暴了------即使只是读取数据,也要等待写操作完成,所有操作本质上变成了串行。
这显然不够。后来人们想到了共享锁 和排他锁的区分:
- 读取数据时加共享锁(S锁),多个读操作可以同时进行
- 修改数据时加排他锁(X锁),谁都得等
这样就实现了"读读并行"的目标。
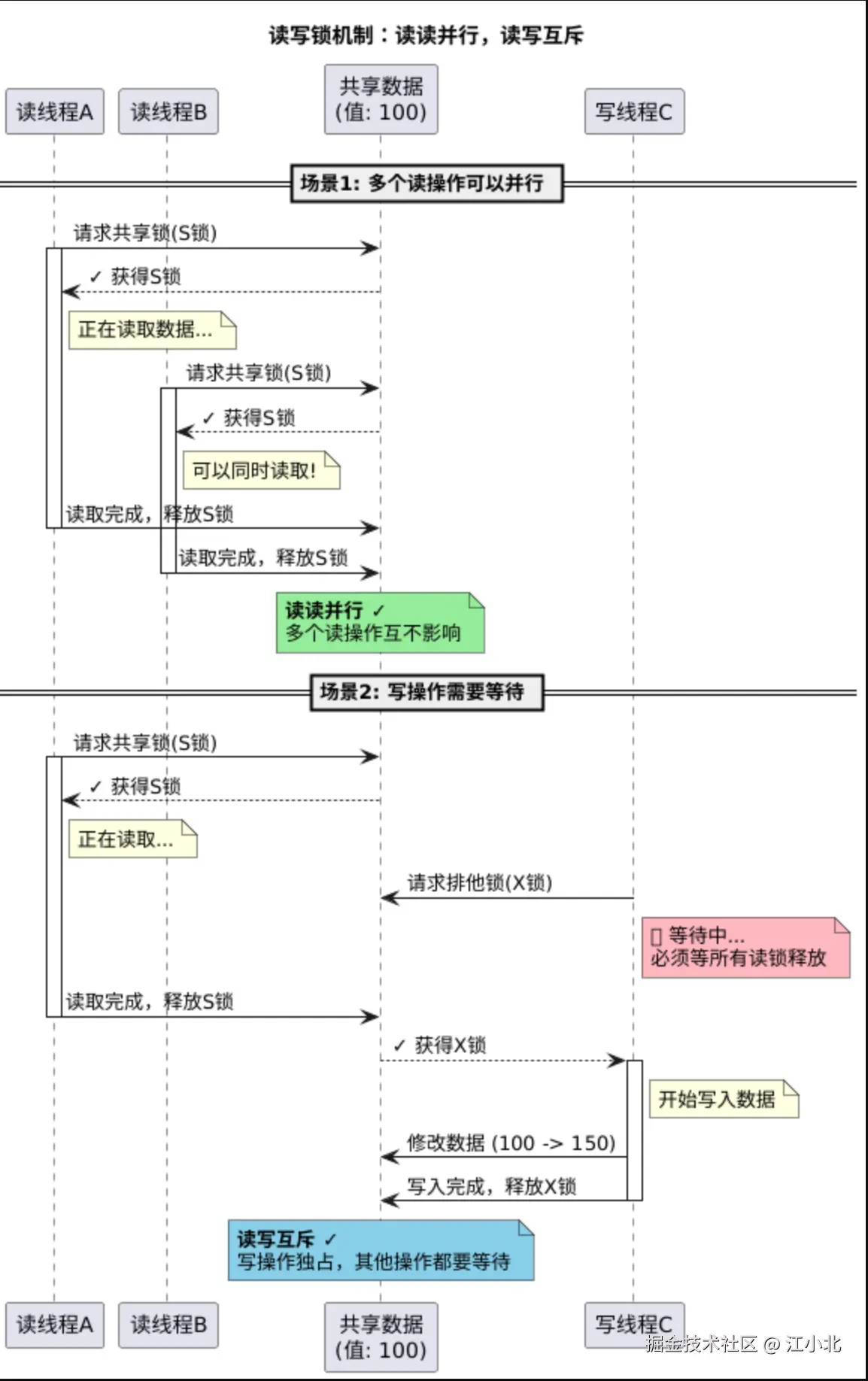
但问题依然存在:
一旦某个写操作开始执行,所有读操作就必须阻塞。对应到数据库层面,就是写事务未提交时,相关数据的select会被挡住。
能不能进一步突破这个瓶颈呢?
最近无意间获得一份阿里大佬写的刷题笔记,一下子打通了我的任督二脉,进大厂原来没那么难。 这是大佬写的 7701页的BAT大佬写的刷题笔记,让我offer拿到手软
数据多版本:读写真正并行的钥匙
这里引出了一个优雅的idea------数据多版本。核心思想很简单:
写操作不要直接修改原数据,而是复制一份新版本来修改。这样,并发的读操作仍然可以读取旧版本的数据。写操作也不会被读阻塞。
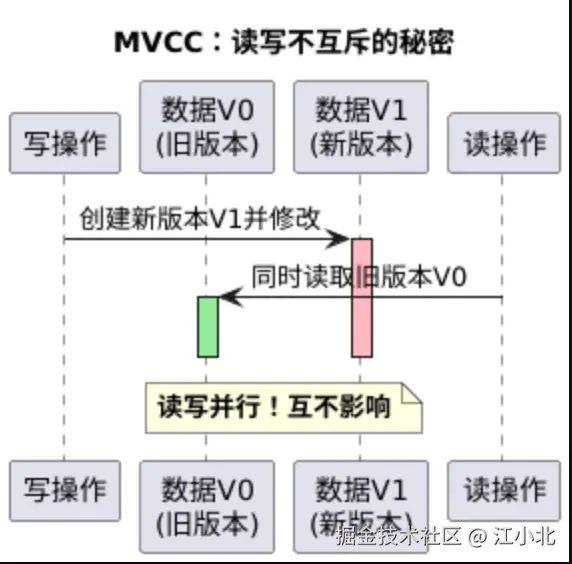
想象这样一个过程:
T1时刻,某个写操作开始,它克隆了一份数据(版本V1),开始修改。
T2时刻,一个读操作到达,它读取的仍是原版本V0的数据。
T3时刻又来了一个读,照样读V0。直到写操作提交,新版本才会变成"当前版本"。
这就是读写并行的秘诀。
并发能力的演进就这样展开了:普通锁做不到并行 → 读写锁实现读读并行 → 多版本技术实现读写并行。
这个思路比具体的技术细节更重要。
实现多版本的基础:redo日志与undo日志
在InnoDB真正如何利用多版本之前,我们需要理解两样东西:redo日志和undo日志。
redo日志的两个使命
事务提交后,数据必须保证刷到磁盘。但每次都直接写磁盘太低效了------磁盘随机写是性能杀手。
聪明的办法是:先把修改操作写到redo日志(这是顺序写,快得多),然后定期将数据刷到磁盘。这样既保证了ACID特性,又大幅提高了吞吐量。
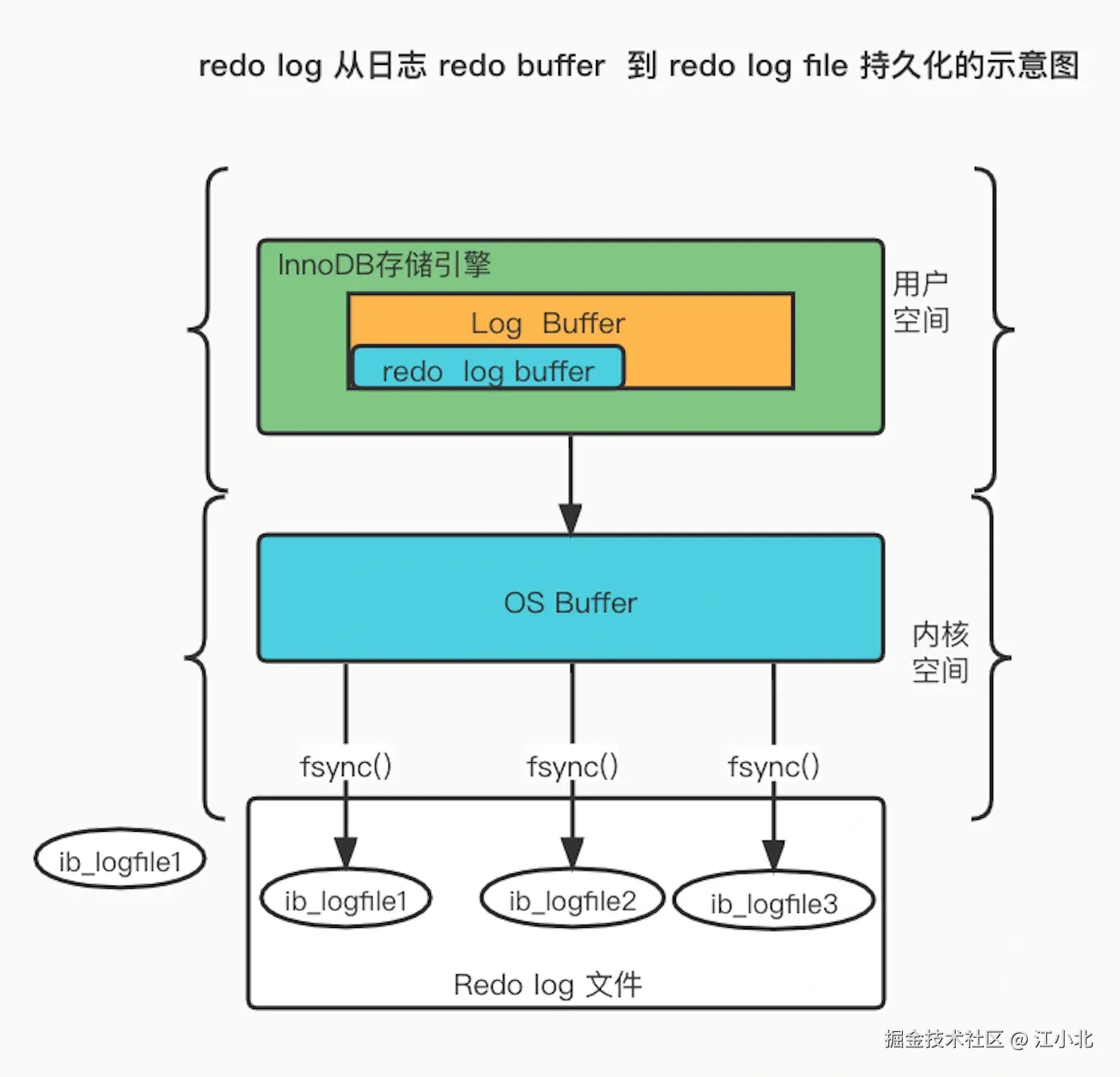
如果数据库中途崩溃,重启时可以重新执行redo日志里的操作,确保所有已提交的事务都被持久化。简言之,redo日志保护已提交事务。
undo日志的角色
undo日志做的事相反。当事务修改数据时,修改前的旧版本被存入undo日志。如果事务需要回滚,或数据库崩溃需要恢复,这些旧版本数据就派上用场了。
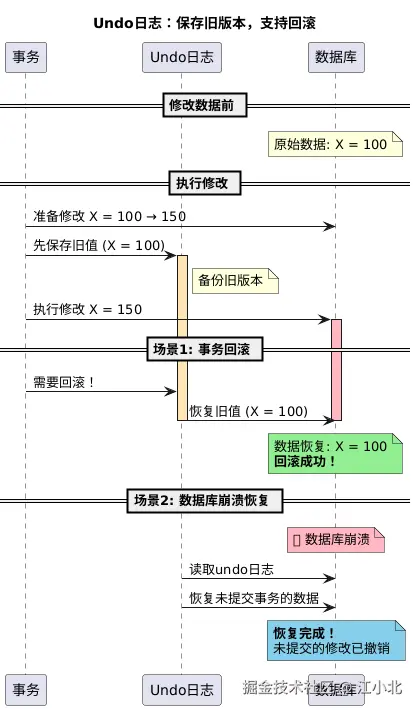
具体来说,insert操作的undo记录新数据的主键,delete和update的undo记录完整的旧数据行。回滚时直接用这些旧版本恢复就行。
undo日志的真正妙用,是为MVCC提供了旧版本数据的来源。
回滚段:undo的仓库
存储undo日志的地方叫回滚段。我们用一个例子来看它如何工作。
假设有个表 t(id PK, name),初始数据是:
1, xiaobei
2, zhangsan
3, lisi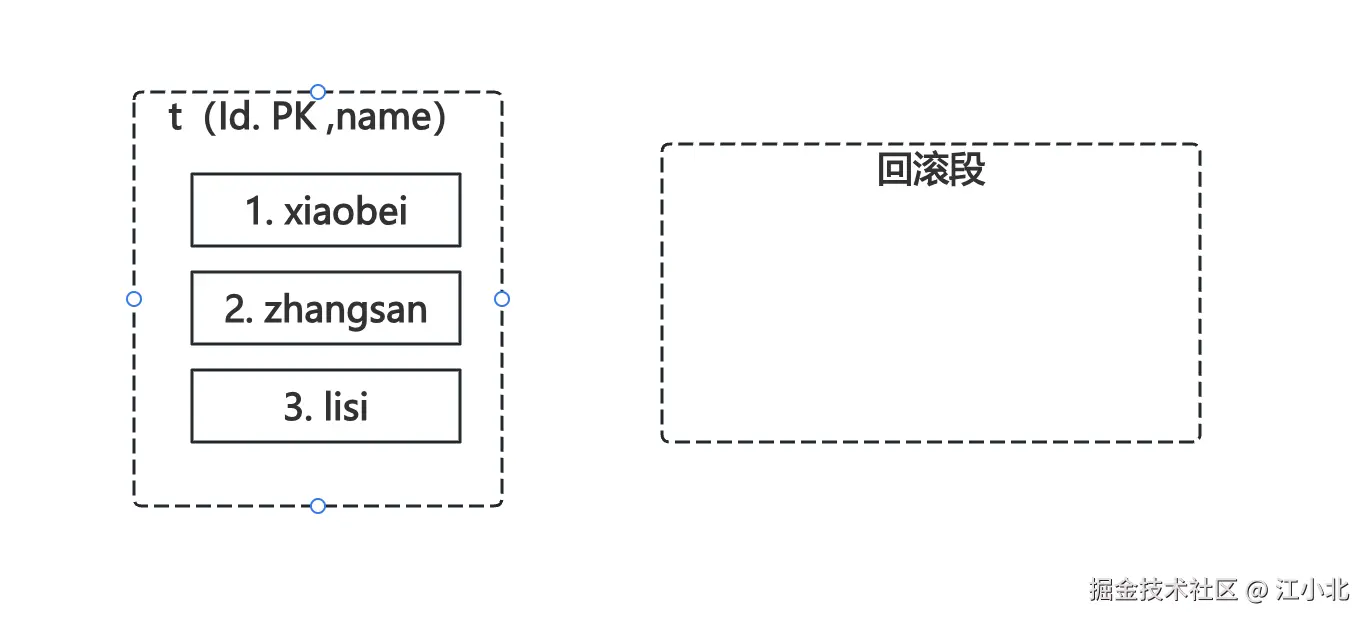
现在启动一个事务执行了几个操作但还未提交:
sql
start trx;
delete (1, xiaobei);
update (3, lisi) to (3, xxx);
insert (4, wangwu);此时回滚段中会出现这些记录:
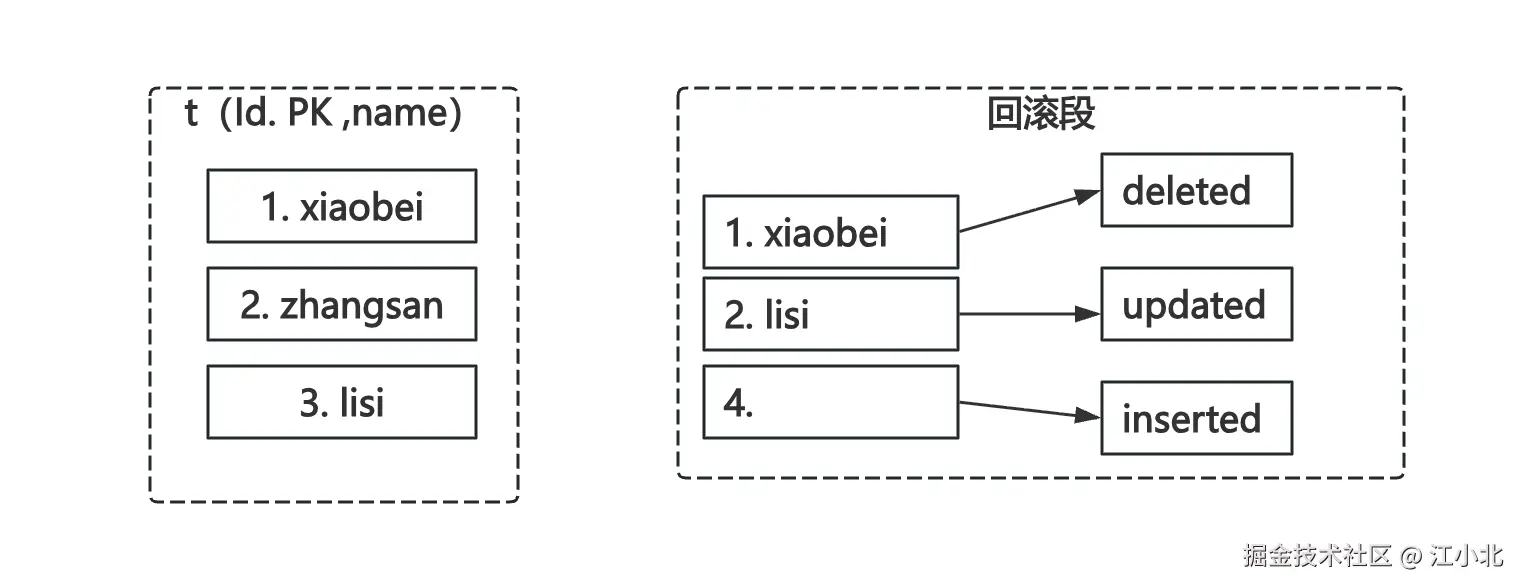
- delete之前的
(1, shenjian)进入回滚段 - update之前的
(3, lisi)进入回滚段 - insert的新PK
4也进去了
如果事务要回滚,这些undo数据就会被用上:
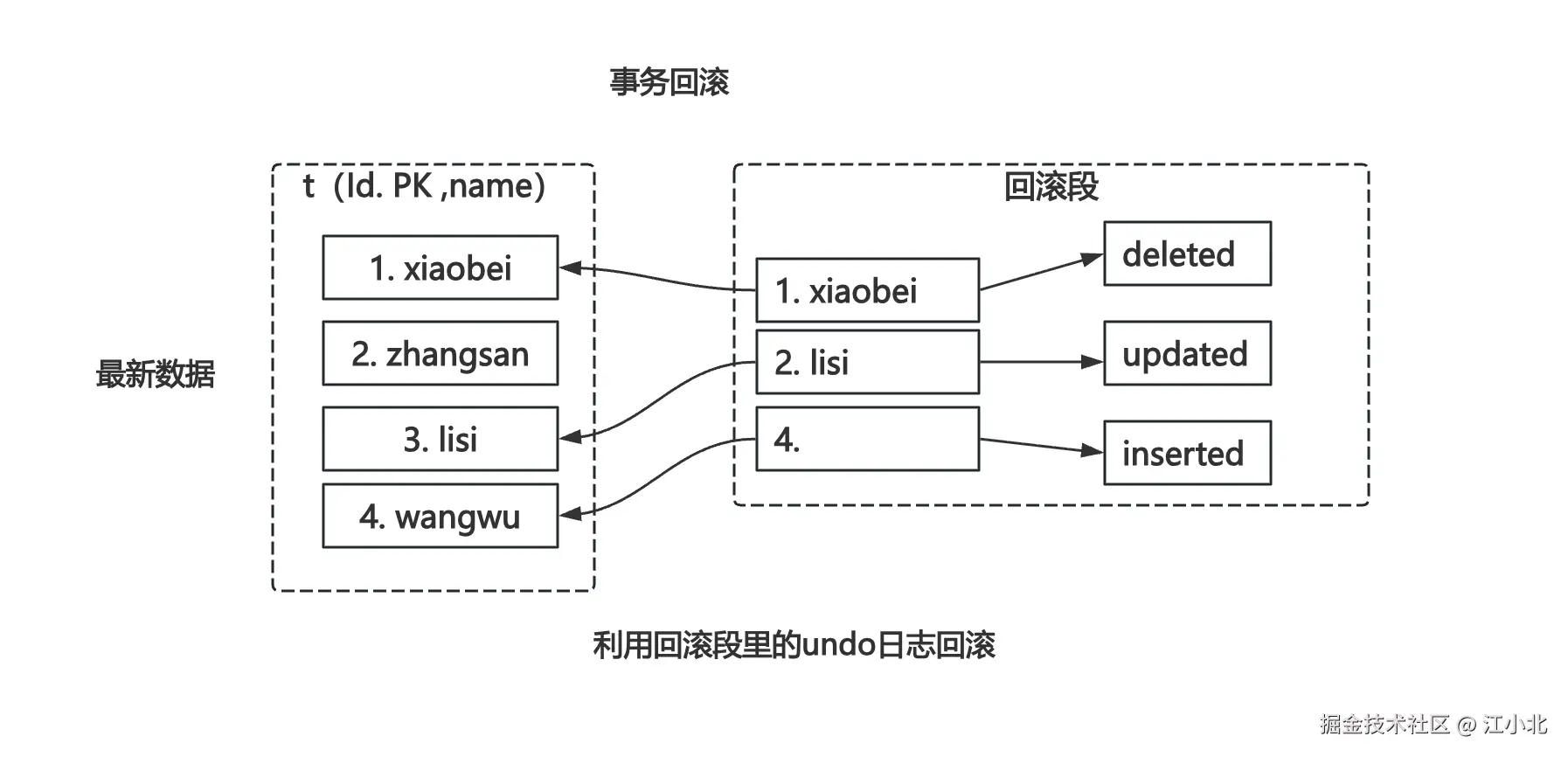
被删的行恢复了,被改的行恢复了,新插入的行被删掉了。
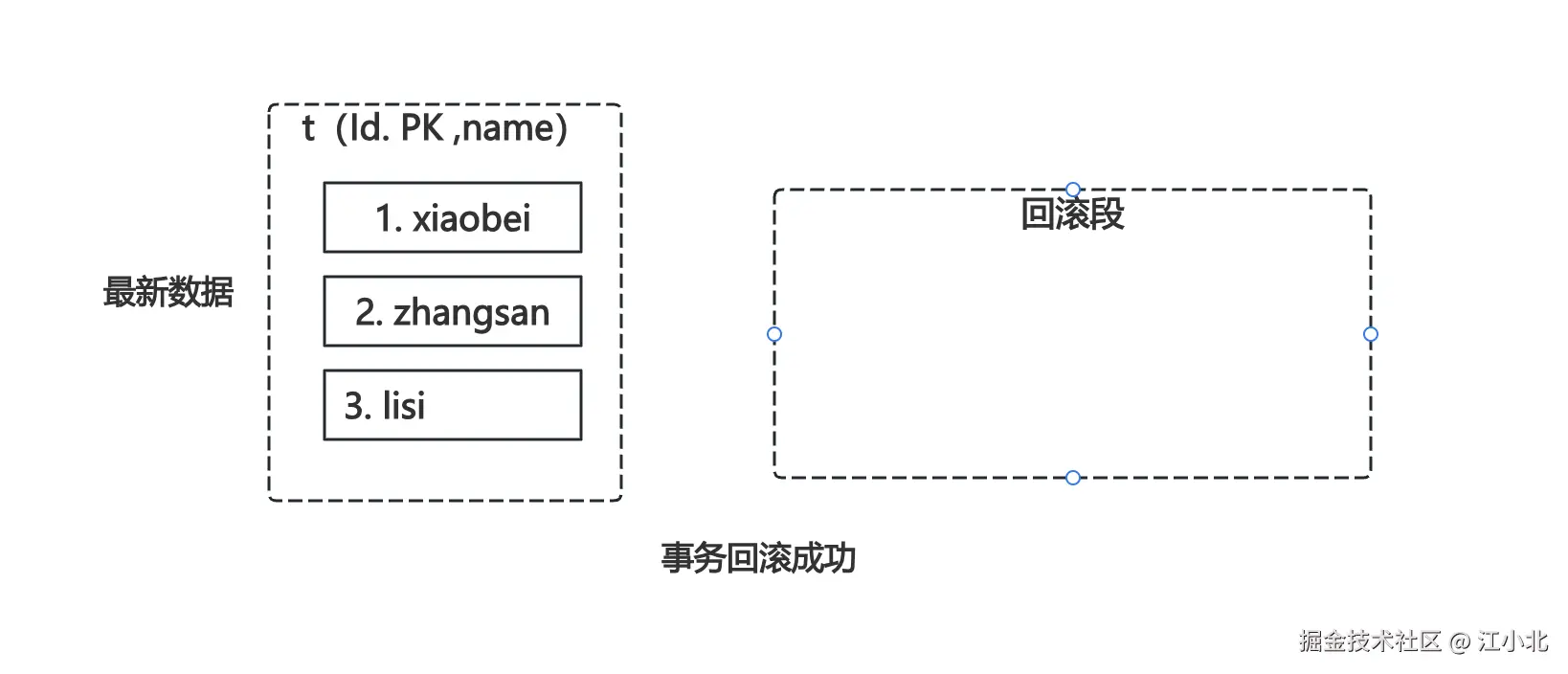
一切回到原点。
InnoDB的MVCC:多版本并发控制的真面目
InnoDB之所以能在互联网的高并发场景中表现出色,根本原因就是MVCC(多版本并发控制)。它通过让事务读取旧版本数据,从而大幅降低锁冲突。
InnoDB内核给每一行数据都加了三个隐藏属性:
- DB_TRX_ID(6字节):最后修改这行数据的事务ID
- DB_ROLL_PTR(7字节):指向回滚段中undo日志的指针
- DB_ROW_ID(6字节):单调递增的行号
这样设计看似简单,实际上威力巨大。回滚段里的数据是历史快照,永不修改。因此select语句可以放心地去读取它们,完全不需要加锁。
这种不加锁的一致性读就叫快照读。它是InnoDB并发高的核心秘密。所谓一致性,是指事务读到的数据要么是事务开始前就存在的(来自其他已提交事务),要么是事务自己插入或修改的。
什么是快照读?
除非你显式加锁,否则普通的select都是快照读:
sql
select * from t where id > 2;显式加锁的读就不同了:
sql
select * from t where id > 2 lock in share mode;
select * from t where id > 2 for update;这两种会加上共享锁或排他锁,成为当前读(current read)。它们会和事务的隔离级别产生复杂的交互。具体怎么工作的,我们后面再展开。
要点回顾
- 并发控制的两个思路是锁和多版本。三个阶段分别是:普通锁(串行)→ 读写锁(读读并行)→ 多版本(读写并行)
- redo日志通过顺序写优化了持久化性能,保护已提交事务
- undo日志为回滚提供了基础,同时也是MVCC的数据源
- InnoDB依靠存储在回滚段中的旧版本数据,实现了快照读这种不加锁的一致性读
- 普通select就是快照读,这是InnoDB高并发的核心原因
架构师小北 致力于从微观原理、中观实践、宏观方法论三个维度讲透技术。希望你有所收获。欢迎关注,我们一起成长
MySQL内核相关文章:
《面试官问:MySQL 能用 Docker 部署吗?答错直接挂!》
《为什么数据库能边跑边备份?MySQL备份这个坑,90%的程序员都掉过》
最后说一句(求关注,求赞,别白嫖我)
最近无意间获得一份阿里大佬写的刷题笔记,一下子打通了我的任督二脉,进大厂原来没那么难。 这是大佬写的 7701页的BAT大佬写的刷题笔记,让我offer拿到手软
本文,已收录于,我的技术网站 cxykk.com:程序员编程资料站,有大厂完整面经,工作技术,架构师成长之路,等经验分享
求一键三连:点赞、分享、收藏
点赞对我真的非常重要!在线求赞,加个关注我会非常感激!