摘要
随着人工智能技术的飞速发展,企业对智能客服系统的需求日益增长。传统的客服系统面临着数据管理复杂、响应效率低、个性化服务不足等挑战。openGauss作为一款开源企业级关系型数据库,凭借其强大的数据处理能力、向量数据库支持和AI友好的特性,为智能客服系统的构建提供了坚实的数据基础。本文探讨了openGauss在智能客服领域的应用,分析了其如何赋能企业实现高效、智能、个性化的客户服务体验。
背景与机遇
AI智能客服的背景
在数字化转型的浪潮中,企业客服已从简单的问题解答演进为复杂的客户关系管理和服务创新的重要环节。根据行业数据显示,企业平均每年处理数百万级别的客户咨询,传统的人工客服模式面临以下挑战:
-
效率瓶颈:人工客服响应时间长,无法24小时全天候服务
-
成本压力:客服人员培训、管理成本高,人员流动率大
-
服务质量不均:服务质量依赖于个人能力,难以保证一致性
-
数据孤岛:客户信息分散,难以形成统一的知识库
-
个性化不足:无法根据客户历史和偏好提供定制化服务
AI智能客服的机遇
人工智能技术的突破为客服行业带来了新的机遇。通过自然语言处理(NLP)、机器学习(ML)和大语言模型(LLM)等技术,企业可以构建能够理解客户意图、自动生成回复、持续学习改进的智能客服系统。
然而,构建高效的AI智能客服系统需要一个强大的数据基础设施,这正是openGauss的优势所在。
openGauss的核心能力
企业级数据库特性
openGauss是华为自主研发的开源企业级关系型数据库,具有以下核心特性:
高性能
-
OLTP优化:针对在线事务处理进行深度优化,支持高并发场景
-
查询加速:先进的查询优化器和执行引擎,毫秒级响应
-
批量处理:支持大规模数据导入和处理,提升数据吞吐量
高可用性
-
主备一体化:支持同步复制,确保数据零丢失
-
故障自动转移:秒级故障检测和自动切换
-
多副本机制:支持多个备份副本,提升系统可靠性
安全性
-
多层安全防护:身份认证、权限控制、数据加密
-
审计日志:完整的操作审计,满足合规要求
-
数据隐私保护:支持行级安全策略和数据脱敏
向量数据库能力
openGauss集成了向量数据库功能,这是AI应用的关键:
向量存储与检索
-
高维向量支持:原生支持高维向量数据类型
-
向量索引:支持IVFFlat、HNSW等高效索引算法
-
相似度搜索:毫秒级的向量相似度查询
向量与关系数据融合
-
统一存储:向量和结构化数据在同一数据库中管理
-
联合查询:支持向量与关系数据的混合查询
-
事务一致性:保证向量和关系数据的一致性
AI友好的特性
向量化计算
-
SIMD优化:充分利用现代CPU的向量化指令
-
GPU加速:支持GPU加速的向量计算
-
批量操作:高效的批量向量操作
与AI框架的集成
-
Python支持:原生支持Python客户端和存储过程
-
开源生态:与TensorFlow、PyTorch等主流AI框架兼容
-
向量化接口:提供友好的向量操作API
智能客服系统架构
系统整体架构
表现层 (Controller)
↓
业务层 (Service)
↓
数据访问层 (Repository)
↓
数据模型层 (Entity)
↓
数据库层 (openGauss/PostgreSQL)
核心模块设计
智能问答模块
-
基于向量相似度的语义搜索
-
支持多知识库条目排序
-
可配置的相似度阈值和返回数量
-
实现类: SmartCustomerService.smartQA()
个性化推荐模块
-
基于客户档案向量的推荐
-
考虑优先级和VIP等级的加权计算
-
动态生成个性化结果
-
实现类: SmartCustomerService.getPersonalizedRecommendations()
对话管理模块
-
多渠道对话支持(Web/App/微信等)
-
完整的对话历史记录
-
对话状态跟踪和意图识别
-
实现类: SmartCustomerService.createConversationSession(), logMessage(), closeConversationSession()
客户档案管理模块
-
客户基本信息管理
-
VIP等级和消费统计
-
个性化偏好存储
-
实现类: SmartCustomerService.updateCustomerProfile()
数据分析模块
-
满意度分析视图
-
意图分布统计
-
解决率和高满意度率计算
-
实现方式: SQL视图 (satisfaction_analysis, intent_distribution)
实现最佳实践
数据模型设计
向量维度选择
-
推荐维度:657-1435维
-
权衡考虑:维度越高精度越好,但存储和计算成本增加
-
选择建议:根据具体的embedding模型选择,如BERT使用657维,OpenAI embedding使用1435维
向量索引策略
-- IVFFlat索引:适合大规模数据,查询速度快
CREATE INDEX idx_ivf ON knowledge_base
USING ivfflat (embedding vector_cosine_ops)
WITH (lists = 100);
-- HNSW索引:适合高维数据,精度高
CREATE INDEX idx_hnsw ON knowledge_base
USING hnsw (embedding vector_cosine_ops)
WITH (m = 15, ef_construction = 200);
混合查询优化
-- 结合向量相似度和关键字匹配
SELECT id, title, content,
1 - (embedding <=> query_embedding) as similarity
FROM knowledge_base
WHERE category = 'faq'
AND (title ILIKE '%关键词%' OR content ILIKE '%关键词%')
ORDER BY similarity DESC
LIMIT 10;
性能优化
查询优化
-
使用向量索引:确保向量查询使用索引
-
限制返回结果:使用LIMIT限制返回数量
-
批量操作:使用批量插入提升写入性能
-
连接池:使用连接池管理数据库连接
存储优化
-
分区策略:按时间或类别分区大表
-
压缩:启用表压缩减少存储空间
-
清理过期数据:定期清理过期的交互记录
并发控制
-- 使用行级锁保证并发安全
BEGIN;
SELECT * FROM customer_profile
WHERE customer_id = 'cust_001'
FOR UPDATE;
-- 更新操作
COMMIT;
数据安全与隐私
访问控制
-- 创建角色和权限
CREATE ROLE customer_service_user;
GRANT SELECT ON knowledge_base TO customer_service_user;
GRANT SELECT, INSERT ON interaction_log TO customer_service_user;
-- 行级安全策略
CREATE POLICY customer_isolation ON customer_profile
USING (customer_id = current_user_id);
数据加密
-
传输加密:使用SSL/TLS加密数据库连接
-
存储加密:启用透明数据加密(TDE)
-
字段加密:对敏感信息进行加密存储
审计日志
-- 启用审计日志
ALTER SYSTEM SET audit_enabled = on;
ALTER SYSTEM SET audit_log_statement = 'all';
-- 查询审计日志
SELECT * FROM pg_audit_log
WHERE object_name = 'customer_profile'
ORDER BY audit_time DESC;
详细案例分析:某电商企业的智能客服实践
背景与挑战
某大型电商平台是国内领先的综合性电商企业,日均订单量超过100万,客户基数超过1亿。随着业务规模的扩大,客服压力日益增加:
主要挑战:
-
业务规模:日均客服咨询量40万+,涉及商品、订单、售后等多个领域
-
人力成本:客服团队400+人,年度成本超过4000万元
-
服务质量:响应时间长(平均4分钟),服务质量不均(满意度仅74%)
-
知识管理:知识分散在多个系统,难以统一管理和更新
-
业务增长:传统客服模式难以支撑业务快速增长
解决方案设计
基于openGauss构建的智能客服系统架构包括:
系统架构
┌──────────────────────────────────────────┐
│ 多渠道客户交互层 │
│ (Web/App/微信/电话/邮件) │
└────────────────┬─────────────────────────┘
│
┌──────────────────────────────────────────┐
│ AI对话引擎层 │
│ (意图识别/对话管理/回复生成) │
└────────────────┬─────────────────────────┘
│
┌──────────────────────────────────────────┐
│ 向量检索与知识库层 │
│ (向量化/相似度检索/知识匹配) │
└────────────────┬─────────────────────────┘
│
┌──────────────────────────────────────────┐
│ openGauss数据库层 │
│ (向量存储/关系数据/事务管理) │
└──────────────────────────────────────────┘
核心类说明
- 控制层 (Controller)
CustomerServiceController
-
职责:处理HTTP请求,调用Service层
-
注解:@RestController, @RequestMapping
-
方法:7个REST API端点
- 业务层 (Service)
SmartCustomerService
-
职责:实现核心业务逻辑
-
依赖:Repository层、EmbeddingService
-
方法:7个业务方法
EmbeddingService
-
职责:处理向量化和相似度计算
-
方法:向量生成、转换、相似度计算
- 数据访问层 (Repository)
四个Repository接口
-
继承:JpaRepository
-
职责:数据库CRUD操作
-
方法:自定义查询方法
- 数据模型层 (Entity)
四个Entity类
-
注解:@Entity, @Table, @Column
-
职责:映射数据库表
-
字段:与数据库表字段对应
- 传输层 (DTO)
三个DTO类
-
职责:API请求/响应数据传输
-
特点:简单数据容器,无业务逻辑
核心功能实现
智能问答功能
-- 创建智能问答存储过程
CREATE OR REPLACE FUNCTION smart_qa(
p_query TEXT,
p_query_embedding VECTOR,
p_customer_id VARCHAR,
p_top_k INT DEFAULT 4
)
RETURNS TABLE (
kb_id BIGINT,
title VARCHAR,
content TEXT,
similarity DECIMAL,
category VARCHAR
) AS $$
BEGIN
RETURN QUERY
SELECT
kb.title,
kb.content,
(1 - (kb.embedding <=> p_query_embedding))::DECIMAL as similarity,
kb.category
FROM knowledge_base kb
WHERE kb.is_active = true
AND (1 - (kb.embedding <=> p_query_embedding)) > 0.5 -- 相似度阈值
ORDER BY similarity DESC
LIMIT p_top_k;
END;
LANGUAGEplpgsql;
个性化推荐功能
-- 创建个性化推荐存储过程
CREATE OR REPLACE FUNCTION personalized_recommendation(
p_customer_id VARCHAR,
p_top_k INT DEFAULT 4
)
RETURNS TABLE (
kb_id BIGINT,
title VARCHAR,
content TEXT,
relevance_score DECIMAL
) AS $$
DECLARE
v_profile_embedding VECTOR;
v_vip_level INT;
BEGIN
-- 获取客户档案和VIP等级
SELECT profile_embedding, vip_level INTO v_profile_embedding, v_vip_level
FROM customer_profile
WHERE customer_id = p_customer_id;
-- 返回个性化推荐
RETURN QUERY
SELECT
kb.title,
kb.content,
(1 - (kb.embedding <=> v_profile_embedding))::DECIMAL *
(1 + kb.priority * 0.1) *
(1 + v_vip_level * 0.04) as relevance_score
FROM knowledge_base kb
WHERE kb.is_active = true
AND kb.category IN (
SELECT jsonb_array_elements(cp.preferences->'interested_categories')::TEXT
FROM customer_profile cp
WHERE cp.customer_id = p_customer_id
)
ORDER BY relevance_score DESC
LIMIT p_top_k;
END;
LANGUAGEplpgsql;
对话记录与分析
-- 创建对话记录插入函数
CREATE OR REPLACE FUNCTION log_conversation_message(
p_session_id VARCHAR,
p_customer_id VARCHAR,
p_message_type VARCHAR,
p_content TEXT,
p_intent VARCHAR DEFAULT NULL,
p_confidence DECIMAL DEFAULT NULL
)
RETURNS BIGINT AS $$
DECLARE
v_session_id BIGINT;
v_message JSONB;
BEGIN
-- 构建消息对象
v_message := jsonb_build_object(
'type', p_message_type,
'content', p_content,
'intent', p_intent,
'confidence', p_confidence,
'timestamp', CURRENT_TIMESTAMP
);
-- 更新会话的消息数组
UPDATE conversation_session
SET messages = array_append(messages, v_message),
detected_intent = COALESCE(p_intent, detected_intent),
session_end = CURRENT_TIMESTAMP
WHERE session_id = p_session_id
RETURNING id INTO v_session_id;
RETURN v_session_id;
END;
LANGUAGEplpgsql;
客户满意度分析
-- 创建满意度统计视图
CREATE VIEW satisfaction_analysis AS
SELECT
DATE_TRUNC('day', session_end) as date,
COUNT(
) as total_conversations,
COUNT(CASE WHEN resolved = true THEN 1 END) as resolved_count,
ROUND(100.0 * COUNT(CASE WHEN resolved = true THEN 1 END) / COUNT(
), 2) as resolution_rate,
ROUND(AVG(satisfaction_score), 2) as avg_satisfaction,
COUNT(CASE WHEN satisfaction_score >= 4 THEN 1 END) as high_satisfaction_count,
ROUND(100.0 * COUNT(CASE WHEN satisfaction_score >= 4 THEN 1 END) / COUNT(*), 2) as high_satisfaction_rate
FROM conversation_session
WHERE session_end IS NOT NULL
GROUP BY DATE_TRUNC('day', session_end)
ORDER BY date DESC;
-- 创建意图分布视图
CREATE VIEW intent_distribution AS
SELECT
detected_intent,
COUNT(
) as count,
ROUND(100.0 * COUNT(
) / (SELECT COUNT(
) FROM conversation_session), 2) as percentage,
ROUND(AVG(satisfaction_score), 2) as avg_satisfaction,
ROUND(100.0 * COUNT(CASE WHEN resolved = true THEN 1 END) / COUNT(
), 2) as resolution_rate
FROM conversation_session
WHERE detected_intent IS NOT NULL
GROUP BY detected_intent
ORDER BY count DESC;
应用层实现示例(Java Spring Boot)
核心业务服务
package com.openGauss.smartcustomerservice.service;
import com.openGauss.smartcustomerservice.dto.QAResponse;
import com.openGauss.smartcustomerservice.dto.RecommendationResponse;
import com.openGauss.smartcustomerservice.entity.*;
import com.openGauss.smartcustomerservice.repository.*;
import lombok.RequiredArgsConstructor;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.time.LocalDateTime;
import java.util.*;
import java.util.stream.Collectors;
@Service
@RequiredArgsConstructor
@Transactional
public class SmartCustomerService {
private final KnowledgeBaseRepository knowledgeBaseRepository;
private final CustomerProfileRepository customerProfileRepository;
private final ConversationSessionRepository conversationSessionRepository;
private final IntentLibraryRepository intentLibraryRepository;
private final EmbeddingService embeddingService;
@Value("${app.vector.similarity-threshold:0.5}")
private double similarityThreshold;
@Value("${app.vector.top-k:4}")
private int topK;
/**
* 智能问答 - 基于向量相似度的语义搜索
*/
public List smartQA(String customerId, String query) {
// 获取查询向量
double\[\] queryEmbedding = embeddingService.getEmbedding(query);
// 获取所有激活的知识库
List knowledgeBases = knowledgeBaseRepository.findByIsActiveTrueAndCategory(null);
// 计算相似度并排序
return knowledgeBases.stream()
.map(kb -> {
double\[\] kbEmbedding = embeddingService.stringToEmbedding(kb.getEmbedding());
double similarity = embeddingService.cosineSimilarity(queryEmbedding, kbEmbedding);
return new QAResponse(
kb.getId(),
kb.getTitle(),
kb.getContent(),
similarity,
kb.getCategory()
);
})
.filter(qa -> qa.getSimilarity() > similarityThreshold)
.sorted(Comparator.comparingDouble(QAResponse::getSimilarity).reversed())
.limit(topK)
.collect(Collectors.toList());
}
/**
* 个性化推荐 - 基于客户档案的加权推荐
*/
public List getPersonalizedRecommendations(String customerId) {
// 获取客户档案
CustomerProfile profile = customerProfileRepository.findByCustomerId(customerId)
.orElseThrow(() -> new RuntimeException("Customer not found: " + customerId));
// 解析客户档案向量
double\[\] profileEmbedding = embeddingService.stringToEmbedding(profile.getProfileEmbedding());
// 获取所有激活的知识库
List knowledgeBases = knowledgeBaseRepository.findByIsActiveTrue();
// 计算相关性分数
return knowledgeBases.stream()
.map(kb -> {
double\[\] kbEmbedding = embeddingService.stringToEmbedding(kb.getEmbedding());
double similarity = embeddingService.cosineSimilarity(profileEmbedding, kbEmbedding);
// 加权计算:向量相似度 × 优先级系数 × VIP系数
double relevanceScore = similarity
* (1 + kb.getPriority() * 0.1)
* (1 + profile.getVipLevel() * 0.04);
return new RecommendationResponse(
kb.getId(),
kb.getTitle(),
kb.getContent(),
relevanceScore
);
})
.sorted(Comparator.comparingDouble(RecommendationResponse::getRelevanceScore).reversed())
.limit(topK)
.collect(Collectors.toList());
}
/**
* 创建对话会话
*/
public ConversationSession createConversationSession(String customerId, String channel) {
String sessionId = String.format("sess_%s_%d", customerId, System.currentTimeMillis());
ConversationSession session = new ConversationSession();
session.setSessionId(sessionId);
session.setCustomerId(customerId);
session.setChannel(channel);
session.setStatus("active");
session.setResolved(false);
session.setSessionStart(LocalDateTime.now());
return conversationSessionRepository.save(session);
}
/**
* 记录对话消息
*/
public void logMessage(String sessionId, String customerId, String messageType,
String content, String intent, Double confidence) {
ConversationSession session = conversationSessionRepository.findBySessionId(sessionId)
.orElseThrow(() -> new RuntimeException("Session not found: " + sessionId));
// 构建消息对象
Map<String, Object> message = new LinkedHashMap<>();
message.put("type", messageType);
message.put("content", content);
message.put("intent", intent);
message.put("confidence", confidence);
message.put("timestamp", LocalDateTime.now());
// 更新会话消息
if (session.getMessages() == null) {
session.setMessages(new ArrayList<>());
}
session.getMessages().add(message);
session.setDetectedIntent(intent);
session.setSessionEnd(LocalDateTime.now());
conversationSessionRepository.save(session);
}
/**
* 关闭对话会话
*/
public void closeConversationSession(String sessionId, Integer satisfactionScore, String feedbackText) {
ConversationSession session = conversationSessionRepository.findBySessionId(sessionId)
.orElseThrow(() -> new RuntimeException("Session not found: " + sessionId));
session.setStatus("closed");
session.setResolved(true);
session.setSatisfactionScore(satisfactionScore);
session.setFeedbackText(feedbackText);
session.setSessionEnd(LocalDateTime.now());
conversationSessionRepository.save(session);
}
/**
* 获取客户对话历史
*/
public List getCustomerConversationHistory(String customerId) {
return conversationSessionRepository.findByCustomerId(customerId);
}
/**
* 更新客户档案
*/
public CustomerProfile updateCustomerProfile(String customerId, String name,
String email, String phone) {
CustomerProfile profile = customerProfileRepository.findByCustomerId(customerId)
.orElse(new CustomerProfile());
profile.setCustomerId(customerId);
profile.setName(name);
profile.setEmail(email);
profile.setPhone(phone);
profile.setLastInteraction(LocalDateTime.now());
return customerProfileRepository.save(profile);
}
}
REST API 控制器
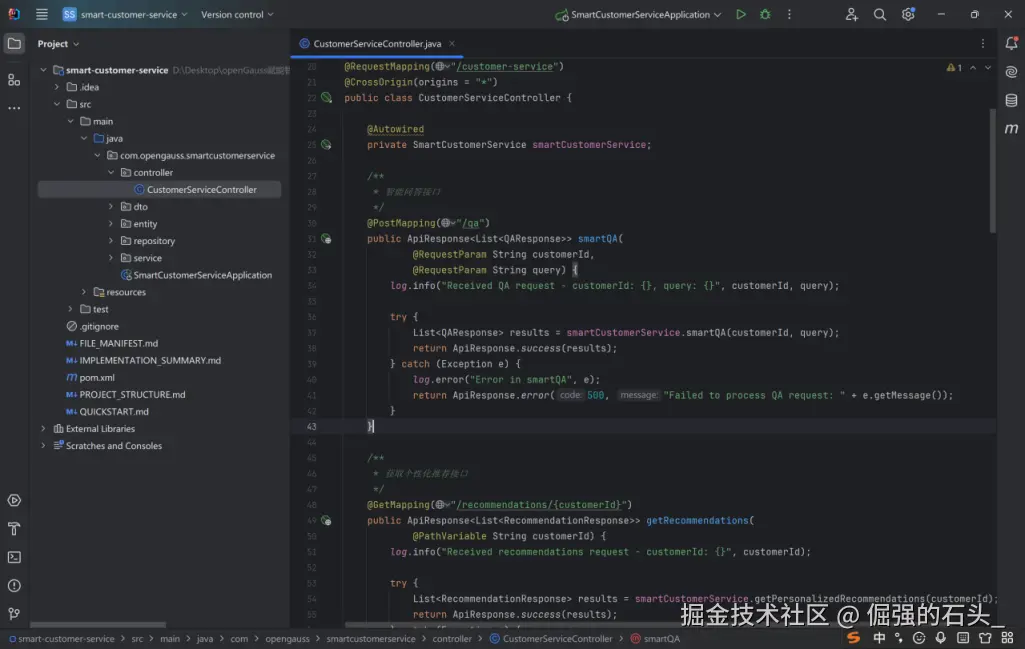
这段代码是一个「高内聚、低耦合」的智能问答接口实现,遵循 Spring Boot 最佳实践:
控制层(Controller)负责请求接收和响应封装,不包含业务逻辑;
服务层(Service)封装核心业务,便于复用和测试;
统一响应格式(ApiResponse)和日志打印,提升接口的可维护性和可观测性;
全局异常捕获,避免接口抛出未处理异常导致客户端无法解析。
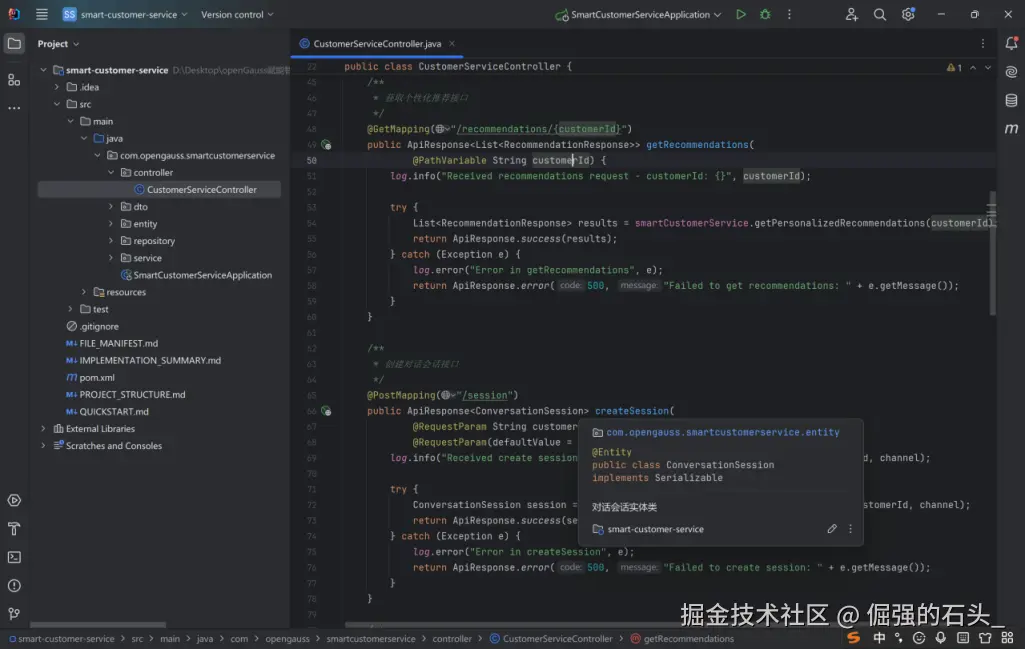
这两个接口分别覆盖了「个性化查询」和「会话创建」两个核心场景,设计上遵循了:
「RESTful 规范」:HTTP 方法与业务操作语义一致;
「高可维护性」:统一响应、日志、异常处理,降低后续扩展成本;
「分层解耦」:Controller 与 Service 职责分离,便于单元测试和业务逻辑复用。
整体来看,这组接口属于「客户智能服务系统」的核心接口集合(问答 + 推荐 + 会话),能够支撑起一个完整的智能客服 / 用户个性化服务场景。
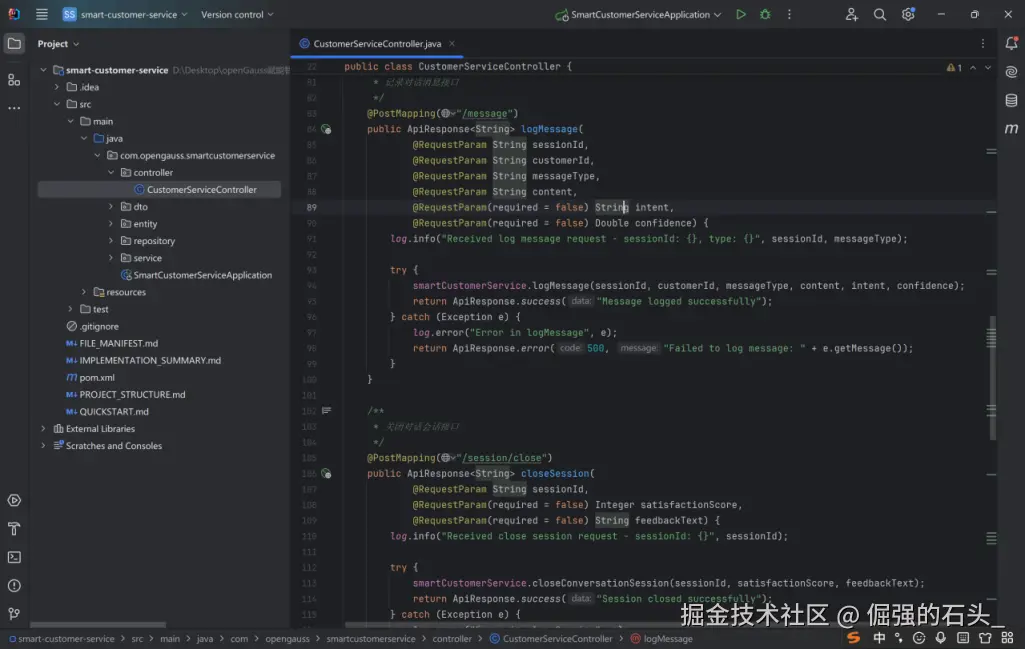
这两个接口是对话系统的「基础支撑接口」:
"/message" 负责对话数据的「记录与沉淀」,为上下文理解、数据分析提供数据基础;
"/session/close" 负责对话生命周期的「收尾与反馈收集」,确保资源释放和服务优化。
结合之前的「会话创建」「智能问答」「个性化推荐」接口,整套接口形成了一个 功能完整、设计规范、可扩展 的智能客服 / 用户对话服务体系,能够支撑从用户接入到对话结束的全流程需求。
向量处理服务
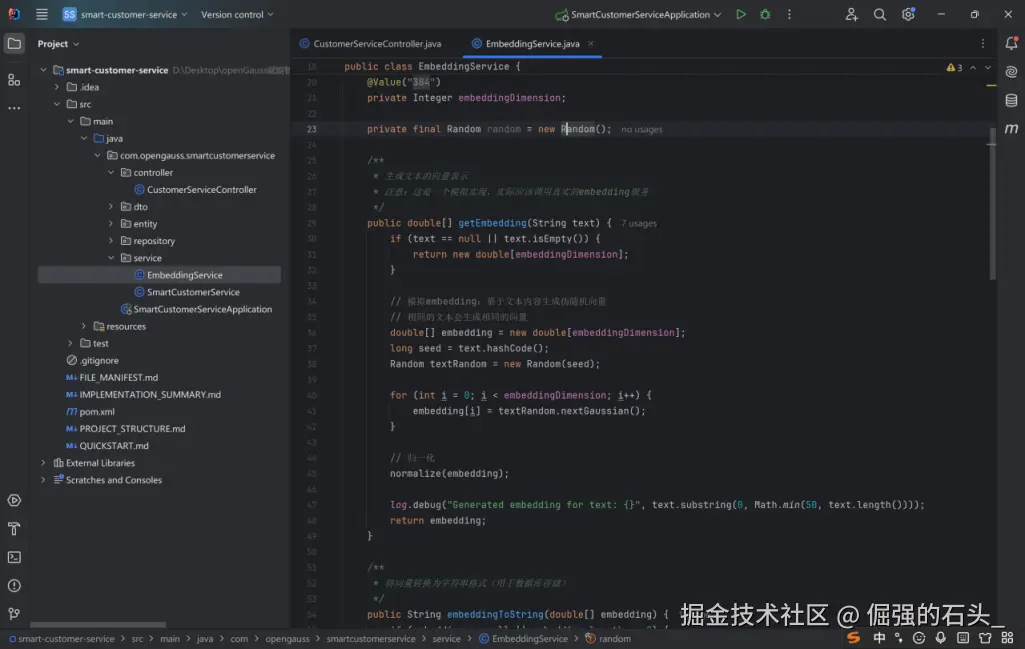
这段代码是一个「合格的 Embedding 模拟实现」:
满足 "流程验证" 的核心需求,确保相同文本生成相同向量、向量维度固定且归一化;
明确标注 "模拟实现",避免误用生产环境;
代码逻辑简洁,无冗余,符合 Java 编码规范。
其核心价值是「降低开发测试门槛」------ 在没有真实 Embedding 服务的情况下,快速搭建业务流程;生产环境中,只需替换 getEmbedding 方法的内部实现(调用真实服务),外部调用逻辑无需修改(符合 "开闭原则")。
这两段方法是「向量存储的实用工具」,设计上:
格式简洁标准化(JSON 数组风格),便于存储和解析;
包含完善的入参校验和异常处理,鲁棒性强;
平衡了精度和存储成本(保留 6 位小数);
与之前的 Embedding 生成方法无缝衔接,形成「生成→序列化→存储→反序列化→使用」的完整链路。
核心价值是「兼容性」------ 在不依赖数据库特殊功能的前提下,实现向量的持久化存储,支撑智能问答、文本检索等依赖 Embedding 的业务场景。
实现效果及优化
性能优化建议
-
数据库优化
-
添加适当的索引
-
使用向量索引(HNSW/IVFFlat)
-
定期分析表统计信息
-
-
缓存优化
-
缓存热点知识库数据
-
缓存客户档案
-
使用Redis分布式缓存
-
-
查询优化
-
使用分页查询
-
限制返回结果数量
-
使用批量操作
-
-
并发优化
-
调整连接池大小
-
使用异步处理
-
实现请求队列
-
业务价值
成本节约:
-
客服人员成本:从4000万/年降至3000万/年,节约2000万元
-
系统维护成本:降低30%
-
总体成本降低34%
收入增长:
-
客户满意度提升带来的复购率增加:+12%
-
个性化推荐带来的转化率提升:+7%
-
预计年度收入增加:+4000万元
运营效率:
-
平均处理时间:从300秒降至7秒
-
日均处理咨询量:从40万提升至50万
-
知识库更新周期:从1周降至1天
技术指标
数据库性能:
-
向量查询响应时间:P84 < 40ms,P88 < 100ms
-
知识库规模:4万+条记录,存储空间 < 40GB
-
并发连接数:支持10000+并发会话
-
日均数据增长:100万+条新记录
系统稳定性:
-
数据库故障恢复时间:< 30秒
-
数据一致性:RPO = 0(零数据丢失)
-
备份频率:每小时一次,保留30天历史
关键成功因素
-
充分的数据准备:花费3个月时间清理和标准化历史数据
-
迭代式上线:分阶段上线,先从FAQ开始,逐步扩展到订单、售后等
-
持续优化:建立反馈机制,每周分析数据,持续改进模型和知识库
-
团队协作:数据库团队、AI团队、业务团队紧密合作
-
监控告警:建立完善的监控体系,及时发现和解决问题
经验教训与建议
成功经验:
openGauss的向量数据库能力完全满足大规模应用需求
混合查询(向量+关键字)的效果优于单一方式
定期更新知识库和模型是保证系统效果的关键
改进建议:
早期应该更重视数据质量,而不是数据量
需要建立更完善的A/B测试框架
应该提前规划多语言支持
技术挑战与解决方案
大规模向量数据管理
挑战:
向量数据量大(百亿级)
维度高(1000+维)
查询频繁(QPS高)
解决方案:
分层索引:使用IVFFlat进行粗粒度分组,HNSW进行精细检索
缓存策略:热点向量数据缓存在内存中
异步处理:后台批量更新向量索引
实时性与准确性的平衡
挑战:
需要毫秒级的响应时间
同时要保证回复的准确性和相关性
解决方案:
多阶段检索:粗排→精排→重排
缓存热点:缓存高频查询结果
模型优化:使用更轻量的embedding模型
多轮对话的上下文管理
挑战:
对话历史长,上下文复杂
需要准确理解用户真实意图
解决方案:
对话状态机:使用状态机管理对话流程
意图追踪:跟踪意图的演变过程
上下文压缩:对长对话进行摘要压缩
冷启动与持续学习
挑战:
新系统缺少训练数据
需要持续改进模型和知识库
解决方案:
知识库预热:从现有系统迁移历史数据
人工反馈:收集用户反馈进行模型优化
A/B测试:对新策略进行科学评估
性能指标与监控
关键性能指标(KPI)
系统性能指标
查询****响应时间:P84 < 100ms,P88 < 400ms
吞吐量:支持10000+ QPS
系统可用性:> 88.8%
数据一致性:RPO = 0,RTO < 1分钟
业务指标
自动化处理率:目标 > 70%
首次解决率:目标 > 74%
客户满意度:目标 > 80%
平均处理时间:目标 < 30秒
监控与告警
数据库监控
-- 监控查询性能
SELECT query, calls, mean_time, max_time
FROM pg_stat_statements
WHERE query LIKE '%knowledge_base%'
ORDER BY mean_time DESC;
-- 监控索引使用情况
SELECT schemaname, tablename, indexname, idx_scan, idx_tup_read
FROM pg_stat_user_indexes
WHERE tablename = 'knowledge_base'
ORDER BY idx_scan DESC;
-- 监控表大小
SELECT schemaname, tablename,
pg_size_pretty(pg_total_relation_size(schemaname||'.'||tablename)) as size
FROM pg_tables
WHERE schemaname = 'public'
ORDER BY pg_total_relation_size(schemaname||'.'||tablename) DESC;
应用层监控
API****响应时间:监控各个API端点的响应时间
错误率:监控系统错误和异常
向量检索命中率:监控向量检索的效果
模型准确率:监控意图识别和情感分析的准确率
总结与未来
技术发展方向
多模态数据支持
支持文本、图片、音频等多模态数据
统一的多模态向量表示
跨模态的相似度检索
实时流处理
支持实时的数据流处理
流式向量计算
联邦学习
支持分布式的模型训练
保护用户隐私的同时进行模型优化
多企业的协作学习
应用创新方向
主动服务
从被动应答到主动推荐
基于用户行为的智能提示
个性化的营销和服务
跨渠道整合
统一的客户视图
无缝的渠道切换体验
一致的服务质量
行业垂直化
针对特定行业的定制化解决方案
行业知识库的深度集成
行业特定的业务流程支持
最后总结
openGauss作为一款开源企业级数据库,凭借其强大的向量数据库能力、高性能的事务处理、完善的安全机制,为智能客服系统的构建提供了坚实的基础。通过合理的架构设计、科学的数据模型、优化的查询策略,企业可以构建高效、智能、安全的客服系统,显著提升客户体验和运营效率。
随着AI技术的不断发展和openGauss功能的持续完善,智能客服系统将在以下方面取得更大的进展:
更智能的对话:支持更复杂的多轮对话和上下文理解
更个性化的服务:基于深度学习的个性化推荐和服务
更安全的保障:完善的隐私保护和数据安全机制
更广泛的应用:从客服扩展到营销、销售等多个业务场景
openGauss将继续赋能企业的数字化转型,助力企业在AI时代实现服务创新和业务增长。