泛型中KTVE?Object等分别代表什么含义?
其实这些字母本身没什么具体的限制,都能用,但是我们一般约定的含义就是:
E:元素(一般在集合中使用)
K:key
V:value
T:type
N:number(数值类型)
Object:表示可以接受任何对象类型
泛型中上下界限定符extends和super有什么区别?
上界限定符:<T extends Car>
public class Text <T extends Car> {
}
public static void main(String[] args) {
Text<Car> carText = new Text<>();
Text<BaoMa> baoMaText = new Text<>();
Text<BenChi> benChiText = new Text<>();
Text<Integer> integerText = new Text<Integer>(); // 报错,因为限定了类型比如是Car或Car的子类
}上界限定符就是限定到时候调用方使用的时候传入的类型比如是在指定的类型或它的子类中选择
下界限定符:<? super Car>
void t(List<? super Car> list){}下界限定符就是限制类型比如是指定的这个和它的父类直到Object
如何理解Java中的多态?
我的理解是同一操作可以有不同实现,从而产生不同效果
比如最常见的就是List,List本身是一个接口,但是具体的底层实现和操作取决于我们后面new的是什么,比如ArrayList或是被LinkedList
满足多态的条件:
- 有类继承或者接口实现。
- 子类要重写父类的方法。
- 父类的引用指向子类的对象。
此外像重写就是一种多态,个人认为多态是一种动态特征,也就是应该是实际运行时才决定决定采用具体的实现方式,当然有些人认为重载也是一种静态多态,对此我并不认可。
如何理解面向对象和面向过程?
面向过程是像C语言这种,面向对象则是像Java这种
- 面向过程是拿到一个问题之后,进行拆解成一个一个的步骤,然后编写成一个一个的方法来实现
- 面对对象同样是对问题进行拆解,但是它会抽离出一个个角色,让每一个角色单独做好自己的事情就行,通过调用不同的角色来完成整个任务
面向过程的特点就是开发简单,但是也带来了难维护的特点;而面向对象则是设计比较难,但是好维护
什么是AIO、BIO和NIO?
BIO:同步阻塞,用户线程发起IO请求之后需要等待IO响应
NIO:同步非阻塞,用户线程发起IO请求之后可以干别的事,直到IO响应才去处理,无需等待
AIO:异步非阻塞,用户发起IO请求之后,可以直接结束,IO响应回来之后,会有其他线程通过调用注册的监听方法进行返回
BIO适合早期的产品或是连接数量少的产品
NIO适合连接数量多,但是都是短链接(轻量级操作)的场景,比较聊天服务
AIO适合连接数量多,但是偏向于长连接(重量级操作)的场景
什么是SPI,和API有啥区别?
API是定义的一组接口,主要是给开发人员调用的
SPI其实可以理解为一种扩展机制,主要是提供可插拔式的扩展方式,主要是给需要对框架进行扩展的人员使用的
总结: API用于定义调用接口,而SPI用于定义和提供可插拔的实现方式。
实现SPI的方式:
-
定义接口和实现类:
public interface IShout {
void shout();
}
public class Cat implements IShout {
@Override
public void shout() {
System.out.println("miao miao");
}
}
public class Dog implements IShout {
@Override
public void shout() {
System.out.println("wang wang");
}
} -
在 src/main/resources/ 下建立 /META-INF/services 目录, 新增一个以接口命名的文件 (org.foo.demo.IShout文件),内容是要加载的类
org.foo.demo.animal.Dog
org.foo.demo.animal.Cat -
通过ServiceLoader.load来加载配置文件
public class SPIMain {
public static void main(String[] args) {
ServiceLoadershouts = ServiceLoader.load(IShout.class);
for (IShout s : shouts) {
s.shout();
}
}
}
什么是UUID,能保证唯一吗?
就是全局唯一标识符,或者可以理解为用来生成全局唯一标识的工具
本质是基于:MAC+时间戳+随机数等参数生成的,能在一定的程度上保证唯一,但是要看具体的版本
v1、v2:基于时间戳+MAC+随机数,在不出现机器时间回拨的前提下能保证全球唯一,但是因为使用了MAC,带来了一定的安全隐患
v3、v5:基于名称空间进行哈希运算,在一定的范围内具有唯一性
v4:只基于随机数,可能会出现重复,适合并发不高的场景(同时也是jdk17默认的)
什么是反射机制?为什么反射慢?
-
反射是Java提供的一个工具,能在运行时获取某一个类的信息,包括:
判断一个对象所属类 -
类的信息,例如:字段、属性之类的(包括私有)
-
构造类的对象
-
调用类的方法
public class Main {
public static void main(String[] args) throws InvocationTargetException, IllegalAccessException, InstantiationException {
// 判断任意一个对象所属类
Dog dog = new Dog();
System.out.println(dog.getClass()); //class main.Service.impl.Dog// 拿到里面的字段和方法 //[public void main.Service.impl.Dog.shout(), public final void java.lang.Object.wait(long,int) throws java.lang.InterruptedException, public final void java.lang.Object.wait() throws java.lang.InterruptedException, public final native void java.lang.Object.wait(long) throws java.lang.InterruptedException, public boolean java.lang.Object.equals(java.lang.Object), public java.lang.String java.lang.Object.toString(), public native int java.lang.Object.hashCode(), public final native java.lang.Class java.lang.Object.getClass(), public final native void java.lang.Object.notify(), public final native void java.lang.Object.notifyAll()] //[private int main.Service.impl.Dog.a, private java.lang.String main.Service.impl.Dog.b] Method[] methods = Dog.class.getMethods(); Field[] declaredFields = Dog.class.getDeclaredFields(); System.out.println(Arrays.toString(methods)); System.out.println(Arrays.toString(declaredFields)); // 调用方法,这里第一个参数要传递这个方法属于的那个类的实例对象 methods[0].invoke(dog); // 创建对象 Dog newDog = Dog.class.newInstance(); System.out.println(newDog); }}
反射的优点就是:灵活性和可拓展性
但是却破坏了封装性,并且会比较慢
慢的原因就是因为需要动态解析类型,这个过程没办法使用虚拟机优化;其次就是这个过程涉及到封装成Object再解析
什么是泛型?有什么好处?
泛型就是一个语法糖,为了让代码能支持更多的数据类型,通过泛型进行代替,等到具体调用时才指定真正的类型
好处:
- 提高了拓展性,一份代码可以适应多种数据类型
- 提高安全性,泛型的作用就是编译阶段对具体类型进行检查,避免在运行阶段需要对Object转化的时候出错
什么是类型擦除?
类型擦除其实就是将泛型信息删除掉,将泛型代码转化成普通代码,在Java里面则是直接编译成普通字节码
public class Foo<T> {
T bar;
void doSth(T param) {
}
};
擦除后:
public class Foo {
Object bar;
void doSth(Object param) {
}
};可以理解为泛型这个语法糖只存在于编译解阶段,就是说编译阶段会对元素类型进行检查,这个时候泛型就会生效,然后编译完成之后就变成普通的字节码了
什么是深拷贝和浅拷贝?
深拷贝和浅拷贝的区分其实是指进行对象拷贝的时候遇到引用类型的属性,是只拷贝旧引用,还是直接复制一份这个对象,并替换成对应的引用
浅拷贝:
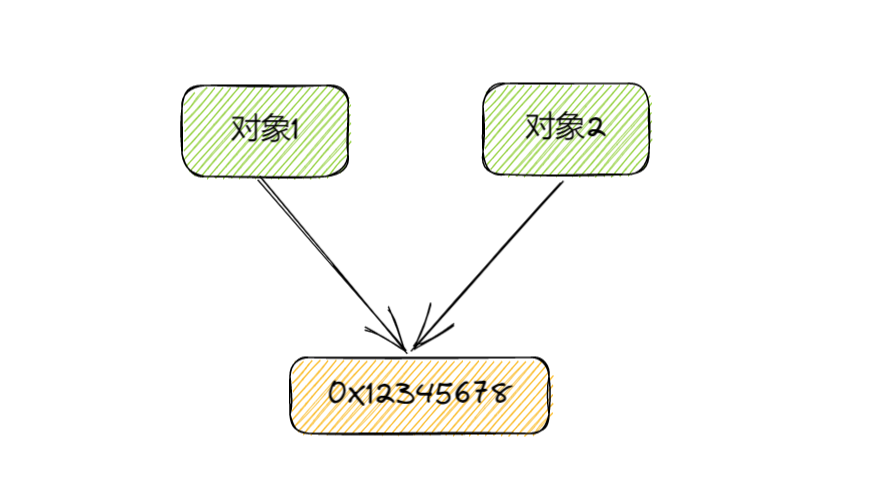
如果对引用类型的属性进行修改会影响旧对象
深拷贝:
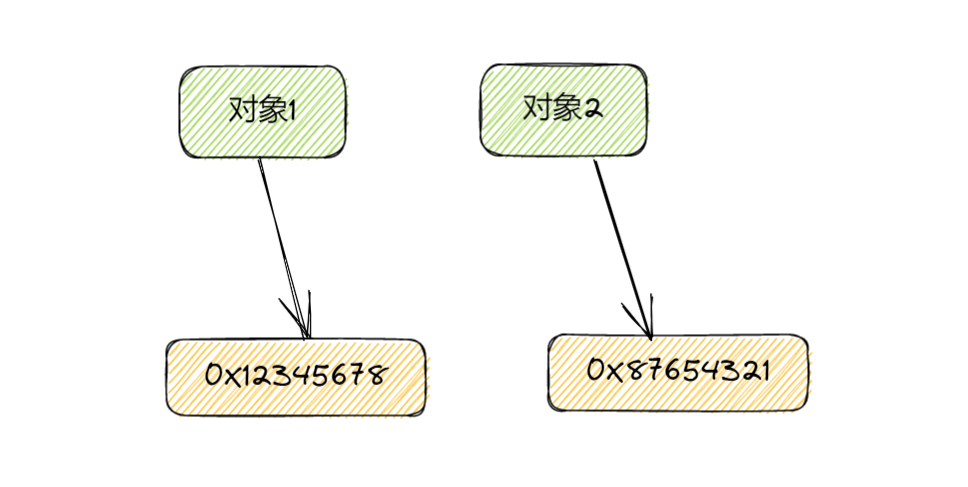
这个就完全拷贝一份新的出来了
常用的BeanUtils.copyProperties(source, t);其实也是浅拷贝
如果要实现深拷贝,可以使用下面的方式
方式1:自己定义clone() 的逻辑,手动的拷贝引用类型的属性
public class Address implements Cloneable{
private String province;
private String city;
private String area;
//省略构造函数和setter/getter
@Override
public Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
class User implements Cloneable{
private String name;
private String password;
private Address address;
//省略构造函数和setter/getter
@Override
protected Object clone() throws CloneNotSupportedException {
User user = (User)super.clone();
user.setAddress((Address)address.clone());
return user;
}
}方式2:使用序列化+反序列化,常用的就是FastJSON
User newUser = JSON.parseObject(JSON.toJSONString(user), User.class);说几个常见的语法糖?
switch 对字符串的支持
public static void main(String[] args) throws InvocationTargetException, IllegalAccessException, InstantiationException {
String str = "222";
switch (str) {
case "111" :
System.out.println("aaa");
break;
case "222" :
System.out.println("bbb");
break;
case "333" :
System.out.println("ccc");
break;
}
}泛型
public static <T> T convert(Object source, Class<T> targetClass) {
if (source == null) {
return null;
}
T t = newInstance(targetClass);
BeanUtils.copyProperties(source, t);
return t;
}自动装箱和拆箱
public static void main(String[] args) throws InvocationTargetException, IllegalAccessException, InstantiationException {
int a = 1;
Integer b = a;
}可变参数
public class Main {
public static void main(String[] args) throws InvocationTargetException, IllegalAccessException, InstantiationException {
t(1, 2, 3, 4);
}
static void t(int... a) {
for (int i : a) {
System.out.print(i + " "); //1 2 3 4
}
}
}其实底层就是一个数组,编译之后会变成 int\[\] a 作为形参
ambda
public static void main(String[] args) throws InvocationTargetException, IllegalAccessException, InstantiationException {
int[][] arr = new int[][]{{1, 2}, {3, 1}, {1, 2}};
Arrays.sort(arr, (a, b) -> a[0] - b[0]);
}增强for循环
int[][] arr = new int[][]{{1, 2}, {3, 1}, {1, 2}};
for (int[] a : arr) {
System.out.println(Arrays.toString(a));
}为什么Java中的main方法必须是public static void的?
为什么要设置为public?
因为JVM需要调用它,所以需要设置为public才能调用到
为什么要设置成static?
因为main方法的调用并不依赖于Main类或是其他什么类的实例对象,那这个时候就必需把它提前到类加载的时候就创建这个方法,否则无法调用,这样就能直接通过类名进行调用了
为什么要设置成void?
比较靠谱的解释是JVM的退出不依赖于main,所以不需要接收它的返回值
为什么形参部分要用String\[\] args?
因为可以从命令行传入参数,但是这个参数个数是没有限制的