1 引言:向量数据的时代背景
随着人工智能、物联网、金融风控等业务的快速发展,非结构化数据(如图像、语音、文本、行为序列)已成为企业数据的主体。如何高效存储、检索和分析这类数据,成为现代数据库系统面临的重大挑战。
向量数据库 应运而生,它专门用于处理高维向量数据,支持高效的相似性搜索、聚类、分类等操作。openGauss 作为企业级关系型数据库,不仅在传统 OLTP/OLAP 场景中表现出色,也通过 DataVec 向量化执行引擎 和 DB4AI 库内人工智能引擎,实现了对向量数据的原生支持与高效处理。
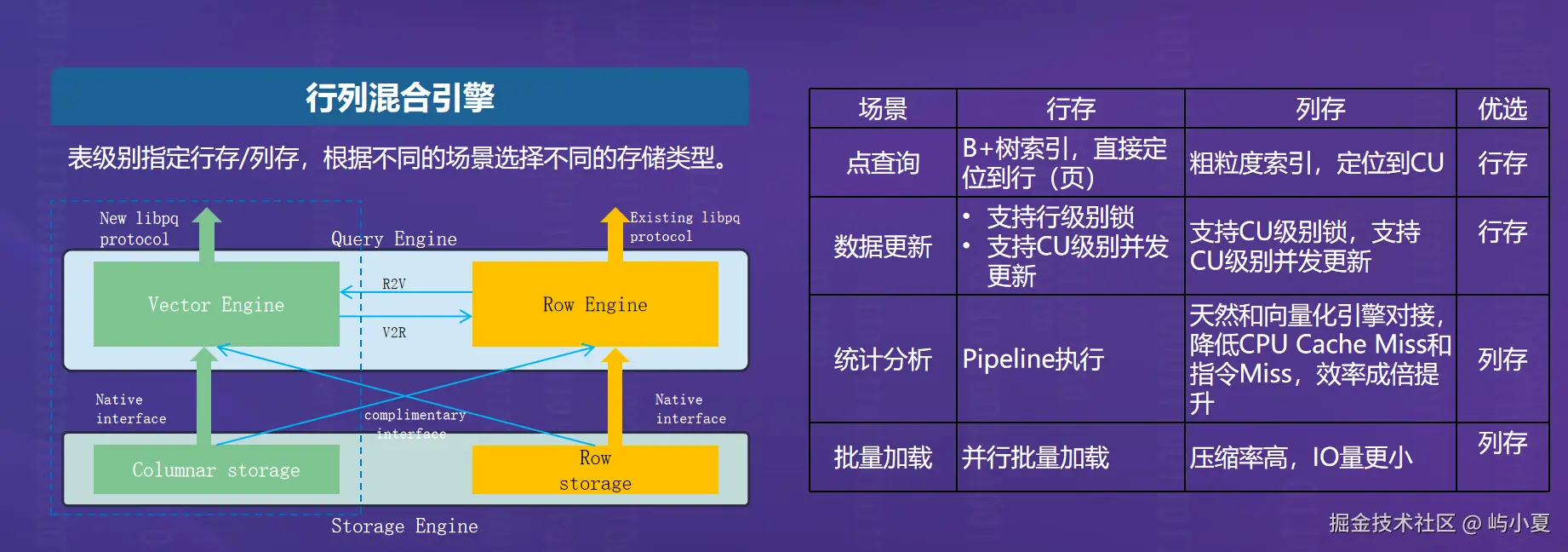
2 openGauss 向量数据处理架构
2.1 行列混合存储引擎
openGauss 支持行存与列存两种存储模式,用户可根据业务特征灵活选择:
行存:适用于高并发的事务处理(OLTP),如订单、交易;
列存:适用于分析型查询(OLAP),如风控分析、用户画像;
行列混合:支持同一数据库中不同表采用不同存储方式,甚至同一查询中关联行列表。
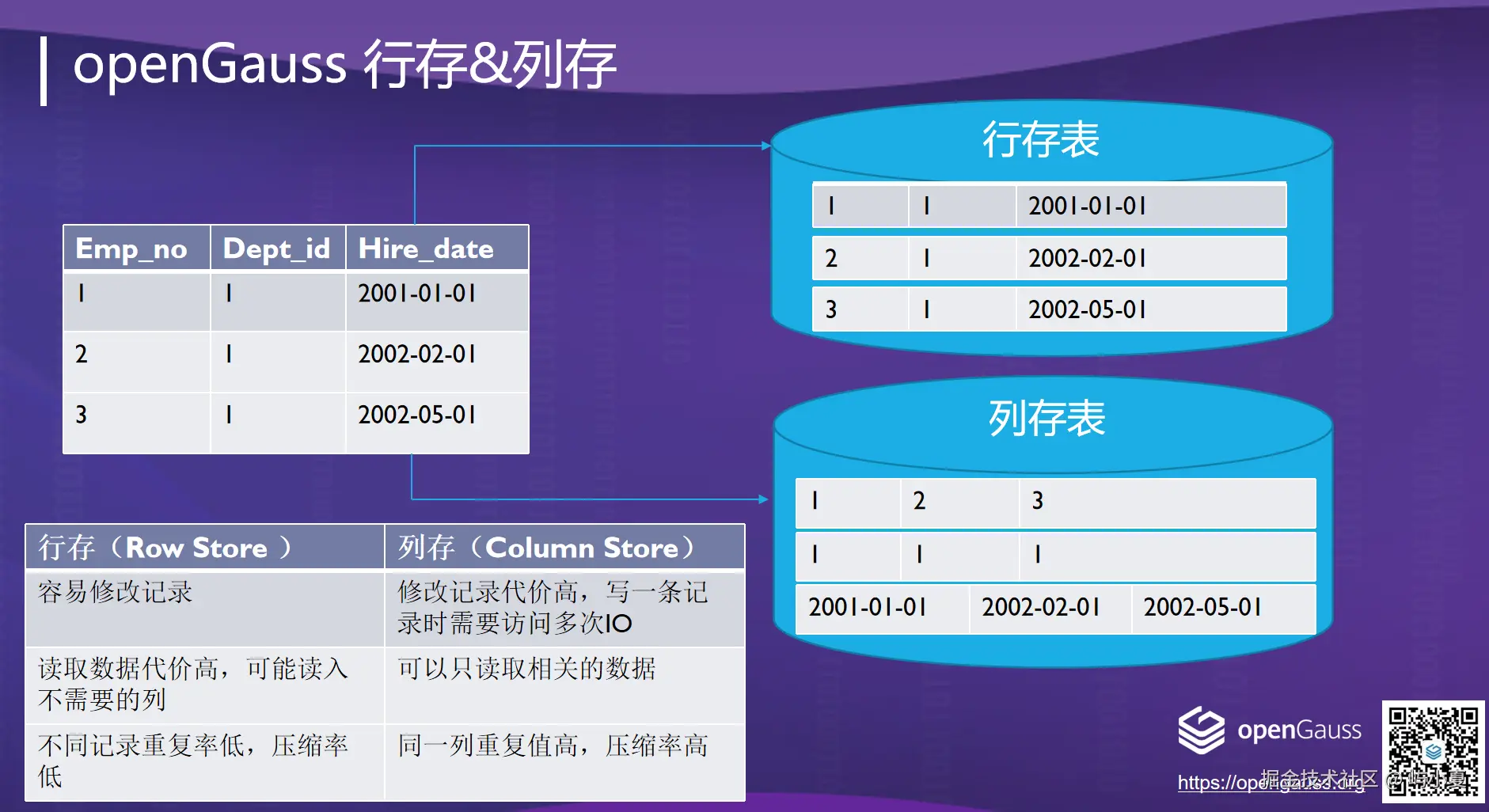
代码示例:创建行列混合存储表
markdown
-- 创建行存表
CREATE TABLE user_transactions (
user_id BIGINT,
transaction_time TIMESTAMP,
amount DECIMAL(10,2),
merchant_id INT
) WITH (ORIENTATION = ROW);
-- 创建列存表
CREATE TABLE user_profiles (
user_id BIGINT,
profile_vector FLOAT8[], -- 用户特征向量
last_updated TIMESTAMP
) WITH (ORIENTATION = COLUMN);
-- 创建行列混合查询
SELECT ut.user_id, ut.amount, up.profile_vector
FROM user_transactions ut -- 行存表
JOIN user_profiles up ON ut.user_id = up.user_id -- 列存表
WHERE ut.transaction_time > NOW() - INTERVAL '1 day';
2.2 向量化执行器
执行器是向量化技术的核心。它与传统行式执行器的对比如下:
| 特性 | 传统行式执行器 | openGauss 向量化执行器 |
|---|---|---|
| 处理单元 | 单行元祖 | 一批列向量(通常包括100-1000行) |
| 函数调用 | 每次多次函数调用 | 每批一次函数调用,摊销开销 |
| CPU 利用 | 指令流水线效率低 | SIMD 指令集,单指令处理多数据 |
| 缓存 locality | 差,访问模式随机 | 好,连续访问同一列数据 |
向量化执行的流程可以概括为:
- 扫描:从列存表中读入数据,形成多个列向量组成的批次。
- 计算:执行器算子(如过滤、聚合、连接)对整个向量批次进行操作。
- 物化:将最终结果批量输出或传递给下一个算子。
代码示例:体验向量化执行的优势
markdown
-- 列存表
CREATE TABLE sensor_data (
sensor_id INT,
timestamp TIMESTAMP,
temperature FLOAT8[],
pressure FLOAT8[],
vibration FLOAT8[]
) WITH (ORIENTATION = COLUMN);
-- 向量化查询
SELECT sensor_id, timestamp
FROM sensor_data
WHERE vector_norm(temperature) > 100.0 -- 向量范数计算
OR vector_distance(pressure, ARRAY[101.3, 101.3, 101.3]) < 1.0;
-- 传统行式处理
-- SELECT sensor_id, timestamp
-- FROM sensor_data
-- WHERE temperature[1] > 100 OR temperature[2] > 100 OR temperature[3] > 100;
3 openGauss 向量数据库核心技术详解
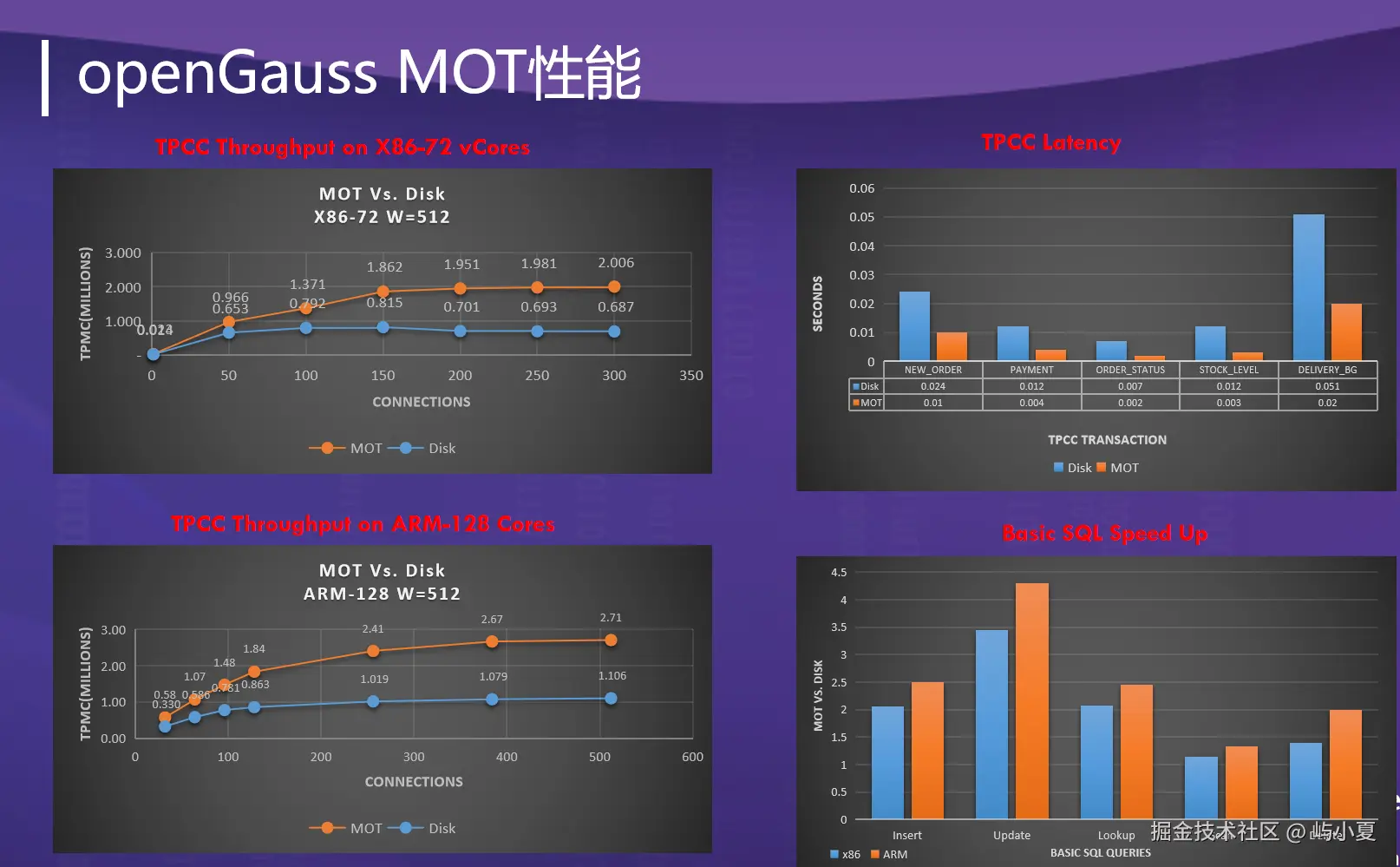
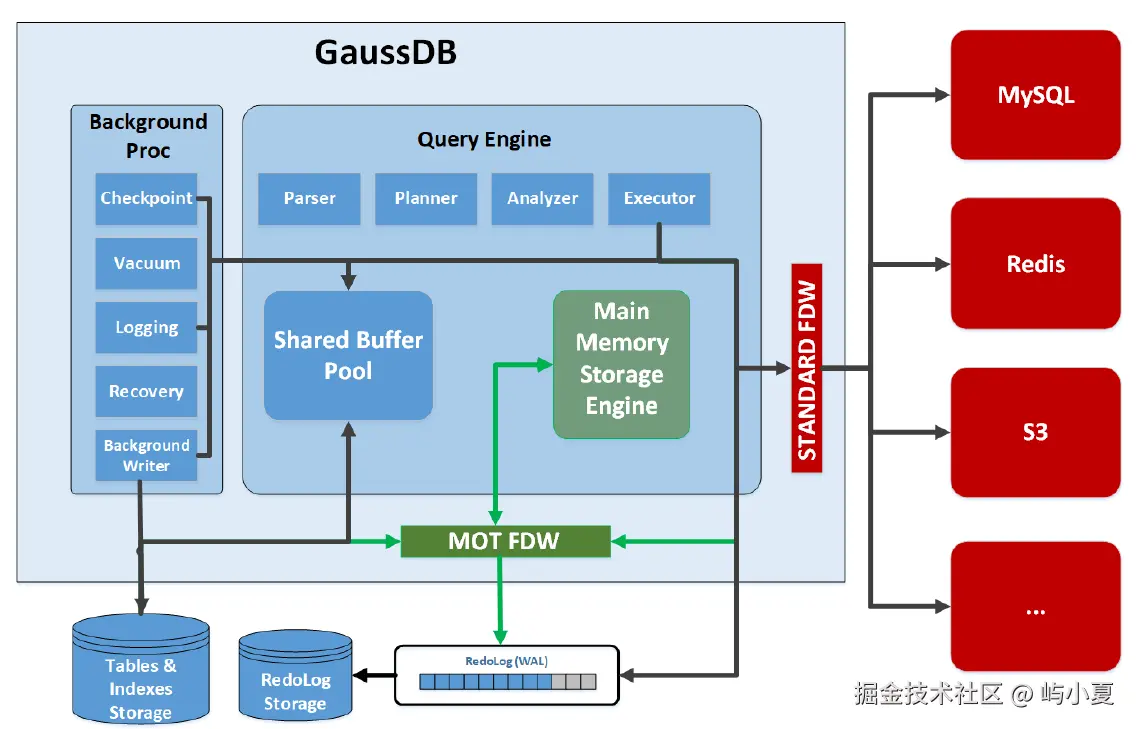
3.1 内存优化表(MOT)与向量加速
openGauss 的 MOT(Memory-Optimized Table) 是一种全内存、无锁的存储引擎,特别适合高并发、低延迟的向量检索场景:
无锁索引:使用 Masstree、Bw-Tree 等结构,避免锁竞争;
NUMA 感知:数据分区与线程绑核,减少跨NUMA节点访问;
向量化扫描:结合DataVec,实现高速向量过滤与投影。
代码示例:创建内存优化表处理实时向量数据
markdown
-- 创建内存优化表
CREATE FOREIGN TABLE real_time_vectors (
vector_id BIGINT,
embedding FLOAT8[], -- 向量嵌入数据
category VARCHAR(50),
created_time TIMESTAMP
) SERVER mot_server;
-- 创建向量索引
-- CREATE INDEX idx_vector_similarity ON real_time_vectors
-- USING ivfflat (embedding) WITH (lists = 100);
-- 高频向量相似度查询
SELECT vector_id, category,
vector_distance(embedding, ARRAY[0.1, 0.2, 0.3, 0.4]) as dist
FROM real_time_vectors
WHERE category = 'image'
ORDER BY dist ASC
LIMIT 10;
3.2 库内AI引擎(DB4AI)
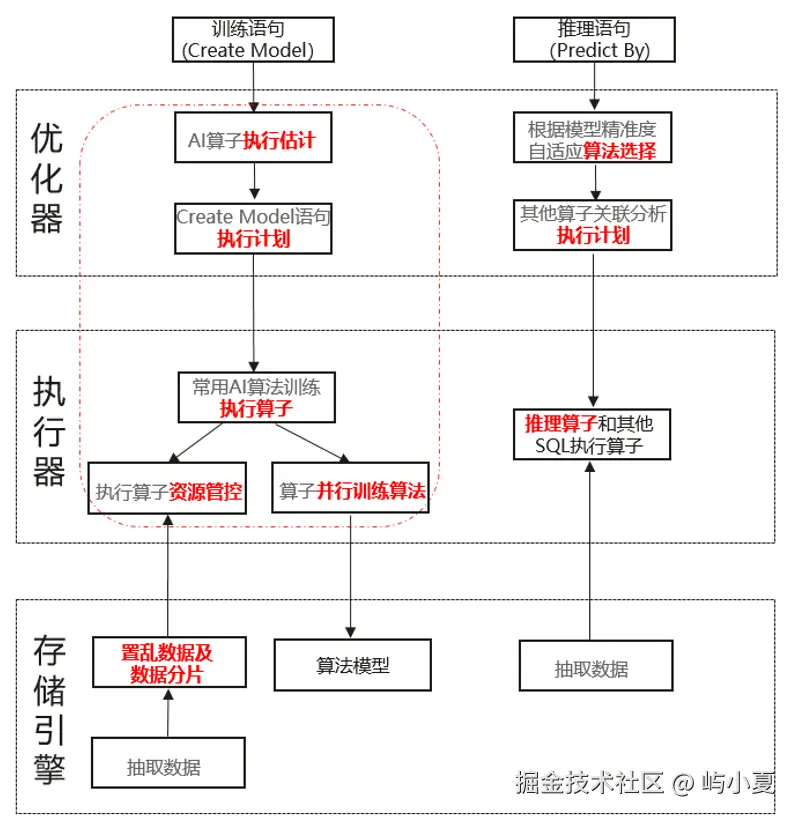
openGauss 的 DB4AI 允许用户在数据库内直接进行机器学习训练与推理,无需导出数据:
SQL接口训练模型:使用 CREATE MODEL 语句训练分类、回归、聚类模型;
向量化特征处理:支持归一化、分桶、特征交叉等预处理;
异构计算支持:可调用 Ascend、GPU 等硬件加速推理。
代码示例:使用DB4AI进行向量数据训练和推理
markdown
-- 准备数据
CREATE TABLE user_behavior_training (
user_id INT,
behavior_vector FLOAT8[], -- 用户行为特征向量
will_churn BOOLEAN -- 是否流失标签
);
CREATE MODEL churn_prediction_model
USING logistic_regression
FEATURES behavior_vector
TARGET will_churn
FROM user_behavior_training;
SELECT user_id,
PREDICT BY churn_prediction_model(FEATURES behavior_vector) as churn_prob,
behavior_vector
FROM current_user_behavior
WHERE last_active_time > NOW() - INTERVAL '1 hour';
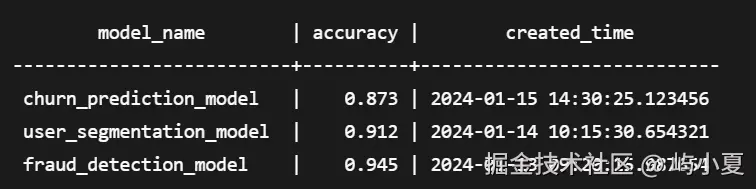
SELECT model_name, accuracy, created_time
FROM gs_model_warehouse;
DROP MODEL churn_prediction_model;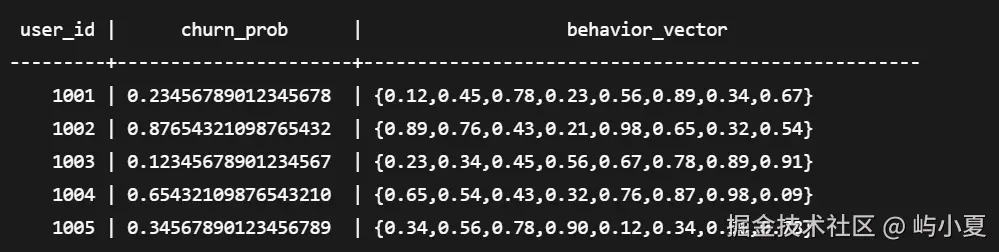
3.3 向量数据的加密与安全
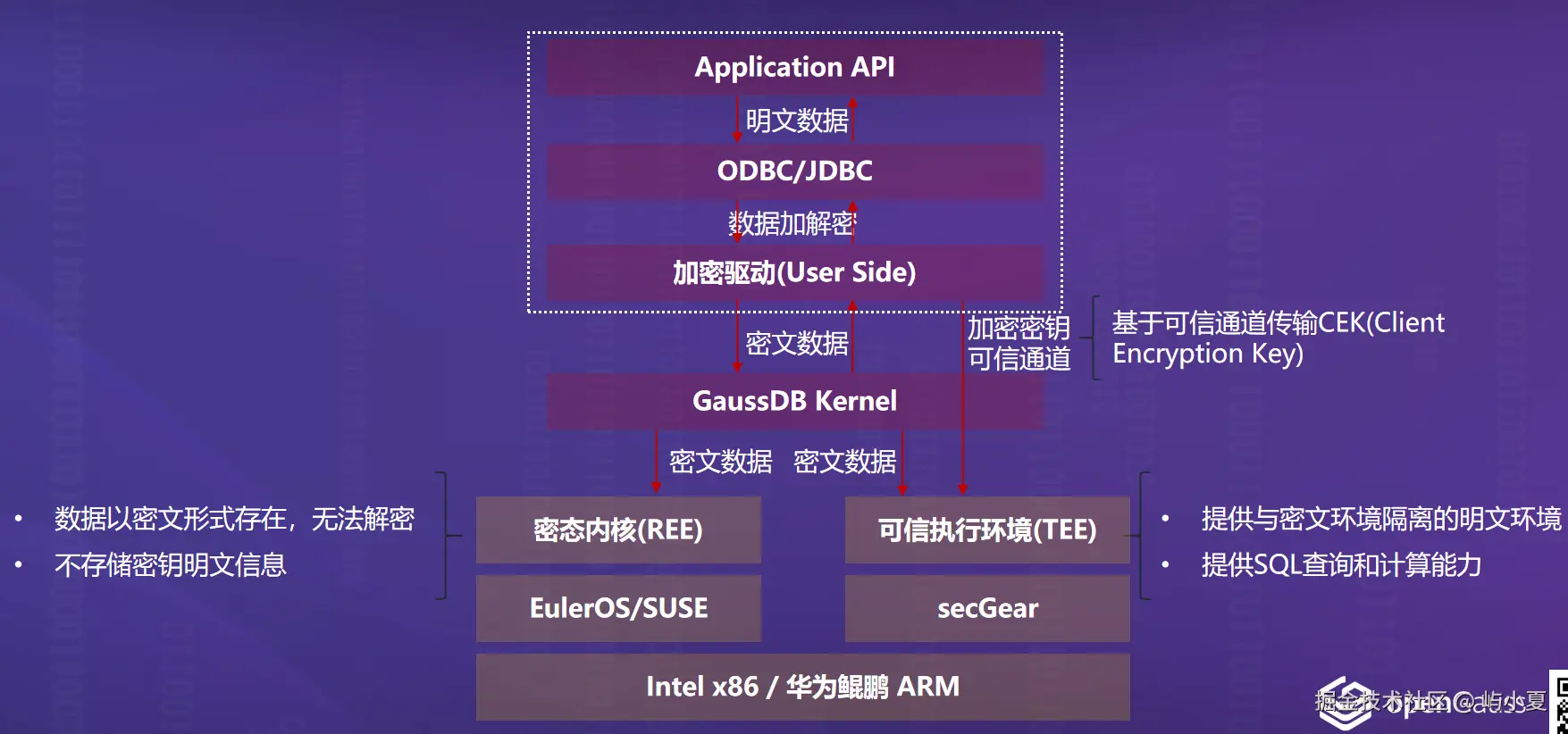
openGauss 提供 全密态等值查询,支持在加密状态下进行向量相似度计算:
客户端加密:数据在客户端加密后传入服务器;
密文计算:服务器在不解密的情况下执行查询;
TEE 环境支持:可选硬件可信执行环境,进一步提升安全性。
代码示例:全密态向量数据处理
markdown
-- 创建全密态表
CREATE TABLE encrypted_vectors (
vector_id BIGINT,
encrypted_data BYTEA, -- 加密后的向量数据
metadata JSONB
) WITH (ENCRYPTED = true);
-- 密文等值查询
SELECT vector_id, metadata
FROM encrypted_vectors
WHERE encrypted_equal(encrypted_data, ?); -- 参数为加密后的查询向量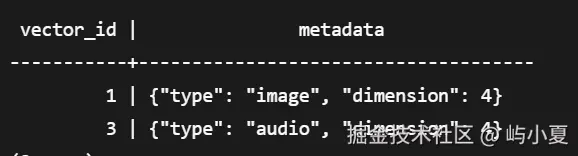
4 典型应用场景
4.1 图像与视频检索
使用 openGauss + 预训练模型(如ResNet)提取特征向量;
通过 HNSW 索引实现亿级图像库的实时以图搜图。
markdown
-- 图像特征向量存储表
CREATE TABLE image_features (
image_id VARCHAR(64) PRIMARY KEY,
file_path VARCHAR(255),
feature_vector FLOAT8[], -- CNN提取的1024维特征向量
upload_time TIMESTAMP,
tags TEXT[]
) WITH (ORIENTATION = COLUMN);
-- CREATE INDEX idx_image_features ON image_features
-- USING hnsw (feature_vector) WITH (m = 16, ef_construction = 64);
SELECT image_id, file_path,
cosine_similarity(feature_vector, ARRAY[/* 查询向量 */]) as similarity
FROM image_features
WHERE array_length(feature_vector, 1) = 1024 -- 确保维度一致
ORDER BY similarity DESC
LIMIT 20;
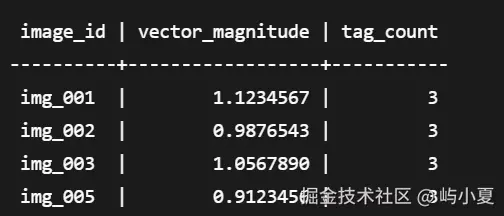
SELECT image_id,
vector_norm(feature_vector) as vector_magnitude,
array_length(tags, 1) as tag_count
FROM image_features
WHERE vector_norm(feature_vector) BETWEEN 0.8 AND 1.2;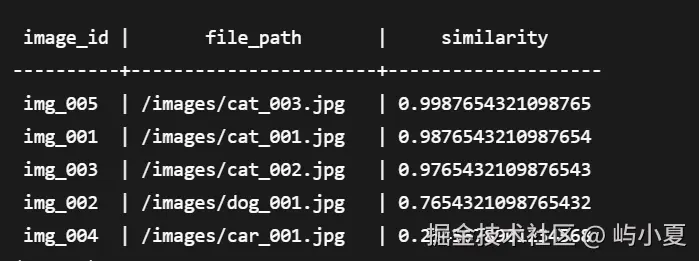
4.2 金融风控实时决策
结合行存表处理交易流水,列存表分析用户行为向量;
使用 MOT 内存表实现规则引擎 + 模型评分的实时风控。
markdown
-- 行存,高并发写入
CREATE TABLE transaction_stream (
tx_id BIGSERIAL PRIMARY KEY,
user_id BIGINT,
amount DECIMAL(15,2),
merchant_id INT,
location POINT,
transaction_time TIMESTAMP DEFAULT NOW()
) WITH (ORIENTATION = ROW);
-- 列存
CREATE TABLE user_behavior_vectors (
user_id BIGINT PRIMARY KEY,
transaction_pattern FLOAT8[], -- 交易模式向量
device_behavior FLOAT8[], -- 设备行为向量
risk_score FLOAT,
last_updated TIMESTAMP
) WITH (ORIENTATION = COLUMN);
SELECT ts.tx_id, ts.user_id, ts.amount,
ubv.risk_score,
vector_distance(ubv.transaction_pattern,
compute_current_pattern(ts.user_id)) as pattern_deviation
FROM transaction_stream ts
JOIN user_behavior_vectors ubv ON ts.user_id = ubv.user_id
WHERE ts.amount > 10000 -- 大额交易
OR vector_distance(ubv.transaction_pattern,
compute_current_pattern(ts.user_id)) > 0.8; -- 行为异常
CREATE FOREIGN TABLE risk_rules (
rule_id INT,
rule_name VARCHAR(100),
condition SQL_EXPRESSION,
risk_level INT
) SERVER mot_server;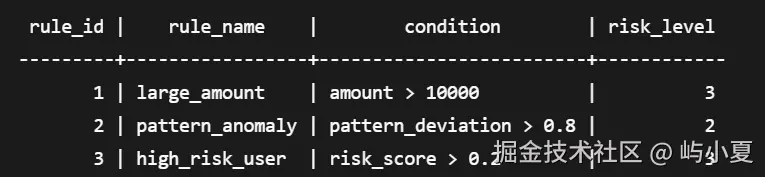
4.3 物联网时序数据分析
列存表存储传感器向量数据;
使用 DB4AI 进行异常检测、预测性维护。

markdown
-- 传感器时序数据
CREATE TABLE sensor_time_series (
device_id VARCHAR(50),
timestamp TIMESTAMP,
sensor_readings FLOAT8[], -- 多传感器读数向量
status_code INT
) WITH (ORIENTATION = COLUMN, COMPRESSION = HIGH);
-- 异常检测
CREATE MODEL sensor_anomaly_model
USING isolation_forest
FEATURES sensor_readings
FROM sensor_time_series
WHERE timestamp > NOW() - INTERVAL '30 days';
SELECT device_id, timestamp, sensor_readings,
PREDICT BY sensor_anomaly_model(FEATURES sensor_readings) as anomaly_score
FROM sensor_time_series
WHERE timestamp > NOW() - INTERVAL '1 hour'
AND PREDICT BY sensor_anomaly_model(FEATURES sensor_readings) > 0.7;
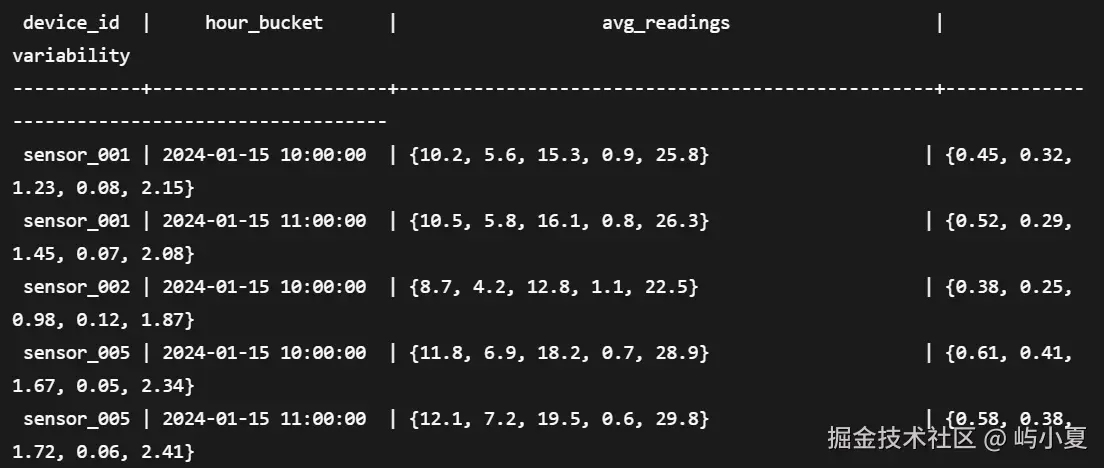
SELECT device_id,
date_trunc('hour', timestamp) as hour_bucket,
vector_avg(sensor_readings) as avg_readings,
vector_stddev(sensor_readings) as variability
FROM sensor_time_series
WHERE timestamp > NOW() - INTERVAL '24 hours'
GROUP BY device_id, hour_bucket;

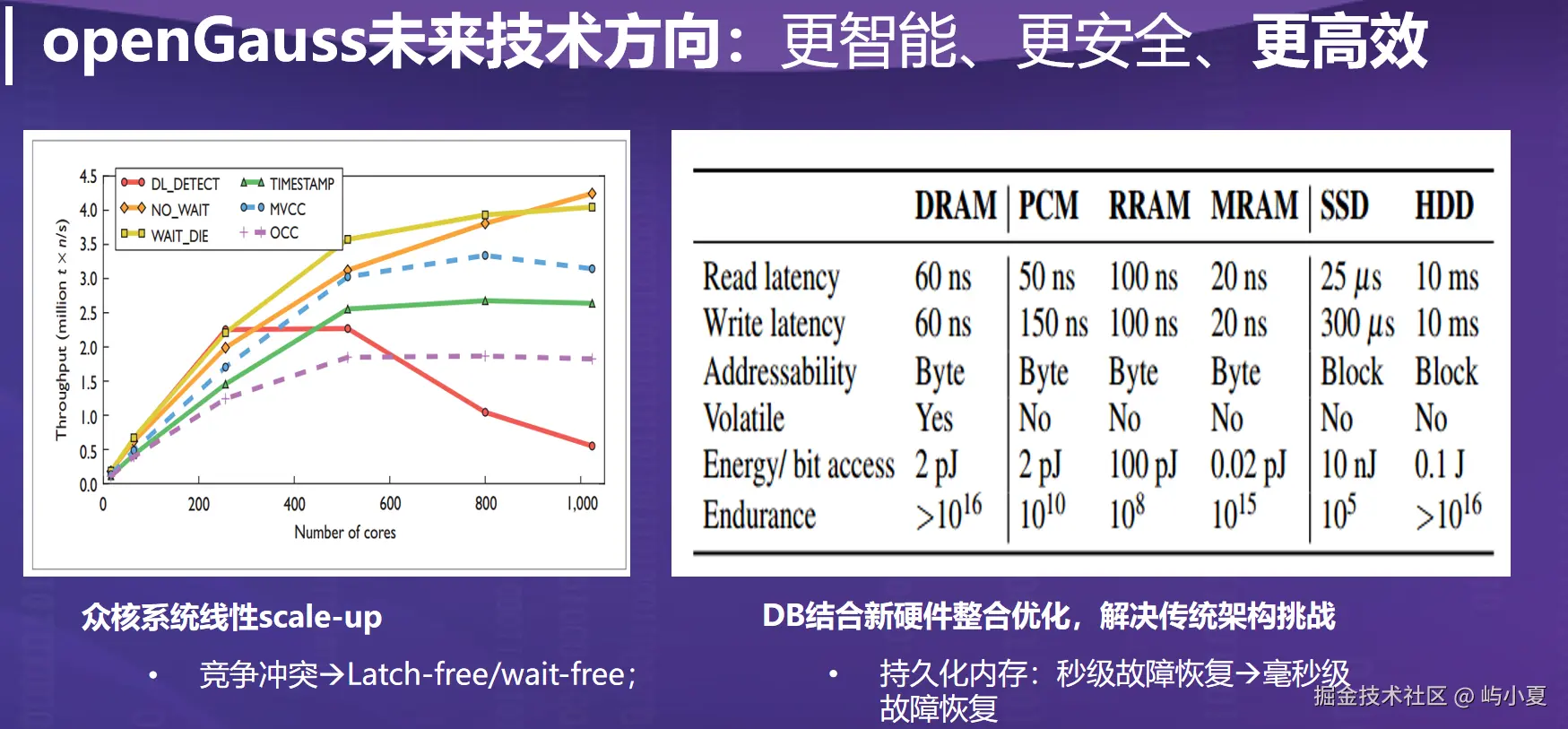
5 未来技术方向
openGauss 在向量数据库方向的未来演进包括:
更智能的向量索引:结合学习型索引(Learned Index)优化存储与检索;
软硬协同优化:持久化内存(PMem)、DPU 等新硬件的深度融合;
自优化查询器:基于强化学习的向量查询路径自适应选择。
6 总结
openGauss 通过 行列混合存储、DataVec 向量化引擎、MOT 内存表、DB4AI 库内AI 等核心技术,构建了一个既能处理传统关系型数据,又能高效处理向量数据的 统一数据平台。在企业数字化转型、AI 落地的背景下,openGauss 为企业提供了 高性能、高安全、易运维 的向量数据解决方案。

六大核心价值重塑数据处理范式
- 极致的性能体验
openGauss通过向量化执行引擎彻底改变了传统的数据处理模式。基于列存的向量化处理不仅大幅减少了函数调用开销,更重要的是充分利用了现代CPU的SIMD指令级并行能力,使得分析型查询的性能提升数倍甚至数十倍。配合MOT内存表的无锁设计和NUMA感知优化,在风控、推荐等实时场景中能够实现毫秒级的向量相似度计算。
- 真正的AI原生支持
DB4AI引擎的引入是openGauss区别于传统数据库的重要标志。它使得机器学习训练和推理过程可以直接在数据库内完成,避免了繁琐的数据导出、转换和加载过程。这种"数据不动、计算动"的理念不仅大幅提升了效率,更重要的是保证了数据安全和一致性,为AI应用的快速迭代提供了坚实基础。
- 完善的安全保障体系
从客户端加密到全密态等值查询,再到TEE可信执行环境支持,openGauss构建了完整的向量数据安全防护体系。这在金融、政务等对数据安全要求极高的场景中具有不可替代的价值,使得企业能够在保障数据隐私的前提下充分利用向量数据的价值。
- 灵活的架构适应性
行列混合存储引擎使得openGauss能够同时胜任OLTP和OLAP两种截然不同的工作负载。这种灵活性在实际业务场景中极具价值------企业无需为不同的业务需求维护多套数据库系统,大大降低了架构复杂度和运维成本。
- 深度的软硬协同优化
openGauss在硬件适配方面的投入使其能够充分发挥现代硬件平台的潜力。从ARM架构的鲲鹏处理器到昇腾AI加速卡,从NUMA架构优化到持久化内存支持,这种深度的软硬协同优化为企业提供了面向未来的性能扩展路径。
- 显著的总拥有成本优势
通过AI4DB技术实现的自运维、自调优能力,大幅降低了数据库的运维复杂度。自动化的参数调优、索引推荐、异常检测等功能不仅提升了系统稳定性,更重要的是释放了DBA的生产力,使其能够专注于更高价值的业务创新工作。
openGauss通过其全面的向量数据处理能力,为企业数字化转型和AI落地提供了坚实的技术基础。在这个数据驱动创新的时代,选择合适的技术平台将在很大程度上决定企业的竞争力和发展潜力。openGauss正是这样一个值得深入研究和投入的优秀平台。