此分类用于记录吴恩达深度学习课程的学习笔记。
课程相关信息链接如下:
- 原课程视频链接:双语字幕吴恩达深度学习deeplearning.ai
- github课程资料,含课件与笔记:吴恩达深度学习教学资料
- 课程配套练习(中英)与答案:吴恩达深度学习课后习题与答案
本周为第三课的第二周内容,本周的内容关于在上周的基础上继续展开,并拓展介绍了几种"学习方法",可以简单分为误差分析和学习方法两大部分。
其中,对于后者的的理解可能存在一些难度。同样,我会更多地补充基础知识和实例来帮助理解。
本篇的内容关于误差分析与快速迭代,是在上周的优化策略上的再一次完善。
1.如何误差分析?
误差分析,一个在理工科里常见的词,我们就不多介绍了,在这里更关键的是,如何在DL领域进行科学的误差分析?
我们继续用课程里的例子来进行介绍:

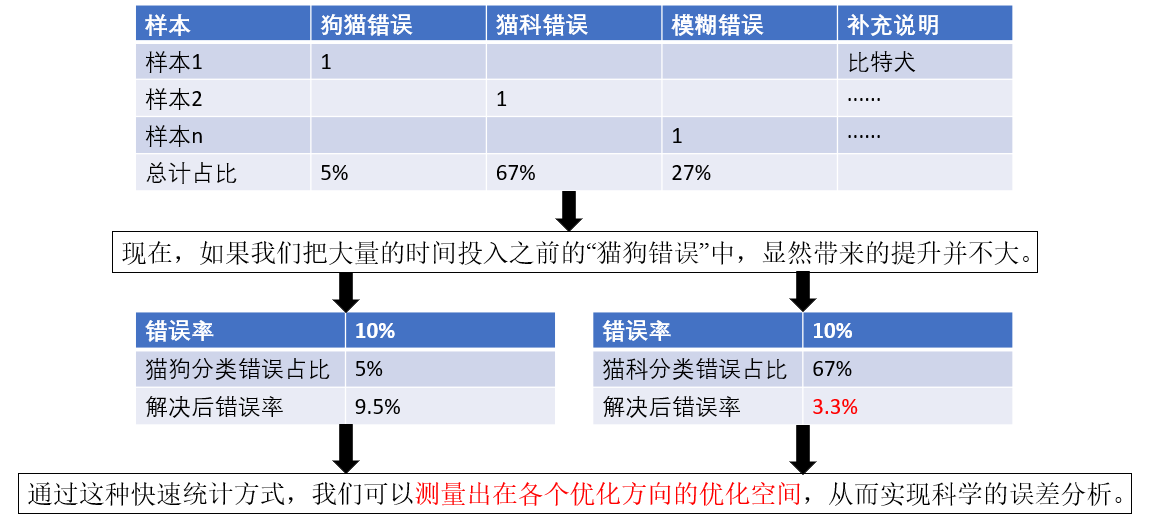
就像例子里所说,我们找到了一个误差原因,可是我们并不知道花费大量时间解决这个问题后指标能上升多少,这个问题到底占全部误差的多少?如何找到最大问题?这就是误差分析的科学所在。
由此,我们继续往下看:
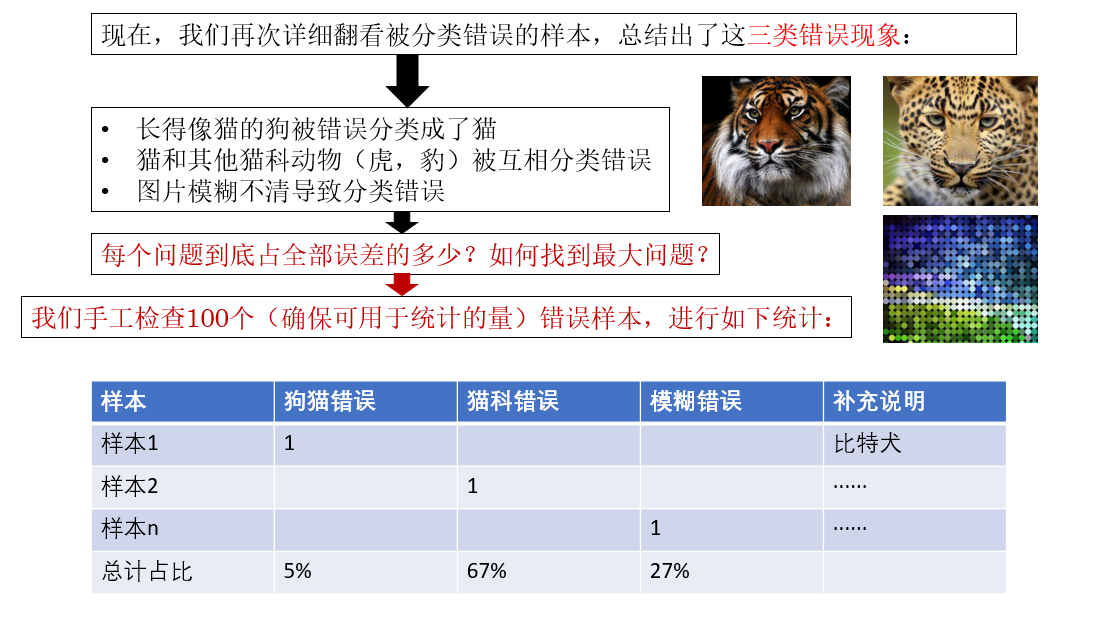
错误现象除此之外还有很多,比如滤镜,标签标注错误等等。
总之,在误差分析中,我们可以找一组错误样例并统计不同错误类型的样本占比,就可以找到更需要优先被解决的问题。
下面的内容,我们再展开一些需要细化的方面和其他策略。
2. 标签标注错误
之前,我们都一直默认数据集是一定正确的。
具体说一下,在监督学习中,每个数据对应其标签,所有猫图像对应一个标签,其他类同理,不会出现一个猫的标签确是狗的情况。
但实际上,图片的标签也是人工标注的 ,因此,出现这种错误并不奇怪,我们由此来展开这种情况带来的影响和相应的处理措施。
来看这个例子:
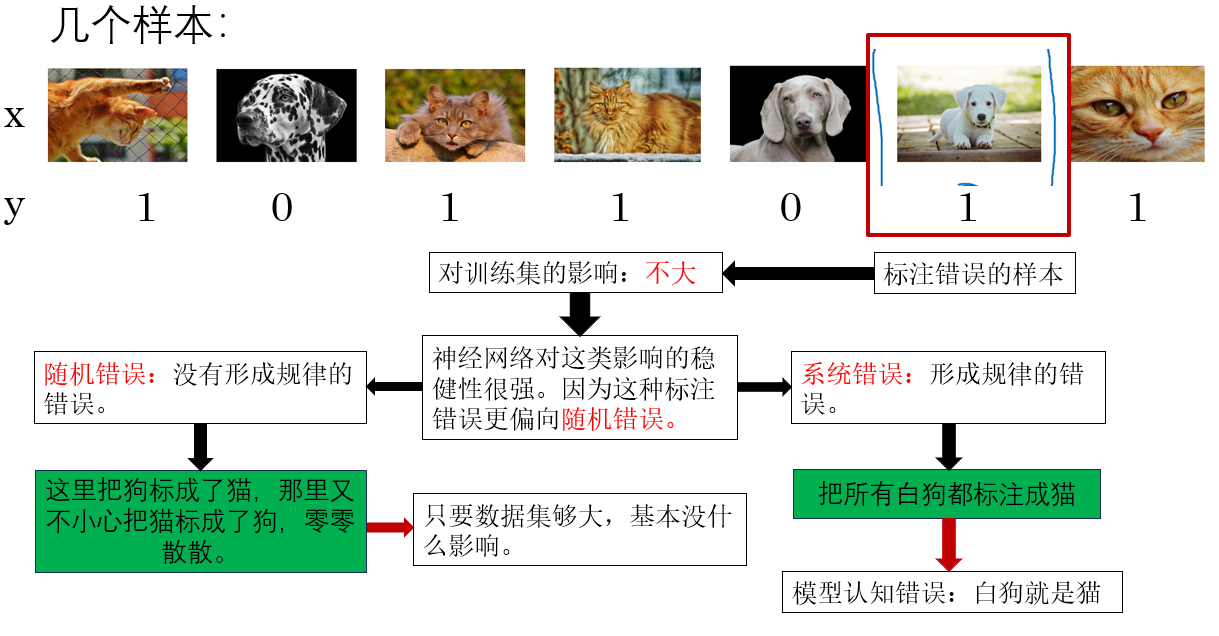
因此,总结来说,这种标注错误在训练集中的影响往往不大。
另外,这里要专门强调一点 :
稳健性 是指系统或模型在面对变化或干扰时保持有效性和稳定性的能力,就像面对此时的标注错误。
你也可以叫他健壮性,稳定性等等可以表达这类含义的词。
但是在论文里或者其他学术相关的地方 ,我们一般统一叫它鲁棒性 。
这种叫法是源于英文中的"robustness"一词,是它的音译 ,来更准确地传达英文原意。
所以,如果你在别的地方看到了鲁棒性,请记住:鲁棒性就是稳健性,稳健性就是鲁棒性。
(如果你看了这节的视频课程,会发现弹幕因为这个问题吵起来了)
我们继续:
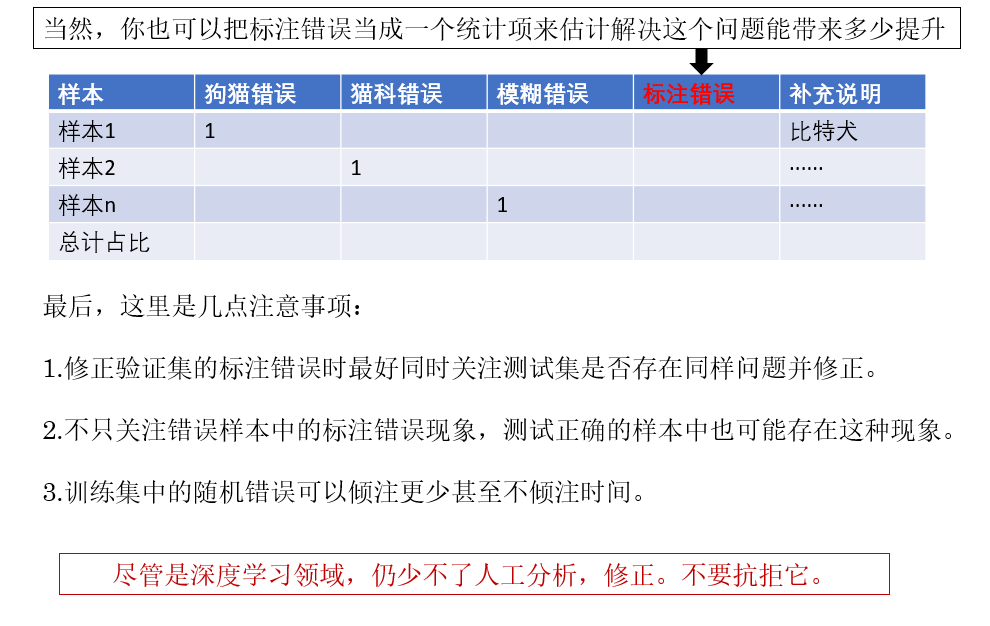
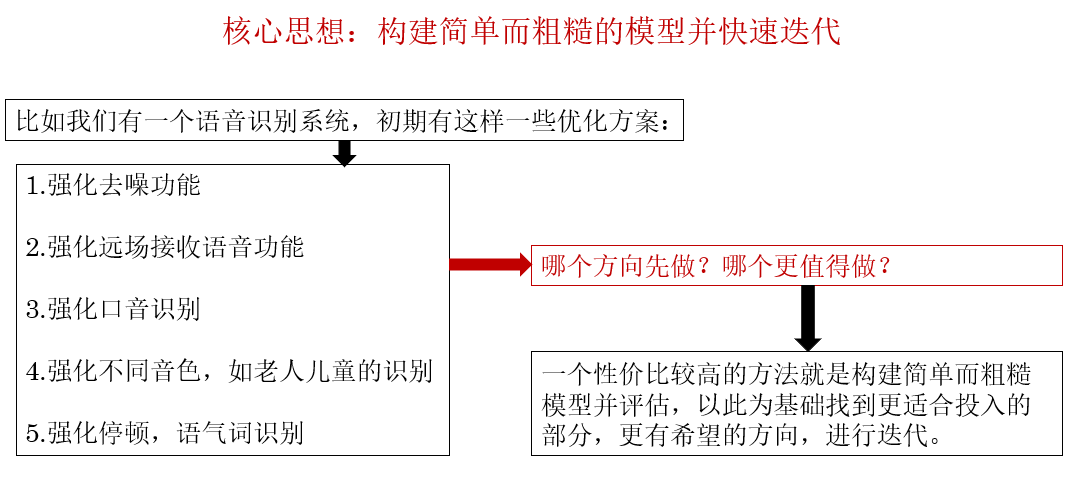
3.快速迭代
实际上这部分的思想和软件工程中的敏捷开发 有些相似,适用于模型的构建初期阶段,很容易理解,就不多展开了。
4.总结
| 概念 | 原理 | 比喻 |
|---|---|---|
| 误差分析(Error Analysis) | 从错误样本中统计不同类型错误的占比,以确定最影响性能、最值得优先解决的问题。 | 就像你做完一张考卷后,不是盲目重学一整本书,而是先数一数:数学丢分多,语文只错一道,那就先补数学。 |
| 数据集标注错误(Label Error) | 训练集中少量"猫被标成狗"这类错误通常不会使模型崩溃,但过多会导致模型混乱。 | 就像有人偶尔喊错你名字你也能反应过来,但如果十个人里有一半都叫你错名,你就不知道谁是谁了。 |
| 鲁棒性(Robustness) | 模型在面对噪声、标注问题、输入扰动等情况下仍保持稳定性能的能力。 | 像一个听力很好的朋友:周围很吵他也能准确听懂你说话,就是很"鲁棒"。 |
| 快速迭代(Rapid Iteration) | 不用一次做出完美模型,而是做--->训练--->看结果--->修正--->继续的循环,类似敏捷开发。 | 像画画:先画草稿确定构图,再慢慢精细化,而不是一开始就拼命画细节。 |