阻塞IO
阻塞 IO(BIO)的多线程模型
java
import java.io.*;
import java.net.ServerSocket;
import java.net.Socket;
import java.text.SimpleDateFormat;
import java.util.Date;
public class BIOBlockDemo {
// 格式化时间,方便观察线程活跃的时间点
private static final SimpleDateFormat sdf = new SimpleDateFormat("HH:mm:ss");
public static void main(String[] args) throws IOException {
// 1. 创建服务器 Socket,监听 8080 端口
ServerSocket serverSocket = new ServerSocket(8080);
System.out.println("BIO 服务器启动,端口 8080,主线程:" + Thread.currentThread().getName()
+ ",时间:" + sdf.format(new Date()));
while (true) {
// 2. 阻塞等待客户端连接(BIO 核心:accept() 会阻塞,直到有新连接)
// 这一步会卡住主线程,直到有客户端连接进来
Socket clientSocket = serverSocket.accept();
String clientAddr = clientSocket.getInetAddress().getHostAddress()
+ ":" + clientSocket.getPort();
System.out.println("新客户端连接:" + clientAddr
+ ",主线程:" + Thread.currentThread().getName()
+ ",时间:" + sdf.format(new Date()));
// 3. 为每个新连接创建一个独立线程处理(BIO 典型模式:一个连接一个线程)
new Thread(() -> {
try {
handleClient(clientSocket, clientAddr);
} catch (IOException e) {
System.out.println("客户端处理异常 " + clientAddr + ":" + e.getMessage());
}
}).start();
}
}
// 处理客户端请求(读取数据,BIO 阻塞操作)
private static void handleClient(Socket clientSocket, String clientAddr) throws IOException {
// 当前处理线程的信息
String threadName = Thread.currentThread().getName();
System.out.println("开始处理客户端 " + clientAddr
+ ",处理线程:" + threadName
+ ",时间:" + sdf.format(new Date()));
// 4. 获取输入流,准备读取客户端数据(BIO 核心:read() 会阻塞,直到有数据)
try (InputStream in = clientSocket.getInputStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(in))) {
String data;
// 循环读取客户端发送的数据(readLine() 会阻塞,直到客户端发送数据或断开)
while ((data = reader.readLine()) != null) {
System.out.println("收到 " + clientAddr + " 的数据:" + data
+ ",处理线程:" + threadName
+ ",时间:" + sdf.format(new Date()));
// 模拟业务处理耗时(非 IO 操作,线程此时处于运行状态)
Thread.sleep(1000);
// 向客户端回写响应(BIO 写操作也可能阻塞,取决于缓冲区)
OutputStream out = clientSocket.getOutputStream();
out.write(("服务器已收到:" + data + "\n").getBytes());
out.flush();
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} finally {
// 关闭连接
clientSocket.close();
System.out.println("客户端 " + clientAddr + " 断开连接"
+ ",处理线程:" + threadName
+ ",时间:" + sdf.format(new Date()));
}
}
}serverSocket.accept() 是阻塞方法:如果没有新客户端连接,主线程会一直卡在这个方法上,不会继续执行后面的代码(包括创建线程的逻辑)。
只有当有客户端发起连接请求,accept() 才会返回一个有效的 clientSocket 对象,此时才会触发新线程的创建。
因此,没有新连接 → accept() 不返回 → 不会进入创建线程的逻辑 → 不会新建线程
代码关键说明:阻塞 IO 中线程的 "时间点分布"
主线程阻塞在 accept():
服务器启动后,主线程(main 线程)会一直卡在 serverSocket.accept(),直到有客户端连接 ------ 此时主线程在 "等待连接" 的时间点处于阻塞状态。
新连接触发新线程创建 :
每有一个客户端连接(如 telnet 连接),主线程会从 accept() 阻塞中唤醒,创建一个新线程处理该连接 ------ 新线程在 "连接建立" 的时间点被创建并启动。
处理线程阻塞在 read():新线程启动后,会调用 reader.readLine() 读取客户端数据,此时若客户端未发送数据,线程会阻塞在 read() 处 ------ 该线程在 "等待数据" 的时间点处于阻塞状态。
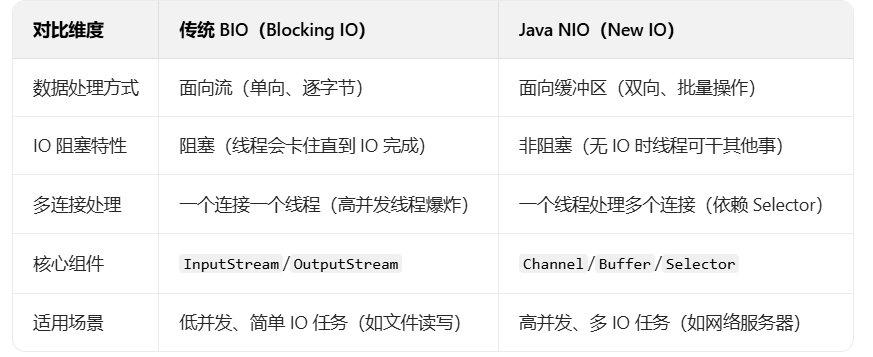
NIO (虽然全称是 New IO) ,是 Java 提供的一套面向缓冲区、支持非阻塞、基于通道的高效 IO 编程模型,核心是解决传统 IO(BIO,Blocking IO)在高并发场景下的性能瓶颈,本质是对操作系统底层 IO 机制(如非阻塞 IO、IO 复用)的 Java 封装。
一、先明确:NIO 不是 "新 IO 技术",而是 "新 IO 模型"
底层 IO 技术(如文件读写、网络通信)始终依赖操作系统,但传统 Java IO(BIO)是 "阻塞、流导向" 的模型,在处理多连接时效率极低(比如一个连接一个线程,高并发时线程爆炸);
Java 1.4 推出的 NIO,并非发明了新的 IO 硬件或操作系统调用,而是通过通道(Channel)、缓冲区(Buffer)、选择器(Selector) 这三个核心组件,封装了操作系统的 "非阻塞 IO" 和 "IO 复用" 能力,让 Java 程序能更高效地处理多 IO 任务 ------ 所以 NIO 的 "新",是相对于传统 BIO 模型的 "新",而非技术本身的 "新"。
二、NIO 的核心特性:为什么它比传统 BIO 高效?
NIO 有三个区别于 BIO 的关键特性,也是它高效的核心原因:
- 面向缓冲区(Buffer),而非面向流(Stream)
传统 BIO 是 "流导向":数据只能单向流动(输入流读、输出流写),且必须逐字节 / 逐字符处理(比如 InputStream.read() 每次读 1 字节),无法灵活操作数据;
NIO 是 "缓冲区导向":所有数据都先读到 Buffer(如 ByteBuffer)中,程序可以在缓冲区中灵活操作数据(比如跳转、修改、重复读取),减少了数据在内存中的拷贝次数,提升效率。
例:读数据时,NIO 是 "通道读数据到缓冲区 → 程序从缓冲区取数据",而 BIO 是 "流直接把数据传给程序",缓冲区的存在让数据操作更灵活。 - 非阻塞(Non-blocking)IO
传统 BIO 是 "阻塞的":比如 Socket.accept() 会阻塞到有新连接,InputStream.read() 会阻塞到有数据可读,一个线程只能处理一个 IO 任务,高并发时需要大量线程(线程切换成本高);
NIO 支持 "非阻塞":比如 ServerSocketChannel.accept() 非阻塞时,没新连接会直接返回 null;SocketChannel.read() 非阻塞时,没数据会直接返回 0,线程不会被卡住 ------ 这意味着一个线程可以同时处理多个 IO 任务(比如循环检查多个通道的状态),大幅减少线程数量。 - 支持 IO 复用(Selector)
传统 BIO 没有 IO 复用能力,要处理多个连接必须开多个线程;
NIO 的 Selector(选择器) 是核心:一个 Selector 可以注册多个 Channel(通道,如 SocketChannel),并监听这些通道的 IO 事件(如 "新连接""数据可读""数据可写")。
工作流程:线程调用 Selector.select() 后会阻塞,直到操作系统通知有通道就绪(IO 复用的核心是 "操作系统帮着轮询"),线程再批量处理所有就绪的通道 ------ 这样一个线程就能处理上百甚至上千个连接,是高并发服务器(如 Netty 框架)的基础。
NIO 的来源:解决传统 BIO 的性能痛点
在 Java 1.4 版本(2002 年发布)之前,Java 仅支持 传统 IO(BIO,Blocking I/O),这套 IO 模型在低并发场景(如简单文件读写)下够用,但在高并发场景(如网络服务器)中存在致命瓶颈,主要问题有两个:
阻塞特性导致线程爆炸 :BIO 的核心是 "阻塞"------ 比如 Socket.accept() 会阻塞到有新连接,InputStream.read() 会阻塞到有数据可读。要处理多个连接,必须为每个连接分配一个独立线程 ("一个连接一个线程" 模型)。高并发时(如同时有上千个客户端连接),线程数量会急剧增加,而线程切换、内存占用的成本极高,会直接拖垮服务器。
面向流的模型效率低: BIO 是 "面向流" 的 ------ 数据只能单向流动(输入流读、输出流写),且必须逐字节 / 逐字符处理(如 read() 每次读 1 字节),无法灵活操作数据(比如重复读取、跳转),频繁的 IO 调用和数据拷贝会浪费大量 CPU 资源。
为解决这些痛点,Java 团队在 Java 1.4 版本中引入了 NIO,目标是通过封装操作系统底层的 "非阻塞 IO""IO 复用" 等高效机制,让 Java 程序能以更少的线程、更低的资源消耗处理高并发 IO 任务。
NIO 的 "新":相对于 BIO 的核心改进
NIO 之所以被称为 "New I/O",核心是它在三个维度上颠覆了传统 BIO 的设计,这些改进都源于对操作系统底层能力的复用:
**从 "阻塞" 到 "非阻塞":**NIO 支持非阻塞 IO(如 SocketChannel.configureBlocking(false))------ 没有新连接时,accept() 直接返回 null;没有数据时,read() 直接返回 0,线程不会被卡住 。这意味着一个线程可以循环检查多个 IO 通道的状态,无需为每个连接开线程。
从 "面向流" 到 "面向缓冲区":NIO 引入了 Buffer(缓冲区) 作为数据载体 ------ 所有 IO 操作都通过缓冲区完成(如 ByteBuffer),数据先读到缓冲区,程序可在缓冲区中灵活操作(跳转、修改、批量读取),减少了数据拷贝次数,提升了效率。
引入 "IO 复用" 能力:NIO 的核心组件 Selector(选择器),本质是对操作系统 "IO 复用" 机制(如 Linux 的 epoll、Windows 的 IOCP)的封装。一个 Selector 可注册多个 IO 通道,线程只需调用 selector.select() 阻塞等待,操作系统会主动通知 "就绪的通道"(如有数据可读的连接),线程再批量处理这些通道 ------ 这是 "一个线程处理上千个连接" 的关键,也是高并发服务器(如 Netty)的基础。
补充:NIO 与 NIO.2 的区别(避免混淆)
需要注意的是,Java 7 版本(2011 年)又推出了 NIO.2(全称 Java New I/O 2.0),它是 NIO 的扩展,主要新增了两个核心功能:
异步 IO(Asynchronous I/O):支持 "发起 IO 操作后无需阻塞等待,IO 完成后操作系统通过回调通知程序",进一步提升了高并发效率(NIO 是 "非阻塞",仍需线程轮询;NIO.2 是 "异步",完全无需轮询)。
增强的文件系统 API:提供了 Path、Files、FileSystem 等类,简化了文件的创建、删除、复制等操作,弥补了传统 IO 文件处理能力的不足。
但日常开发中说的 "NIO",通常指 Java 1.4 引入的基础 NIO 模型(Channel/Buffer/Selector),它是理解 Java 高并发 IO 的核心。
总结
NIO 的全称是 Java New I/O ,其来源是 Java 团队为解决传统 BIO 在高并发场景下的 "线程爆炸""效率低" 等痛点,在 Java 1.4 版本中引入的新 IO 模型 。它并非发明了新的 IO 技术,而是通过封装操作系统的 "非阻塞 IO""IO 复用" 机制,提供了更高效的 IO 编程接口,成为 Java 高并发网络编程(如服务器开发)的基础。
一、非阻塞 I/O 模型(应用程序轮询)
非阻塞 I/O 中,应用程序需要主动轮询检查 I/O 状态,操作系统不参与轮询, 仅被动响应查询。以非阻塞 Socket 为例(模拟服务器接收客户端数据):
java
import java.net.*;
import java.nio.ByteBuffer;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
import java.util.ArrayList;
import java.util.List;
public class NonBlockingIOExample {
public static void main(String[] args) throws Exception {
// 1. 创建非阻塞服务器通道
ServerSocketChannel serverSocket = ServerSocketChannel.open();
serverSocket.socket().bind(new InetSocketAddress(8080));
serverSocket.configureBlocking(false); // 设置为非阻塞模式
System.out.println("非阻塞服务器启动,端口 8080");
// 存储所有已连接的客户端通道(需要应用程序自己维护)
List<SocketChannel> clients = new ArrayList<>();
// 2. 应用程序主动轮询(核心:轮询由应用程序执行)
while (true) {
// 2.1 检查是否有新客户端连接(非阻塞 accept,立即返回 null 或客户端通道)
SocketChannel client = serverSocket.accept();
if (client != null) {
System.out.println("新客户端连接:" + client.getRemoteAddress());
client.configureBlocking(false); // 客户端通道也设为非阻塞
clients.add(client);
}
// 2.2 遍历所有客户端,轮询检查是否有数据可读(应用程序主动轮询)
for (SocketChannel c : clients) {
ByteBuffer buffer = ByteBuffer.allocate(1024);
// 非阻塞 read:有数据则读取,无数据则返回 0(不会阻塞)
int bytesRead = c.read(buffer);
if (bytesRead > 0) {
buffer.flip();
byte[] data = new byte[buffer.remaining()];
buffer.get(data);
System.out.println("收到来自 " + c.getRemoteAddress() + " 的数据:" + new String(data));
} else if (bytesRead == -1) {
// 客户端断开连接
System.out.println("客户端断开:" + c.getRemoteAddress());
c.close();
clients.remove(c);
break; // 避免遍历修改引发异常,简化处理
}
}
// 3. 模拟应用程序可同时处理其他逻辑(非阻塞的优势)
Thread.sleep(100); // 降低轮询频率,避免 CPU 占用过高
}
}
}关键说明:
轮询执行者:应用程序(while(true) 循环主动检查新连接和数据)。
非阻塞特性:accept() 和 read() 均为非阻塞调用,无操作时立即返回,不会卡住。
缺点:应用程序需自己维护连接列表并轮询,高并发时会消耗大量 CPU(空轮询)。
二、I/O 复用模型(操作系统轮询)
I/O 复用中,应用程序通过操作系统提供的多路复用接口(如 Java 的 Selector)注册 I/O 事件,由操作系统负责轮询,就绪时通知应用程序。以 NIO 的 Selector 为例(高效处理多客户端):
java
import java.net.*;
import java.nio.ByteBuffer;
import java.nio.channels.*;
import java.util.Iterator;
import java.util.Set;
public class IOMultiplexingExample {
public static void main(String[] args) throws Exception {
// 1. 创建服务器通道和选择器(Selector 是 Java 对 I/O 复用的封装)
ServerSocketChannel serverSocket = ServerSocketChannel.open();
serverSocket.socket().bind(new InetSocketAddress(8080));
serverSocket.configureBlocking(false); // 非阻塞模式
Selector selector = Selector.open(); // 创建选择器(依赖操作系统的 epoll/poll/select)
// 2. 注册服务器通道到选择器,关注"新连接"事件(OP_ACCEPT)
serverSocket.register(selector, SelectionKey.OP_ACCEPT);
System.out.println("I/O 复用服务器启动,端口 8080");
// 3. 应用程序等待操作系统通知(轮询由操作系统执行)
while (true) {
// 3.1 阻塞等待,直到有事件就绪(由操作系统轮询后通知)
// 说明:select() 会让操作系统底层轮询所有注册的通道,有事件时唤醒应用程序
int readyChannels = selector.select();
if (readyChannels == 0) continue; // 无事件就绪,继续等待
// 3.2 处理就绪的事件(操作系统已筛选出有状态变化的通道)
Set<SelectionKey> selectedKeys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = selectedKeys.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
// 3.3 新客户端连接事件
if (key.isAcceptable()) {
ServerSocketChannel server = (ServerSocketChannel) key.channel();
SocketChannel client = server.accept();
client.configureBlocking(false);
System.out.println("新客户端连接:" + client.getRemoteAddress());
// 注册客户端通道到选择器,关注"读数据"事件(OP_READ)
client.register(selector, SelectionKey.OP_READ);
}
// 3.4 客户端数据可读事件
else if (key.isReadable()) {
SocketChannel client = (SocketChannel) key.channel();
ByteBuffer buffer = ByteBuffer.allocate(1024);
int bytesRead = client.read(buffer);
if (bytesRead > 0) {
buffer.flip();
byte[] data = new byte[buffer.remaining()];
buffer.get(data);
System.out.println("收到来自 " + client.getRemoteAddress() + " 的数据:" + new String(data));
} else if (bytesRead == -1) {
// 客户端断开
System.out.println("客户端断开:" + client.getRemoteAddress());
client.close();
key.cancel(); // 取消注册
}
}
keyIterator.remove(); // 移除已处理的事件
}
}
}
}关键说明:
轮询执行者:操作系统(通过 selector.select() 调用,底层依赖 OS 的 epoll(Linux)、kqueue(Mac)等 I/O 复用机制,由 OS 轮询注册的 I/O 事件 )。
高效性:应用程序无需自己轮询所有连接,只需处理操作系统筛选后的 "就绪事件",大幅降低 CPU 消耗。
核心逻辑:通过 Selector 注册事件(连接、读、写),OS 轮询后通知应用程序处理就绪事件,适合高并发场景(如 Nginx、Netty 底层均基于此模型 )。
总结:轮询执行者对比
运行程序
telnet localhost 8080 连接访问,输入内容
IO多路复用是复用在那个地方
IO 多路复用的 "复用" 核心体现在 "复用同一个线程处理多个 IO 通道(如网络连接)"------ 通过一个线程监听并处理多个 IO 事件(如连接、读、写),避免为每个 IO 通道单独创建线程,从而减少线程资源消耗(线程创建、切换、内存占用的成本)。
一、"复用" 的具体含义:一个线程处理多个 IO 任务
传统 BIO 模型中,"一个连接对应一个线程":
每有一个客户端连接,就必须创建一个新线程处理该连接的 IO 操作(读 / 写数据);
当连接数达到上千个时,线程数也会达到上千个,线程切换和内存占用会拖垮系统。
IO 多路复用模型中,"一个线程处理所有连接":
所有客户端连接(IO 通道)都注册到一个 "选择器(Selector)" 上;
一个线程通过选择器监听所有通道的 IO 事件(如 "有数据可读");
只有当某个通道的 IO 事件就绪时,线程才会去处理该通道,其余时间线程可以阻塞等待或处理其他任务。
这里的 "复用" 就是复用同一个线程的执行权,处理多个 IO 通道的事件,核心是 "用少量线程(甚至一个线程)支撑大量 IO 连接"。
Java 代码示例:用 NIO 实现 IO 多路复用
下面的代码模拟一个服务器,用单线程 + Selector 处理多个客户端连接,展示 "复用一个线程处理多个 IO 通道" 的过程:
java
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.*;
import java.util.Iterator;
import java.util.Set;
public class IOMultiplexingDemo {
public static void main(String[] args) throws Exception {
// 1. 创建服务器通道(非阻塞模式)
ServerSocketChannel serverChannel = ServerSocketChannel.open();
serverChannel.socket().bind(new InetSocketAddress(8080));
serverChannel.configureBlocking(false); // 关键:设置为非阻塞
// 2. 创建选择器(Selector),用于监听多个通道的事件
Selector selector = Selector.open();
// 3. 将服务器通道注册到选择器,关注"新连接"事件(OP_ACCEPT)
// 注意:注册时需指定事件类型,选择器只监听注册的事件
serverChannel.register(selector, SelectionKey.OP_ACCEPT);
System.out.println("服务器启动,监听端口 8080,线程:" + Thread.currentThread().getName());
// 4. 单线程循环处理所有事件(复用这个线程)
while (true) {
// 4.1 阻塞等待事件就绪(由操作系统轮询,有事件时唤醒线程)
// 这一步是 IO 多路复用的核心:线程阻塞在这里,直到有通道的事件就绪
int readyChannels = selector.select();
if (readyChannels == 0) {
continue; // 无事件就绪,继续等待
}
// 4.2 获取所有就绪的事件(操作系统已筛选出有状态变化的通道)
Set<SelectionKey> selectedKeys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = selectedKeys.iterator();
// 4.3 遍历处理每个就绪事件(复用当前线程处理多个通道)
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
// 处理"新连接"事件(客户端发起连接)
if (key.isAcceptable()) {
// 接收新客户端连接
ServerSocketChannel server = (ServerSocketChannel) key.channel();
SocketChannel clientChannel = server.accept();
clientChannel.configureBlocking(false); // 客户端通道也设为非阻塞
System.out.println("新客户端连接:" + clientChannel.getRemoteAddress() + ",线程:" + Thread.currentThread().getName());
// 将新客户端通道注册到选择器,关注"读数据"事件(OP_READ)
clientChannel.register(selector, SelectionKey.OP_READ);
}
// 处理"数据可读"事件(客户端发送数据)
else if (key.isReadable()) {
SocketChannel clientChannel = (SocketChannel) key.channel();
ByteBuffer buffer = ByteBuffer.allocate(1024);
int bytesRead = clientChannel.read(buffer);
if (bytesRead > 0) { // 读取到数据
buffer.flip();
byte[] data = new byte[buffer.remaining()];
buffer.get(data);
System.out.println("收到 " + clientChannel.getRemoteAddress() + " 的数据:" + new String(data) + ",线程:" + Thread.currentThread().getName());
} else if (bytesRead == -1) { // 客户端断开连接
System.out.println("客户端断开:" + clientChannel.getRemoteAddress() + ",线程:" + Thread.currentThread().getName());
clientChannel.close();
key.cancel(); // 从选择器中移除该通道
}
}
// 移除已处理的事件(避免重复处理)
keyIterator.remove();
}
}
}
}代码中 "复用" 的体现(关键分析)
线程复用:整个程序只有一个主线程(main 线程) ,所有客户端的连接建立、数据读取都由这个线程处理 ------ 无论有 10 个还是 1000 个客户端,都不需要创建新线程,实现了 "一个线程处理多个 IO 任务"。
事件监听复用:Selector 同时监听多个通道的事件(服务器通道的 OP_ACCEPT、客户端通道的 OP_READ),替代了传统 BIO 中 "每个线程监听一个通道" 的模式,实现了 "一个选择器复用多个通道的事件监听"。
阻塞时机复用:线程只在 selector.select() 处阻塞(等待事件就绪),而非为每个通道单独阻塞 ------ 当没有事件时,线程休眠(不占用 CPU);有事件时,线程被唤醒并批量处理所有就绪事件,避免了线程空转。
"非阻塞 IO + 线程池"),与 "NIO 多路复用(Selector)" 相比,在高并发场景下性能差距显著。前者虽然比传统 BIO 高效,但仍无法解决 "线程资源浪费" 和 "系统调用开销" 问题,而多路复用通过单线程(或少量线程)处理大量连接,能显著降低资源消耗。

NIO + 线程池(非多路复用)
这种方案用非阻塞 Channel 接收连接,但不使用 Selector,而是直接将每个连接的 IO 操作丢到线程池处理:
java
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class NIOWithThreadPool {
private static final int PORT = 8080;
// 线程池:处理 IO 读写操作
private static final ExecutorService ioThreadPool = Executors.newFixedThreadPool(20);
public static void main(String[] args) throws IOException {
// 1. 创建非阻塞服务器通道
ServerSocketChannel serverChannel = ServerSocketChannel.open();
serverChannel.bind(new InetSocketAddress(PORT));
serverChannel.configureBlocking(false); // 非阻塞模式(不使用 Selector)
System.out.println("NIO + 线程池 服务器启动,端口:" + PORT);
while (true) {
// 2. 非阻塞 accept:无连接时返回 null,不会阻塞
SocketChannel clientChannel = serverChannel.accept();
if (clientChannel != null) {
// 3. 客户端通道设为非阻塞
clientChannel.configureBlocking(false);
String clientAddr = clientChannel.getRemoteAddress().toString();
System.out.println("新连接:" + clientAddr + ",交给线程池处理");
// 4. 将 IO 操作丢到线程池(核心:线程池处理读写)
ioThreadPool.submit(() -> handleClient(clientChannel, clientAddr));
}
// 5. 主线程空转(无 Selector 时,需循环轮询新连接,浪费 CPU)
try {
Thread.sleep(1); // 降低空转频率,减少 CPU 消耗
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}
// 线程池处理客户端 IO 读写(非阻塞读)
private static void handleClient(SocketChannel clientChannel, String clientAddr) {
ByteBuffer buffer = ByteBuffer.allocate(1024);
try {
// 非阻塞读:循环尝试读取数据(无数据时返回 0,不会阻塞)
while (true) {
int bytesRead = clientChannel.read(buffer);
if (bytesRead > 0) { // 读到数据
buffer.flip();
byte[] data = new byte[buffer.remaining()];
buffer.get(data);
System.out.println("线程 " + Thread.currentThread().getName()
+ " 收到 " + clientAddr + " 的数据:" + new String(data));
buffer.clear();
// 回写响应
clientChannel.write(ByteBuffer.wrap(("已收到:" + new String(data)).getBytes()));
} else if (bytesRead == -1) { // 客户端断开
System.out.println("线程 " + Thread.currentThread().getName()
+ " 处理的 " + clientAddr + " 断开");
clientChannel.close();
break;
} else { // 无数据,短暂休眠避免 CPU 空转
Thread.sleep(10);
}
}
} catch (Exception e) {
System.out.println(clientAddr + " 处理异常:" + e.getMessage());
try { clientChannel.close(); } catch (IOException ignored) {}
}
}
}NIO 多路复用(Selector)
用 Selector 单线程监听事件,业务逻辑按需用线程池:
java
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.*;
import java.util.Iterator;
import java.util.Set;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class NIOWithSelector {
private static final int PORT = 8080;
// 业务线程池:仅处理业务逻辑(非 IO 操作)
private static final ExecutorService businessPool = Executors.newFixedThreadPool(5);
public static void main(String[] args) throws IOException {
// 1. 创建服务器通道和 Selector
ServerSocketChannel serverChannel = ServerSocketChannel.open();
serverChannel.bind(new InetSocketAddress(PORT));
serverChannel.configureBlocking(false);
Selector selector = Selector.open();
// 2. 注册服务器通道到 Selector,监听连接事件
serverChannel.register(selector, SelectionKey.OP_ACCEPT);
System.out.println("NIO 多路复用 服务器启动,端口:" + PORT);
// 3. 单线程循环处理 Selector 事件
while (true) {
// 阻塞等待事件就绪(操作系统轮询,无事件时线程休眠)
selector.select();
// 处理就绪事件
Set<SelectionKey> keys = selector.selectedKeys();
Iterator<SelectionKey> iterator = keys.iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
iterator.remove();
if (key.isAcceptable()) { // 新连接事件
ServerSocketChannel server = (ServerSocketChannel) key.channel();
SocketChannel client = server.accept();
client.configureBlocking(false);
// 注册客户端通道到 Selector,监听读事件
client.register(selector, SelectionKey.OP_READ);
System.out.println("新连接:" + client.getRemoteAddress());
} else if (key.isReadable()) { // 读数据事件
SocketChannel client = (SocketChannel) key.channel();
// 提交到业务线程池处理(IO 事件监听仍在主线程)
businessPool.submit(() -> handleRead(client));
}
}
}
}
// 处理读事件(业务逻辑)
private static void handleRead(SocketChannel client) {
ByteBuffer buffer = ByteBuffer.allocate(1024);
try {
int bytesRead = client.read(buffer);
if (bytesRead > 0) {
buffer.flip();
byte[] data = new byte[buffer.remaining()];
buffer.get(data);
System.out.println("线程 " + Thread.currentThread().getName()
+ " 收到 " + client.getRemoteAddress() + " 的数据:" + new String(data));
// 回写响应
client.write(ByteBuffer.wrap(("已收到:" + new String(data)).getBytes()));
} else if (bytesRead == -1) { // 客户端断开
client.close();
System.out.println(client.getRemoteAddress() + " 断开");
}
} catch (IOException e) {
try { client.close(); } catch (IOException ignored) {}
}
}
}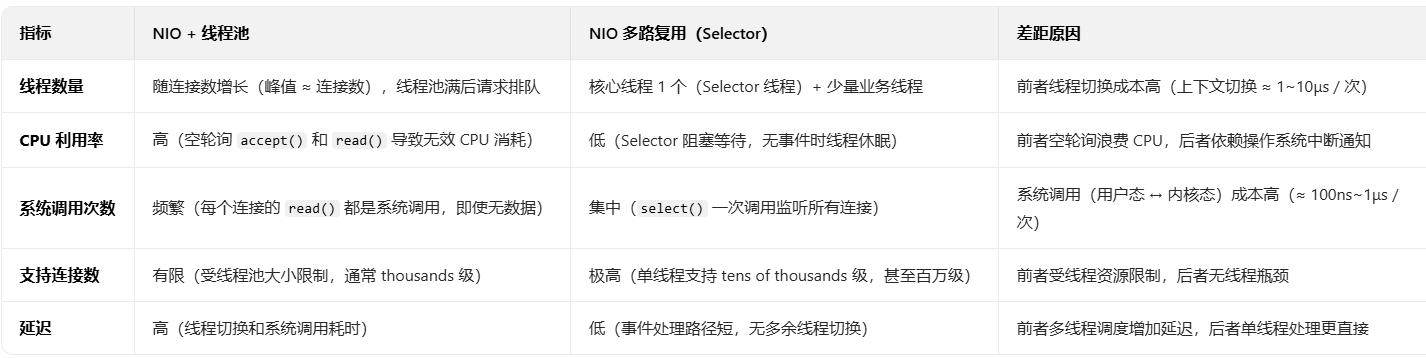
NIO + 线程池:适合 中低并发场景(连接数 < 1000),实现简单,无需理解 Selector 机制。
NIO 多路复用:适合 高并发场景(连接数 > 1000),性能优势明显,是 Netty、Redis 等中间件的核心方案。
本质差距在于:多路复用通过 "操作系统级别的事件监听" 替代了 "应用程序级别的线程轮询",从根源上减少了资源消耗和系统开销,这是线程池无法比拟的。
Java 早期不自己实现类似 Selector.select() 的逻辑,核心原因是 "用户态代码无法高效完成 IO 复用的核心工作,必须依赖操作系统底层支持"------IO 复用的本质是 "批量监听多个 IO 状态",这个工作只有操作系统能做,且效率远高于 Java 自己在用户态模拟
一、核心矛盾:IO 状态监听是 "操作系统特权",Java 无法绕过
要实现 "同时监听多个网络连接的 IO 事件"(比如哪些连接有数据可读),必须获取 硬件 IO 设备的状态(如网卡缓冲区是否有数据)。而硬件 IO 设备的控制权完全归操作系统所有,Java 作为运行在用户态的编程语言,有两个无法突破的限制:
1.无法直接访问硬件 IO 端口 / 寄存器 :网卡、硬盘等 IO 设备的状态(如是否有数据到达),需要通过操作硬件的 IO 端口或内存映射地址获取。但这些操作属于 "特权指令",只有操作系统内核(核心态)能执行,Java 代码运行在用户态,根本无法直接读取硬件状态 ------ 连 "某个连接是否就绪" 的原始数据都拿不到,更谈不上自己实现监听逻辑。
2.无法高效阻塞等待多个 IO 事件:如果 Java 想在用户态模拟 "监听多个连接",唯一的办法是 主动轮询(比如循环调用每个 Socket 的 read() 方法,检查是否有数据)。但这种方式有致命问题:
若用 阻塞 IO(传统 BIO):轮询到一个未就绪的连接时,线程会被 read() 阻塞,无法继续检查其他连接,本质还是 "一个连接一个线程",解决不了高并发问题;
若用 非阻塞 IO:轮询时会频繁调用系统调用(如 read()),即使没有数据也要反复查询,导致 CPU 空转(比如每秒循环上万次,99% 的调用都是 "无数据"),效率极低。
而操作系统的 select/poll/epoll(Linux)、IOCP(Windows)等 IO 复用接口,能直接通过硬件中断感知 IO 状态变化(比如网卡有数据时主动通知内核),无需轮询,效率是用户态模拟无法比拟的。
二、历史背景:Java 早期设计优先 "简单性",而非 "高并发"
Java 1.0(1996 年)推出时,主要目标是 "跨平台、简化开发",而非 "高并发网络编程":
*1.早期场景不需要高并发:*当时互联网还处于萌芽阶段,网络应用多是 "少量客户端连接"(如简单的 B/S 网站、桌面应用的网络请求),传统 BIO 的 "一个连接一个线程" 模型完全够用,没有迫切需要 "高效处理上千个连接" 的场景。
2.跨平台需要依赖操作系统接口 :Java 的核心优势是 "一次编写,到处运行",如果自己在用户态实现监听逻辑,需要针对不同操作系统(Windows、Linux、macOS)做差异化适配(比如不同系统的 IO 设备驱动、中断机制不同),这会破坏跨平台特性。而通过封装操作系统的标准 IO 复用接口(如 select),既能实现跨平台,又能复用操作系统的高效实现。
直到 Java 1.4(2002 年),随着互联网高并发场景(如大型网站、即时通讯)的兴起,传统 BIO 的瓶颈凸显,Java 团队才推出 NIO,通过 Selector 封装操作系统的 IO 复用能力 ------ 本质是 "借操作系统的能力,解决用户态无法解决的问题"。
三、技术成本:用户态实现会导致 "性能灾难"
即使不考虑特权限制,Java 自己在用户态实现类似 Selector.select() 的逻辑,也会面临无法解决的性能问题 :
1.系统调用开销 :每个 IO 状态检查都需要调用操作系统的系统调用(如 read()),用户态与核心态的切换成本极高(一次切换约几十到几百纳秒)。如果监听 1000 个连接,每秒轮询 100 次,就会产生 10 万次系统调用,大部分 CPU 资源会消耗在切换上,而非实际业务处理。
2.缺乏硬件中断支持 :操作系统的 IO 复用接口能直接响应硬件中断(如网卡收到数据后,硬件触发中断通知内核,内核标记对应的连接为 "就绪"),无需主动轮询。而 Java 在用户态无法感知硬件中断,只能通过 "忙轮询"(反复查询)模拟,会导致 CPU 利用率飙升(比如空轮询时 CPU 占用率 100%)。
3.内存拷贝开销:如果 Java 自己管理多个连接的 IO 数据,需要频繁在用户态与核心态之间拷贝数据(比如从内核缓冲区拷贝到 Java 堆)。而操作系统的 IO 复用接口能优化数据路径(如 epoll 支持 "零拷贝"),减少拷贝开销 ------ 这是用户态实现无法做到的。
总结
Java 早期不自己实现 Selector.select() 逻辑,根本原因是 "用户态代码无法突破操作系统的特权限制,也无法达到操作系统级别的效率":
1.IO 状态监听依赖硬件控制和中断机制,这些是操作系统的核心能力,Java 作为用户态语言无法绕过;
2.用户态模拟(如轮询)会导致 CPU 空转、系统调用开销激增,性能远不如操作系统原生 IO 复用接口;
3.早期场景不需要高并发,Java 优先保证跨平台和简单性,直到高并发需求出现后,才通过 Selector 封装操作系统能力。
简单说:不是 Java 不想自己实现,而是 "做不到、做不好、没必要"------ 最高效的方式,就是借助操作系统的原生能力,通过 Selector 把这种能力封装成 Java 开发者能直接使用的 API。
操作系统级别的事件监听(即 IO 复用机制),核心是通过 "硬件中断触发 + 内核态事件管理" 实现对多 IO 通道的高效监听,底层依赖特定数据结构快速管理 "注册事件" 和 "就绪事件"。不同操作系统实现差异较大,主流方案中 Linux 的 epoll 设计最经典(兼顾性能与扩展性),Windows 的 IOCP 次之,下面以 epoll 为核心拆解原理、数据结构,并结合实例说明。
一、核心原理:从 "应用轮询" 到 "内核主动通知
传统 IO 模型(如 BIO)中,应用需主动循环调用 read() 等接口判断 IO 是否就绪("应用猜"),效率极低;而操作系统级事件监听是 "内核盯"------ 内核直接与硬件交互,感知 IO 状态变化后主动通知应用,流程可拆解为 4 步:
1. 硬件中断:IO 状态变化的 "触发器"
当网卡收到数据、磁盘完成读写时,硬件会向 CPU 发送 中断信号,CPU 会暂停当前任务,转去执行内核的 "中断处理函数"。
例:客户端向服务器发送数据,网卡接收数据后触发中断,CPU 调用内核的网卡中断处理函数。
2. 内核标记:将 IO 通道标记为 "就绪"
中断处理函数会找到对应的 IO 通道(如 socket 的文件描述符 fd),将其状态标记为 "就绪",并加入内核维护的 "就绪事件列表"。
例:中断处理函数找到服务器监听的 socket fd,将其 "读事件" 标记为就绪,并存入就绪列表。
3. 应用阻塞:线程挂起等待通知
应用程序调用 IO 复用接口(如 epoll 的 epoll_wait())后,线程会从用户态切换到内核态:
若 "就绪事件列表" 为空,内核会将线程挂起(不占用 CPU 资源);
若列表非空,内核会直接返回就绪事件,避免线程空等。
4. 事件通知:唤醒线程处理就绪事件
当内核检测到 "就绪事件列表" 非空时(如硬件中断触发后),会立即唤醒挂起的应用线程,将就绪事件列表返回给应用。应用只需处理这些 "已就绪" 的 IO 通道,无需遍历所有注册的通道。
二、关键数据结构:不同 IO 复用机制的实现对比
操作系统需要通过数据结构管理 "已注册的 IO 通道" 和 "就绪的事件",不同机制的设计直接影响性能,以下是主流实现的对比:

其中 epoll 的红黑树 + 就绪链表 是最优秀的设计,我们重点拆解它的数据结构和工作流程。
三、深度解析:Linux epoll 的数据结构与工作流程
epoll 是 Linux 下高性能 IO 复用的核心,通过 红黑树(管理注册事件) 和 就绪链表(存储就绪事件) 实现 "O (1) 时间复杂度" 的事件查询,具体如下:
- 核心数据结构
epoll 在内核中会为每个应用程序的 epoll 实例(通过 epoll_create() 创建)维护两个关键数据结构:
红黑树(RB-Tree) :
作用:存储应用程序 "已注册的所有 IO 通道和事件"(如某个 socket 注册了 "读事件")。
优势:红黑树是平衡二叉搜索树,支持 O (log n) 时间的插入、删除、查询操作,适合管理大量动态变化的 IO 通道(比如 thousands 到 millions 级的 socket)。
示例:当应用调用 epoll_ctl(EPOLL_CTL_ADD) 注册一个 socket 的 "读事件" 时,内核会将这个 socket 和事件封装成 epitem 结构体,插入红黑树。
就绪链表(Ready List):
作用:存储 "已就绪的 IO 事件"(如某个 socket 有数据可读)。
优势:链表的插入和删除是 O (1) 时间,且无需遍历 ------ 当硬件中断触发后,内核会直接将对应的 epitem 从红黑树中找到,加入就绪链表。
示例:当网卡收到数据后,中断处理函数会找到对应的 socket,将其 epitem 标记为 "读就绪",并添加到就绪链表。 - 完整工作流程(以 "监听 socket 读事件" 为例)
graph TD
A应用程序调用 epoll_create() --> B内核创建 epoll 实例,初始化红黑树和就绪链表
B --> C应用调用 epoll_ctl(EPOLL_CTL_ADD),注册 socket 的读事件
C --> D内核将 socket 封装成 epitem,插入红黑树
D --> E应用调用 epoll_wait(),线程进入内核态
E --> F{就绪链表是否为空?}
F -->|是| G内核挂起线程,释放 CPU
F -->|否| H内核唤醒线程,将就绪链表返回给应用
G --> I硬件收到数据,触发中断
I --> J内核中断处理函数:找到对应 epitem,加入就绪链表
J --> H
H --> K应用遍历就绪链表,处理读事件(如读取 socket 数据)
关键细节:
应用调用 epoll_wait() 后,线程会被内核挂起(不占用 CPU),直到有事件就绪 ------ 这区别于 select/poll 的 "每次调用都要遍历所有注册通道",epoll 只需直接返回就绪链表,无遍历开销;
红黑树的作用是 "快速找到已注册的 IO 通道",避免注册 / 删除时的线性查找;就绪链表的作用是 "直接返回就绪事件",避免应用对未就绪通道的无效处理。
四、例子:用 epoll 实现简单服务器(C 语言,体现内核机制)
虽然关注 Java,但 epoll 是内核机制,用 C 语言能更直观体现数据结构的作用(Java 的 Selector 在 Linux 下就是封装了 epoll)。以下是简化的 epoll 服务器代码,对应上述工作流程:
c
#include <stdio.h>
#include <stdlib.h>
#include <sys/epoll.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <unistd.h>
#define MAX_EVENTS 1024 // 就绪事件列表的最大长度
#define PORT 8080
int main() {
int server_fd, epoll_fd, nfds;
struct epoll_event ev, events[MAX_EVENTS];
struct sockaddr_in addr;
socklen_t addr_len = sizeof(addr);
// 1. 创建 socket(监听用)
server_fd = socket(AF_INET, SOCK_STREAM, 0);
addr.sin_family = AF_INET;
addr.sin_addr.s_addr = INADDR_ANY;
addr.sin_port = htons(PORT);
bind(server_fd, (struct sockaddr*)&addr, sizeof(addr));
listen(server_fd, 5);
// 2. 创建 epoll 实例(内核初始化红黑树和就绪链表)
epoll_fd = epoll_create1(0);
if (epoll_fd == -1) { perror("epoll_create1"); exit(EXIT_FAILURE); }
// 3. 注册"服务器 socket 的连接事件"到 epoll(插入红黑树)
ev.events = EPOLLIN; // 监听"读事件"(新连接本质是读事件)
ev.data.fd = server_fd; // 关联服务器 socket 的文件描述符
if (epoll_ctl(epoll_fd, EPOLL_CTL_ADD, server_fd, &ev) == -1) {
perror("epoll_ctl: server_fd"); exit(EXIT_FAILURE);
}
printf("epoll 服务器启动,端口 %d\n", PORT);
// 4. 循环等待事件就绪(应用阻塞在 epoll_wait())
while (1) {
// 调用 epoll_wait(),内核返回就绪事件数量
nfds = epoll_wait(epoll_fd, events, MAX_EVENTS, -1); // -1 表示无限阻塞
if (nfds == -1) { perror("epoll_wait"); exit(EXIT_FAILURE); }
// 5. 遍历就绪链表(events 数组就是内核返回的就绪事件列表)
for (int i = 0; i < nfds; i++) {
// 处理新连接事件(服务器 socket 就绪)
if (events[i].data.fd == server_fd) {
int client_fd = accept(server_fd, (struct sockaddr*)&addr, &addr_len);
if (client_fd == -1) { perror("accept"); continue; }
printf("新客户端连接:%d\n", client_fd);
// 注册"客户端 socket 的读事件"到 epoll(插入红黑树)
ev.events = EPOLLIN | EPOLLET; // EPOLLET:边缘触发(高效模式)
ev.data.fd = client_fd;
if (epoll_ctl(epoll_fd, EPOLL_CTL_ADD, client_fd, &ev) == -1) {
perror("epoll_ctl: client_fd"); close(client_fd);
}
}
// 处理客户端数据读事件(客户端 socket 就绪)
else {
char buf[1024] = {0};
int bytes_read = read(events[i].data.fd, buf, sizeof(buf));
if (bytes_read <= 0) { // 客户端断开或读错误
close(events[i].data.fd);
printf("客户端断开:%d\n", events[i].data.fd);
} else { // 读取到数据
printf("收到客户端 %d 数据:%s\n", events[i].data.fd, buf);
write(events[i].data.fd, "已收到数据\n", 11); // 回写响应
}
}
}
}
close(server_fd);
close(epoll_fd);
return 0;
}代码对应内核机制:
epoll_create1(0):内核创建 epoll 实例,初始化红黑树(管理注册的 fd)和就绪链表(存储就绪事件);
epoll_ctl(epoll_fd, EPOLL_CTL_ADD, ...):将 fd 和事件插入红黑树,完成注册;
epoll_wait(...):应用线程进入内核态,若就绪链表为空则挂起,有事件则返回就绪链表(events 数组);
循环遍历 events 数组:直接处理内核筛选后的就绪事件,无需遍历所有注册的 fd,效率极高。
五、为什么 Java 的 Selector 在 Linux 下高效?
Java 的 Selector 是对操作系统 IO 复用机制的封装:
在 Linux 系统下,Selector 底层就是调用 epoll 系列函数(epoll_create/epoll_ctl/epoll_wait);
Java 中的 SelectionKey 对应 epoll 的 epitem 结构体,Selector.selectedKeys() 返回的集合对应内核的 "就绪链表";
因此,Java 用 Selector 实现的 NIO 多路复用,本质是借助了 Linux epoll 的 "红黑树 + 就绪链表" 设计,实现高效的事件监听。
总结
操作系统级别的事件监听,核心是 "内核代替应用监控硬件 IO 状态,通过高效数据结构管理事件":
原理:硬件中断触发内核标记就绪事件,应用阻塞等待内核通知,避免主动轮询;
数据结构:epoll 用红黑树管理注册事件(O (log n) 增删查),用就绪链表存储就绪事件(O (1) 访问),是性能最优的设计;
例子:C 语言 epoll 代码直接体现内核机制,Java Selector 封装后提供跨平台 API,但在 Linux 下仍依赖 epoll 实现高性能。
这种设计从根源上解决了 "应用轮询" 的低效问题,让单线程能轻松处理百万级 IO 连接,是高并发服务器(如 Netty、Nginx)的核心技术基石
。